







一、相关指标
1. PSNR
峰值信噪比(PSNR,Peak Signal-to-Noise Ratio)是一种用于衡量图像质量的指标,通常用于评价图像压缩、超分辨率、图像复原等算法的效果。它通过衡量重建图像与参考图像之间的差异,来评估图像的质量。PSNR 的单位是 dB(分贝),数值越大表示图像质量越高,重建图像越接近参考图像。在通常的RGB图像中,PSNR的最大值(MSE最小,为0时)为20*lg(255)≈48左右。
(1)高于40dB:说明图像质量极好(即非常接近原始图像)
(2)30—40dB:通常表示图像质量是好的(即失真可以察觉但可以接受)
(3)20—30dB:说明图像质量差
(4)低于20dB:图像质量不可接受
PSNR = 10 ⋅ log 10 ( MAX 2 MSE ) = 20 ⋅ log 10 ( MAX MSE ) = 20 ⋅ log 10 MAX − 10 ⋅ log 10 MSE \text{PSNR} = 10 \cdot \log_{10} \left( \frac{\text{MAX}^2}{\text{MSE}} \right) \\ ~\\ = 20 \cdot \log_{10} \left( \frac{\text{MAX}}{\sqrt \text{MSE}} \right)\\ ~\\ = 20 \cdot \log_{10}{\text{MAX}} - 10 \cdot \log_{10}{\text{MSE}} PSNR=10⋅log10(MSEMAX2) =20⋅log10(MSEMAX) =20⋅log10MAX−10⋅log10MSE
其中:
- MAX:图像像素值的最大可能值。对于 8-bit 图像来说,MAX = 255,因为 8-bit 图像的像素值范围是 [0, 255]。
- MSE(均方误差,Mean Squared Error):它是重建图像和参考图像之间像素差异的平方平均值。MSE 越小,表示重建图像和参考图像越接近。公式如下:
MSE = 1 m n ∑ i = 0 m − 1 ∑ j = 0 n − 1 ( I 1 ( i , j ) − I 2 ( i , j ) ) 2 \text{MSE} = \frac{1}{mn} \sum_{i=0}^{m-1} \sum_{j=0}^{n-1} \left( I_1(i,j) - I_2(i,j) \right)^2 MSE=mn1i=0∑m−1j=0∑n−1(I1(i,j)−I2(i,j))2
其中:
- I 1 ( i , j ) I_1(i,j) I1(i,j)是参考图像(Ground Truth)在像素位置 ( i , j ) (i,j) (i,j)的像素值
- I 2 ( i , j ) I_2(i,j) I2(i,j)是重建图像在像素位置 ( i , j ) (i,j) (i,j)的像素值
- m m m和 n n n分别是图像发宽度和高度
对于多通道图像(例如 RGB 图像),我们需要分别计算每个通道的均方误差(MSE),然后将其取平均值。对于一个 𝐶 通道的图像,计算 MSE 的公式会有所调整,包含所有通道的像素误差。
MSE = 1 C ⋅ m ⋅ n ∑ c = 1 C ∑ i = 0 m − 1 ∑ j = 0 n − 1 ( I 1 c ( i , j ) − I 2 c ( i , j ) ) 2 \text{MSE} = \frac{1}{C \cdot m \cdot n} \sum_{c=1}^{C} \sum_{i=0}^{m-1} \sum_{j=0}^{n-1} \left( I_1^c(i,j) - I_2^c(i,j) \right)^2 MSE=C⋅m⋅n1c=1∑Ci=0∑m−1j=0∑n−1(I1c(i,j)−I2c(i,j))2
其中:
- 𝐶 :图像的通道数(对于RGB图像, 𝐶 = 3)
- I 1 c ( i , j ) I_1^c (i,j) I1c(i,j)和 I 2 c ( i , j ) I_2^c (i,j) I2c(i,j):第 c 个通道中,参考图像 I 1 I_1 I1和重建图像 I 2 I_2 I2在像素位置 ( i , j ) (i,j) (i,j)的像素值
pytorch 计算PSNR代码:Peak Signal-to-Noise Ratio (PSNR)
接口说明:classtorchmetrics.image.PeakSignalNoiseRatio(data_range=None,base=10.0, reduction=‘elementwise_mean’, dim=None, **kwargs)
>>> from torchmetrics.image import PeakSignalNoiseRatio
>>> psnr = PeakSignalNoiseRatio()
>>> preds = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
>>> target = torch.tensor([[3.0, 2.0], [1.0, 0.0]])
>>> psnr(preds, target)
tensor(2.5527)
python计算代码
import os
import torch
from torchmetrics.image import PeakSignalNoiseRatio
from PIL import Image
import numpy as np
def load_image(image_path):
"""Load an image and convert it to a tensor."""
