






1.论文名: KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation 【2024.RAG.arXiv】
2.科学问题:
RAG依赖于文本的向量相似度作为参考信息的检索,所以对深度语义信息较为缺乏。
我的想法是将余弦相似度与KL散度,然后利用词典对句子分词,捕获谓语动词评价其词汇的情感,将三者综合起来作为句子与句子之间的相似度。
3.做出假设:
作者认为 KG 和 RAG 起到了互补作用,不仅仅是利用 KG 作为一个知识库,而且还包含了语义类型和关系,使得 Query 能够明确地指向实体类型,减轻噪音的干扰。
4.方法细节:
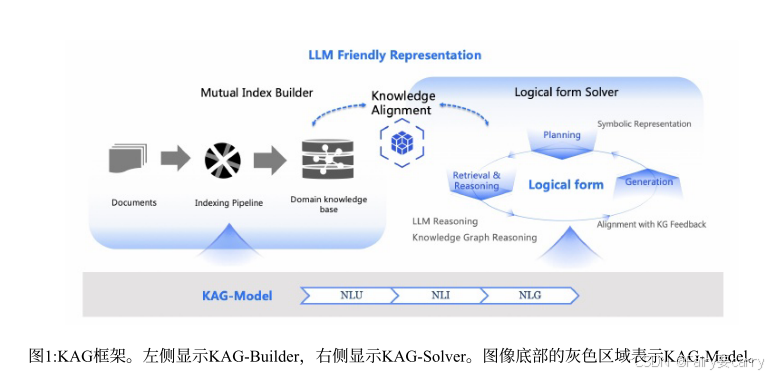
作者提出了三个部分,KAG-Builder、KAG-Solver、KAG-Model。KAG-Builder 用于构建离线索引,其作用是构建知识结构和文本片段之间的相互索引。KAG-Solver,引入了一个推理求解器,其中包含知识推理、数学逻辑推理、LLM 推理。KAG-Model 用于优化每个模块的能力。【主要侧重于:KG-Builder 和 KG-Solver】
原来的RAG: 文本分块->向量化->相似度检索…
KAG: 知识分块->构建知识图谱->构建相互索引…
4.1 KAG-Builder:
**目的:**在图结构和文本块之间建立 mutual-index 、利用概念语义来对齐不同的知识粒度。
**过程:**结构化信息获取、知识对齐、存储。
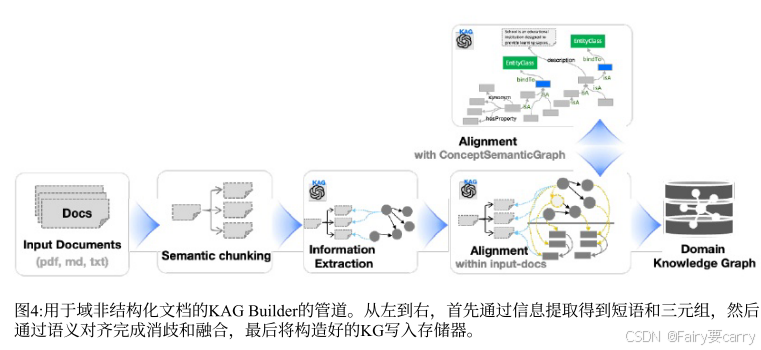
4.1.1 Semantic Chunk 分块:
