






一、PR曲线
1.1原理
PR曲线是Precision-Recall(精确率-召回率)曲线的简称,用于评估二分类模型在不同阈值下的性能表现。PR曲线的横轴是召回率(Recall),纵轴是精确率(Precision),通过绘制不同阈值下的精确率和召回率之间的关系,可以直观地展示模型在不同阈值下的整体性能。
召回率是衡量模型对实际正例样本的识别能力,即模型能够正确预测出多少实际正例。计算公式为:Recall=TP/(FN+TP)。
准确率是衡量模型在预测为正例的样本中真正为正例的比例,即模型预测为正例的样本中有多少是真正的正例。计算公式为:Precision=TP/(FP+TP)。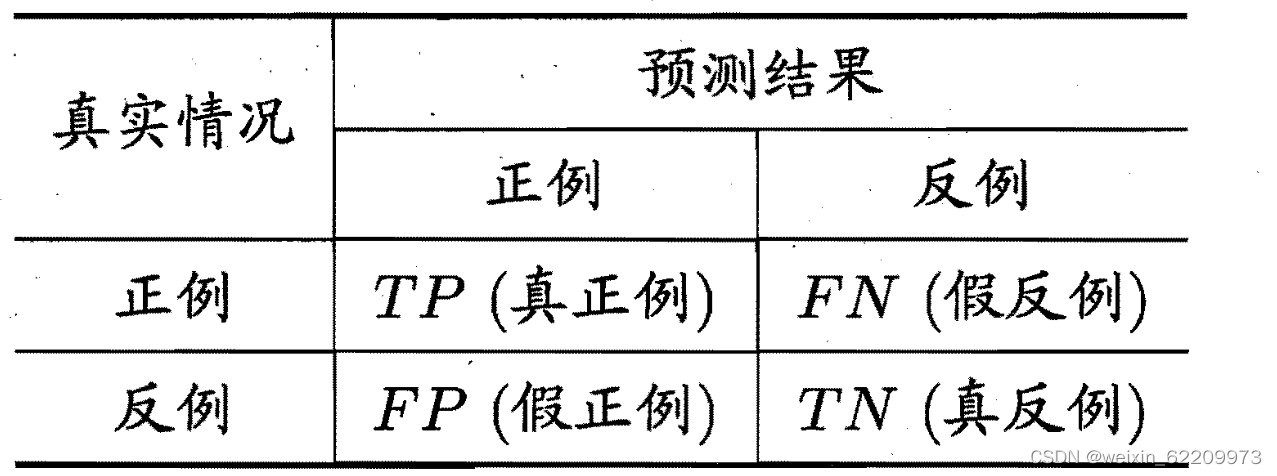
以下有一个例子:有十条狗,5条患有狂犬病,另外5条未患有狂犬病
| 实际情况 | 预测结果 |
| 未患病 | 患病 |
| 未患病 | 患病 |
| 未患病 | 未患病 |
| 未患病 | 未患病 |
| 未患病 | 患病 |
| 患病 | 未患病 |
| 患病 | 未患病 |
| 患病 | 患病 |
| 患病 | 患病 |
| 患病 | 未患病 |
根据上表可得:
TP(True Positive):2 即实际情况为“患病”,预测结果为“患病”的。
FP(False Positive):3 即实际情况为“未患病”,预测结果为“患病”的人数。
TN(True Negative):2 即实际情况为“未患病”,预测结果为“未患病”的人数。
FN(False Negative):3 即实际情况为“患病”,预测结果为“未患病”的人数。
召回率Recall=TP/(FN+TP)=2/(3+2)=0.4
准确率Precision=TP/(FP+TP)=2(2+3)=0.4
因此,在这个例子中,召回率和查准率都是0.4。这意味着我们的模型能够正确地识别出40%的真实正例,并且在所有预测为正例的样本中有40%是真正的正例。
1.2代码实现
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
# 真实标签和预测概率
y_true = [0, 0, 1, 1]
