






Hugging Face 其实可以类比为机器学习领域的 GitHub,它是用于分享、协作和托管预训练模型、数据集和相关代码的平台。其主要的优势是提供了简单易用的 API 和界面,使得即使是没有深厚机器学习背景的用户也能轻松使用这些模型。
一、安装相关库来加载模型和调用
在使用 Hugging Face 进行自然语言处理(NLP)和计算机视觉(CV)等任务时,首先需要在Python中安装相关的库:
pip install transformers
pip install datasets
pip install pytorch
pip install tokenizers
pip install diffusers
pip install accelerate
pip install evaluate
pip install optimum
pip install pillow
pip install requests
pip install gradio1.模型调用高级API——transformers
Hugging Face 的核心库,提供了用于加载预训练模型、分词器和其他相关工具的接口。可以理解为它可以直接调用HuggingFace上各种预训练模型中的每块“积木”(如编码器、解码器、注意力机制层等),用户可以直接下载这些去搭建使用,而非像研究者一样需要用pytorch或者tensorflow框架对一层层神经网络进行搭建去关注其中的细节。
#from_pretrained方法
from transformers import AutoModel, AutoConfig, AutoTokenizer
#AutoModel.from_pretrained(pretrained_model_name_or_path, **kwargs)
model = AutoModel.from_pretrained("google-bert/bert-base-cased")
#AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
config = AutoConfig.from_pretrained("bert-base-uncased")
#AutoTokenizer.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
#register方法 创建个性化类
# AutoConfig.register(model_type, config, exist_ok = False)
AutoConfig.register("new-model", NewModelConfig)
#如果想保存模型到本地,使用save_pretrained方法
model.save_pretrained('PATH')Auto Classes和from_pretrained方法
使用autoclass的from_pretrained方法可以自动检索到相关名字的预训练模型的权重、配置或者词汇表的位置,从而通过指定预训练模型的名称或路径来实例化一个模型或分词器对象,并快速使用预训练的权重。每个Auto 类都有可以使用自定义类进行扩展的方法,从而自己也可以创建个性化的Auto类。
- AutoModel:用于加载模型的架构和权重,根据提供的预训练模型名称或路径加载对应的模型配置(通过 AutoConfig),然后使用这个配置来构建模型的架构,并加载预训练的权重,从而进行实例化。
- 模型架构是模型的层次结构,包括各种层(如嵌入层、编码器层、解码器层等)和它们之间的连接方式,定义了数据如何通过模型流动。可以理解为模型的计算图,定义了如何将输入数据通过一系列的数学运算转换为输出数据。
- 模型权重是模型在预训练过程中学习到的参数,包括嵌入层的权重、编码器层的权重、注意力机制的参数等,存储在模型文件中,通常是以二进制格式保存的。pytorch_model.bin或tf_model.h5:模型权重文件
- AutoConfig:用于加载预训练模型的配置,包含了模型的各种参数和设置,例如模型的大小、层数、隐藏单元数、注意力头的数量、dropout率等。配置文件通常以 JSON 格式存储,包含了模型的所有超参数。配置不包含模型的训练参数,而是定义了模型的结构和超参数。 config.json:模型配置文件
- AutoTokenizer:用于加载预训练模型的分词器(分词器的词汇表和其它相关配置),以便对新的文本数据进行正确的分词。
