






code:diffusers/examples/community at main · huggingface/diffusers · GitHub
集成度很高,一个py文件就能整合一个模型,还在看结构
1 报错
1.路径及文件问题
改为自己的绝对路径,custom_pipeline也要改,指向py文件
motion_id = "/data/diffusers-main/checkpoint/animatediff-motion-adapter-v1-5-2"
adapter = MotionAdapter.from_pretrained(motion_id)
controlnet = ControlNetModel.from_pretrained("/data/diffusers-main/checkpoint/control_v11p_sd15_openpose", torch_dtype=torch.float16)
vae = AutoencoderKL.from_pretrained("/data/diffusers-main/checkpoint/sd-vae-ft-mse", torch_dtype=torch.float16)
# 加载预训练的运动适配器、控制网络和自编码器模型
model_id = "/data/diffusers-main/checkpoint/Realistic_Vision_V5.1_noVAE"
pipe = DiffusionPipeline.from_pretrained(
model_id,
motion_adapter=adapter,
controlnet=controlnet,
vae=vae,
# custom_pipeline="pipeline_animatediff_controlnet",
custom_pipeline="/data/diffusers-main/examples/community/pipeline_animatediff_controlnet.py",
).to(device="cuda", dtype=torch.float16)
# 创建扩散管道并加载预训练的模型,包括运动适配器、控制网络和自编码器模型pipeline_animatediff_controlnet.py文件中的主类名要改成pipeline_animatediff_controlnet

同时在anidi.py中添加
from pipeline_animatediff_controlnet import pipeline_animatediff_controlnet这样两个文件就连起来了。直接把custom_pipeline改成AnimateDiffControlNetPipeline应该也可以
2.找不到图片

这是要自己把16帧条件输入视频处理成图像吗?
拆分工具:在线GIF图片帧拆分工具 - UU在线工具 (uutool.cn)


ok了
3.torch.cuda.OutOfMemoryError
Traceback (most recent call last):
File "/data/diffusers-main/examples/community/anidi.py", line 43, in <module>
result = pipe(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/.cache/huggingface/modules/diffusers_modules/local/pipeline_animatediff_controlnet.py", line 1079, in __call__
down_block_res_samples, mid_block_res_sample = self.controlnet(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/controlnet.py", line 800, in forward
sample, res_samples = downsample_block(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/unet_2d_blocks.py", line 1160, in forward
hidden_states = attn(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/transformer_2d.py", line 392, in forward
hidden_states = block(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/attention.py", line 288, in forward
attn_output = self.attn1(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 522, in forward
return self.processor(
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 743, in __call__
attention_probs = attn.get_attention_scores(query, key, attention_mask)
File "/data/diffusers-main/.conda/lib/python3.10/site-packages/diffusers/models/attention_processor.py", line 590, in get_attention_scores
baddbmm_input = torch.empty(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 18.00 GiB (GPU 0; 11.91 GiB total capacity; 5.43 GiB already allocated; 4.75 GiB free; 6.38 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF报错的位置:
if attention_mask is None:
baddbmm_input = torch.empty(
query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device
)
beta = 0
else:
baddbmm_input = attention_mask
beta = 1在计算注意力得分时,尝试分配显存空间时出错。显存要求18G。。要并行GPU才行
尝试1.
import os
os.environ['CUDA_VISIBLE_DEVICES']='0,1'
model_id = torch.nn.DataParallel(model_id, device_ids=[0, 1])没用,还是显示只使用了GPU0
尝试2.调小参数,比如生成视频的大小/batchsize/num_inference_steps/guidance_scale
没用T T
尝试3.

最终发现,如果可以肯定没有别的问题,那一定是参数设置的还不够小

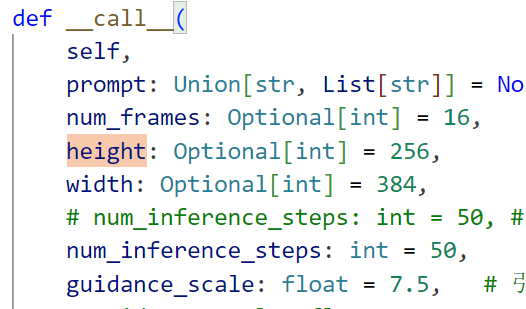
好了,主要影响显存的就是height和width,减半就行。上一次尝试没用的原因可能是有的地方的参数遗漏了,要保持所有地方同步
4.AttributeError: 'list' object has no attribute 'frames'
Traceback (most recent call last):
File "/data/diffusers-main/examples/community/anidi.py", line 64, in <module>
export_to_gif(result.frames[0], "result.gif")
AttributeError: 'list' object has no attribute 'frames'位置:

result是一个列表对象而不是具有frames属性的对象。为了解决这个问题,您需要检查代码中生成result的部分,并确定为什么result变量是一个列表。这段代码从
diffusers.utils模块中导入了export_to_gif函数,并使用该函数将推理结果的第一个帧保存为 GIF 图像。通过访问result.frames[0]来获取结果的第一个帧数据。然后,export_to_gif函数将该帧数据作为输入,将其保存为名为 "result.gif" 的 GIF 图像文件。
解决:去掉frame[0]
from diffusers.utils import export_to_gif
# export_to_gif(result.frames[0], "/data/diffusers-main/output/result.gif")
export_to_gif(result, "/data/diffusers-main/output/result.gif")complete!
不过为啥出来的脸这么诡异,怪不得默认prompt是astronauts in the space,不用画脸。。


