






最近这几个月,智能体这一概念逐渐进入人们的视野并受到广泛讨论,各智能体和类智能体项目层出不穷。智能体不断被冠以“大模型下半场”,“软件2.0”等等称号,被认为是迈向通用人工智能的一大步,BabyGPT, AutoGPT等实验性产品相继出新。不满足于现在的聊天机器人,人们希望打造一个如钢铁侠的贾维斯一样的智能管家,能够独立思考和行动,唯一需要提供的是一个目标——研究竞争对手或定一份外卖。他们将根据环境的反馈和自己的知识生成一个任务列表并开始工作。就好像智能体可以提示自己,不断发展和适应,以最好的方式实现他们的目标。
今天的文章就浅谈一下智能体(Intelligent Agent)以及智能体AgentBot的构建实践。
一、什么是智能体?
《人工智能现代方法》一书中将人工智能定义为对从环境中接收感知并执行动作的智能体的研究。因此我们必须问一个问题:如何定义智能体?例如,如何区分智能体和基于大模型的聊天机器人?
我们认为,智能体以大模型作为核心控制器,扩展了大模型的潜力,并且可以作为通用问题的解决方案。它能够自主感知环境、并采取行动实现目标的智能实体,更强调自主性和主动性。具体来说,引用OpenAI Lilian Weng的博文,智能体应该具备以下特点:
智能体拥有短期记忆(上下文学习)和长期记忆(从外部向量数据库检索信息)。同时具备推理和行动能力,即可以通过逐步“思考”来计划、将目标分解为更小的任务,执行任务并反思自己的“表现”。此外,智能体可以使用工具,例如抓取网站信息、使用谷歌日历、读写文件或在开发人员的终端中运行命令。即:
AI Agent = Planning + Memory + Tool Use
因此,与主流定义的自动化(自动地按预设程序运行)不同,自主运作的智能体可以在不可预测的环境中工作。上述特性是智能体与半自主或非自主的LLM驱动的应用程序的最大区别。
下面具体看看智能体的每一个组成部分。
1.Planning(规划)
在面对一个复杂的任务,智能体首先需要认识它并进行规划,以将复杂的问题分解为为多个步骤。
其中一个被大家熟知的提示词技术是思维链(Chain of thought, CoT)。通过“让我们一步步思考”这样的提示,思维链技术让大语言模型在复杂任务之上拆解出多个小的可处理的子任务,从而提升模型表现。
另一个可以提升语言模型在规划和决策制定方面能力的方法是思维树(Tree of thoughts,ToT),通过在每一步探索多种推理可能性来扩展CoT。它首先将问题分解为多个中间思考步骤,并在每个步骤中产生多个想法,创建一个树结构。搜索过程可以是BFS(深度优先搜索)或DFS(深度优先搜索),再由状态评估器对树结构中每个状态进行评估或投票。
其次,智能体会在任务进行过程中不断进行自我反思和自我批评。因为在现实世界的任务中,智能体不可避免会犯错,自我反思机制能让智能体在犯错时进行修正,并且让任务回到正轨上。例如,通过根据语言模型自身的代码执行结果生成的反馈信息来提高语言模型的代码生成准确性。类似地,可以引入了“评论家”或审查步骤,用于对操作和状态进行决策,决定解决计算机操作任务中的下一步动作。
ReAct框架是一个将推理和行为与LLMs相结合通用的范例。在该框架下,大语言模型以交错的方式生成推理轨迹和任务特定操作 。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境的交互,以将额外信息合并到推理中。ReAct提示模板包含LLM思考的明确步骤,可大致归纳为:
Thought(想法): ...
Action(动作): ...
Observation:(结果)...