image = Image.open(image_path).convert('RGB') # Convert to RGB
image = np.array(image) # Convert to numpy array
image = torch.tensor(image, dtype=torch.float32) # Convert to tensor
image /= 255.0 # Normalize to [0, 1]
return image
def calculate_psnr(lr_folder, hr_folder, output_file):
"""Calculate PSNR for all image pairs in the specified folders."""
psnr_calculator = PeakSignalNoiseRatio()
results = []
total_psnr = 0.0
count = 0
# Get lists of image files in both folders
lr_images = sorted(os.listdir(lr_folder))
hr_images = sorted(os.listdir(hr_folder))
# Ensure the number of images matches
if len(lr_images) != len(hr_images):
raise ValueError("The number of images in both folders must match.")
# Iterate through the image pairs
for lr_image, hr_image in zip(lr_images, hr_images):
lr_path = os.path.join(lr_folder, lr_image)
hr_path = os.path.join(hr_folder, hr_image)
# Load images
lr = load_image(lr_path)
hr = load_image(hr_path)
# Resize LR image to match HR image dimensions if necessary
if lr.shape[:2] != hr.shape[:2]: # Only check height and width
lr = torch.nn.functional.interpolate(
lr.permute(2, 0, 1).unsqueeze(0), # Change to (1, C, H, W)
size=(hr.shape[0], hr.shape[1]), # Target size: (H, W)
mode='bilinear',
align_corners=False
).squeeze(0).permute(1, 2, 0) # Change back to (H, W, C)
# Check shapes
if lr.shape != hr.shape:
print(f"Shape mismatch: {lr.shape} vs {hr.shape}")
continue # Skip this pair if sizes do not match
# Calculate PSNR
psnr_value = psnr_calculator(lr, hr).item()
results.append((lr_image, psnr_value))
total_psnr += psnr_value
count += 1
# Calculate average PSNR if there are valid results
average_psnr = total_psnr / count if count > 0 else 0
# Write results to output file
with open(output_file, 'w') as f:
