









🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
XGBoost 有很多超参数。XGBoost 基础学习器超参数包含所有决策树超参数作为起点。有梯度提升超参数,因为 XGBoost 是梯度提升的增强版本。XGBoost 独有的超参数旨在提高准确性和速度。然而,试图一次处理所有 XGBoost 超参数可能会令人眼花缭乱。
在第 2 章,深度决策树中,我们回顾并应用了基础学习器超参数,例如max_depth,而在第 4 章,从梯度提升到 XGBoost,我们应用了重要的 XGBoost 超参数,包括n_estimators和learning_rate。在本章中,我们将在 XGBoost 的背景下重新审视这些超参数。此外,我们还将了解新的 XGBoost 超参数,例如gamma和技术叫早停。
在本章中,为了精通微调 XGBoost 超参数,我们将涵盖以下主要主题:
-
准备数据和基础模型
-
调整核心 XGBoost 超参数
-
应用提前停止
-
把它们放在一起
准备数据和基础模型
在引入和应用 XGBoost 超参数之前,让我们做以下准备:
-
获取心脏病数据集
-
构建XGBClassifier模型
-
实施StratifiedKFold
-
对基线 XGBoost 模型进行评分
-
将GridSearchCV与RandomizedSearchCV组合成一个强大的功能
在微调超参数时,良好的准备对于获得准确性、一致性和速度至关重要。
心脏病数据集
使用的数据集贯穿本章的是最初在第 2 章“深度决策树”中介绍的心脏病数据集。我们选择了相同的数据集来最大化超参数微调所花费的时间,并最大限度地减少数据分析所花费的时间。让我们开始这个过程:
-
转到Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn/Chapter06 at master · PacktPublishing/Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn · GitHub将heart_disease.csv加载到 DataFrame 中并显示前五行。这是代码:
import pandas as pd df = pd.read_csv('heart_disease.csv') df.head()结果应如下所示:
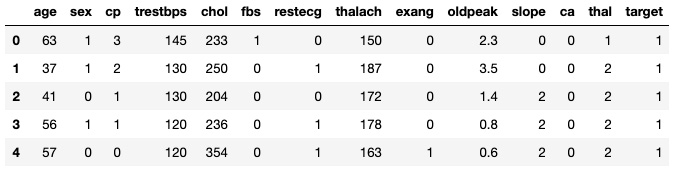
图 6.1 – 前五行
最后一列target是目标列,其中1表示存在,表示患者患有心脏病,2表示不存在。有关其他列的详细信息,请访问UCI 机器学习存储库中的https://archive.ics.uci.edu/ml/datasets/Heart+Disease ,或参阅第 2 章,深度决策树。
-
df.info()这是输出:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 303 entries, 0 to 302 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 303 non-null int64 1 sex 303 non-null int64 2 cp 303 non-null int64 3 trestbps 303 non-null int64 4 chol 303 non-null int64 5 fbs 303 non-null int64 6 restecg 303 non-null int64 7 thalach 303 non-null int64 8 exang 303 non-null int64 9 oldpeak 303 non-null float64 10 slope 303 non-null int64 11 ca 303 non-null int64 12 thal 303 non-null int64 13 target 303 non-null int64 dtypes: float64(1), int64(13) memory usage: 33.3 KB
由于所有数据点是非空的和数字的,数据是机器学习准备好的。是时候建立一个分类器了。
XGBClassifier
调音前超参数,让我们构建一个分类器,以便我们可以获得基线分数作为起点。
要构建 XGBoost 分类器,请执行以下步骤:
-
从各自的库中下载XGBClassifier和accuracy_score 。代码如下:
from xgboost import XGBClassifier from sklearn.metrics import accuracy_score -
将X声明为预测列,将y声明为目标列,其中最后一行是目标列:
X = df.iloc[:, :-1] y = df.iloc[:, -1] -
使用booster='gbtree'和objective='binary:logistic'默认值以及random_state=2初始化XGBClassifier:
model = XGBClassifier(booster='gbtree', objective='binary:logistic', random_state=2)基础学习器“gbtree”助推器是梯度增强树。“二元:逻辑”目标是确定损失函数时二元分类的标准。尽管XGBClassifier默认包含这些值,但我们将它们包含在这里是为了熟悉它们,以便在后面的章节中修改它们。
-
要得分基线模型,导入cross_val_score和numpy来拟合、评分和显示结果:
from sklearn.model_selection import cross_val_score import numpy as np scores = cross_val_score(model, X, y, cv=5) print('Accuracy:', np.round(scores, 2)) print('Accuracy mean: %0.2f' % (scores.mean()))准确度得分如下:
Accuracy: [0.85 0.85 0.77 0.78 0.77] Accuracy mean: 0.81
81% 的准确度分数是一个很好的起点,远高于第 2 章,Deepth决策树中DecisionTreeClassifier获得的 76% 交叉验证。
我们在这里使用了 cross_val_score,我们将使用GridSearchCV来调整超参数。接下来,让我们找到一种使用StratifiedKFold确保测试折叠相同的方法。
分层KFold
微调时超参数、GridSearchCV和RandomizedSearchCV是标准选项。第 2 章,Decision Trees in Depth的一个问题是cross_val_score和GridSearchCV / RandomizedSearchCV不会以相同的方式拆分数据。
一种解决方案是在使用交叉验证时使用StratifiedKFold 。
分层折叠包括每个折叠中相同百分比的目标值。如果数据集在目标列中包含 60% 的 1 和 40% 的 0,则每个分层测试集包含 60% 的 1 和 40% 的 0。当折叠是随机的时,一个测试集可能包含 70-30 的拆分,而另一个包含 50-50 的目标值拆分。
小费
使用train_test_split时, shuffle 和 stratify 参数使用默认值来为您分层数据。有关一般信息,请参阅sklearn.model_selection.train_test_split — scikit-learn 1.1.2 documentation。
要使用StratifiedKFold,请执行以下操作:
-
从sklearn.model_selection实施StratifiedKFold:
from sklearn.model_selection import StratifiedKFold -
接下来,通过选择n_splits=5、shuffle=True和random_state=2作为StratifiedKFold参数,将折叠数定义为kfold 。请注意,random_state提供一致的索引顺序,而shuffle=True允许最初对行进行混洗:
kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=2)kfold变量现在可以在cross_val_score、GridSeachCV和RandomizedSearchCV中使用,以确保结果一致。
现在,让我们使用kfold返回cross_val_score,以便我们有一个合适的基线进行比较。
基线模型
现在我们有一个获得一致折叠的方法,是时候在 cross_val_score 中使用 cv=kfold 对官方基线模型进行评分了。代码如下:
scores = cross_val_score(model, X, y, cv=kfold)
print('Accuracy:', np.round(scores, 2))
print('Accuracy mean: %0.2f' % (scores.mean()))准确度得分如下:
Accuracy: [0.72 0.82 0.75 0.8 0.82]
Accuracy mean: 0.78分数已经下降了。这是什么意思?
重要的是不要为了获得尽可能高的分数而过于投入。在这种情况下,我们在不同的折叠上训练了相同的XGBClassifier模型并获得了不同的分数。这说明了在训练模型时与测试折叠保持一致的重要性,以及为什么分数不一定是最重要的。尽管在模型之间进行选择时,获得最佳分数是一种最佳策略,但这里的分数差异表明模型不一定更好。在这种情况下,两个模型具有相同的超参数,并且分数的差异归因于不同的折叠。
这里的重点是在使用GridSearchCV和RandomizedSearchCV微调超参数时使用相同的折叠来获得新的分数,以便分数的比较是公平的。
结合 GridSearchCV 和 RandomizedSearchCV
GridSearchCV搜索一切可能超参数网格中的组合以找到最佳结果。RandomizedSearchCV默认选择 10 个随机超参数组合。当GridSearchCV变得笨拙时,通常使用RandomizedSearchCV ,因为有太多的超参数组合无法详尽地检查每一个。
我们不会为GridSearchCV和RandomizedSearchCV编写两个单独的函数,而是将它们组合成一个简化的函数,步骤如下:
-
从sklearn.model_selection导入GridSearchCV和RandomizedSearchCV:
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV -
使用params字典作为输入定义一个grid_search函数,以及random=False:
def grid_search(params, random=False): -
xgb = XGBClassifier(booster='gbtree', objective='binary:logistic', random_state=2) -
如果random=True ,使用xgb和params字典初始化RandomizedSearchCV 。设置n_iter=20以允许 20 个随机组合而不是 10 个。否则,使用相同的输入初始化GridSearchCV 。确保设置cv=kfold以获得一致的结果:
if random: grid = RandomizedSearchCV(xgb, params, cv=kfold, n_iter=20, n_jobs=-1) else: grid = GridSearchCV(xgb, params, cv=kfold, n_jobs=-1) -
将X和y拟合到网格模型:
grid.fit(X, y) -
获取并打印best_params_:
best_params = grid.best_params_ print("Best params:", best_params) -
获取并打印best_score_:
best_score = grid.best_score_ print("Training score: {:.3f}".format(best_score))
调整 XGBoost 超参数
有许多 XGBoost 超参数,其中一些已经在前面的章节中介绍过。下表总结了关键的 XGBoost 超参数,我们在本书中介绍了其中的大部分。
笔记
这里介绍的 XGBoost 超参数并不详尽,但它们是全面的。有关超参数的完整列表,请阅读官方文档XGBoost 参数,网址为XGBoost Parameters — xgboost 1.7.0-dev documentation。
下表提供了进一步的解释和示例:
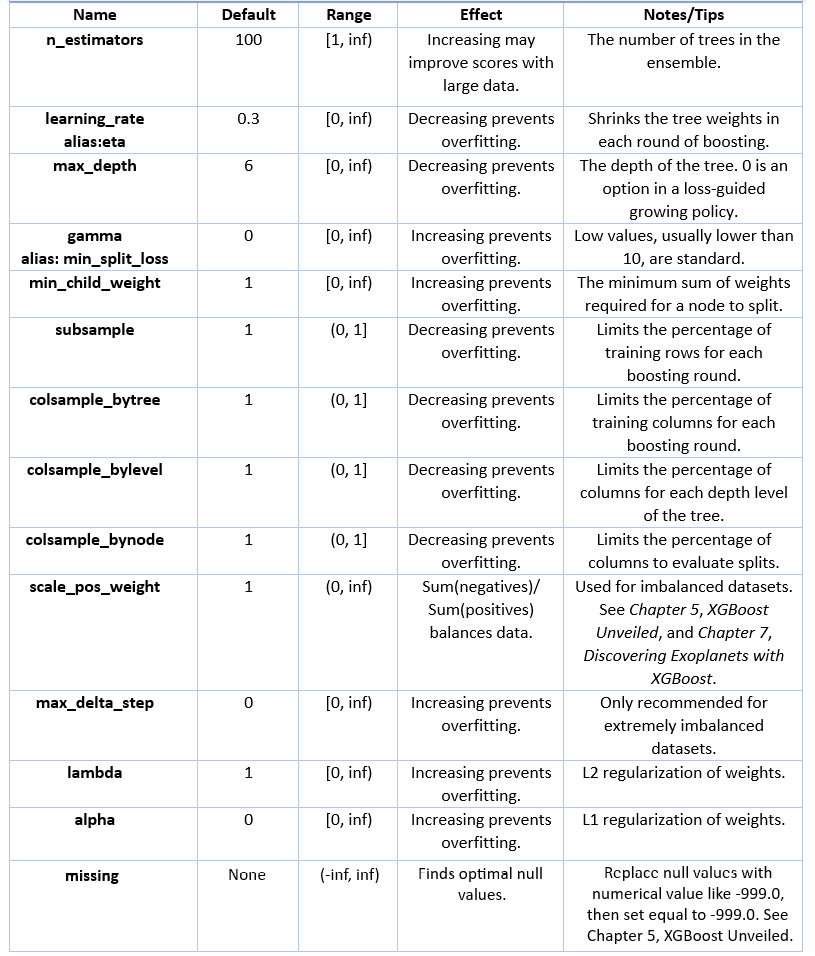
图 6.2 – XGBoost 超参数表
现在已经介绍了关键的 XGBoost 超参数,让我们通过以下方式更好地了解它们一次调整一个。
应用 XGBoost 超参数
XGBoost本节中介绍的超参数经常由机器学习从业者进行微调。在对每个超参数进行简要说明后,我们将使用上一节中定义的grid_search函数测试标准变体。
n_estimators
记起n_estimators提供了树的数量在合奏中。在 XGBoost 的情况下,n_estimators是在残差上训练的树的数量。
使用默认值100初始化n_estimators的网格搜索,然后将树的数量翻倍至800,如下所示:
grid_search(params={'n_estimators':[100, 200, 400, 800]})输出如下:
Best params: {'n_estimators': 100}