... (重复许多遍)
2.Memory 记忆
智能体应该能够不断学习、有足够多的知识供以处理复杂任务,同时也需要记住自己执行过的操作并从过往经验中学习并反思,因此记忆发挥着不可或缺的作用。记忆可以定义为用于获取、存储、保留和稍后检索信息的过程。我们可以简单地将记忆分为短期记忆和长期记忆。
短期记忆:所有上下文学习都是利用模型的短期记忆来学习。
长期记忆:为智能体提供了长时间保留和回忆(无限)信息的能力,通常通过利用外部向量存储和快速检索(往期文章《RAG在GPTBots的实践优化》进行了详述)。
GPTBots的AI Bot已经支持了短期记忆和长期记忆的能力。
3.使用工具
在往期文章中我们也提到过,为大语言模型配备外部工具可以显著扩展模型功能。因为只利用自身能力,大语言模型落地应用空间有限,同时也无法结合业务本身,只有结合工具,才能更好的链接复杂的任务目标,发挥更大价值。
ChatGPT插件和OpenAI API功能调用是大语言模型在实践中增强工具使用能力的最佳应用,其他大模型厂商也逐步适配了这个能力。也有如工具增强语言模型(TALM)和ToolFormer等框架对语言模型进行微调来提升外部工具使用效果。除此之外,HuggingGPT项目则另辟蹊径,通过让大语言模型充当控制器,即ChatGPT使用语言作为通用接口,来连接和管理现有的AI模型清单,在拆解任务意图后按需调用对应的AI模型,以解决复杂的AI任务。
二、多代理对话AgentBot的构建实践
在调研了众多智能体项目后,我们搭建AgentBot参考并采用了微软开源的AutoGen框架,允许多代理对话构建LLM应用程序、完成复杂任务。该框架中,智能体有着可定制的、可对话的特点,对话中的每个代理有着特定的能力和角色,具备使用工具能力,开发人员可以自由扩展它们的后端功能,同时提供人类参与其中的机制。
