






 工具变量法是经济学和统计学中用于解决因果推断中内生性问题的一种方法。它通过寻找高度相关但与误差项无关的变量作为工具变量,以修正模型估计。2SLS是常用的工具变量法实施步骤,包括两阶段回归。寻找合适工具变量是关键,可以是宏观变量、自然现象、随机事件等。统计检验包括强相关检验和模型差异检验。该方法广泛应用在社会科学中,解决遗漏变量、双向因果和测量误差等问题。
工具变量法是经济学和统计学中用于解决因果推断中内生性问题的一种方法。它通过寻找高度相关但与误差项无关的变量作为工具变量,以修正模型估计。2SLS是常用的工具变量法实施步骤,包括两阶段回归。寻找合适工具变量是关键,可以是宏观变量、自然现象、随机事件等。统计检验包括强相关检验和模型差异检验。该方法广泛应用在社会科学中,解决遗漏变量、双向因果和测量误差等问题。
一、什么是工具变量
在对自然科学的模仿中,当下的实证研究的主流发展是因果推断。而在因果推断的过程中,需要得到解释变量X对于被解释变量Y的因果效应估计。这种因果推断需要基于一个反事实的框架,即一个人干了某件事和没干某件事有什么差异。我想要知道我上大学能多赚多少钱,那么我就得知道我上大学和没上大学两种情况下各能赚多少。但是我其实只能要么上大学,要么没上大学,正所谓人不能两次踏入同一条河流。也就是说在发生了其中一种事实的情况下,我们无法得到另外一种情况——反事实。
在回归模型中,我们通常只能使用是否上大学这个变量来估计对收入的影响。而直接把这个变量放入模型中会产生一系列的内生性问题,它会影响上大学对于收入的系数估计。
基于此,社会科学和统计学使用了一系列的方法去解决这种内生性问题。
(1)遗漏变量偏差:面板数据模型、工具变量(IV)、双重差分法(DID)、断点回归设计(RDD)、随机实验或自然实验、倾向得分匹配(PSM)、Heckman选择模型
(2)双向因果关系:工具变量(IV)
(3)测量误差偏差:工具变量(IV)
(4)动态面板偏差:差分GMM、系统GMM
可以看到,工具变量法比较牛逼,可以解决好几种内生性问题偏差。那么什么又是工具变量法?
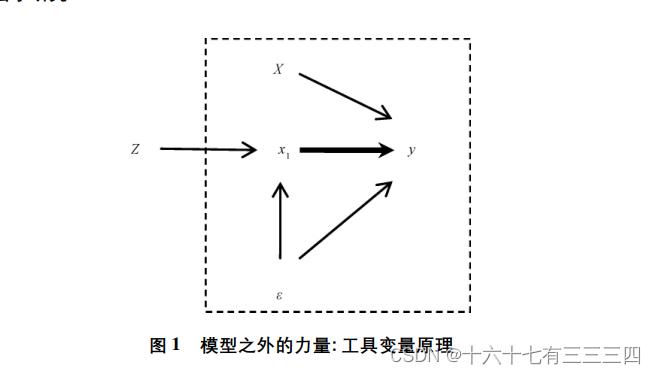
首先回到最简单的OLS回归:y= β0 + β1x1 + βX + ε
其中,x1是关心的解释变量。如果此时存在内生性问题(如x1可能和y是反向因果关系,可能存在一个重要的变量x2被遗漏了,并且x2和x1是相关的,也可能x1这个变量测量有问题),那么应该怎么办?
x1本质上可以从两个方向上来理解。从数学上来说,它是一个向量,是样本中的个案在某个维度上数字取值的集合。从理论上来说,它反映的是一个概念,只不过我们在定量研究中把它操作成了数字。x1是我们感兴趣的,但是这个操作化的变量在回归模型中并不能很好地完成与理论、与现实的对接,这其实就表现出数学模型和现实之间存在的一个大的张力。
那么,如果我们能找到另外一个概念操作化完之后也是这个数学向量,并且从理论和现实来说,这个概念和y没啥关系,和ε没啥关系,并且测量又测量得很好,是不是就解决了内生性问题。
当然,我们并不能找到对应另外一个概念Z在测量上和x1是相同的一组数字,但是退一步来说,它们只要是高度相关的就好了。
我们把这个概念也就是变量Z称之为工具变量,它本质上是用来替代x1。它既能完成x1在数学模型上的光荣使命,又同时避免了在现实上和其他变量扯不清道不明的问题,得到了我们最终想要的干净的系数估计。成功实现了既要又要!
就比如说我想要去街上买根冰棍,不过我其实是个懒狗。但是这时候发现我的邻居也去街上买东西,于是我叫我的邻居顺手帮我带一根。因为我其实目的不是要去街上,我只是想要根冰棍,叫邻居买和我自己去买都能达到这个目的,但是自己去买对我而言比较痛苦。
冰棍对应想要的x1的估计系数;
走路去买对应有问题的x1;
自己去买会让我感到痛苦对应x1有内生性问题;
邻居去买对应工具变量Z;
当然,隐含的假设是我是个厚脸皮的人,这样叫人家买冰棍对我就没什么困扰了。所以厚脸皮对应工具变量Z和误差项 ε不相关。
二、如何使用工具变量法
工具变量法的使用通常使用二阶段最小二乘(2SLS)来估计,具体操作过程如下:
1、以内生变量x1为因变量,工具变量Z和其他外生变量X为自变量,进行模型拟合。
2、以y为因变量,一阶段中的x1的预测值和其他外生变量X为自变量,进行模型拟合。
二阶段最小二乘的理论逻辑是:x1的变量当中有好的部分,也有坏的部分。其中一部分是与扰动项相关的,另外一部分是不和扰动项相关的。目的就是要得到和扰动项不相关的那部分。第一阶段中通过使用工具变量Z和其他外生变量X进行模型拟合,可以消除掉x1的内生部分,保留x1的外生部分。
问题:
x1的一阶段拟合值为什么是外生的?因为工具变量Z和其他外生变量X是外生的。
为什么第一阶段中要加入其他外生变量?这样才能保证其他外生变量和x1也是不相关的。
第二阶段中的其他外生变量的系数是外生变量的纯effect吗?不是,一部分在x1里面。
为什么不需要检验x1和Z之间的相关性?看一阶段的系数显著性就能判断x1和Z的相关性是否显著了,但强弱可以通过进一步的统计检验判断。

