






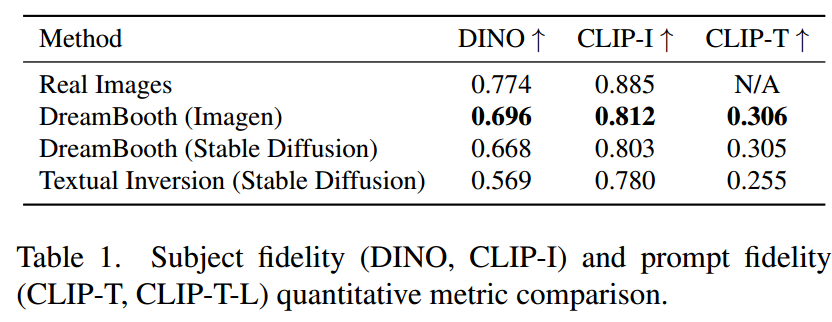
本文以DreamBooth为基准
Evaluation Metrics
- DINO:facebookresearch/dino: PyTorch code for Vision Transformers training with the Self-Supervised learning method DINO
- CLIP [Learning transferable visual models from natural language supervision]。
subject fidelity 主体保真度:评估特定物体的生成是否相似。
用 CLIP-I 和 DINO 这两个模型分别提取原始真实图片和生成图片之间的特征,然后对比这些特征之间的余弦相似度,如果相似度越高,就说明生成图片与原图的更相似,也就反映了生成物体的保真性更高。 为什么使用 DINO 和 clip 去提取这种图像特征去对比保真度?因为 DINO 和 CLIP 都是基于对比学习的方法,对比学习的损失是同一个样本之间才会是被认为正样本,会尽量让它们相似,那对于那种不同样本,即使是你同一个类下的不同样本,它也会被认为是负向样本,会尽量让特征远离,让它们的特征更不相似。因此这两个算法实际上是能够区分每一个单独个体的,因为它会让不同个体的 embedding 表达都尽量远离。
prompt fidelity 保真度:评估生成图片和输入的文本之间特征的相似度。
用 CLIP-T 分别去提取文本和图像特征,比较生成的图像和输入的文本之间的相似度,如果比较近的话,就说明图像更加遵循输入文本的控制,和输入的文本相似度更高。生成的图片里面的个体要尽可能和原图中的个体相似,又要与输入文本相似,这就是prompt fidelity。
通过计算余弦相似度矩阵,值越大,保真度越好。
Ablation Studies
Prior Preservation Loss(PPL) Ablation
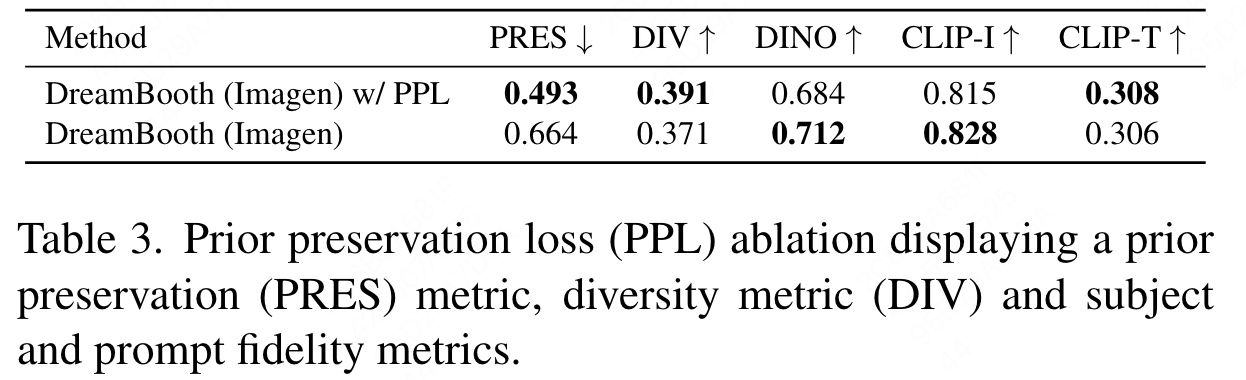
prior preservation metric (PRES) :用于评估模型语言漂移。
计算先验类别随机生成目标与真实图指定目标之间DINO embedding距离,该指标高,表明目标多样性不足,发生模式坍塌。评估方式:对于训练完后的模型,输入某一个类来生成图片,希望:不指定特定物体 和 指定特定物体之间 生成的图片越不相似越好。说明模型保持了 class prior,依然具有生成其他狗而不是这个特定狗的能力。PRES 的指标越不相似越好,即数值越低越好。
DIV (Diversity Matrix) :用于描述模型生成多样性。
用平均LPIPS进行多样性评估(DIV)。同一个 prompt 下生成的一组图片之间的平均余弦相似度距离。对于同一个prompt,如果希望生成更多的种类的样本,需要余弦相似度越低越好,说明更多样。但是注意的是,div 实际上是一个距离的概念,值越大,代表距离越远,代表模型的多样性会越好。
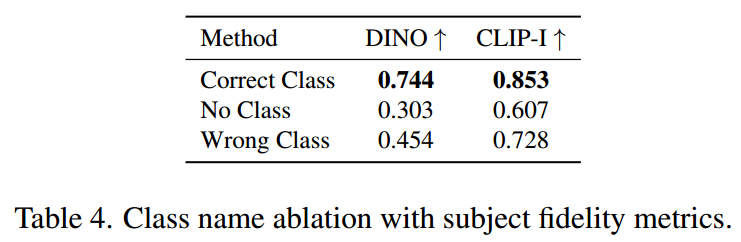
类别先验
使用类别先验,可生成各种纹理目标;使用错误类别,将导致生成奇怪物体;不使用类别先验,导致模型难以拟合,进而生成错误目标。实验结果如表4。
参考:DreamBooth 论文精读+通俗理解-CSDN博客
计算
evaluate
We collected a dataset of 30 subjects, including unique objects and pets such as backpacks, stuffed animals, dogs, cats, sunglasses, cartoons, etc. We separate each subject into two categories: objects and live subjects/pets. 21 of the 30 subjects are objects, and 9 are live subjects/pets.We provide one sample image for each of the subjects in Figure 5. Images for this dataset were collected by the authors or sourced from Unsplash. We also collected 25 prompts.
For the evaluation suite we generate four images per subject and per prompt, totaling 3,000 images. This allows us to robustly measure performances and generalization capabilities of a method. We make our dataset and evaluation protocol publicly available on the project webpage for future use in evaluating subject-driven generation.
作者的评估数据集包括 30个主题(subjects) 和 25个提示词(prompts)。每个主题和提示词组合生成 4张图片。计算方式如下:
-
30个主题,每个主题有25个提示词组合,共有 30×25=750 个组合。
-
对于每个组合生成4张图片,因此总共生成的图片数为750×4=3000 张。
要复现这个结果还蛮麻烦的。。
提示词组合如下:
Classes
subject_name,class
backpack,backpack
backpack_dog,backpack
bear_plushie,stuffed animal
berry_bowl,bowl
can,can
candle,candle
cat,cat
cat2,cat
clock,clock
colorful_sneaker,sneaker
dog,dog
dog2,dog