for image_name, psnr_value in results:
f.write(f"{image_name}: {psnr_value:.2f} dB\n")
f.write(f"Average PSNR: {average_psnr:.2f} dB\n")
# Example usage
lr_folder = 'path/to/lr/images' # Replace with your low-res images folder path
hr_folder = 'path/to/hr/images' # Replace with your high-res images folder path
output_file = 'psnr_results.txt' # Output file to save results
calculate_psnr(lr_folder, hr_folder, output_file)
2. SSIM
结构相似性指数(Structural Similarity Index, SSIM)是一种用于衡量两幅图像之间相似度的指标。与传统的均方误差(MSE)或峰值信噪比(PSNR)不同,SSIM更关注图像的结构信息,从而更好地反映人类视觉系统的感知。
SSIM通过以下三个方面来对两幅图像的相似性进行评估,即
- 亮度(Luminance)
- 对比度(Contrast)
- 结构 (Structure)
算法的框图基本如下:
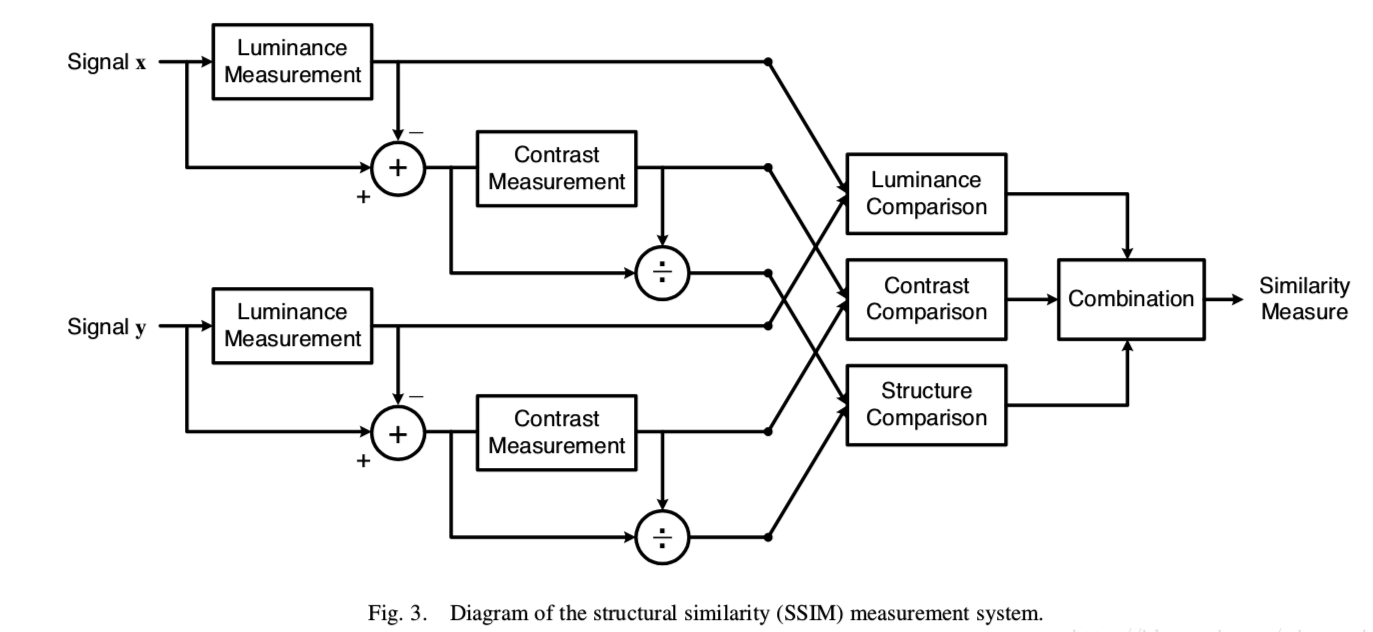
基本流程为:
(1)对于输入的x和y,首先计算出(亮度测量)luminance measurement,进行比对,得到第一个相似性有关的评价;
(2)再减去luminance的影响,计算(对比度测量)contrast measurement,比对,得到第二个评价;
(3)再用上一步的结果除掉对比度的影响,再进行structure的比对。最后将结果combine,得到最终的评价结果。
以下是用于计算SSIM时的主要参数和相关公式,分别是亮度的均值(𝜇)和标准差(σ),以及协方差的计算公式:
1. 均值(𝜇)
- 图像 𝑥 和 𝑦 的局部均值,通常通过在小窗口内对像素值进行平均来计算。
- 计算公式为:
μ x = 1 N ∑ i = 1 N x i \mu_x = \frac{1}{N} \sum_{i=1}^{N} x_i μx=N1i=1∑Nxi μ y = 1 N ∑ i = 1 N y i \mu_y = \frac{1}{N} \sum_{i=1}^{N} y_i μy=N1i=1∑Nyi
其中 μ x \mu_x μx和 μ y \mu_y μy分别为图像 𝑥 和 𝑦 在一个小窗口内的均值,𝑁 是窗口中的像素数量。
2 标准差(σ)
- 图像 𝑥 和 𝑦 的标准差,表示图像的对比度。
- 计算公式为:
σ x = 1 N − 1 ∑ i = 1 N ( x i − μ x ) 2 \sigma_x = \sqrt{\frac{1}{N-1} \sum_{i=1}^{N} \left( x_i - \mu_x \right)^2} σx=N−11i=1∑N(xi−μx)2 σ y = 1 N − 1 ∑ i = 1 N ( y i − μ y ) 2 \sigma_y = \sqrt{\frac{1}{N-1} \sum_{i=1}^{N} \left( y_i - \mu_y \right)^2} σy=N−11i=1∑N(yi−μy)2
3 协方差(𝜎𝑥𝑦)
- 图像 𝑥 和 𝑦 的协方差,反映它们的线性关系。
- 计算公式为:
σ x y = 1 N − 1 ∑ i = 1 N ( x i − μ x ) ( y i − μ y ) \sigma_{xy} = \frac{1}{N-1} \sum_{i=1}^{N} \left( x_i - \mu_x \right) \left( y_i - \mu_y \right) σxy=N−11i=1∑N(xi−μx)(yi−μy)
