







 本文概述了YOLO系列从v1到v8的目标检测算法的发展,包括结构改进、性能提升和面临的挑战。YOLOv8尤其突出在速度和精度上的显著进步,成为实时检测器的首选。
本文概述了YOLO系列从v1到v8的目标检测算法的发展,包括结构改进、性能提升和面临的挑战。YOLOv8尤其突出在速度和精度上的显著进步,成为实时检测器的首选。
YOLOv1、v3、v5、v7、v8
1.YOLO(2015)

结构
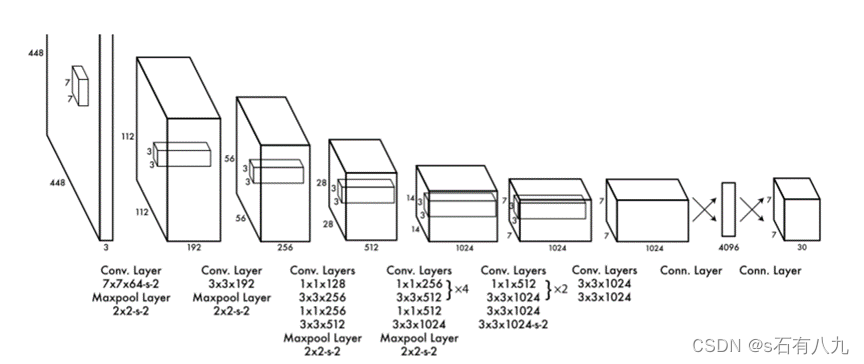
YOLO检测网络包括24个卷积层和2个全连接层
其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
- YOLO网络借鉴了GoogLeNet分类网络结构。不过使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
- YOLO论文中,作者还给出一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。
- Loss函数使用均方和误差,即网络输出的SxSx(Bx5 + C)维向量与真实图像的对应SxSx(Bx5 + C)维向量的均方和误差。
coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
训练:
batchsize=64 momentum=0.9 decay=0.0005 前期:learning rate= 10−3 to 10−2.后期10−2训练75个epoch,然后用10−3训练30个epoch,最后用10−4训练30个epoch。dropout layer with rate =0.5 数据增强:20%的随机缩放和平移,随机调整曝光和饱和度的图像在HSV颜色空间的一个因子1.5
优点:
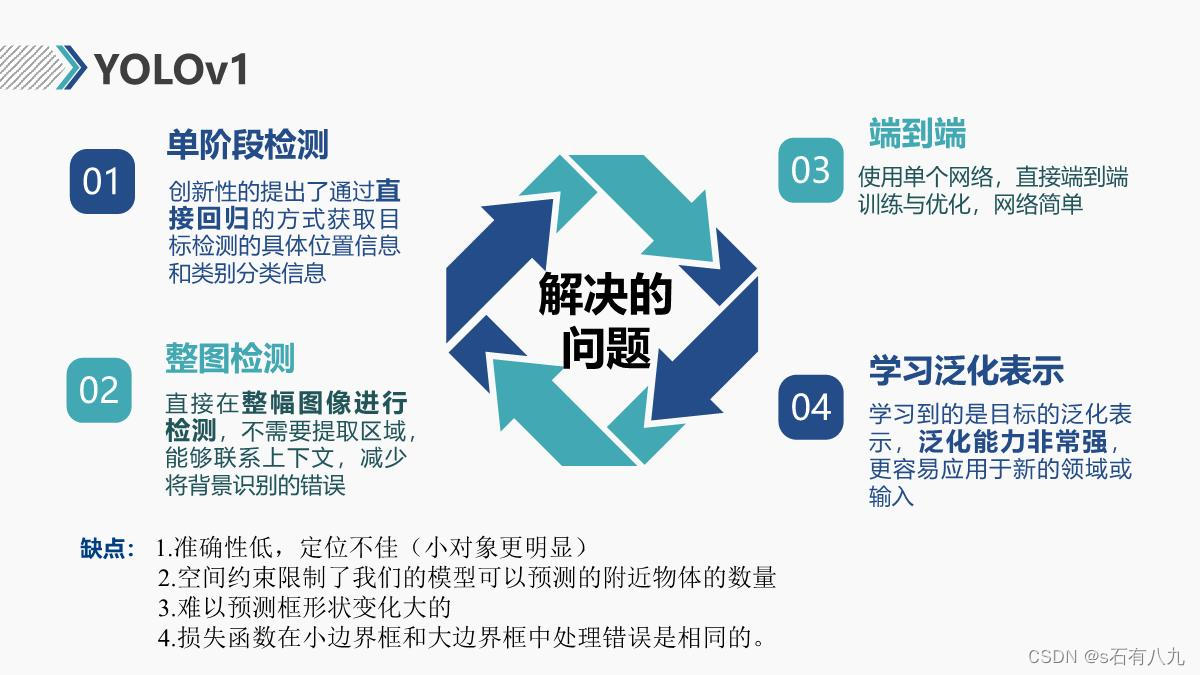
- 速度快,将检测视为回归问题(平均精度也高)
- 对图像进行全局推理,关联背景上下文(背景错误少)
- 学习对象的通用模式(相当于模板),推广性强
缺点:
- 准确性低,定位不佳(小对象更明显)
- 空间约束限制了我们的模型可以预测的附近物体的数量
- 难以预测框形状变化大的
- 损失函数在小边界框和大边界框中处理错误是相同的。
2.YOLOv2(2016) YOLO9000: Better, Faster, Stronger
1. 结构
数据集:ImageNet的9000多个类
yolov2主要集中在提高召回率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4653
4653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