- vocab.txt:词汇表文件
- tokenizer_config.json:分词器配置文件
- AutoModelForPreTraining:用于自动加载预训练模型,这些模型是为了预训练任务而设计的。
从本质上讲,AutoModelForPreTraining 和 AutoModel 调用的模型在配置文件和权重方面确实是一样的,它们共享相同的模型架构和预训练权重。然而,它们之间的区别在于模型的头部(head)和使用的场景:
AutoModelForPreTraining:包含预训练任务特定的头部,例如用于掩码语言建模(MLM)的解码器头部和用于下一句预测(NSP)的分类头部。这些头部是预训练任务的一部分,用于在预训练过程中优化模型。用于继续预训练模型或评估模型在预训练任务上的性能。
AutoModel:通常不包含特定于预训练任务的头部。它提供的是模型的主体,即编码器部分,没有额外的输出层。这使得用户可以根据自己的下游任务添加自定义的头部。用于在下游任务中微调模型,例如文本分类、序列标注、问答等。
AutoBackbone:用于自动加载预训练模型的“主干”部分(指模型的主要特征提取部分,不包括为特定任务设计的头部)进行特征提取,可以自由地替换或添加自定义的头部以用于不同下游任务的场景。
2.数据处理框架——datasets
一个独立的用于加载和预处理数据集的库,它包含了大量的预加载数据集,并且可以方便地加载和转换自定义数据集。它的底层并不专门依赖于pytorch,但可以与pytorch等深度学习框架很好地协作,可以方便地将数据集转换为pytorch的dataset和dataloader对象,这里对比一下:
datasets主要是实现从Huggingface Hub下载和缓存数据集、数据预处理、加载和计算指标等功能
from datasets import load_dataset
dataset = load_dataset('squad')
#定义preprocess_function
def preprocess_function(examples):
return {'question': examples['question'], 'context': examples['context']}
#map函数用于将一个函数(在这里是 preprocess_function)应用到数据集的每个元素上
#batched=True表示map函数会以批量的方式处理数据,而不是逐个元素处理
tokenized_datasets = dataset.map(preprocess_function, batched=True)
#结合pytorch使用
from torch.utils.data import DataLoader
#在批次处理数据时如何合并样本的函数,以便进行并行处理
def collate_fn(examples):
return {key: torch.tensor(val) for key, val in examples.items()}
#set_format方法用于设置数据集的输出格式和选择的列
#这里将数据集的输出格式设置为pytorch张量,指定只返回 ‘question’ 和 ‘context’ 两列数据
tokenized_datasets.set_format(type='torch', columns=['question', 'context'])
loader = DataLoader(tokenized_datasets['train'], batch_size=32, collate_fn=collate_fn)
在pytorch中,dataset是一个用于表示数据集的抽象类。它的主要职责是提供数据的访问接口,使得数据可以被dataloader方便地加载和处理;dataloader是一个迭代器,用于多线程地读取数据,并可以实现批量(batch)处理和数据随机打乱(shuffle)等功能,它组合了数据集(dataset)和采样器(sampler),并在数据集上提供单线程或多线程的可迭代对象。
import torch.utils.data.dataset as Dataset
import torch.utils.data.dataloader as DataLoader
from PIL import Image
import torch
import os
#自定义的Dataset类,用于加载图像数据及其标签