dog3,dog
dog5,dog
dog6,dog
dog7,dog
dog8,dog
duck_toy,toy
fancy_boot,boot
grey_sloth_plushie,stuffed animal
monster_toy,toy
pink_sunglasses,glasses
poop_emoji,toy
rc_car,toy
red_cartoon,cartoon
robot_toy,toy
shiny_sneaker,sneaker
teapot,teapot
vase,vase
wolf_plushie,stuffed animal
Prompts
Object Prompts
(25组提示,21 of the 30 subjects are objects)
prompt_list = [
'a {0} {1} in the jungle'.format(unique_token, class_token),
'a {0} {1} in the snow'.format(unique_token, class_token),
'a {0} {1} on the beach'.format(unique_token, class_token),
'a {0} {1} on a cobblestone street'.format(unique_token, class_token),
'a {0} {1} on top of pink fabric'.format(unique_token, class_token),
'a {0} {1} on top of a wooden floor'.format(unique_token, class_token),
'a {0} {1} with a city in the background'.format(unique_token, class_token),
'a {0} {1} with a mountain in the background'.format(unique_token, class_token),
'a {0} {1} with a blue house in the background'.format(unique_token, class_token),
'a {0} {1} on top of a purple rug in a forest'.format(unique_token, class_token),
'a {0} {1} with a wheat field in the background'.format(unique_token, class_token),
'a {0} {1} with a tree and autumn leaves in the background'.format(unique_token, class_token),
'a {0} {1} with the Eiffel Tower in the background'.format(unique_token, class_token),
'a {0} {1} floating on top of water'.format(unique_token, class_token),
'a {0} {1} floating in an ocean of milk'.format(unique_token, class_token),
'a {0} {1} on top of green grass with sunflowers around it'.format(unique_token, class_token),
'a {0} {1} on top of a mirror'.format(unique_token, class_token),
'a {0} {1} on top of the sidewalk in a crowded street'.format(unique_token, class_token),
'a {0} {1} on top of a dirt road'.format(unique_token, class_token),
'a {0} {1} on top of a white rug'.format(unique_token, class_token),
'a red {0} {1}'.format(unique_token, class_token),
'a purple {0} {1}'.format(unique_token, class_token),
'a shiny {0} {1}'.format(unique_token, class_token),
'a wet {0} {1}'.format(unique_token, class_token),
'a cube shaped {0} {1}'.format(unique_token, class_token)
]
Live Subject Prompts
(24组提示,9 of the 30 subjects are live subjects/pets)
prompt_list = [
'a {0} {1} in the jungle'.format(unique_token, class_token),
'a {0} {1} in the snow'.format(unique_token, class_token),
'a {0} {1} on the beach'.format(unique_token, class_token),
'a {0} {1} on a cobblestone street'.format(unique_token, class_token),
'a {0} {1} on top of pink fabric'.format(unique_token, class_token),
'a {0} {1} on top of a wooden floor'.format(unique_token, class_token),
'a {0} {1} with a city in the background'.format(unique_token, class_token),
