







DeepSeeK-V3中核心技术详解:什么是FP8?什么是MLA?什么是MOE?
关键词:FP8、MLA、MOE、DeepSeeK-V3、核心技术
亮点:细致拆解,直击技术本质,助你快速掌握核心概念!
🚀 前言
AI领域的创新从未停止,每一代新技术都在突破硬件极限和算法瓶颈。在DeepSeeK-V3中,有三大核心技术尤为引人注目:FP8、MLA 和 MOE。这些技术不仅提升了模型性能,还在推理效率、能耗优化上展现了巨大的潜力。
今天,猫头虎将逐一解析这些技术,带你深入了解它们的核心原理与应用场景!😺✨

作者简介
猫头虎是谁?
大家好,我是 猫头虎,猫头虎技术团队创始人,也被大家称为猫哥。我目前是COC北京城市开发者社区主理人、COC西安城市开发者社区主理人,以及云原生开发者社区主理人,在多个技术领域如云原生、前端、后端、运维和AI都具备丰富经验。
我的博客内容涵盖广泛,主要分享技术教程、Bug解决方案、开发工具使用方法、前沿科技资讯、产品评测、产品使用体验,以及产品优缺点分析、横向对比、技术沙龙参会体验等。我的分享聚焦于云服务产品评测、AI产品对比、开发板性能测试和技术报告。
目前,我活跃在CSDN、51CTO、腾讯云、阿里云开发者社区、华为云开发者社区、知乎、微信公众号、视频号、抖音、B站、小红书等平台,全网粉丝已超过30万。我所有平台的IP名称统一为猫头虎或猫头虎技术团队。
我希望通过我的分享,帮助大家更好地掌握和使用各种技术产品,提升开发效率与体验。
作者名片 ✍️
- 博主:猫头虎
- 全网搜索关键词:猫头虎
- 作者微信号:Libin9iOak
- 作者公众号:猫头虎技术团队
- 更新日期:2024年12月30日
- 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能!
加入我们AI共创团队 🌐
- 猫头虎AI共创社群矩阵列表:
加入猫头虎的共创圈,一起探索编程世界的无限可能! 🚀
正文
🌟 1. 什么是FP8?
🔍 概念解析
FP8,全称是8位浮点数(Float Point 8)。它是一种新的数值表示方式,用于深度学习的计算加速。相比传统的FP32和FP16,FP8进一步压缩了数据位数,极大地提升了硬件计算效率。
🧩 技术亮点
- 更小的数据表示:使用8位表示浮点数,有效减少存储需求和传输延迟。
- 高效的硬件支持:FP8针对AI芯片优化,能更好地利用硬件算力。
- 精度与性能的平衡:通过定制化的动态范围管理,确保精度损失对模型性能的影响降到最低。
💡 应用场景
- 模型训练:在大型语言模型(如GPT-4)中使用FP8可显著降低显存占用。
- 推理优化:在高并发场景下,FP8减少计算资源消耗,提高推理速度。
🌟 2. 什么是MLA?
🔍 概念解析
MLA,全称是机器学习加速器(Machine Learning Accelerator),是一种专门为深度学习任务设计的硬件模块。DeepSeeK-V3的MLA技术通过硬件与软件协同优化,极大提升了训练效率。
🧩 技术亮点
- 专属算力引擎:每个MLA单元都具备高效的矩阵计算能力,针对深度学习核心操作(如矩阵乘法、卷积运算)进行了专门优化。