class CustomDataset(Dataset):
def __init__(self, image_paths, labels):
self.image_paths = image_paths
self.labels = labels
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = Image.open(self.image_paths[idx])
label = self.labels[idx]
return image, label
#实例化CustomDataset类
dataset = CustomDataset(image_paths, labels)
#创建DataLoader迭代器
dataloader = DataLoader.DataLoader(dataset, batch_size=32, shuffle = True, num_workers= 4)
#后续就可以进行训练或者验证了在实际运用中,datasets主要运用其load_dataset方法来加载数据集,更多还是和pytorch的库结合使用。
dataset = load_dataset(
'dataset_name', #数据集名称
name='subset_name' #数据集的子集名称
split='train' #数据集的分割,如 ‘train’、‘test’、‘validation’ 等
cache_dir='./cache', # 指定数据集的缓存目录
use_auth_token='your_token', # 使用认证令牌
download_mode='force_redownload' #指定下载模式 或'reuse_dataset_if_exists'
)3.底层的深度学习框架——pytorch或者tensorflow
由于transformers库本身并不直接执行深度学习模型的训练和推理计算,而是提供了一个高级接口来管理和使用预训练模型,实际的计算工作是由底层的深度学习框架来完成的(目前主流是pytorch和tensorflow),因此需要安装pytorch或者tensorflow作为后端计算引擎来使用transformers库中的模型进行训练、微调或推理。
4.其他辅助的工具以及数据处理相关依赖包(视情况选择)
- tokenizers:支持多种分词方法【分词是将文本转换为模型可以理解和处理的小单位(tokens)的过程】,并且与Transformers库紧密集成,使得在处理 NLP 任务时可以轻松地进行文本预处理,用于快速、高效的文本分词(tokenization)。
- diffusers:操作扩散模型的工具箱,可以非常方便地使用各种扩散模型生成图像、音频,也可以非常方便地使用各种噪声调度器,以调节模型推理过程中模型生成的速度和质量。
- accelerate:简化在各种硬件配置上训练和部署机器学习模型的流程的Python包,可以在任何类型的设备上运行原本的pytorch训练脚本,关注于利用多GPU、单GPU、CPU以及自动优化器加速训练,同时保持代码的简洁和可读性。
- evaluate:用于评估机器学习模型的库,它提供了一组工具和指标,可以帮助用户快速、准确地评估模型在各种任务上的性能。
- optimum:用于优化和部署机器学习模型的库,旨在帮助用户更高效地训练、优化和部署模型,同时保持模型的性能和精度。提供了多种模型优化技术,如量化、剪枝和蒸馏等,以减少模型大小和加快推理速度;还提供了部署工具和框架,如Docker容器、API服务等,以简化部署流程。
- timm:torch image models,一个广泛使用的开源图像分类库,基于pytorch框架,提供了CV中大量预训练的SOTA模型(如ResNet、EfficientNet、RegNet、ViT等)、实用工具和训练脚本。
- requests:用于发送 HTTP 请求,通常用于下载在线资源,如模型权重或数据集。
- PIL 或 Pillow:图像处理库,用于打开、操作和保存许多不同图像文件格式。PIL是Python原始的图像处理库,2011年后不再更新维护;Pillow是其的分支(fork),与前者兼容并添加了额外的新功能以及一些Bug的修复。
- numpy:强大的数值计算库,用于数据处理和分析。
- scikit-learn:进行模型评估、特征提取等任务时常用的机器学习库。
- protobuf:用于序列化结构化数据,某些模型或数据集可能需要这个库。