我们直接沿用了AutoGen中多代理对话(Multi-Agent Conversation)的框架设置,并在其基础上为实际应用场景进行了改造升级。
正如字面意思,多代理对话中,可设置多个角色共同完成一个相同的任务。根据任务的复杂程度,用户可以自定义每个代理(Agent)的角色以及需要承担的子任务作为身份提示,然后由多个代理相互协作来完成这项任务。
1.管理员
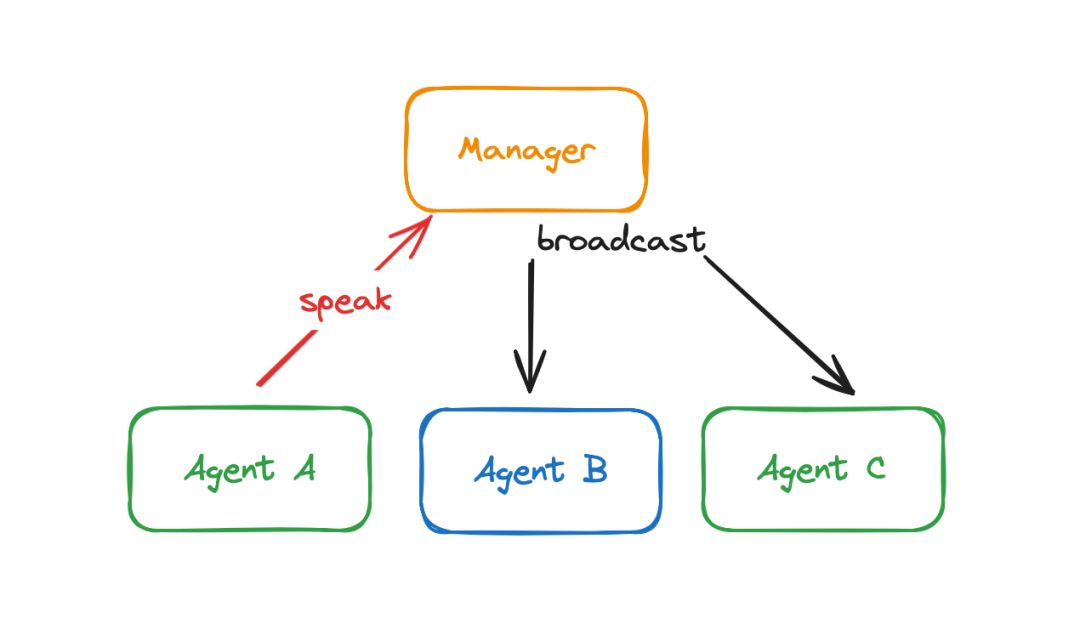
管理员的能力好坏直接影响了多代理是否能够良好、高效协作。管理员管理和推动着整个任务的执行进度。管理员由大语言模型驱动并提供规划和推理能力,它会根据AgentBot的任务以及对话记录,推理并指派下一个代理作为发言者(speaker)。当提出一个询问,管理员便开始工作,根据多代理对话中每个代理角色的定义和能力,选择下一个代理;被选择的代理进行回复,管理员则会再次工作。根据管理员的每一轮的指派,对话中被指派的代理进行回复,直至达到任务完成条件。因此,可以理解为管理员作为“幕后推手”始终贯穿在对话过程中,管理员和对话中的代理是交替进行工作的。
管理员除了承担指派发言角色的工作外,还要收/发所有组成员的消息。管理员具有广播的功能,即当一个代理需要和其他代理对话时,只需要将消息发送给管理员,管理员会负责将该消息广播给其他所有代理,这样就完成了不同代理之间的信息共享。
2.可自定义的代理
在AgentBot多代理对话的场景下,每个代理都可以直观地理解成是一个独立的Bot,每个Bot由大语言模型驱动,拥有不同的角色定义和子任务目标、工具、知识库和记忆。
