






习题4-1 对于一个神经元,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢。
此神经元对 求导后的结果为
,可见,若输入
恒大于 0 ,则在当前batch上,所有数据的梯度都同号(大于 0 或小于 0 ),使得权重更新时发生抖动,如图1-1中的红线:
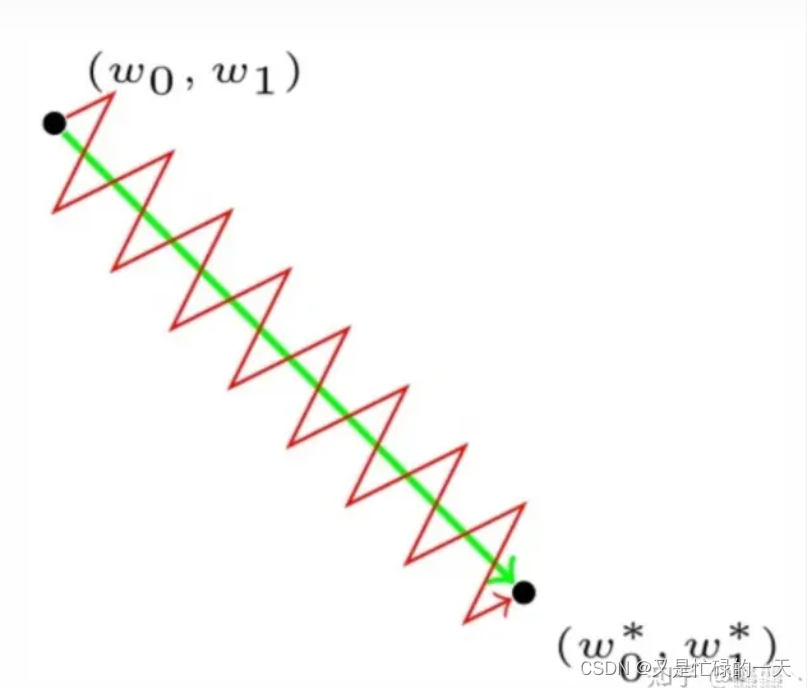
同时,对于sigmoid函数来说,当数据趋向于 0 时导数最大,若数据很大,则会出现梯度消失的现象,导致权值更新缓慢。
习题4-5 如果限制一个神经网络的总神经元数量(不考虑输入层)为 N+1 ,输入层大小为  ,输出层大小为 1 ,隐藏层的层数为 L ,每个隐藏层的神经元数量为
,输出层大小为 1 ,隐藏层的层数为 L ,每个隐藏层的神经元数量为  ,试分析参数数量和隐藏层层数 L的关系.
,试分析参数数量和隐藏层层数 L的关系.
这里只考虑 W 参数,若要计算其他参数如 b 或阈值之类的,方法类似:
令参数数量为 t
由于简单的前馈神经网络中都是全连接层,即第 i层中所有结点与第 i+1 层中所有结点两两互连,因此每两层之间的参数为两层结点数量相乘。例如,第 i 层中有 x 个结点,第 i+1 层中有 y 个结点,则其间的参数有 xy 个。
因此,分为三部分来看:输入层与第二层之间的参数、隐藏层之间的参数、倒数第二层与输出层之间的参数,分别令其为 t1,t2,t3
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
在神经网络中,偏置项b是一个常数,它不会随着输入数据的变化而变化,所以对偏置项进行正则化并不会对模型的泛化能力产生影响。
此外对偏置项进行正则化可能会使模型更加复杂,因为偏置项通常只有一个,而且其取值通常很小。如果对偏置项进行正则化,可能会使得模型过于关注偏置项的取值,从而导致模型过拟合。
因此,在神经网络模型的结构化风险函数中通常不对偏置项进行正则化。相反,我们通常只对权重进行正则化,以减少模型的复杂度,并提高其泛化能力。
习题4-8 为什么在用反向传播算法进行参数学习时要采用随即参数初始化的方式而不是直接令W=0,b=0?
若令 W=0,b=0 ,那么第一次计算时,隐层神经元的计算结果都一样,并且在反向传播时参数更新也一样,导致在每两层之间的参数都是一样的,这样相当于隐层只有 1 个神经元。
习题4-9 梯度消失问题是否可以通过增加学习率来缓解?
梯度消失问题是指在深层神经网络中,反向传播过程中的梯度逐层相乘导致梯度值逐渐减小,甚至变得非常接近于零的情况。这会导致深层网络的参数更新变得非常缓慢,甚至无法进行有效的学习。
增加学习率可能会在一定程度上缓解梯度消失问题,但是这种方法并不总是有效的,而且可能会引入新的问题。比如:增大学习率带来的缺陷会比梯度消失问题更加严重,学习率变大时,很容易使得参数跳过最优值点,然后梯度方向改变,导致参数优化时无法收敛。

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