'a {0} {1} with a mountain in the background'.format(unique_token, class_token),
'a {0} {1} with a blue house in the background'.format(unique_token, class_token),
'a {0} {1} on top of a purple rug in a forest'.format(unique_token, class_token),
'a {0} {1} wearing a red hat'.format(unique_token, class_token),
'a {0} {1} wearing a santa hat'.format(unique_token, class_token),
'a {0} {1} wearing a rainbow scarf'.format(unique_token, class_token),
'a {0} {1} wearing a black top hat and a monocle'.format(unique_token, class_token),
'a {0} {1} in a chef outfit'.format(unique_token, class_token),
'a {0} {1} in a firefighter outfit'.format(unique_token, class_token),
'a {0} {1} in a police outfit'.format(unique_token, class_token),
'a {0} {1} wearing pink glasses'.format(unique_token, class_token),
'a {0} {1} wearing a yellow shirt'.format(unique_token, class_token),
'a {0} {1} in a purple wizard outfit'.format(unique_token, class_token),
'a red {0} {1}'.format(unique_token, class_token),
'a purple {0} {1}'.format(unique_token, class_token),
'a shiny {0} {1}'.format(unique_token, class_token),
'a wet {0} {1}'.format(unique_token, class_token),
'a cube shaped {0} {1}'.format(unique_token, class_token)
]
其中{0}是唯一标识符,{1}是类别标识符
-
物体类:
- 21个object,每个主体应用25个物体提示词。产生 21×25=525 个提示词-主体组合。
-
活体类:
- 9个live subject,每个主体应用24个活体提示词。产生 9×24=216 个提示词-主体组合。
-
总图像数量:
- 如果每个提示词组合生成4张图像,则总计生成 (525+216)×4=2,964 张图像。
- 为了凑足3000张图像,可能会额外增加一些特定场景或细节的测试。
把这30种主体分一下类:
Object 类
backpack
backpack_dog
bear_plushie
berry_bowl
can
candle
clock
colorful_sneaker
duck_toy
fancy_boot
grey_sloth_plushie
monster_toy
pink_sunglasses
poop_emoji
rc_car
red_cartoon
robot_toy
shiny_sneaker
teapot
vase
wolf_plushie
Live Subject 类
cat
cat2
dog
dog2
dog3
dog5
dog6
dog7
dog8然后就是漫长的生成~可以写个代码批量训练一下,建议用lora更快些,生成的safetensors也更小(100MB),详情见:DreamBooth
CLIP-I指标计算:用clip model计算embedding然后算两个image embedding之间的cosine similarity。 有现成的库:Taited/clip-score: Quick scripts to calculate CLIP text-image similarity
如何计算可以参考:
Text2Image评价指标——CLIP Score-CSDN博客
Text2Image评价指标——CLIP Score(2)-CSDN博客
Text2Image-similary:
首先加载预训练的CLIP模型和数据处理器,然后定义了几个函数来处理图像和文本数据。get_all_folders函数:获取指定文件夹下的所有子文件夹,get_all_images函数:获取指定文件夹下的所有图像文件,get_clip_score函数:计算图像和文本之间的CLIP得分。calculate_clip_scores_for_all_categories函数:主要的处理函数,它遍历指定的图像文件夹,对每个子文件夹(即类别)下的所有图像计算CLIP得分,并计算每个类别的平均得分。
最后从文件中读取文本提示,调用calculate_clip_scores_for_all_categories函数计算所有类别的CLIP得分和平均得分,并打印出结果。
from tqdm import tqdm
from PIL import Image
import torch
import os
import numpy as np
from transformers import CLIPProcessor, CLIPModel
# 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.set_device(6)
# 加载模型
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