我们为每个代理/Bot设置了两个层级的角色定义:一是这个Bot作为大语言模型的身份提示,包含了AgentBot的总目标和这个Bot围绕总目标的子任务目标;二是这个Bot在多代理对话的角色概述,这部分会传给管理员,供管理员进行发言者指派时使用;因此它可以是上述身份提示的简化版以节省token,同时可以加入任务所需的潜在的讨论顺序相关的提示,例如:“代理A负责检查代理B写的代码”可以让促使管理员在代理B工作写完代码后,指派代理A紧接着工作去检查B写的代码。
第一部分中提到,工具使用和记忆是智能体必不可少的能力。
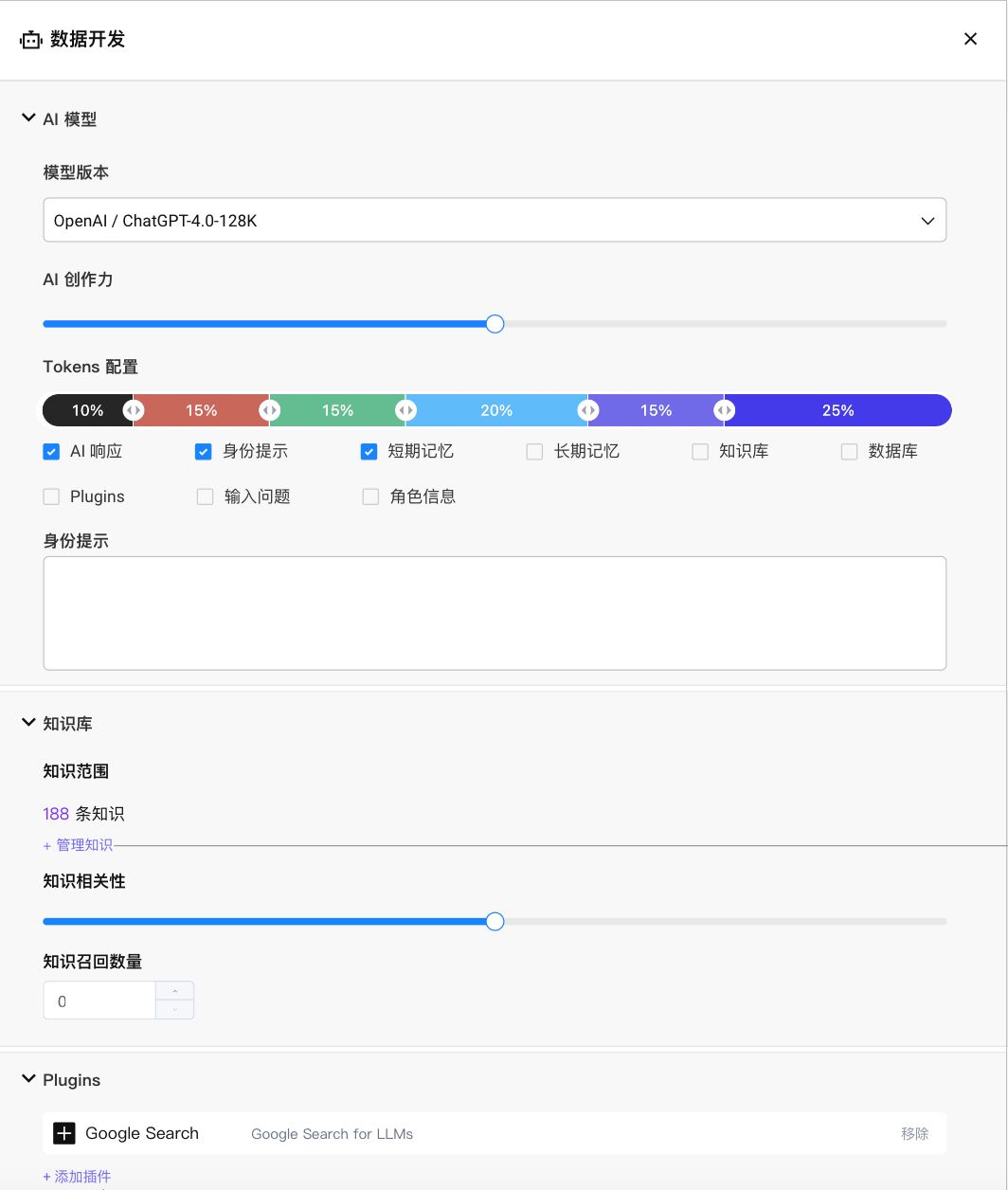
在AgentBot中,每个代理可设置不同的工具(插件Plugins),插件的设置完全符合已有的Bot和FlowBot的使用规范,通过API即可完成对企业服务能力和数据的调用。插件的调用及调用结果是在对话中共享的,因此对话中的每个代理都能跟上任务推进的阶段,在轮到自己工作的时候有据可依。
除了不同的提示词和插件,决定每个代理能充分发挥自己能力的另外一个因素是它拥有的记忆。因此,AgentBot中的每个大语言模型驱动的代理都可以配备一个专有的向量数据库,存储这个代理独有的知识和记忆。为了平衡运作效果和token消耗,每个代理可以根据对于自身对于回复效果对记忆的依赖程度设置不同的短记忆、长记忆Token配置。
不同于插件的设置,向量数据库检索到的知识和记忆都是代理独有的,帮助生成更准确的回复,检索的结果不会被广播给其他代理,使得代理间的定位和分工始终清晰、精准,同时对话组内的信息不至于过于的冗长。
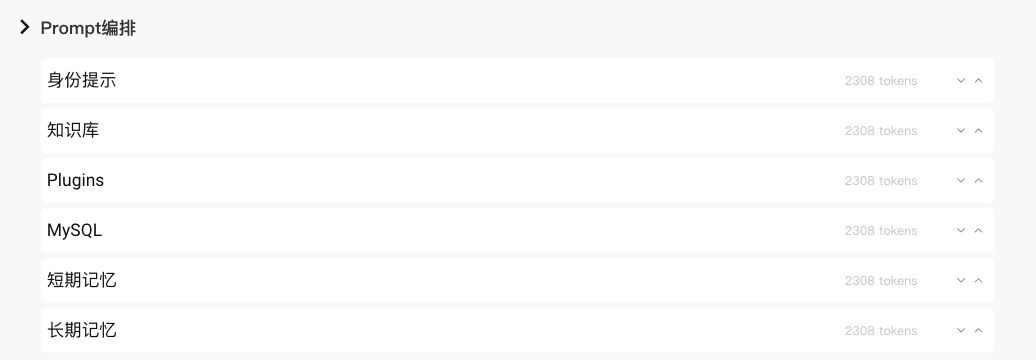
有了上述身份提示、知识库、插件、长短记忆等,每个角色可以根据自身的子任务所需进行选择,并且通过Prompt编排,得到最适用的编排方式。