2 结构
motion_id = "/data/diffusers-main/checkpoint/animatediff-motion-adapter-v1-5-2"
adapter = MotionAdapter.from_pretrained(motion_id)
controlnet = ControlNetModel.from_pretrained("/data/diffusers-main/checkpoint/control_v11p_sd15_openpose", torch_dtype=torch.float16)
vae = AutoencoderKL.from_pretrained("/data/diffusers-main/checkpoint/sd-vae-ft-mse", torch_dtype=torch.float16)
# 加载预训练的运动适配器、控制网络和自编码器模型
model_id = "/data/diffusers-main/checkpoint/Realistic_Vision_V5.1_noVAE"
pipe = DiffusionPipeline.from_pretrained(
model_id,
motion_adapter=adapter,
controlnet=controlnet,
vae=vae,
# custom_pipeline="pipeline_animatediff_controlnet",
custom_pipeline="/data/diffusers-main/examples/community/pipeline_animatediff_controlnet.py",
).to(device="cuda", dtype=torch.float16)
# 创建扩散管道并加载预训练的模型,包括运动适配器、控制网络和自编码器模型
pipe.scheduler = DPMSolverMultistepScheduler.from_pretrained(
model_id, subfolder="scheduler", clip_sample=False, timestep_spacing="linspace", steps_offset=1
)
# 加载预训练的扩散管道调度器
pipe.enable_vae_slicing()
# 启用自编码器切片功能
conditioning_frames = []
for i in range(1, 16 + 1):
# conditioning_frames.append(Image.open(f"frame_{i}.png"))
conditioning_frames.append(Image.open(f"/data/diffusers-main/checkpoint/GIF/frame_{i}.png"))
# 加载条件帧(conditioning frames),这些帧将作为模型的输入条件
# model_id = torch.nn.DataParallel(model_id, device_ids=[1])
model_id = torch.nn.DataParallel(model_id, device_ids=[0,1])
prompt = "astronaut in the stray space, dancing, good quality, 4k"
negative_prompt = "nsfw, bad quality, worst quality, jpeg artifacts, ugly"
result = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
# width=512,
# height=768,
width=256,
height=384,
conditioning_frames=conditioning_frames,
num_inference_steps=12,
).frames[0]
# 使用扩散管道进行推理,生成结果帧
from diffusers.utils import export_to_gif
# export_to_gif(result.frames[0], "/data/diffusers-main/output/result.gif")
export_to_gif(result, "/data/diffusers-main/output/astronaut.gif")
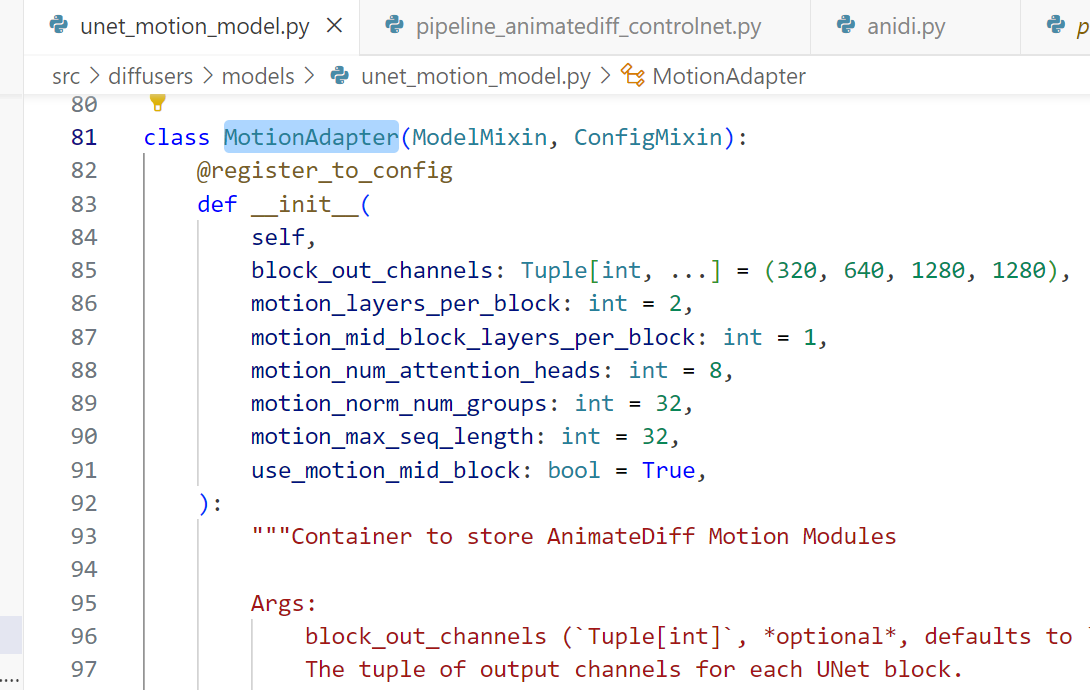
# 将结果帧导出为 GIF 图像文件ControlNetModel: 封装了ControlNet

MotionAdapter: 存储AnimateDiff运动模块的容器















 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