# 加载数据处理器
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
def get_all_folders(folder_path):
# 获取文件夹中的所有文件和文件夹
all_files = os.listdir(folder_path)
# 过滤所有的文件夹
folder_files = [file for file in all_files if os.path.isdir(os.path.join(folder_path, file))]
# 将文件夹的路径添加到一个列表中
folder_paths = [os.path.join(folder_path, folder_file) for folder_file in folder_files]
# 返回列表
return folder_paths
def get_all_images(folder_path):
# 获取文件夹中的所有文件和文件夹
all_files = os.listdir(folder_path)
# 过滤所有的图片文件
image_files = [file for file in all_files if file.endswith((".jpg", ".png", ".jpeg"))]
# 将图片文件的路径添加到一个列表中
image_paths = [os.path.join(folder_path, image_file) for image_file in image_files]
# 返回列表
return image_paths
def calculate_clip_scores_for_all_categories(images_folder_path, text_prompts):
# 获取所有的类别文件夹
category_folders = get_all_folders(images_folder_path)
# 初始化一个字典来存储每个类别的 Clip Score
category_clip_scores = {}
# 初始化一个字典来存储每个类别的平均值
category_mean_scores = {}
# 遍历每个类别文件夹
for category_folder, text_prompt in tqdm(zip(category_folders, text_prompts),total=len(category_folders),desc="Processing categories"):
# 获取类别名称
category_name = os.path.basename(category_folder)
# 获取该类别下的所有图片
images_path = get_all_images(category_folder)
# 计算该类别的 Clip Score
clip_score = get_clip_score(images_path, [text_prompt])
# 将 Clip Score 存储在字典中
category_clip_scores[category_name] = clip_score
# 计算平均值
mean_score = torch.mean(clip_score, dim=0)
# 将平均值存储在字典中
category_mean_scores[category_name] = mean_score.item() # 使用.item()将torch.Tensor转换为Python的标准数据类型
return category_clip_scores,category_mean_scores
def get_clip_score(images_path, text):
images = [Image.open(image_path) for image_path in images_path]
inputs = processor(text=text, images=images, return_tensors="pt", padding=True)
# 将输入数据移动到GPU
inputs = {name: tensor.to(device) for name, tensor in inputs.items()}
outputs = model(**inputs)
# print(outputs)
logits_per_image = outputs.logits_per_image
# print(logits_per_image, logits_per_image.shape) # 1,4
# probs = logits_per_image.softmax(dim=1)
# 计算平均值
# mean_score = torch.mean(logits_per_image,dim=0)
# print(f"CLIP-T的平均值是:{mean_score}")
return logits_per_image
# 从文件中获取文本提示
def read_prompts_from_file(file_path):
with open(file_path, 'r') as file:
prompts = file.readlines()
# 去除每行末尾的换行符
prompts = [prompt.strip() for prompt in prompts]
return prompts
# 使用函数读取文本提示
text_prompts = read_prompts_from_file('./texts/prompts.txt')
# 提示文本列表,每个类别对应一个提示文本
# text_prompts = ['a bird flying in the sky', 'a cat playing with a ball','a dog running in the park' ]
# 计算所有类别的 Clip Score 和平均值
category_clip_scores, category_mean_scores = calculate_clip_scores_for_all_categories("./samples_images", text_prompts)
