




自编码器(autoencoder)属于嵌入与表征学习的一种。作为深度神经网络的一类方法,它主要用于数据降维、压缩以及获取低维度表征等。自编码器与传统机器学习中的主成分分析(PCA)、因子分析(FA)等降维方法作用相同,但与之相比更为灵活,效果往往更好。
一:基本原理
对于自编码器,其结构可分为编码器(encoder)与解码器(decoder)两部分。encoder部分,可以是卷积、池化、全连接等层组成的一个神经网络(为了缩小维度,卷积一般采取下采样,或将其中矩阵转成1维张量,再进行全连接,全连接层神经元节点个数逐层逐渐减少),并且输出维度与输入相比会小很多(如500500的图片可以经encoder得到1
50的序列,10维的数据变成更小的维度);decoder部分,其结构可以为卷积、全连接等各层的组合(为了增加维度,卷积通常采取上采样,或者全连接层神经元节点个数逐层逐渐增加),decoder部分将encoder部分的输出作为输入,最终的输出与输入的维度完全一致。网络训练的关键是使输入与输出尽可能相同(损失尽可能小),所以损失函数中分别为该数据与该数据通过自编码器得到的输出。训练结束后,某一数据输入自编码器,此时Encoder的输出embedding即为该数据的表征。

以上便是基本的自编码器的架构。
二:模型实现
兔兔在这里以rdkit创建的分子图片数据为例(读者也可以选择其他图片来进行训练,并先随意定义一个模型进行尝试)。
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader
from rdkit import Chem
from rdkit.Chem import Draw
from PIL import Image
class dataset:
'''训练数据集'''
def __init__(self):
smis=['C=C','C(=O)C','CNC','CCC(=O)C',
'C1=CC=CC=C1','C#CC','O=C=O','CCCO',
'N#N','C=CC=CO','NC(=O)C','OCCOCC']
'''创建分子图片数据集,保存在Data文件夹中'''
for i in range(len(smis)):
mol=Chem.MolFromSmiles(smis[i])
img=Draw.MolToImage(mol,size=(50,50))
img.save('Data/img{}.png'.format(i))
traindata=[]
for i in range(len(smis)):
'''将图片转成50x50x3 张量'''
traindata.append(np.array(Image.open('Data/img{}.png'.format(i))))
self.traindata=torch.tensor(np.array(traindata),dtype=torch.float32)
self.n=len(smis)
def __len__(self):
return self.n
def __getitem__(self, item):
return self.traindata[item]
class Autuencoder(nn.Module):
'''自编码器'''
def __init__(self):
super().__init__()
self.encode=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=1,kernel_size=(5,5),stride=1,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(5,5),stride=1,padding=0),
nn.Conv2d(in_channels=1,out_channels=3,kernel_size=(5,5),stride=1,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(5,5),stride=1,padding=0),
nn.Flatten(start_dim=2,end_dim=3),
nn.Linear(1156,1000),
nn.ReLU(),
nn.Linear(1000,800),
nn.ReLU())
self.decode=nn.Sequential(nn.Linear(800,2000),