上面的计算我们在实际应用的时候一般不这样去逐像素计算,一般采用高斯核函数(即高斯卷积)计算图像的均值、方差以及协方差,而不是采用遍历像素点的方式,以换来更高的效率。
具体的计算公式如下所示:
(1)亮度luminance测量值——实际上是
μ
x
\mu_x
μx和
μ
y
\mu_y
μy的函数
L
(
x
,
y
)
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
L(x, y) = \frac{2\mu_x \mu_y + C_1}{\mu_x^2 + \mu_y^2 + C_1}
L(x,y)=μx2+μy2+C12μxμy+C1
(2)对比度contrast测量值——实际上是
σ
x
σ_x
σx和
σ
y
σ_y
σy的函数
C
(
x
,
y
)
=
2
σ
x
σ
y
+
C
2
σ
x
2
+
σ
y
2
+
C
2
C(x, y) = \frac{2\sigma_x \sigma_y + C_2}{\sigma_x^2 + \sigma_y^2 + C_2}
C(x,y)=σx2+σy2+C22σxσy+C2
(3)结构structure测量值——实际上是
σ
x
y
σ_{xy}
σxy与
σ
x
σ_x
σx和
σ
y
σ_y
σy的函数
S
(
x
,
y
)
=
σ
x
y
+
C
3
σ
x
σ
y
+
C
3
S(x, y) = \frac{\sigma_{xy} + C_3}{\sigma_x \sigma_y + C_3}
S(x,y)=σxσy+C3σxy+C3
(4) SSIM综合公式:
S
S
I
M
(
x
,
y
)
=
(
L
(
x
,
y
)
)
α
⋅
(
C
(
x
,
y
)
)
β
⋅
(
S
(
x
,
y
)
)
γ
SSIM(x, y) = \left( L(x, y) \right)^\alpha \cdot \left( C(x, y) \right)^\beta \cdot \left( S(x, y) \right)^\gamma
SSIM(x,y)=(L(x,y))α⋅(C(x,y))β⋅(S(x,y))γ
α,β,γ 分别代表了不同特征在SSIM衡量中的占比,当都为1时,有:
S
S
I
M
(
x
,
y
)
=
(
2
μ
x
μ
y
+
C
1
)
(
2
σ
x
σ
y
+
C
2
)
(
σ
x
y
+
C
3
)
(
μ
x
2
+
μ
y
2
+
C
1
)
(
σ
x
2
+
σ
y
2
+
C
2
)
(
σ
x
σ
y
+
C
3
)
SSIM(x, y) = \frac{(2\mu_x \mu_y + C_1)(2\sigma_x \sigma_y + C_2)(\sigma_{xy} + C_3)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)(\sigma_x \sigma_y + C_3)}
SSIM(x,y)=(μx2+μy2+C1)(σx2+σy2+C2)(σxσy+C3)(2μxμy+C1)(2σxσy+C2)(σxy+C3)
C
3
=
C
2
/
2
C_3 = C_2/2
C3=C2/2时
S
S
I
M
(
x
,
y
)
=
(
2
μ
x
μ
y
+
C
1
)
(
2
σ
x
y
+
C
2
)
(
μ
x
2
+
μ
y
2
+
C
1
)
(
σ
x
2
+
σ
y
2
+
C
2
)
SSIM(x, y) = \frac{(2\mu_x \mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}
SSIM(x,y)=(μx2+μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2)
SSIM的取值范围为[-1,1],约接近1表示效果越好,大部分sota模型都是在0.8~0.9左右【具体与数据集相关】
补充:
但是由于SSIM应该应用于局部,这是为了拟合人类视觉的局部性的特点,因此实际上我们用 mean-SSIM或者MSSIM,对各个local window的SSIM求平均。什么意思呢?