做完2SLS之后,我们需要进行进一步的统计检验。
一个是强相关检验。这个可以算第一阶段回归模型的F统计量来得出。一般而言,F值大于10就把这个工具变量称为强工具变量。
一个是对OLS和二阶段最小二乘进行模型差异检验。这个使用豪斯曼检验来做。如果因变量是二分类的,那就可以用瓦尔德内生性检验来做。
除了2SLS之外,另外一种也可以使用GMM(广义矩估计的方法)来做。
三、如何寻找工具变量
工具变量法最难的并不是方法,而是如何找到一个合适的工具变量。
陈云松老师2012年发表在《社会学研究》期刊上的研究详细总结了这一点。
1、使用“宏观”变量当作工具变量
例如,使用大范围的地区、省的宏观变量去分析邻里、学校、社区变量对个人的影响。但是这样会容易产生遗漏偏误,以及噪音。
2、使用“自然界”的工具变量
河流、地震、灾害、降雨量、地形起伏数据甚至化学污染等,在一定范围内有高度的随机性,它们与个人和群体的异质性无关,但是同时又能影响一些社会过程。
3、生老病死
出生季度研究教育回报:出生季度是随机的,但是和教育年限是相关的,上半年出生退学概率大于下半年。
孩子数量对母亲就业的影响:使用孩子的性别组合。由于性别偏好,性别组合和生育数量是相关的。但是出生性别是随机的。
4、距离和价格
家到大学的距离研究教育对收入的影响。各国到赤道的距离研究制度的影响。茶叶价格研究性别收入对男女出生比例的影响。
5、自然实验和虚拟实验
外生性的政策干预变量,如上山下乡。
陈云松.(2012).逻辑、想象和诠释: 工具变量在社会科学因果推断中的应用. 社会学研究(06),192-216+245-246.

















 6938
6938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









