






第二周:在自然语音处理领域打下基础。学习词嵌入技术,RNN,以及如何通过pad_sequence处理不定长的序列。
1:导必要包并设置忽略警告
import torch
import torch.nn as nn
import torchvision
from torchvision import datasets, transforms
import os, PIL, pathlib,warnings
warnings.filterwarnings('ignore')
warnings.filterwarnings('ignore')
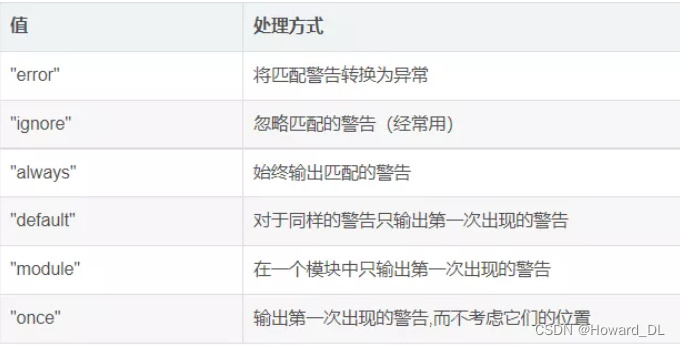
Python通过调用 warnings 模块中定义的 warn() 函数来发出警告。但某些情况下我们不希望抛出异常或者直接退出程序。
这时就可以设置警告过滤器来控制是否发出警告消息,警告过滤器是一些匹配规则和动作的序列。可以通过调用 filterwarnings() 将规则添加到过滤器,并通过调用 resetwarnings() 将其重置为默认状态
警告过滤器【warnings.filterwarnings("ignore")】用于控制警告消息的行为,如忽略,显示或转换为错误(引发异常)。参数有如下几个。我们一般设置ignore即可。
2:导入数据与torchtext安装
from torchtext.datasets import AG_NEWS
train_iter,test_iter=AG_NEWS(split=('train','test'))首先尤其要注意torchtext的导包方法。否则会无意中修改自己的环境
如果用conda install torchtext==0.15.1类似的,则由于torchtext 要与torch 匹配。则该命令会修改你的torch环境。不过你是cuda版本还是其他的,都会给你删掉。并修改成对应的。
所以我们当用下面的命令安装:
conda install -c pytorch torchtext函数
torchtext.datasets.AG_NEWS(split=('train','test'))。导入AG_news数据。其中参数为导入的数据类型。可以是split='train',split='test',或者split=('train','test')
注意返回的不是dataset数据类型。而是iterator迭代器数据类型。创建词表时只能yeild迭代输入。
3:导入分词器tokenizer(此处用的是torchtext的分词器,注意与transformers分词器的区别)
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
tokenizer=get_tokenizer('basic_english')
#例子
print(tokenizer('i like learning NLP'))
##输出为 ['i', 'like', 'learning', 'nlp']
下面是transformer的分词器,注意语句的对应。上面的语句对应的是tokenizer.tokenize
from transformers import AutoTokenizer
tokenizer2=AutoTokenizer.from_pretrained('bert-base-uncased')
print(tokenizer2('i like learning NLP'))
#输出为
'''
{'input_ids': [101, 1045, 2066, 4083, 17953, 2361, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
'''
print(tokenizer2.tokenize('i like learning NLP'))
#输出为['i', 'like', 'learning', 'nl', '##p']
4:建词表
def yield_tokens(data_iter):
for _,text in data_iter:
yield tokenizer(text)
vocab=build_vocab_from_iterator(yield_tokens(train_iter),specials=['<unk>'])
vocab.set_default_index(vocab['<unk>'])
vocab(['here' ,'is' ,'an' ,'example'])
#输出为[475, 21, 30, 5297]
#注意不能为vocab('here is an example'),vocab只是把字转为id
text_pipeline=lambda x:vocab(tokenizer(x))
label_pipeline=lambda x:int(x)-1
text_pipeline('here is an example')
#输出为[475, 21, 30, 5297]
这里有个注意的点就是vocab(['here' ,'is' ,'an' ,'example']),vocab里面只能是列表,不能是句子,因为句子不在词表里,只有分词后的词在里面,所以要先切分,再转化为id
注:text_pipeline为整合的管道。
vocab.set_default_index(vocab['<unk>'])的意思是把所有不在词表中的单词设为<unk>,id 为0
5:创建dataloader 并将batch内可变序列长度填充为最大定长长度
import torch.utils.data as data
from torch.nn.utils.rnn import pad_sequence
def collate_fn(batch):
labels,texts,lenn=[],[],[]
for (label,text) in batch:
labels.append(label_pipeline(label))
texts.append(torch.tensor(text_pipeline(text)))
lenn.append(len(text_pipeline(text)))
labels=torch.tensor(labels)
texts=pad_sequence(texts, batch_first = True, padding_value = 0 )