实际上就是先将一副图像划分成一些区域,对每一个区域求一个SSIM的值,然后一幅图像上面的所有区域的SSIM的平均值作为整个图像的SSIM值。
pytorch 计算MULTI-SCALE SSIM代码 (基于多尺度计算ssim)
torchmetrics.image 中。MultiScaleStructuralSimilarityIndexMeasure(gaussian_kernel=True, kernel_size=11, sigma=1.5, reduction=‘elementwise_mean’, data_range=无, k1=0.01, k2=0.03, betas=(0.0448, 0.2856, 0.3001, 0.2363, 0.1333), normalize=‘relu’, **kwargs)
>>> from torch import rand
>>> from torchmetrics.image import MultiScaleStructuralSimilarityIndexMeasure
>>> preds = torch.rand([3, 3, 256, 256])
>>> target = preds * 0.75
>>> ms_ssim = MultiScaleStructuralSimilarityIndexMeasure(data_range=1.0)
>>> ms_ssim(preds, target)
tensor(0.9628)
python代码
import os
import torch
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
from skimage.metrics import structural_similarity as ssim
import numpy as np
# 图像转换:将PIL图像转换为PyTorch张量
transform = transforms.Compose([
transforms.ToTensor(), # 转换为 [0, 1] 范围内的浮点型张量
transforms.Lambda(lambda x: x * 255) # 恢复到 [0, 255] 范围
])
def calculate_ssim(img1, img2):
"""
计算两个图像之间的SSIM值
:param img1: 原始图像,PyTorch张量
:param img2: 超分辨率图像,PyTorch张量
:return: SSIM值
"""
# 转换为 NumPy 数组,并确保为单通道灰度图像
img1_np = img1.squeeze().cpu().numpy().astype(np.uint8) # 去掉batch维度,并转换为NumPy
img2_np = img2.squeeze().cpu().numpy().astype(np.uint8) # 同样处理超分辨率图像
# 计算 SSIM
ssim_value, _ = ssim(img1_np, img2_np, full=True)
return ssim_value
def batch_calculate_ssim(lr_dir, sr_dir, output_file):
lr_files = sorted(os.listdir(lr_dir)) # 低分辨率图像的文件名
sr_files = sorted(os.listdir(sr_dir)) # 超分辨率图像的文件名
ssim_list = []
with open(output_file, 'w') as f:
# 遍历文件夹中的每对图像
for lr_file, sr_file in zip(lr_files, sr_files):
lr_path = os.path.join(lr_dir, lr_file)
sr_path = os.path.join(sr_dir, sr_file)
# 读取低分辨率图像和超分辨率图像
lr_image = Image.open(lr_path).convert('L') # 将图像转换为灰度图像
sr_image = Image.open(sr_path).convert('L') # 同样处理超分辨率图像
# 转换为PyTorch张量
lr_image_tensor = transform(lr_image).unsqueeze(0) # 添加batch维度
sr_image_tensor = transform(sr_image).unsqueeze(0) # 添加batch维度
# 获取低分辨率图像的尺寸
lr_size = lr_image_tensor.shape[-2:] # (height, width)
# 调整超分辨率图像的大小,使其与低分辨率图像一致
sr_image_resized = F.interpolate(sr_image_tensor, size=lr_size, mode='bilinear', align_corners=False)
# 计算 SSIM
ssim_value = calculate_ssim(lr_image_tensor, sr_image_resized)