# 打印结果
for category, clip_score in category_clip_scores.items():
clip_score_list = clip_score.tolist()
for score in clip_score_list:
print(f"Category: {category}, Clip Score: {score[0]:.4f}")
for category, mean_score in category_mean_scores.items():
print(f"Category: {category}, Mean Score: {mean_score:.4f}")
Image2Image-similary:
calculate_clip_scores_for_all_categories,遍历指定的图像文件夹,对每个子文件夹(即类别)下的所有图像计算CLIP得分,并计算每个类别的平均得分。最后从文件中读取了文本提示,然后计算所有类别的CLIP得分和平均得分,并打印出结果。
import torch
from tqdm import tqdm
from transformers import CLIPImageProcessor, CLIPModel, CLIPTokenizer
# from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import os
import cv2
# 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.set_device(6)
# Load the CLIP model
model_ID = "openai/clip-vit-large-patch14"
model = CLIPModel.from_pretrained(model_ID).to(device)
preprocess = CLIPImageProcessor.from_pretrained(model_ID)
def get_all_folders(folder_path):
# 获取文件夹中的所有文件和文件夹
all_files = os.listdir(folder_path)
# 过滤所有的文件夹
folder_files = [file for file in all_files if os.path.isdir(os.path.join(folder_path, file))]
# 将文件夹的路径添加到一个列表中
folder_paths = [os.path.join(folder_path, folder_file) for folder_file in folder_files]
# 返回列表
return folder_paths
def get_all_images(folder_path):
# 获取文件夹中的所有文件和文件夹
all_files = os.listdir(folder_path)
# 过滤所有的图片文件
image_files = [file for file in all_files if file.endswith((".jpg", ".png", ".jpeg"))]
# 将图片文件的路径添加到一个列表中
image_paths = [os.path.join(folder_path, image_file) for image_file in image_files]
# 返回列表
return image_paths
# Define a function to load an image and preprocess it for CLIP
def load_and_preprocess_image(image_path):
# Load the image from the specified path
image = Image.open(image_path)
# 使用预先定义的函数preprocess函数对图像进行预处理
image = preprocess(image, return_tensors="pt")
# 返回预处理后的图像
return image
def calculate_img_scores_for_all_images(images_folder_path1, images_folder_path2):
# 获取所有的类别文件夹
folders1 = get_all_folders(images_folder_path1)
folders2 = get_all_folders(images_folder_path2)
# 初始化一个字典来存储每个类别的 img Score
category_img_scores = {}
# 遍历每个类别文件夹
for folder1, folder2 in tqdm(zip(folders1, folders2),total=len(folders1),desc="Processing"):
# 获取类别名称
name = os.path.basename(folder1)
# 获取该类别下的所有图片
images_path1 = get_all_images(folder1)
images_path2 = get_all_images(folder2)
# 初始化一个变量来存储该类别的所有图像分数
img_scores = 0
# 遍历每个图像路径,并计算其与其他的图像的分数
for image1_path in tqdm(images_path1,total=len(images_path1),desc="Processing images"):
# img_score_mean = 0
for image2_path in images_path2:
img_score = clip_img_score(image1_path,image2_path)
img_scores += img_score
