







1.是什么
基于数据寻找规律从而建立关系,进行升级,如果是以前的固定算式那就是符号学习了

2.基本框架
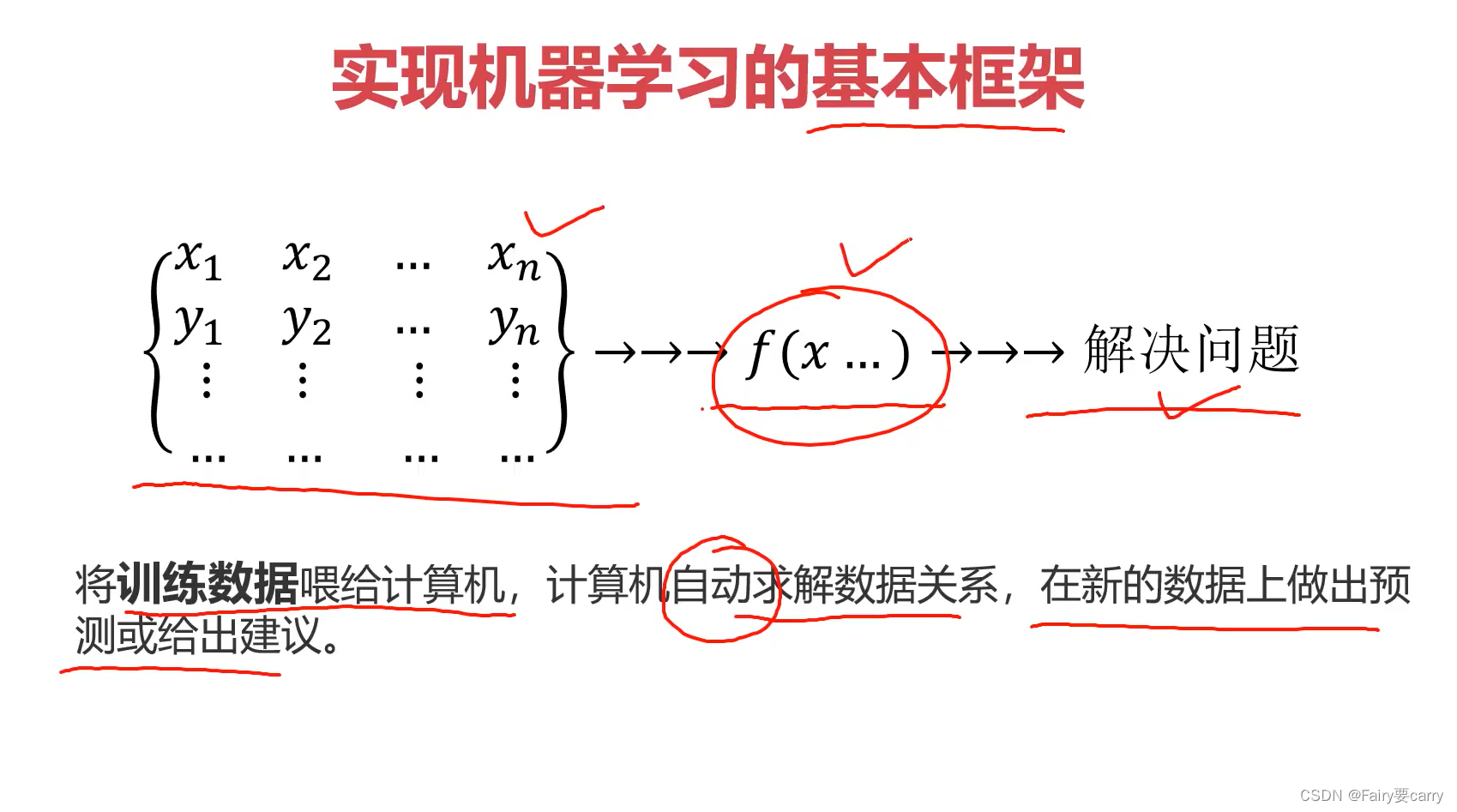
3.监督学习和无监督式学习:

-
监督学习:根据正确结果进行数据的训练;
在监督式学习中,训练数据包括输入和对应的输出标签。模型的目标是学习如何映射输入到输出。
在训练期间,模型通过与标签进行比较来调整自身的参数,以最小化预测与真实标签之间的误差。
一旦模型经过训练,它可以用于预测未见过的输入数据的输出标签。
例如,给定一组包含猫和狗图像的数据集,并且每张图像都有相应的标签(是猫还是狗),监督式学习算法可以学习如何从图像中提取特征,并预测新图像中是否有猫或狗。(比如性格预测等等) -
无监督式学习:
在无监督式学习中,训练数据没有与之相关联的输出标签。模型的目标是从数据中发现隐藏的结构或模式。
模型试图在数据中找到某种形式的组织或聚类,而无需事先知道该数据的标签。
由于缺乏标签,无监督式学习通常用于探索性数据分析或数据预处理阶段。
例如,使用聚类算法对一组顾客的购买历史进行分组,以发现具有相似购买模式的顾客群体,而无需事先知道每个顾客的标签或类别。 -
强化学习:
根据执行效果给定一种奖励惩罚的模式:比如RAG,AlphaGO -
**新思路:**混合学习















 1892
1892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