ssim_list.append(ssim_value)
# 写入每张图像的 SSIM
f.write(f"Image {lr_file} -> {sr_file}: SSIM = {ssim_value:.4f}\n")
# 统计所有图像的平均 SSIM
average_ssim = sum(ssim_list) / len(ssim_list) if ssim_list else 0
f.write(f"\nAverage SSIM: {average_ssim:.4f}\n")
return ssim_list, average_ssim
# 文件夹路径
low_res_folder = 'path_to_low_resolution_images' # 低分辨率图像文件夹
super_res_folder = 'path_to_super_resolution_images' # 超分辨率图像文件夹
output_file = 'ssim_results.txt' # 保存结果的文件
# 批量计算 SSIM 并保存结果到txt文件
ssim_values, avg_ssim = batch_calculate_ssim(low_res_folder, super_res_folder, output_file)
# 输出结果到控制台
for i, ssim_val in enumerate(ssim_values):
print(f"Image {i+1}: SSIM = {ssim_val:.4f}")
print(f"Average SSIM: {avg_ssim:.4f}")
3. Mean SSIM
Mean SSIM(MS-SSIM)是通过在图像上以滑动窗口的方式计算局部SSIM值,并将这些值进行平均来评估整张图像的质量。下面是计算Mean SSIM的基本步骤和公式。
计算步骤
- 选择窗口大小:定义一个窗口大小 𝑊(例如 8×8 或 11×11)。
- 滑动窗口:在图像上以步长 𝑆 滑动窗口,遍历整个图像。
- 计算局部SSIM:对于每个窗口,计算该窗口内的SSIM值。
- 平均计算:将所有局部SSIM值取平均,得到Mean SSIM。
公式
Mean SSIM的计算公式如下:
MS-SSIM
(
x
,
y
)
=
1
N
∑
k
=
1
N
S
S
I
M
(
x
k
,
y
k
)
\text{MS-SSIM}(x, y) = \frac{1}{N} \sum_{k=1}^{N} SSIM(x_k, y_k)
MS-SSIM(x,y)=N1k=1∑NSSIM(xk,yk)
其中:
𝑁 是窗口的总数。
S
S
I
M
(
x
k
,
y
k
)
SSIM(x_k, y_k)
SSIM(xk,yk)是在窗口
k
k
k 内计算的SSIM值。
4. LPIPS
Learned Perceptual Image Patch Similarity (LPIPS) 是一种用于图像相似度评估的指标,旨在更好地反映人类的视觉感知。LPIPS 通过计算图像在特定深度神经网络(如 VGG、AlexNet 等)中提取的特征之间的差异,从而实现比传统像素级指标(如均方误差 MSE 和峰值信噪比 PSNR)更符合人类感知的相似度度量。LPIPS的取值范围为[0,1],约接近0表示效果越好,大部分sota模型都是在0.2~0.26左右
LPIPS 的核心思想
LPIPS 的基本思想是将图像看作在特征空间中的点,通过测量这些特征之间的距离来评估图像的相似性。LPIPS 的主要步骤如下:
- 特征提取:
- 通过预训练的卷积神经网络(如 VGG、AlexNet)提取输入图像的特征。
- 通常会使用网络中的多个层的特征,特别是中间层的特征,来捕捉图像的不同细节。
- 特征比较:
- 计算两张图像在特征空间中的差异。这是通过将它们的特征向量进行比较来实现的。
- 归一化和加权:
- 使用特定的权重对不同层的特征进行加权,以便在感知相似度计算中强调更重要的特征。
LPIPS 的公式
LPIPS 的计算公式通常可以表示为:
LPIPS
(
x
,
y
)
=
∑
l
w
l
⋅
∥
ϕ
l
(
x
)
−
ϕ
l
(
y
)
∥
2
2
\text{LPIPS}(x, y) = \sum_{l} w_l \cdot \| \phi_l(x) - \phi_l(y) \|_2^2
LPIPS(x,y)=l∑wl⋅∥ϕl(x)−ϕl(y)∥22
pytorch 计算LPIPS 代码
classtorchmetrics.image.lpip.LearnedPerceptualImagePatchSimilarity(net_type=‘alex’, reduction=‘mean’, normalize=False, **kwargs)
>>> from torch import rand
>>> from torchmetrics.image.lpip import LearnedPerceptualImagePatchSimilarity
>>> lpips = LearnedPerceptualImagePatchSimilarity(net_type='squeeze')
>>> # LPIPS needs the images to be in the [-1, 1] range.
