







目的:原来的一些比较好的方法,不论是FlowNet2还是PWCNet,网络所消耗的算力都不小。FlowNet2需要级联encoder-decoder结构以达到SOTA;而PWCNet使用了feature pyramid使得网络轻量,但在不同分辨率解码光流时都需要使用不同的Denset block,参数量也不少。而这篇文章提出IRR方法,使得模型参数量大大减少,主要原因在于IRR这种训练方法使得每一个model unit或是block uint的复用率大大增加。
方法
IRR从经典的能量最小化方法和残差网络中汲取灵感,提出一种基于权重共享的迭代残差细化方法,IRR可以与多个主干网络结合。减少了参数量的同时,提高了准确性。集成了遮挡预测和双向流估计后,IRR可以进一步提升性能。
FlowNet的IRR版本就是迭代地重复使用FlowNetS,利用网络预测的光流去warp图像2,然后与图像1一起再次输入同一个FlowNetS,这样不断地refine这个网络。PWC-Net的IRR版本的主要改动在optical flow decoder部分,原始的PWC-Net会在每个分辨率使用一个decoder去预测光流,但是IRR版本的PWC-Net复用同一个decoder去预测不同分辨率的光流。
IRR with FlowNet
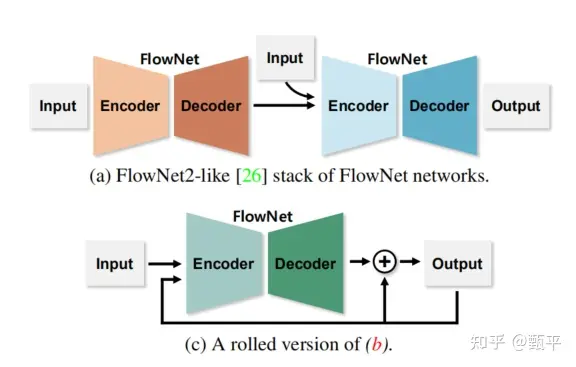
FlowNet的IRR版本就是迭代地重复使用FlowNetS,利用网络预测的光流去warp图像2,然后与图像1一起再次输入同一个FlowNetS,这样不断地refine这个网络。具体的公式表示如下:
看下面这个图就更清楚了---图(a)中是两个不同的encoder-decoder,而图(c)中是同一个encoder-decoder。
IRR with PWC-Net
PWC-Net的IRR版本的主要改动在optical flow decoder那部分,原始的PWC-Net会在每一个分辨率使用一个decoder去预测光流,但是IRR版本的PWC-Net就复用一个decoder去预测不同分辨率的光流,这个地方着实有点巧妙。具体公式表示如下:
其中
较小分辨率的光流预测结果经过upsample就可以用来warp较高分辨率的feature map,从而构建cost volume,连同图像1的feature map还有经过上采样的光流就可以被用来预测较高分辨率的光流残差。如下图所示:

参考:IRR论文笔记 - 知乎















 2259
2259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