y_scores = [0.11, 0.45, 0.35, 0.8]
# 计算 Precision-Recall 曲线的数据
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
# 绘制 PR 曲线
plt.plot(recall, precision)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.show()运行结果: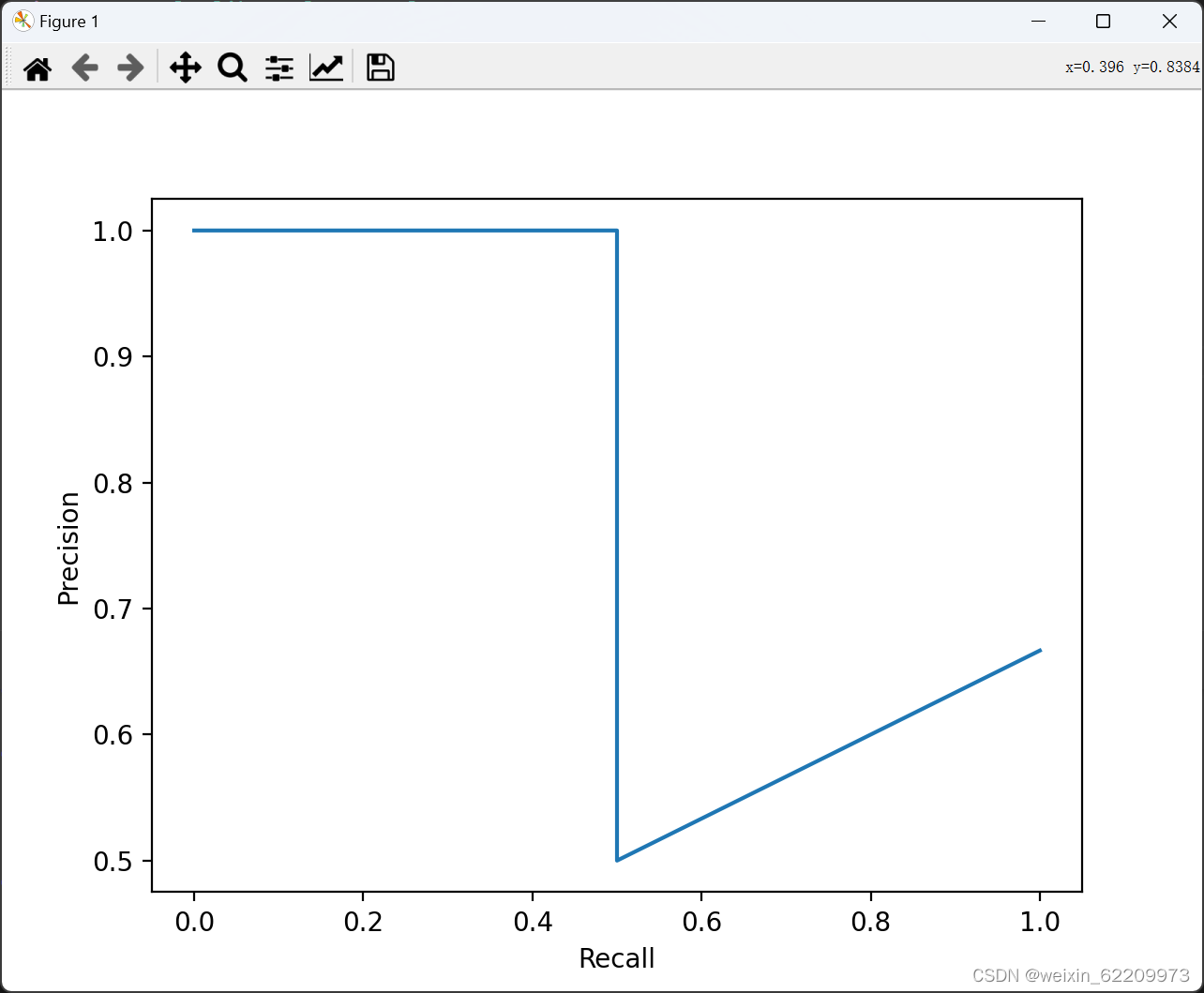
二、ROC曲线
2.1、原理
ROC(Receiver Operating Characteristic)曲线是一种常用的二分类模型性能评估工具,它以真阳率(True Positive Rate,TPR)为纵轴,假阳率(False Positive Rate,FPR)为横轴绘制,这两个重要的性能指标是绘制ROC曲线的基础。
真阳率(TPR)也称为灵敏度(Sensitivity)或命中率(Recall),表示模型正确预测为正例的样本占所有正例样本的比例,计算公式为 TPR = TP / (TP + FN),其中 TP 表示真正例数量,FN 表示假反例数量。
假阳率(FPR)表示模型错误预测为正例的样本占所有负例样本的比例,计算公式为 FPR = FP / (FP + TN),其中 FP 表示假正例数量,TN 表示真反例数量。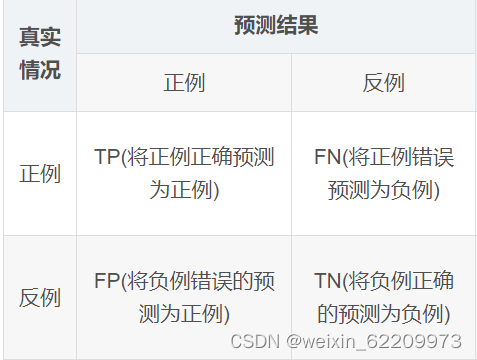
再以上面的患病为例子:
| 实际情况 | 预测结果 |
| 未患病 | 患病 |
| 未患病 | 患病 |
| 未患病 | 未患病 |
| 未患病 | 未患病 |
| 未患病 | 患病 |
| 患病 | 未患病 |
| 患病 | 未患病 |
| 患病 | 患病 |
| 患病 | 患病 |
| 患病 | 未患病 |
TP(True Positive):2 即实际情况为“患病”,预测结果为“患病”的。
FP(False Positive):3 即实际情况为“未患病”,预测结果为“患病”的人数。
TN(True Negative):2 即实际情况为“未患病”,预测结果为“未患病”的人数。