>>> img1 = (rand(10, 3, 100, 100) * 2) - 1
>>> img2 = (rand(10, 3, 100, 100) * 2) - 1
>>> lpips(img1, img2)
tensor(0.1024)
5. CLIP-IQA
CLIP Image Quality Assessment (CLIP-IQA),该指标基于 CLIP 模型,该模型是一种在各种(图像、文本)对上训练的神经网络,能够生成图像和文本的矢量表示,如果图像和文本在语义上相似,则该矢量表示相似。
该指标通过计算用户提供的图像和预定义提示之间的余弦相似度来工作。提示总是以“正”和“负”成对出现,例如“好照片”和“坏照片”。通过计算图像嵌入与“正”和“负”提示之间的相似度,该指标可以确定图像与哪个提示更相似。然后,该指标返回图像与第一个提示比与第二个提示更相似的概率。
内置提示符包括:
- quality: “好照片” vs “差照片。”
- brightness: “明亮的照片。” 与 “Dark photo.”
- noisiness:“干净的照片。”与“噪点的照片”。
- colorfullness: “彩色照片。” vs “沉闷的照片。”
- sharpness: “清晰的照片。” vs “照片模糊”。
- contrast: “高对比度照片。” 与 “Low contrast photo.”
- complexity: “复杂照片。” 与 “Simple photo.”
- natural: “自然照片。” 与 “合成照片.”
- happy: “Happy photo.” vs “Sad photo.”
- scary: “可怕的照片。” vs “Peaceful photo.”
- new:“新照片”与“旧照片”。
- warm: “暖照片。” vs “冷照片。”
- real: “真实照片” 与 “抽象照片.”
- beautiful: “美丽的照片。” vs “丑陋的照片”。
- lonely: “Lonely photo.” 与 “Sociable photo.”
- relaxing: “放松的照片”与“压力大的照片”。
pytorch 计算[CLIP-IQA 代码]
torchmetrics.multimodal 的 TorchMetrics.multimodal 中。CLIPImageQualityAssessment(model_name_or_path=‘clip_iqa’, data_range=1.0, prompts=(‘quality’,), **kwargs)
- 单个提示:
>>> from torch import randint
>>> from torchmetrics.multimodal import CLIPImageQualityAssessment
>>> imgs = randint(255, (2, 3, 224, 224)).float() ##生成了两张尺寸为224×224 的随机图像,每张图像有 3 个通道(即 RGB 格式)。
>>> metric = CLIPImageQualityAssessment()
>>> metric(imgs) ## 调用后会返回一个张量,表示每张图像的 CLIP 图像质量评估分数。
tensor([0.8894, 0.8902])
- 多个提示:
>>> from torch import randint
>>> from torchmetrics.multimodal import CLIPImageQualityAssessment
>>> imgs = randint(255, (2, 3, 224, 224)).float()
>>> metric = CLIPImageQualityAssessment(prompts=("quality", "brightness")) ## metric 是 CLIPImageQualityAssessment 的实例,并指定了 prompts=("quality", "brightness"),即评价指标包括“质量”和“亮度”。
>>> metric(imgs)
{'quality': tensor([0.8693, 0.8705]), 'brightness': tensor([0.5722, 0.4762])}
- 定义提示。必须始终是长度为 2 的 Tuples,带有正提示和负提示。
>>> from torch import randint
>>> from torchmetrics.multimodal import CLIPImageQualityAssessment
>>> imgs = randint(255, (2, 3, 224, 224)).float()
>>> metric = CLIPImageQualityAssessment(prompts=(("Super good photo.", "Super bad photo."), "brightness")) ## 第一个 prompt 是元组 ("Super good photo.", "Super bad photo."),表示评估图像是否符合“超级好照片”这一属性。
## 第二个 prompt 是字符串 "brightness",表示对图像亮度的评价。
>>> metric(imgs)