nn.ReLU(),
nn.Linear(2000,2500))
def forward(self,input):
out=self.encode(input)
out=self.decode(out)
b,c,_=out.shape
out=out.view(b,c,50,50)
return out
if __name__=='__main__':
epochs=30
batch_size=2
dataloder=DataLoader(dataset(),shuffle=True,batch_size=batch_size) #加载数据
auto=Autuencoder()
optim=torch.optim.Adam(params=auto.parameters())
Loss=nn.MSELoss() #损失函数
for i in range(epochs):
for data in dataloder:
data=data.permute(0,3,1,2)
yp=auto(data)
loss=Loss(yp,data)
optim.zero_grad()
loss.backward()
optim.step()
torch.save(auto,'autoencoder.pkl') #保存模型以上模型结构如下所示。
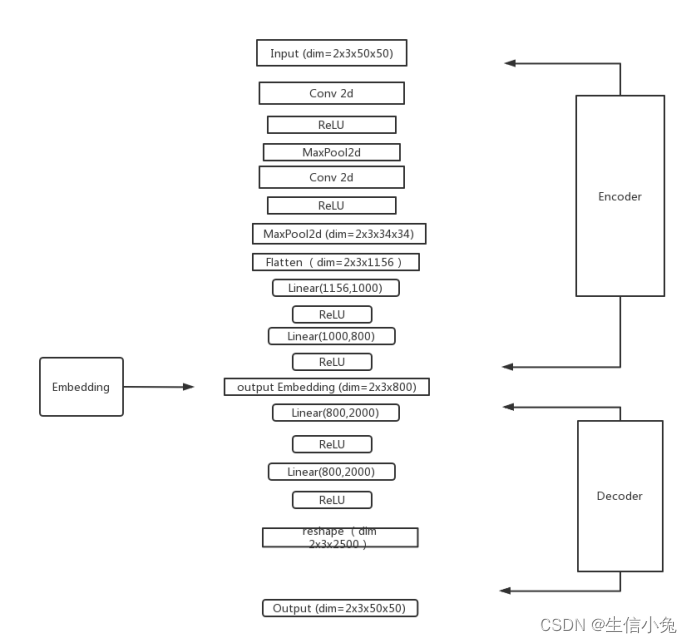
由于兔兔的计算机算力与内存等问题,图片的维数、数据集数量等不能过大,所以选择以上的数据与模型。
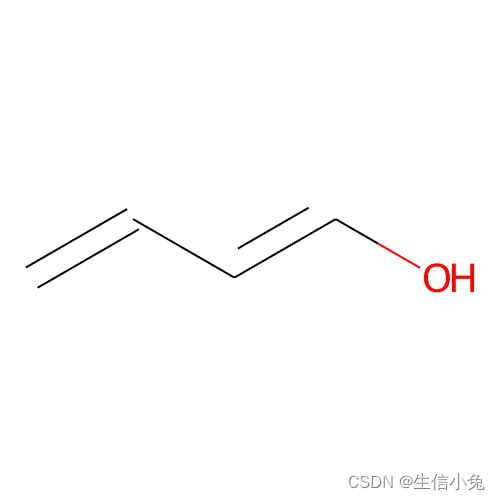
训练结束后,我们以img9为例。
import matplotlib .pyplot as plt
from ex1 import Autuencoder
from PIL import Image
import torch
import numpy as np
auto=torch.load('autoencoder.pkl')
input=np.array(Image.open('Data/img9.png'))
input=torch.tensor(np.array([input]),dtype=torch.float32).permute(0,3,1,2)
out=auto(input)
out=out.permute(0,2,3,1)[0]
out=out.detach().numpy()
img=Image.fromarray(out.astype('uint8'))
plt.imshow(img)
plt.show()将img9数据的输入训练好的自编码器,得到输出如下图所示。
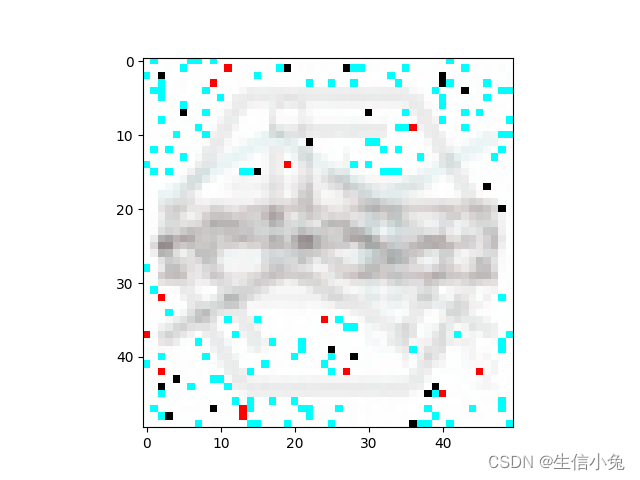
理想的情况是输入与输出图片是相同的,这里显然没有训练充分(或模型以及其中参数有一定问题,或许不采用卷积只用全连接对于这样的小样本数据会训练更快,效果更好)。
训练好自编码器后,我们也可以得到这个图片的压缩的编码表示。
auto=torch.load('autoencoder.pkl')
input=np.array(Image.open('Data/img9.png'))
input=torch.tensor(np.array([input]),dtype=torch.float32).permute(0,3,1,2)
out=auto.encode(input)
print(out)这里的编码或许不是一维张量,在实际应用中这样是可行的。
设想:
对于一些分子数据库,我们从中获取分子的图片(或将获取的文件处理得到分子图片),用自编码器学习该分子的表示(分子描述符),这样是否可行呢?答案是否定的,因为同一个分子,可以有非常多不同的图片——或是平移、旋转以及分子的其他结构画法都可以使得分子图像的不同,然而它们却是同一个分子,那么encoder得到的编码只能表征这个图片,不能表征这个分子。对于这些分子结构,目前仍是以图神经网络或基于结构的点云神经网络等方法来处理。
三:总结
自编码器作为一种嵌入与表征方法,在实际应用中具有广泛的应用。它可以有效地进行数据降维,学习数据的表征,并用这些表征来进一步解决监督学习问题。


















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