# img_score_mean +=img_score
# 计算该类别的平均分数,并将 Clip Score 存储在字典中
category_img_scores[name] = img_scores / (len(images_path1) * len(images_path2))
return category_img_scores
def clip_img_score(img1_path, img2_path):
# Load the two samples_images and preprocess them for CLIP
image_a = load_and_preprocess_image(img1_path)["pixel_values"].to(device)
image_b = load_and_preprocess_image(img2_path)["pixel_values"].to(device)
# Calculate the embeddings for the samples_images using the CLIP model
with torch.no_grad():
# 使用CLIP 模型计算两个图像的嵌入
embedding_a = model.get_image_features(image_a)
embedding_b = model.get_image_features(image_b)
# Calculate the cosine similarity between the embeddings
# 通过计算余弦相似度来比较两个嵌入的相似性
similarity_score = torch.nn.functional.cosine_similarity(embedding_a, embedding_b)
# 返回相似度分数,这个分数越高,表示两个图像越相似
return similarity_score.item()
images_path1 = "./samples_images"
images_path2 = "./regulation_images"
# 计算图像的相似度分数
img_scores = calculate_img_scores_for_all_images(images_path1, images_path2)
# 打印图像的相似度分数
for category, score in img_scores.items():
print(f"Image similarity score for {category}: {score:.4f}")CLIP计算参考:
CLIP计算图片与文本相似度(多幅图片与一个文本)_计算文本和图片的clip-CSDN博客
Image Search — Sentence Transformers documentation
CLIP-T score
import os
from PIL import Image
import numpy as np
import torch
import clip
# 加载 CLIP 模型
model, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
your_image_folder = "/data/diffusers/output/dog"
your_texts = ["A photo of dog in a bucket"]
images = []
for filename in os.listdir(your_image_folder):
if filename.endswith(".png") or filename.endswith(".jpg"):
path = os.path.join(your_image_folder, filename)
image = Image.open(path).convert("RGB")
images.append(preprocess(image))
# 图像和文本预处理
image_input = torch.tensor(np.stack(images)).cuda()
text_tokens = clip.tokenize(your_texts).cuda()
# 计算特征
with torch.no_grad():
image_features = model.encode_image(image_input).float() # 图像的 embedding 维度512
text_features = model.encode_text(text_tokens).float() # 文本的 embedding
# 归一化特征
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
# 计算余弦相似度
similarity = (text_features.cpu().numpy() @ image_features.cpu().numpy().T)
# 计算平均余弦相似度
average_similarity = np.mean(similarity, axis=1)
# Average cosine similarity
print('CLIP-T score:', average_similarity)
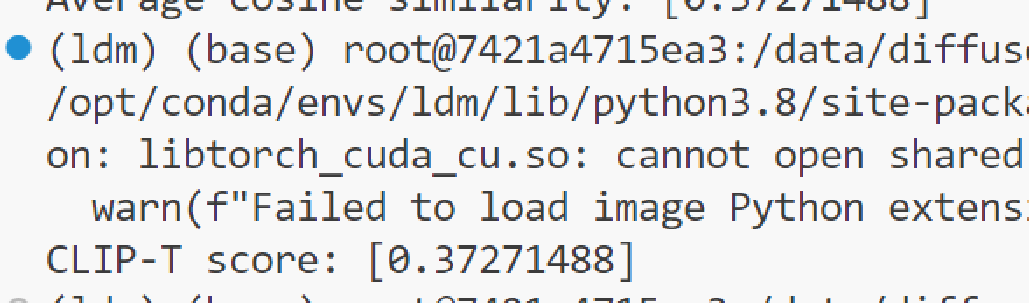
这里计算的是指定文件夹下所有生成图像与文本之间的emb余弦相似度的平均值
CLIP-I score
import os
import torch
import clip
from PIL import Image
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 真实图像
real_image = preprocess(Image.open("/data/diffusers/pic/dog/02.jpg")).unsqueeze(0).to(device)
generated_image_embeddings = []
# 生成图像文件夹路径
generated_image_folder = "/data/diffusers/output/dog"