{'user_defined_0': tensor([0.9578, 0.9654]), 'brightness': tensor([0.5495, 0.5764])}
‘user_defined_0’ 的值接近 1,表示这两张图像较为符合“Super good photo.”的描述。
‘brightness’ 值在 0.5 附近,表明图像在亮度描述上处于中等水平。
6. MUSIQ
MUSIQ(Multi-Scale Image Quality)指标是一种用于图像质量评估的深度学习模型,专为无参考图像质量评估(NR-IQA)任务设计。与传统的图像质量评估方法不同,MUSIQ 不需要任何“参考”图像,而是基于多尺度特征和深度学习模型自动判断图像的质量。这种方法尤其适合评估风景、肖像等高分辨率图像的整体质量。
MUSIQ的特点
- 多尺度特征提取:MUSIQ 使用多尺度方法处理图像,即它通过不同的分辨率来评估图像特征。这种方法模仿了人眼在不同观察尺度下的视觉效果,能够捕捉图像的细节、颜色、纹理等丰富特征。
- 无参考:MUSIQ 的评分不需要对比标准参考图像,因此可以独立评估图像质量。传统的图像质量评估指标(如 PSNR、SSIM)往往需要参考图像,而 MUSIQ 则可以独立完成质量预测。
- 基于视觉内容的模型优化:MUSIQ 使用数据驱动的方式优化模型,并通过大量图像样本进行训练,使模型在图像质量判断上更符合人类的主观评价。
- 适应不同类型图像:它能够在高分辨率风景图像、自然场景等不同图像类别中提供可靠的质量评分,适合应用于图像增强、生成模型、图像传输等任务。
MUSIQ指标的计算原理
MUSIQ 模型通过卷积神经网络(CNN)提取多尺度的视觉特征,然后将这些特征聚合并输入全连接层得到最终的质量分数。公式一般如下:
M
U
S
I
Q
(
I
)
=
f
(
C
N
N
(
I
s
c
a
l
e
1
)
,
C
N
N
(
I
s
c
a
l
e
2
)
,
.
.
.
C
N
N
(
I
s
c
a
l
e
N
)
MUSIQ(I) = f(CNN(I_{scale1}),CNN(I_{scale2}),...CNN(I_{scaleN})
MUSIQ(I)=f(CNN(Iscale1),CNN(Iscale2),...CNN(IscaleN)
其中:
- i i i是输入图像
- I s c a l e 1 , I s c a l e 2 , I s c a l e N I_{scale1},I_{scale2},I_{scaleN} Iscale1,Iscale2,IscaleN表示图像在不同尺度下的表示。
- C N N CNN CNN 是用于提取视觉特征的卷积神经网络。
- f f f 表示特征融合及评分函数。
7. ICC
ICC(Intraclass Correlation Coefficient,类内相关系数)是一种用于测量数据一致性的统计指标,特别适合评估多个评分者之间的一致性、相似性或重现性。ICC 常用于心理学、医学、机器学习的图像质量评分、深度学习模型的性能评估等领域,用于评价同一对象在不同条件下的结果相似性。
ICC的特点与用途
- 评估一致性:ICC 可以判断多次测量结果的一致性,例如多个观测者对同一图像质量的评分结果是否一致。
- 重复性测量:适用于重复性测量的数据,例如在机器学习模型中对同一数据集重复评估模型的性能。
- 不同类型的 ICC:ICC 有多种类型,适用于不同的情境,如 ICC(1,1), ICC(2,1), ICC(3,1) 等。不同类型适用于不同的实验设计和数据结构,具体选择依赖于数据是否是双向随机、双向混合或单向随机设计。
ICC计算公式
对于单向随机效果模型(例如 ICC(1,1)),基本公式如下:
ICC
(
1
,
1
)
=
σ
between
2
σ
between
2
+
σ
within
2
\text{ICC}(1,1) = \frac{\sigma^2_{\text{between}}}{\sigma^2_{\text{between}} + \sigma^2_{\text{within}}}
ICC(1,1)=σbetween2+σwithin2σbetween2
其中:
- σ between 2 \sigma^2_{\text{between}} σbetween2是类间方差,表示不同评分者(或不同测量条件)之间的变异性。
- σ within 2 \sigma^2_{\text{within}} σwithin2是类内方差,表示同一评分者(或测量条件)在同一对象上的变异性。
ICC的取值范围
0 ≤ ICC ≤ 1:ICC 的值在 0 到 1 之间。
- 接近 1 时表示测量的一致性非常高(评分者或测量之间具有高度相似性)。
- 接近 0 时表示测量的一致性很差(评分者或测量之间差异很大)。
应用场景
- 图像质量评分:用于评估多个算法对同一组图像的质量评估一致性。
- 医学影像:多个医生对同一医学影像的诊断一致性分析。
- 机器学习模型的评估:衡量多个模型对同一数据集的预测结果的一致性。


















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