FN(False Negative):3 即实际情况为“患病”,预测结果为“未患病”的人数。
真阳率:TPR = TP / (TP + FN)=2/(2+3)=0.4
假阳率:FPR = FP / (FP + TN)=3/(3+2)=0.4
2.2代码实现
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# 真实标签和预测概率
y_true = [0, 0, 1, 1]
y_scores = [0.11, 0.45, 0.35, 0.8]
# 计算 ROC 曲线的数据
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
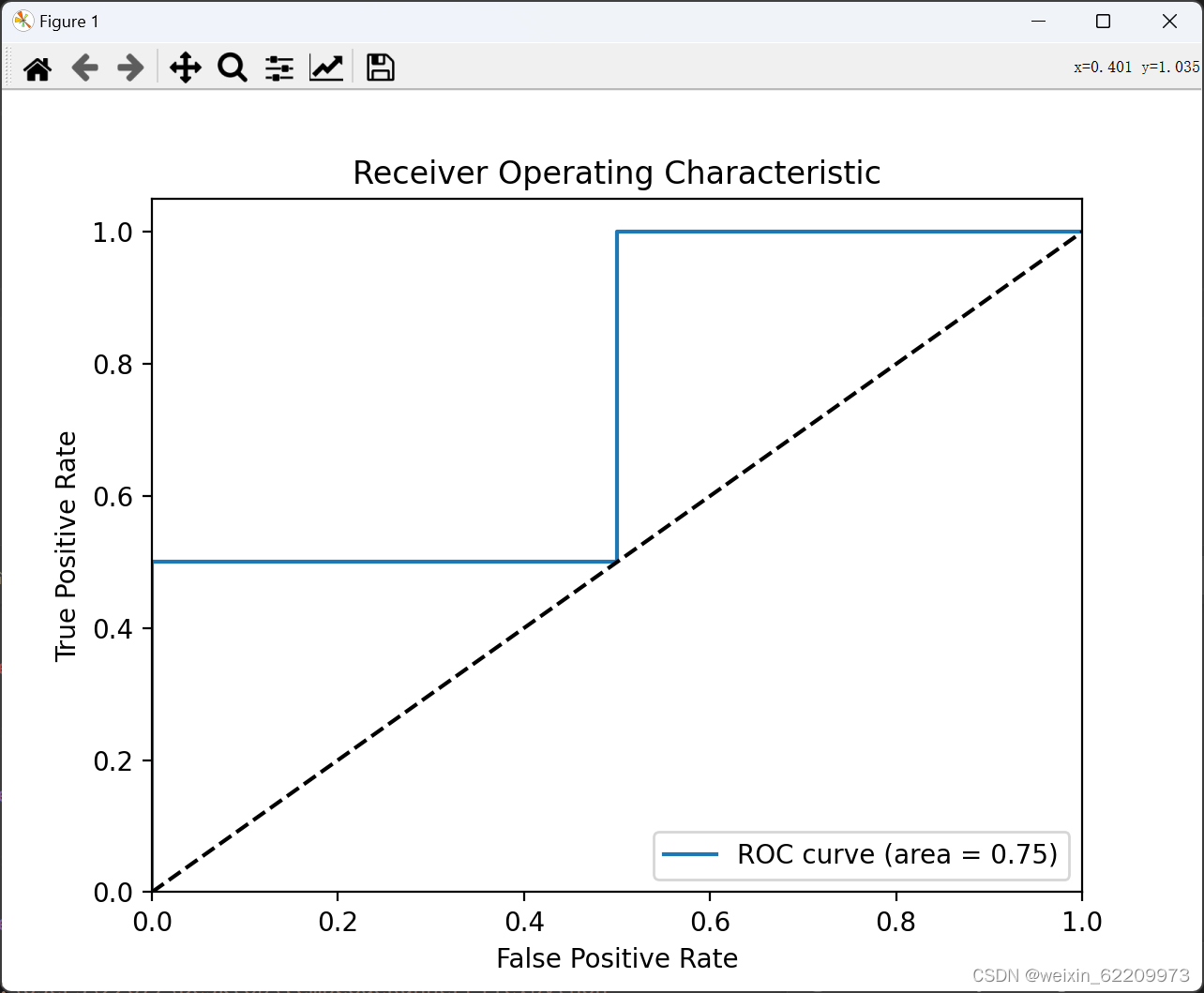
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--') # 对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()运行结果:
三、实验小结
PR曲线以查准率(Precision)为纵轴,召回率(Recall)为横轴,可以反映出模型在不同阈值下的精确度和召回率之间的平衡关系。适用于数据不平衡的情况,例如正例样本较少的分类问题。
ROC(Receiver Operating Characteristic Curve)曲线以真阳率(TPR)为纵轴,假阳率(FPR)为横轴,可以反映出模型在不同阈值下的灵敏度和特异度之间的平衡关系。通过改变模型的分类阈值,观察模型在不同条件下的误判情况。
两者曲线相比,ROC曲线适用于数据分布均衡的二分类问题,能够全面评估模型在不同阈值下的性能。而PR曲线适用于数据不平衡的二分类问题,重点关注模型的查准率和召回率。
通过ROC曲线和PR曲线可以直观地了解模型在不同条件下的表现,并根据实际需求选择合适的分类阈值。















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