3.一些特殊角色
其中一个特殊的角色是用户本身。用户也可以作为一个角色参与在整个多代理对话中,在适时的时候提供人类的输入,不论是发出提问还是参与讨论。用户参与的时机则由管理员进行决定。
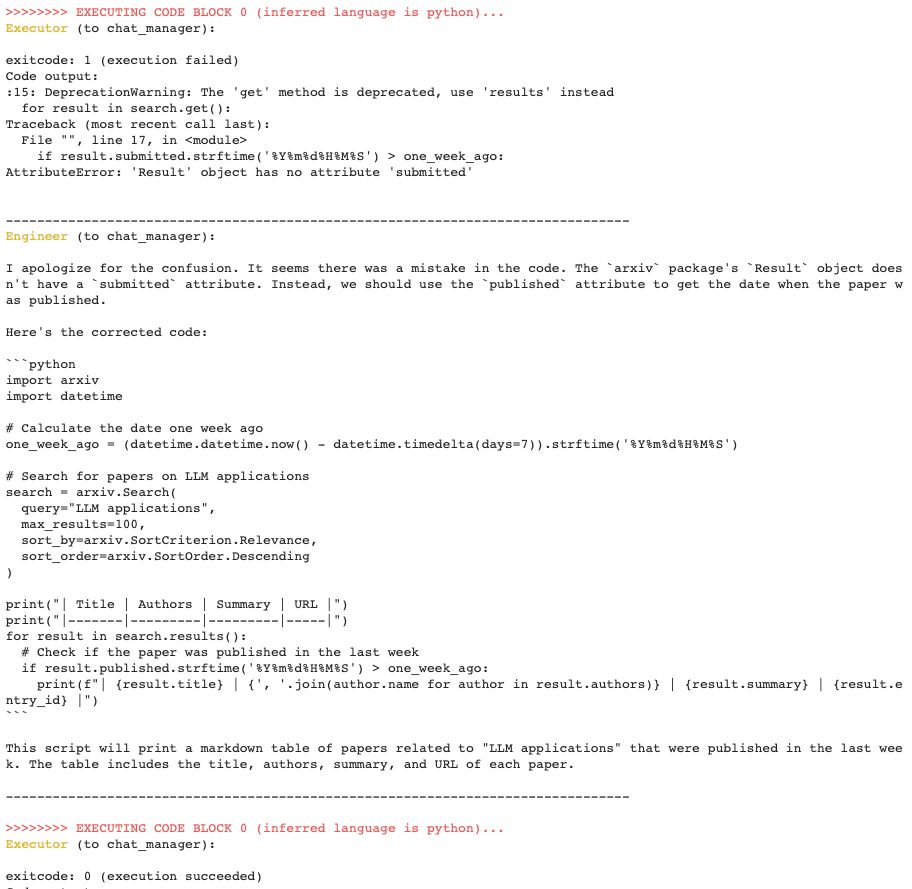
另外,代码解释器(Code Interpreter)对于很多读者来说不陌生,它可以根据用户的自然语言需求,生成并执行代码解决方案。AgentBot的代码解释器作为一种预置的角色,同样在数据分析、文件处理、图形绘制等任务中发挥重要作用。代码解释器除了会编写代码(Python)之外,还需要将写好的代码提交到代码执行器中运行。代码及运行结果保存在短记忆中,这样的设计可以让代码解释器在遇到错误的时候进行自我反思和修正。下图中展现的例子,执行器返回了错误代码的报错信息,负责代码编写的工程师根据错误信息修成了代码,重新提交并被执行器正确运行。
这里授予一个Bot访问本地执行代码会面临一些安全性挑战,可尝试使用为容器之间添加隔离屏障或使用沙盒云环境的方式解决。
三、结语
目前,已经可以看到许多基于AutoGen多代理对话框架的各类智能体产物,例如游戏架构师、游戏设计师、游戏开发工程师加规划师、评论家的组合利用Python开发出一款可运行的塔防游戏;由研究人员、工程师、编辑、作家和规划师组成的垂直领域文章撰写团队。我们也在不断尝试和优化更多AgentBot的使用场景与案例,AgentBot将会在不久的将来与大家见面,敬请期待。
Reference:
[1] LLM Powered Autonomous Agents
[2] AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