Best score: 0.78235由于我们的数据集很小,增加n_estimators并没有产生更好的结果。本章的应用提前停止部分讨论了一种找到理想n_estimators值的策略。
learning_rate
learning_rate缩小每棵树的权重一轮助推。通过降低learning_rate,需要更多的树来产生更好的分数。降低learning_rate可以防止过度拟合,因为前推权重的大小更小。
使用默认值0.3,尽管以前版本的 scikit-learn 使用0.1。这是放在我们的grid_search函数中的learning_rate的起始范围:
grid_search(params={'learning_rate':[0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5]})输出如下:
Best params: {'learning_rate': 0.05}
Best score: 0.79585改变学习率略有增加。作为在第 4 章,从梯度提升到 XGBoost中进行了描述,当n_estimators上升时,降低learning_rate可能是有利的。
max_depth
max_depth确定树的长度,等价为分裂的轮数。限制max_depth可以防止过度拟合,因为单个树只能在max_depth允许的范围内增长。XGBoost 提供的默认max_depth值为 6:
grid_search(params={'max_depth':[2, 3, 5, 6, 8]})输出如下:
Best params: {'max_depth': 2}
Best score: 0.79902将max_depth从6更改为2可以获得更好的分数。max_depth的较低值意味着方差已减小。
gamma
已知作为拉格朗日乘数,伽玛提供阈值在根据损失函数进行进一步拆分之前,节点必须超过该节点。gamma的值没有上限。默认值为0,超过10的任何值都被认为非常高。增加gamma会导致模型更加保守:
grid_search(params={'gamma':[0, 0.1, 0.5, 1, 2, 5]})输出如下:
Best params: {'gamma': 0.5}
Best score: 0.79574min_child_weight
min_child_weight指到最低限度节点分裂为子节点所需的权重总和。如果权重之和小于min_child_weight的值,则不再进行拆分。min_child_weight通过增加其值来减少过拟合:
grid_search(params={'min_child_weight':[1, 2, 3, 4, 5]})输出如下:
Best params: {'min_child_weight': 5}
Best score: 0.81219对min_child_weight稍作调整可以得到最好的结果。
subsample
subsample超参数限制百分比每个提升轮的训练实例(行)。从 100% 减少子样本可减少过拟合:
grid_search(params={'subsample':[0.5, 0.7, 0.8, 0.9, 1]})输出如下:
Best params: {'subsample': 0.8}
Best score: 0.79579分数再次略有提高,表明存在少量过度拟合。
colsample_bytree
相似的对subsample , colsample_bytree随机根据给定的百分比选择特定的列。colsample_bytree可用于限制列的影响和减少方差。请注意,colsample_bytree将百分比作为输入,而不是列数:
grid_search(params={'colsample_bytree':[0.5, 0.7, 0.8, 0.9, 1]})输出如下:
Best params: {'colsample_bytree': 0.7}
Best score: 0.79902这里的收益充其量是微乎其微的。我们鼓励您自己尝试colsample_bylevel和colsample_bynode。colsample_bylevel为每个树深度随机选择列,colsample_bynode在评估每个树拆分时随机选择列。
微调超参数是一门艺术和一门科学。与这两个学科一样,不同的方法都有效。接下来,我们将研究早期停止作为微调n_estimators的特定策略。
应用提前停止
提前停止是在迭代机器学习算法中限制训练轮数的通用方法。在本节中,我们将查看eval_set、eval_metric和early_stopping_rounds以应用提前停止。
什么叫早停?