# 加载并预处理生成图像
for filename in os.listdir(generated_image_folder):
if filename.endswith(".png") or filename.endswith(".jpg"):
image_path = os.path.join(generated_image_folder, filename)
generated_image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)
# 提取生成图像的特征向量
with torch.no_grad():
generated_image_embedding = model.encode_image(generated_image).cpu().numpy()
generated_image_embeddings.append(generated_image_embedding)
# 将所有生成图像的 embedding 组合成一个数组
generated_image_embeddings = np.vstack(generated_image_embeddings)
# 提取真实图像的特征向量
with torch.no_grad():
real_image_embedding = model.encode_image(real_image).cpu().numpy()
# 计算余弦相似度
cosine_similarity_scores = cosine_similarity(generated_image_embeddings, real_image_embedding)
# 计算平均余弦相似度
average_cosine_similarity = np.mean(cosine_similarity_scores)
print("CLIP-I Score:", average_cosine_similarity)
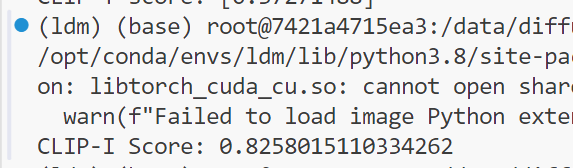
这里计算的是指定文件夹下所有生成图像与真实图像之间的emb余弦相似度的平均值
CLIP-I Score: 0.82
DINO score
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import torch.nn as nn
import torch
import os
# 定义环境
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
# 加载 dinov2 模型
model_folder = '/data/diffusers/model/dinov2-base'
processor = AutoImageProcessor.from_pretrained(model_folder)
model = AutoModel.from_pretrained(model_folder).to(device)
# 加载并处理真实图像
real_image = Image.open('/data/diffusers/pic/dog/02.jpg')
with torch.no_grad():
inputs1 = processor(images=real_image, return_tensors="pt").to(device)
outputs1 = model(**inputs1)
image_features1 = outputs1.last_hidden_state
image_features1 = image_features1.mean(dim=1)
# 初始化相似度计算
cos = nn.CosineSimilarity(dim=0)
# 设置生成图像文件夹路径
generated_image_folder = '/data/diffusers/output/dog'
# 初始化相似度总和和计数器
total_similarity = 0
count = 0
# 遍历生成图像文件夹并计算相似度
for filename in os.listdir(generated_image_folder):
if filename.endswith(".png") or filename.endswith(".jpg"):
image_path = os.path.join(generated_image_folder, filename)
# 加载生成图像并处理
generated_image = Image.open(image_path)
with torch.no_grad():
inputs2 = processor(images=generated_image, return_tensors="pt").to(device)
outputs2 = model(**inputs2)
image_features2 = outputs2.last_hidden_state
image_features2 = image_features2.mean(dim=1)
# 计算相似度
sim = cos(image_features1[0], image_features2[0]).item()
sim = (sim + 1) / 2 # 将相似度值归一化到 [0, 1] 范围
# 累加相似度值和计数
total_similarity += sim
count += 1
print(f'real_image和{filename}的相似度值: {sim}')
# 计算平均相似度并输出
if count > 0:
average_similarity = total_similarity / count
print(f'DINO score: {average_similarity}')
else:
print('没有找到生成图像。')
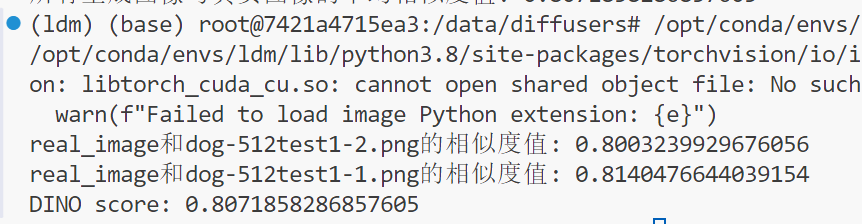
这里计算的是指定文件夹下所有生成图像与真实图像之间的emb余弦相似度的平均值

















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