return texts,lenn,labels
train_dl=data.DataLoader(train_iter,batch_size=3,shuffle=True,collate_fn=collate_fn)
test_dl=data.DataLoader(train_iter,batch_size=3,shuffle=True,collate_fn=collate_fn)
collate_fn为最后数据以怎样的方式集成dataloader。
collate_fn返回什么,最后dataloader就返回什么。
torch.nn.utils.rnn.pad_sequence将序列填充为最大长度,输入为元素为tensor的列表。
6:建立LSTM神经网络
架构为先把文本转化为id,再进行词嵌入。最后通过多层BiLSTM进行提取。结果为最后一层,最后一个神经元的输出。
#%% model
embed_dim=32
class CustomRNN(nn.LSTM):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.embedding=nn.Embedding(len(vocab),embed_dim,sparse=False)
self.danse=nn.Linear(16,4)
def forward(self, input, lengths):
input=self.embedding(input)
package = nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=self.batch_first,
enforce_sorted=False)
result, hn = super().forward(package)
output, lens = nn.utils.rnn.pad_packed_sequence(result, batch_first=self.batch_first,
total_length=input.shape[self.batch_first])
out=output[:,-1,:]
out=self.danse(out)
return out
# 定义网络
model = CustomRNN(input_size=embed_dim, hidden_size=8, batch_first=True,
num_layers=7, bidirectional=True)# 改进的LSTM模型
7:设置训练参数并训练
注意:训练过程已经完全封装成了函数,可以直接搬取套用。同时也可以写成自己的模块python包自己导入。
#%%设置训练参数
epochs=1
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
loss_fn=torch.nn.CrossEntropyLoss()
opt=torch.optim.Adam(model.parameters(),lr=1e-4)
#%%训练
def train(data_iter, model, loss_fn, optimizer, device):
train_loss, train_acc, num_batches = 0, 0, 1 # 初始化训练损失和正确率
for _, (x1, x2, y) in enumerate(data_iter): # 获取图片及其标签
# 计算预测误差
pred = model(x1, x2) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
num_batches += 1
train_acc /= (num_batches * 3)
train_loss /= num_batches
return train_acc, train_loss
#ans1=train(train_dl, model, loss_fn, opt, device)
#%%
def test(dataloader, model, loss_fn, device):
test_loss, test_acc, num_batches = 0, 0, 1
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for _, (x1, x2, target) in enumerate(dataloader):
# 计算loss
target_pred = model(x1, x2)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
num_batches += 1
test_acc /= (num_batches * 3)
test_loss /= num_batches
return test_acc, test_loss
#ans2=test(test_dl, model, loss_fn, device)
#%%
def start_train_and_test(epochs, device, model, train_dl, test_dl, loss_fn, opt):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt, device)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn, device)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(
template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
return {'train_acc': train_acc, 'train_loss': train_loss, 'test_acc': test_acc, 'test_loss': test_loss}
#%%
ans=start_train_and_test(epochs, device, model, train_dl, test_dl, loss_fn, opt)最后如果想每周深度学习带练打基础与提高的话,可以联系我















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