提前停止提供迭代机器学习算法训练的轮数限制。提前停止不是预先定义训练轮数,而是允许训练继续进行,直到连续n轮未能产生任何收益,其中n是用户决定的数字。
在查找n_estimators时只选择 100 的倍数是没有意义的。最好的值可能是 737 而不是 700。手动找到一个如此精确的值可能会很累,尤其是当超参数调整可能需要在未来进行更改时。
使用 XGBoost,可以在每轮增强后确定分数。尽管分数会上下波动,但最终分数会趋于平稳或朝着错误的方向发展。
当所有后续分数都未能提供任何收益时,达到最高分数。您确定在 10、20 或 100 轮训练后未能提高分数的峰值。您选择轮数。
在提前停止时,重要的是要给模型足够的时间来失败。如果模型过早停止,比如说,在五轮没有改进之后,模型可能会错过它可能会错过的一般模式稍后再接。与经常使用提前停止的深度学习一样,梯度提升需要足够的时间来发现数据中的复杂模式。
对于 XGBoost,early_stopping_rounds是应用提前停止的关键参数。如果early_stopping_rounds=10,模型将在连续 10 轮训练未能改进模型后停止训练。类似地,如果early_stopping_rounds=100,训练会持续到连续 100 轮未能改进模型。
现在您已经了解了提前停止是什么,让我们来看看eval_set和eval_metric。
eval_set 和 eval_metric
early_stopping_rounds是不是超参数,而是一种优化n_estimators超参数的策略。
通常在选择超参数时,会在所有提升轮次完成后给出测试分数。要使用提前停止,我们需要在每轮之后的测试分数。
eval_metric和eval_set可用作 .fit 的参数,以生成每一轮训练的测试分数。eval_metric提供了评分方法,通常“error”用于分类,“rmse”用于回归。eval_set提供要评估的测试,通常是X_test和y_test。
以下六个步骤显示了每轮训练的评估指标,默认为 n_estimators=100:
-
将数据拆分为训练集和测试集:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2) -
初始化模型:
model = XGBClassifier(booster='gbtree', objective='binary:logistic', random_state=2) -
声明eval_set:
eval_set = [(X_test, y_test)] -
声明eval_metric:
eval_metric = 'error' -
model.fit(X_train, y_train, eval_metric=eval_metric, eval_set=eval_set) -
查看最终成绩:
y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy: %.2f%%" % (accuracy * 100.0))这是截断的输出:
[0] validation_0-error:0.15790 [1] validation_0-error:0.10526 [2] validation_0-error:0.11842 [3] validation_0-error:0.13158 [4] validation_0-error:0.11842 … [96] validation_0-error:0.17105 [97] validation_0-error:0.17105 [98] validation_0-error:0.17105 [99] validation_0-error:0.17105 Accuracy: 82.89%
不要太激动关于分数,因为我们没有使用交叉验证。事实上,我们知道当n_estimators=100时,StratifiedKFold交叉验证的平均准确率为 78% 。分数的差异来自测试集的差异。
early_stopping_rounds
early_stopping_rounds是一个可选参数在拟合模型时包含eval_metric和eval_set 。
让我们尝试early_stopping_rounds=10。
重复前面的代码,并添加early_stopping_rounds=10:
model = XGBClassifier(booster='gbtree', objective='binary:logistic', random_state=2)
eval_set = [(X_test, y_test)]
eval_metric='error'
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, early_stopping_rounds=10, verbose=True)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))输出如下:
[0] validation_0-error:0.15790
Will train until validation_0-error hasn't improved in 10 rounds.
[1] validation_0-error:0.10526
[2] validation_0-error:0.11842
[3] validation_0-error:0.13158
[4] validation_0-error:0.11842
[5] validation_0-error:0.14474
[6] validation_0-error:0.14474
[7] validation_0-error:0.14474
[8] validation_0-error:0.14474
[9] validation_0-error:0.14474
[10] validation_0-error:0.14474
[11] validation_0-error:0.15790
Stopping. Best iteration:
[1] validation_0-error:0.10526
Accuracy: 89.47%结果可能来一个惊喜。提前停止表明n_estimators=2给出了最好的结果,这可能是测试折叠的原因。
为什么只有两棵树?通过只给模型 10 轮来提高准确性,数据中的模式可能尚未被发现。但是,数据集非常小,因此两轮增强可能会产生最佳结果。
更彻底的方法是使用更大的值,例如n_estimators = 5000和early_stopping_rounds=100。
通过设置early_stopping_rounds=100,您可以保证达到 XGBoost 提供的100 个增强树的默认值。
这是给出最多 5,000 棵树的代码,并且在连续 100 轮找不到任何改进后将停止:
model = XGBClassifier(random_state=2, n_estimators=5000)
eval_set = [(X_test, y_test)]
eval_metric="error"
model.fit(X_train, y_train, eval_metric=eval_metric, eval_set=eval_set, early_stopping_rounds=100)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))[0] validation_0-error:0.15790
Will train until validation_0-error hasn't improved in 100 rounds.