- 分块依据:根据文档的结构层次和段落之间的逻辑关系,基于 Prompt(系统内置提示)实现语义分块
- Chunk 的表示:每个块被定义为一个实例,由文章标识符 articleID、文档段落编号 paraCode、段落中块的顺序编号 idlnPara,然后每个块具有摘要 summary 和主要文本内容 mainText。【分为三种:文章、段落、段中的块】
- 优势:在不同的粒度进行匹配
KG-Pipline 的想法: 在病人分类这块,前台 Agent 显然需要有很多的基础知识。所以,我们可以将以往的病例进行分块:ID由病例 ID、门诊 ID组成、病例中的摘要、主要内容。
如:
Chunk1:
- id = “001#01”
- summary = “患者初步诊断为太阳能利用相关的皮肤炎症。”
- mainText = “患者因长时间暴露于太阳能设备下,出现皮肤红肿、瘙痒等症状。经过初步检查,怀疑是太阳能利用过程中的紫外线辐射导致的炎症。建议进一步进行皮肤测试,并避免直接接触太阳能设备,直到症状缓解。”
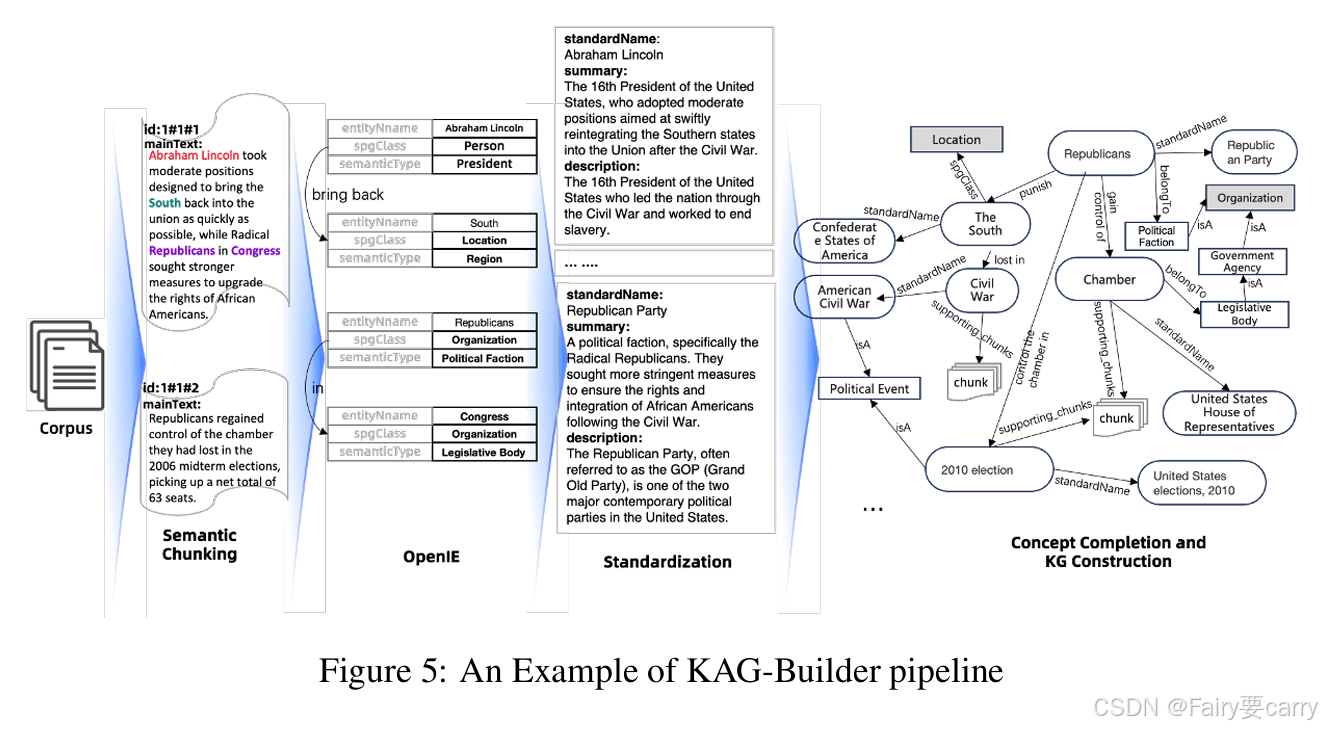
4.1.2 OpenIE 开放信息抽取:
利用 LLM 去抽取,首先逐个 Chunk 提取所有实体集 E = {e1,e2,e3…},其次,提取出与实体相关联的事件集 EV = {ev1,ev2,ev3,…},然后迭代取出实体之间的关系集 R = {r1,r2,…}。
为什么要这么做?
一个具体的人,做了具体的事,怎么样做的。有了这三个点就能判定你要挂什么科。
如图所示:
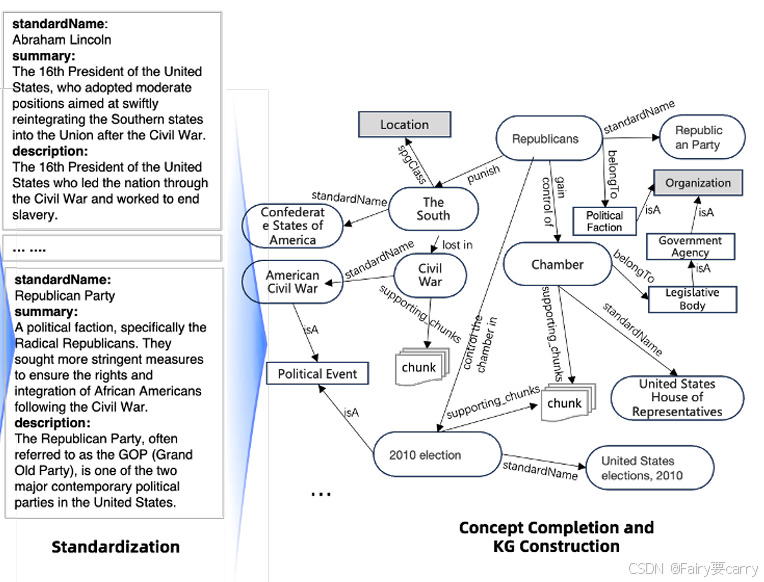
