






一、KNN算法是什么?
KNN算法是一种基本的机器学习算法,用于分类和回归任务。它是一种无参数学习算法,也被称为懒惰学习算法,因为它不会从训练数据中显式地学习模型参数。在KNN算法中,通过将新的输入样本与训练样本进行相似度度量,来进行分类或回归预测。
二、KNN算法基本工作原理
通过选择最近邻居的多数类别(分类任务)或平均值(回归任务)来对待预测样本进行分类或回归。
三、KNN算法基本步骤
对于分类任务:
- 计算训练集中每个样本与待预测样本之间的距离或相似度。
- 根据距离或相似度的大小,选择K个最近邻的训练样本。
- 统计这K个最近邻样本中出现最频繁的类别作为待预测样本的类别。
对于回归任务:
- 计算训练集中每个样本与待预测样本之间的距离或相似度。
- 根据距离或相似度的大小,选择K个最近邻的训练样本。
- 使用K个最近邻样本的输出值的平均值作为待预测样本的输出值。
四、KNN算法k值选取
1.当训练数据集较小时:
选择较小的K值可以减少噪声的影响,但也容易受到局部特征的干扰。
2.当训练数据集较大时:
选择较大的K值可以使决策边界更加平滑,但可能会导致错分类的概率增加
五、KNN算法实践
使用KNN算法预测一个人是否得癌症并输出此结论正确的概率
1.代码和实现思路:

使用csv包读取名为"Prostate_Cancer.csv"的数据文件,将其转换为字典格式存储在datas列表中。
![]()
使用random.shuffle函数打乱datas列表的顺序。

根据留一法将datas列表划分为训练集train_set和测试集test_set

定义了计算欧氏距离的distance函数,用于计算两个数据点之间的距离,并设置K值为5
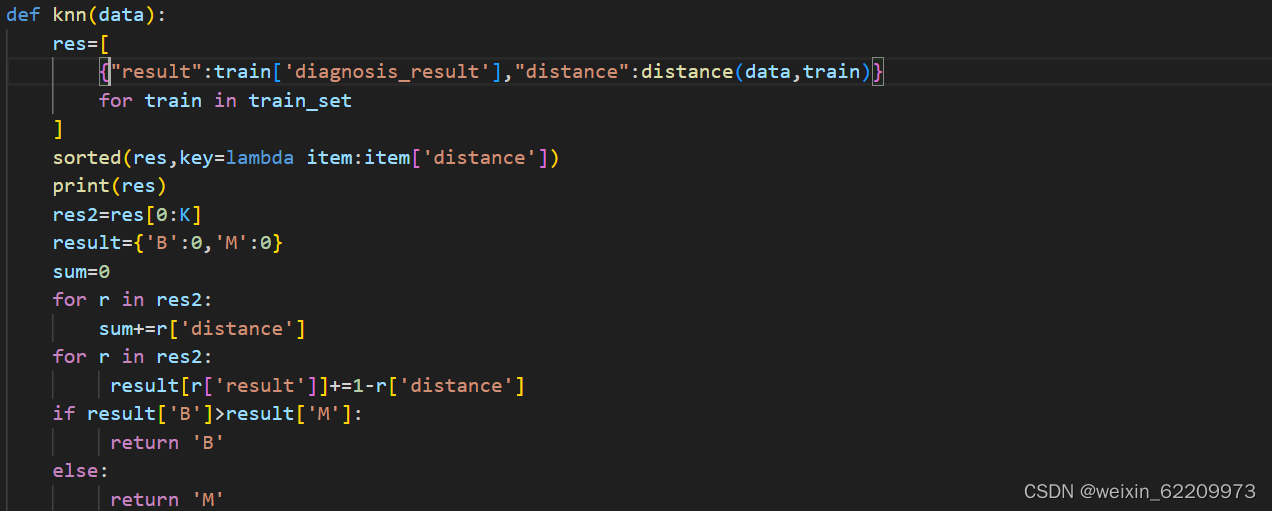
定义一个knn函数,用于进行KNN分类:
在函数内部,遍历训练集train_set中的每个数据点,并计算其与输入数据点之间的距离。将计算的结果以字典的形式存储在res列表中,包括训练数据点的分类结果和与输入数据点的距离。使用sorted函数对res列表按照距离进行排序。取出前K个距离最小的数据点。对K个数据点进行加权平均,根据权重大小得出最终的分类结果。
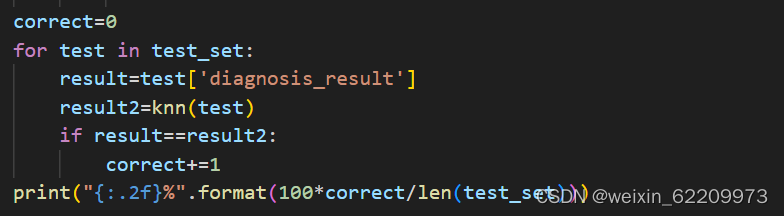
定义correct变量并初始化为0,用于记录分类准确的样本数量。遍历测试集test_set中的每个数据点,分别计算其真实分类结果和KNN分类结果,并统计分类准确的样本数量。
2.运行结果

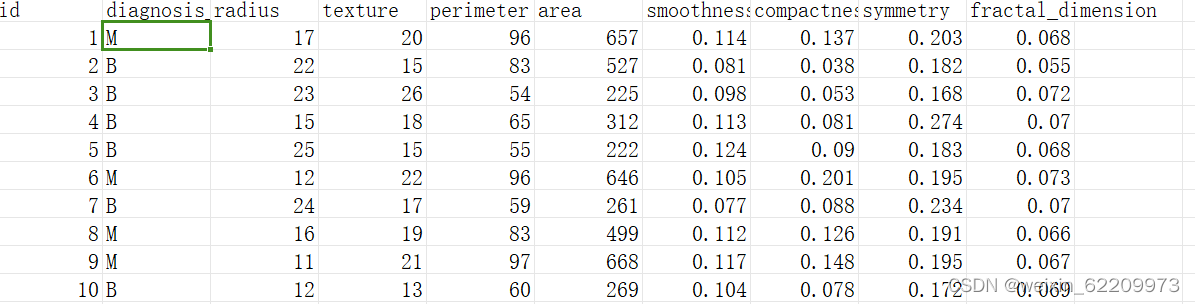
输出结果中:B为良性(无癌症),M为恶性(有癌症)
数据集:















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