[1] validation_0-error:0.10526
[2] validation_0-error:0.11842
[3] validation_0-error:0.13158
[4] validation_0-error:0.11842
...
[98] validation_0-error:0.17105
[99] validation_0-error:0.17105
[100] validation_0-error:0.17105
[101] validation_0-error:0.17105
Stopping. Best iteration:
[1] validation_0-error:0.10526
Accuracy: 89.47%经过 100 轮 boosting,两棵树提供的分数仍然是最好的。
最后一点,考虑当不清楚时,早期停止对于大型数据集特别有用你应该瞄准多高。
现在,让我们使用提前停止的结果以及之前调整的所有超参数来生成最佳模型。
组合超参数
是时候了结合本章的所有组成部分,以提高通过交叉验证获得的 78% 的分数。
如您所知,没有一种万能的超参数微调方法。一种方法是使用RandomizedSearchCV输入所有超参数范围。一种更系统的方法是一次处理一个超参数,将最佳结果用于后续迭代。所有方法都有优点和局限性。无论策略如何,都必须尝试多种变化并在数据进入时进行调整。
一次一个超参数
使用系统方法,我们一次添加一个超参数,并在此过程中汇总结果。
n_estimators
虽然n_estimators值为2给出了最好的结果,值得尝试使用交叉验证的grid_search函数的范围:
grid_search(params={'n_estimators':[2, 25, 50, 75, 100]})输出如下:
Best params: {'n_estimators': 50}
Best score: 0.78907毫不奇怪,n_estimators=50介于之前的最佳值 2 和默认值 100 之间,给出了最好的结果。由于在提前停止中没有使用交叉验证,因此结果这里不同。
max_depth
max_depth超参数确定长度每棵树。这是一个不错的范围:
grid_search(params={'max_depth':[1, 2, 3, 4, 5, 6, 7, 8], 'n_estimators':[50]})输出如下:
Best params: {'max_depth': 1, 'n_estimators': 50}
Best score: 0.83869这是一个非常重要的获得。深度为 1 的树称为决策树桩。通过仅调整两个超参数,我们从基线模型中获得了四个百分点。
保持最高值的方法的一个限制是我们可能会错过更好的组合。也许n_estimators=2或n_esimtators=100与max_depth一起提供更好的结果。让我们来了解一下:
grid_search(params={'max_depth':[1, 2, 3, 4, 6, 7, 8], 'n_estimators':[2, 50, 100]})输出如下:
Best params: {'max_depth': 1, 'n_estimators': 50}
Best score: 0.83869n_estimators=50和max_depth=1仍然给出最好的结果,所以我们将继续使用它们,稍后再回到我们的早期停止分析。
learning_rate
由于n_esimtators是合理的低,调整 learning_rate可能会改善结果。这是一个标准范围:
grid_search(params={'learning_rate':[0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'learning_rate': 0.3, 'max_depth': 1, 'n_estimators': 50}
Best score: 0.83869这与之前获得的分数相同。请注意,learning_rate值为 0.3 是 XGBoost 提供的默认值。
min_child_weight
grid_search(params={'min_child_weight':[1, 2, 3, 4, 5],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'max_depth': 1, 'min_child_weight': 1, 'n_estimators': 50}
Best score: 0.83869在这种情况下,最好的分数是相同的。请注意, 1 是min_child_weight的默认值。
subsample
如果减少方差是有益的,子样本可以通过限制样本的百分比。然而,在这种情况下,一开始只有 303 个样本,而且样本数量少,很难调整超参数来提高分数。这是代码:
grid_search(params={'subsample':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'max_depth': 1, 'n_estimators': 50, 'subsample': 1}
Best score: 0.83869还是没有收获。此时,您可能想知道n_esimtators=2是否会继续获得新的收益。
grid_search(params={'subsample':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'min_child_weight':[1, 2, 3, 4, 5],
'learning_rate':[0.1, 0.2, 0.3, 0.4, 0.5],
'max_depth':[1, 2, 3, 4, 5],
'n_estimators':[2]})输出如下:
Best params: {'learning_rate': 0.5, 'max_depth': 2,
'min_child_weight': 4, 'n_estimators': 2, 'subsample': 0.9}