4.1.3 标准化:
对抽取的实体进行标准化,即补充实体的属性信息,包括摘要和描述。具体如图所示:
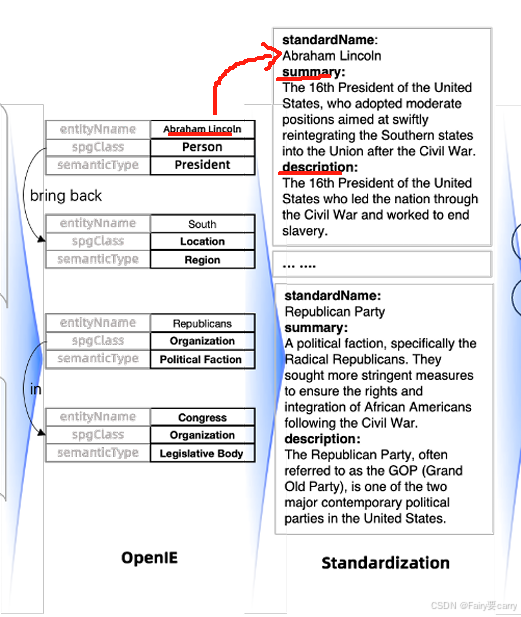
对实体进行标准化的目的类似于:在某个时间点,某种年龄和某种性别的人并发症状可能比较明显,因此我们可以利用实时的外部知识去丰富实体的属性内容。
4.1.4 概念完成后知识图的构建:
目的:将标准化后的实体与关系、事件构成 KG ,而 Mutual-Index 即为语义分块后的文本内容与 KG 之间建立关联。
4.2 KAG Solver:
在问题方面,作者设计了一个 Logical Form Solver,分为 Planning、Reasoning、Retrieval 三个阶段。
Planning:
- 子问题分解
Reasoning、Retrieval:
- 每个子问题利用检索和推理器得到子问题答案,并将答案记录到 history
- 根据 history 中的答案判断是否需要生成新的问题
- 迭代
实验:
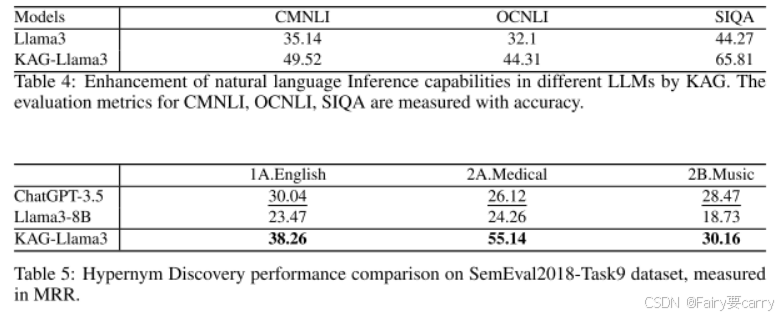
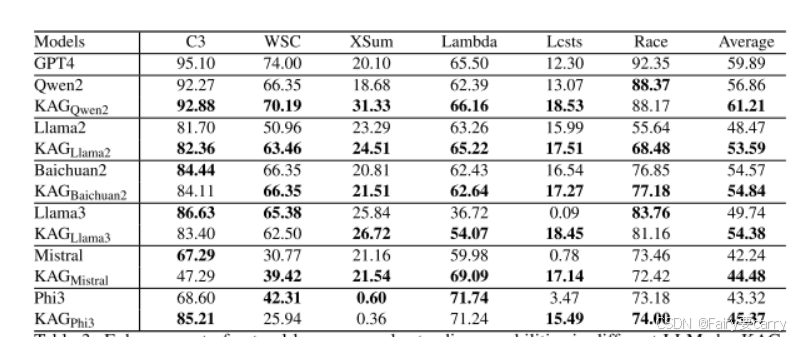
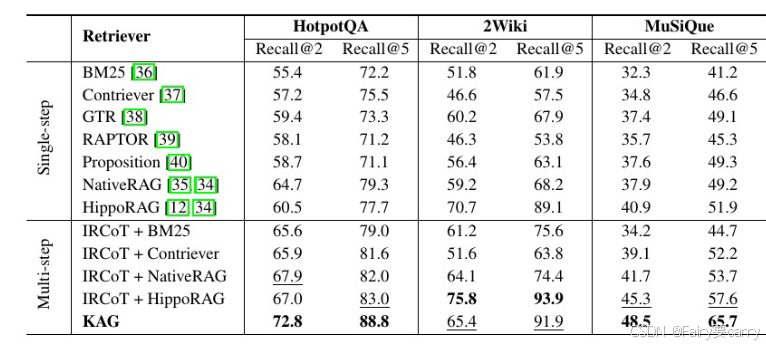
作者构建了一个含有8000个知识内容的知识集,并拆分成了六个不同类别的数据集,评估了推理效果,指标为ACC和R1(衡量输出和参考答案的相关性)


















 2593
2593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