- gradio:用于快速创建和部署交互式机器学习模型演示,允许用户通过简单的界面与机器学习模型进行交互,使得非技术用户也能轻松地测试和使用这些模型。(需要python>3.7)
二、直接通过Pipleline调用
深度学习的pipeline是模型实现的步骤,即流水线。现在一般认为是模型的pipeline,比较强调具体模型的组件构成流程。
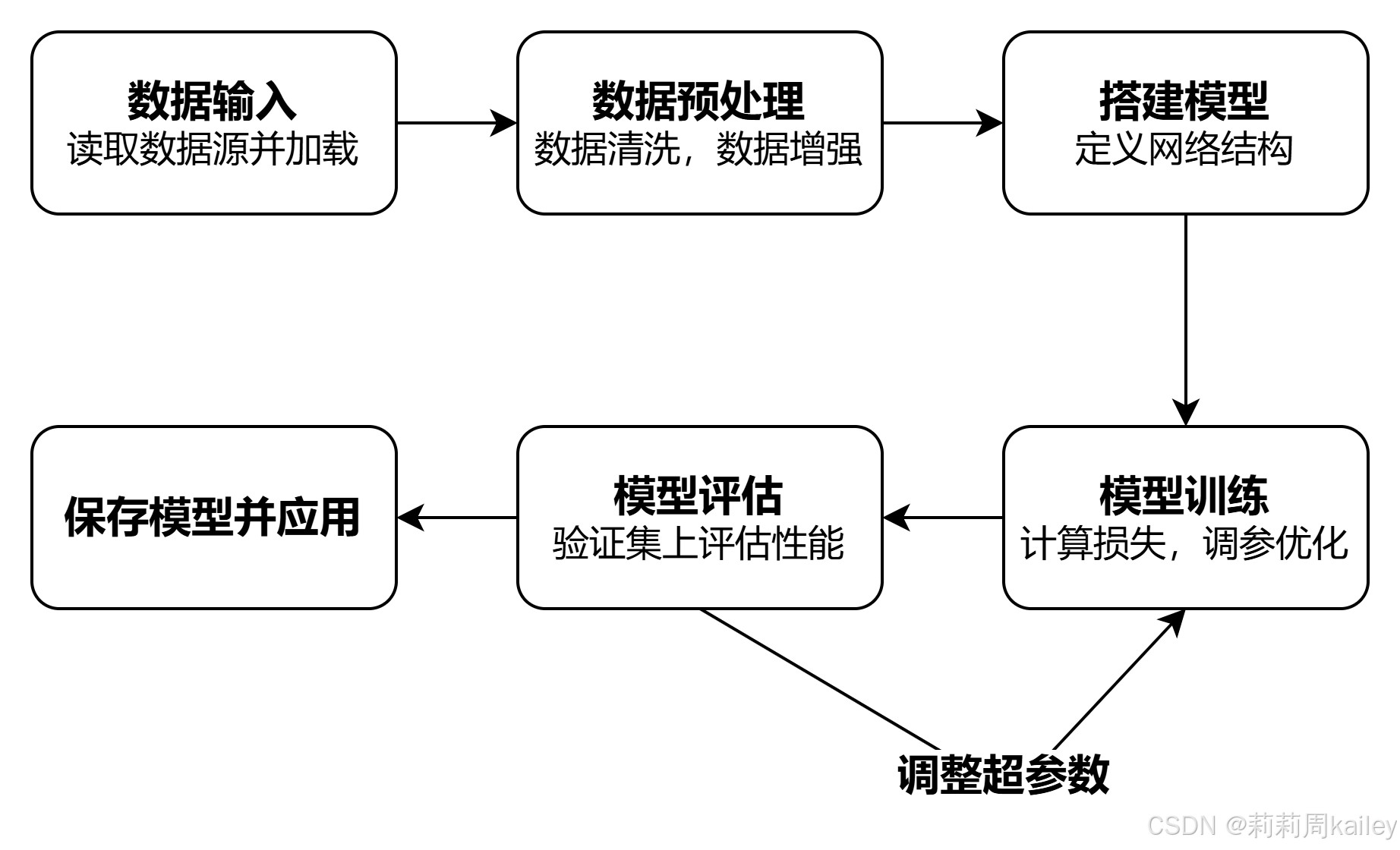
huggingface的pipeline库是一个高级API,旨在简化自然语言处理(NLP)任务的执行流程。它为各种NLP任务提供了一站式的解决方案,将复杂的NLP任务抽象为简单的函数调用,用户无需深入了解任务的实现细节,就可以轻松地使用预训练模型进行推理(预测)。
from transformers import pipeline
# 文本分类
classifier = pipeline('text-classification')
predictions = classifier('This product is awesome!')
print(predictions)
# 命名实体识别
ner = pipeline('ner')
predictions = ner('Hello, my name is John and I live in New York.')
print(predictions)
# 问答
question_answerer = pipeline('question-answering')
context = "The capital of France is Paris."
question = "What is the capital of France?"
predictions = question_answerer(question=question, context=context)
print(predictions)
# 机器翻译
translator = pipeline('translation_en_to_fr')
predictions = translator('How are you?', max_length=40)
print(predictions)三、登录Hugging Face Hub
如果想访问私有模型或数据集、上传模型或数据集到Hugging Face Hub或者遇到某些模型或数据集可能有使用限制的情况,需要通过登录Hugging Face Hub来验证自己的身份。需要访问https://huggingface.co/settings/tokens,创建具有写权限的访问令牌,然后使用令牌来登录。
1.Jupyter Notebook中
from huggingface_hub import notebook_login
notebook_login()
#在输入中输入你的token2.在文件代码中
from huggingface_hub import login
login(token="your_token")3.在命令行中
pip install huggingface_hub
huggingface-cli login
#输入你的访问令牌后,提示登录成功
#也可以通过添加环境变量来实现
export HUGGINGFACE_TOKEN=your_token
#验证是否登录成功
huggingface-cli whoami
总结一下,Hugging Face的Transformers库不仅仅是一个调用已有模型的平台,也是用于自然语言处理(NLP)等任务的模型训练、推理和部署的强大工具。
- 调用已有模型:Transformers库提供了大量预训练模型的接口,可以方便地加载和使用这些模型进行推理。
- 训练模型:Transformers库也支持模型的微调(fine-tuning)和从头开始训练,可以使用库中的Trainer API或自定义训练循环来训练模型。
Transformers库封装了大量的NLP模型和训练流程,实际上是在使用pytorch(或tensorflow)的底层功能,提供了更高层次的抽象,简化了模型训练和推理的流程。但是对于研究者来说,要实现更复杂的训练需求还是要通过pytorch或tensorflow的原生API来编写。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