Best score: 0.81224只有两棵树的分类器表现更差也就不足为奇了。即使初始分数更好,它也没有经过足够的迭代来让超参数做出重大调整。
超参数调整
换挡时带有超参数的方向,由于输入范围广泛,RandomizedSearchCV很有用。
这是一系列将新输入与先前知识相结合的超参数值。使用RandomizedSearchCV限制范围会增加找到最佳组合的几率。回想一下,当组合的总数对于网格搜索来说太耗时时, RandomizedSearchCV很有用。有 4,500 种可能的组合,具有以下选项:
grid_search(params={'subsample':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'min_child_weight':[1, 2, 3, 4, 5],
'learning_rate':[0.1, 0.2, 0.3, 0.4, 0.5],
'max_depth':[1, 2, 3, 4, 5, None],
'n_estimators':[2, 25, 50, 75, 100]},random=True)
输出如下:
Best params: {'subsample': 0.6, 'n_estimators': 25,
'min_child_weight': 4, 'max_depth': 4, 'learning_rate': 0.5}
Best score: 0.82208这是有趣的。不同的值正在获得良好的结果。
我们使用未来最好分数的超参数。
样品
现在,让我们按顺序尝试colsample_bytree、colsample_bylevel和colsample_bynode。
colsample_bytree
grid_search(params={'colsample_bytree':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'colsample_bytree': 1, 'max_depth': 1, 'n_estimators': 50}
Best score: 0.83869分数没有提高。接下来,尝试colsample_bylevel。
colsample_bylevel
grid_search(params={'colsample_bylevel':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'colsample_bylevel': 1, 'max_depth': 1, 'n_estimators': 50}
Best score: 0.83869还是没有收获。
似乎我们正在使用浅数据集达到顶峰。让我们尝试不同的方法。让我们一起调整所有 colsamples,而不是单独使用colsample_bynode 。
colsample_bynode
grid_search(params={'colsample_bynode':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'colsample_bylevel':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'colsample_bytree':[0.5, 0.6, 0.7, 0.8, 0.9, 1],
'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'colsample_bylevel': 0.9, 'colsample_bynode': 0.5,
'colsample_bytree': 0.8, 'max_depth': 1, 'n_estimators': 50}
Best score: 0.84852杰出的。在职的这些 colsamples 结合在一起提供了迄今为止的最高分数,比原来的高 5 个百分点。
gamma
最后一个超参数我们将尝试微调的是gamma。这是旨在减少过度拟合的一系列伽马值:
grid_search(params={'gamma':[0, 0.01, 0.05, 0.1, 0.5, 1, 2, 3],
'colsample_bylevel':[0.9], 'colsample_bytree':[0.8],
'colsample_bynode':[0.5], 'max_depth':[1], 'n_estimators':[50]})输出如下:
Best params: {'colsample_bylevel': 0.9, 'colsample_bynode': 0.5,
'colsample_bytree': 0.8, 'gamma': 0, 'max_depth': 1, 'n_estimators': 50}
Best score: 0.84852gamma保持默认值0。
由于我们的最佳分数比原来的高出 5 个百分点以上,这对 XGBoost 来说是不小的壮举,我们将在此停止。
概括
在本章中,您通过使用StratifiedKFold建立基线 XGBoost 模型为超参数微调做好了准备。然后,您将GridSearchCV和RandomizedSearchCV组合成一个强大的功能。您学习了关键 XGBoost 超参数的标准定义、范围和应用,以及一种称为早期停止的新技术。您综合了所有函数、超参数和技术来微调心脏病数据集,从默认的 XGBoost 分类器中获得了令人印象深刻的 5 个百分点。
XGBoost 超参数微调需要时间来掌握,而且你正在顺利进行。微调超参数是区分机器学习专家和机器学习新手的关键技能。XGBoost 超参数的知识不仅有用,而且对于充分利用您构建的机器学习模型至关重要。
恭喜你完成了这一重要章节。
接下来,我们从头到尾介绍 XGBoost 回归的案例研究,重点介绍 XGBClassifier 的功能、范围和应用。

















 2562
2562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