- 动态任务调度:MLA可以根据任务需求实时分配算力,确保硬件资源不被浪费。
- 可扩展性:支持多模块并联,适配大规模分布式训练。
💡 应用场景
- 大模型训练:尤其适用于Transformer架构模型,显著提升训练速度。
- 边缘计算:MLA在低功耗设备上实现高效推理,为IoT和边缘AI赋能。
🌟 3. 什么是MOE?
🔍 概念解析
MOE,全称是专家混合(Mixture of Experts),是一种动态路由技术。通过在每次计算中只激活部分专家网络,MOE在保证模型性能的同时显著降低了计算开销。
🧩 技术亮点
- 动态路由机制:根据输入特征动态选择最合适的“专家”,避免全模型计算的资源浪费。
- 极致的参数效率:尽管模型参数规模庞大,但实际计算的子集专家参数占比很小。
- 灵活的扩展性:可以在不增加显存压力的情况下扩展专家数量。
💡 应用场景
- 多任务学习:MOE在处理跨领域任务时具备显著优势。
- 高效推理:在大规模推荐系统中,MOE有效减少延迟,提高精准度。
📊 技术性能对比
| 技术名称 | 核心优势 | 应用领域 | 性能提升 |
|---|---|---|---|
| FP8 | 存储效率高,算力优化 | 大模型训练、高效推理 | 🚀 显存降低30%+ |
| MLA | 硬件加速,动态调度 | Transformer、边缘设备推理 | 🚀 训练速度翻倍 |
| MOE | 参数高效,动态激活 | 推荐系统、多任务学习 | 🚀 减少50%计算 |
🔮 未来趋势与总结
FP8、MLA和MOE的融合,是AI技术向更高效率、更低成本发展的典型案例。尤其在DeepSeeK-V3的推动下,这些技术展现出了广阔的应用前景。
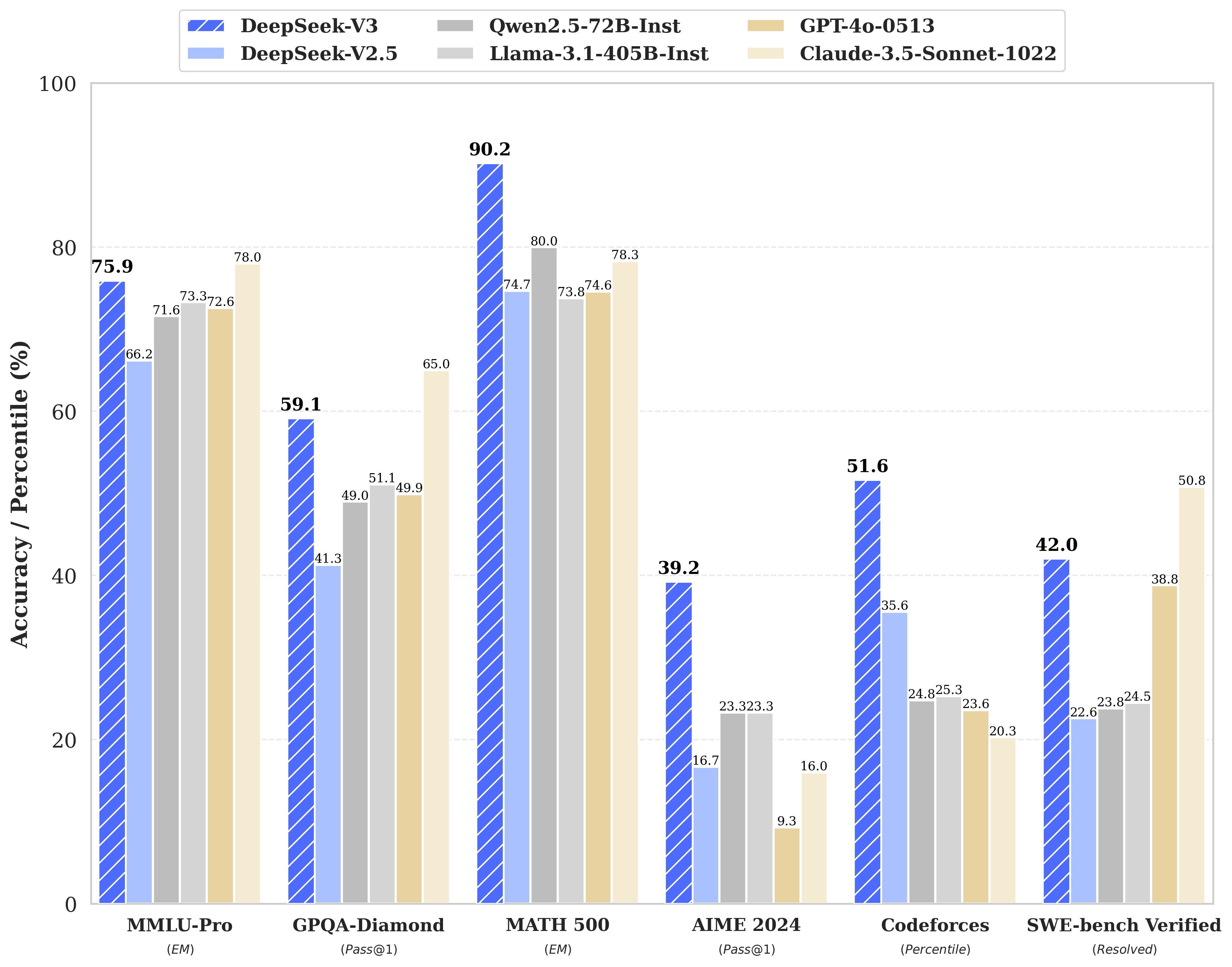
未来,我们或许会看到FP8进一步提升为FP4、MLA全面嵌入边缘设备,而MOE则可能成为超大规模模型的标配策略。这些创新将共同推动AI迈向新高度!🌐✨

😺 猫头虎技术团队温馨提醒:如果本文对你有所帮助,别忘了点赞、分享!更多技术干货,欢迎关注我们的公众号【猫头虎技术团队】!
粉丝福利
👉 更多信息:有任何疑问或者需要进一步探讨的内容,欢迎点击文末名片获取更多信息。我是猫头虎,期待与您的交流! 🦉💬
🌐 第一板块:
- 链接:[直达链接]https://zhaimengpt1.kimi.asia/list

💳 第二板块:最稳定的AI全平台可支持平台
- 链接:[粉丝直达链接]https://bewildcard.com/?code=CHATVIP


联系我与版权声明 📩
- 联系方式:
- 微信: Libin9iOak
- 公众号: 猫头虎技术团队
- 版权声明:
本文为原创文章,版权归作者所有。未经许可,禁止转载。更多内容请访问猫头虎的博客首页。
点击✨⬇️下方名片⬇️✨,加入猫头虎AI共创社群,交流AI新时代变现的无限可能。一起探索科技的未来,共同成长。🚀


















 5089
5089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









