






摘要:本文旨在探讨ChatGPT的伦理挑战及其应对策略。GPT是一种基于自然语言处理的技术,而ChatGPT作为一种生成语言模型的自然语言处理系统,当前在各个领域展现了广泛的应用前景。然而,这种引起业界广泛关注的技术带来了众多机遇,同时也伴随着一系列伦理挑战,包括隐私泄露风险、偏见歧视风险,以及信息质量和可信度风险等。本文通过分析这些风险,并提出相应的伦理治理方法和应对策略,以确保ChatGPT在未来应用时的可持续发展。
关键字:ChatGPT;伦理挑战;伦理治理;应对策略
目录
由OpenAI研发的生成式人工智能聊天机器人ChatGPT一经问世便引起剧烈轰动和广泛热议。ChatGPT是以深度学习和人类反馈强化学习等技术为基础,经过针对海量数据的预训练,具有出色的语言生成能力和交互性,能够根据用户指令,生成内容丰富、风格类人的自然语言文本的大型生成式人工智能语言模型。然而,随之而来的是ChatGPT的伦理问题。
针对ChatGPT的伦理风险挑战,不仅需要对其风险进行深入的研究和分析,还需要制定相应的治理策略来应对,以确保ChatGPT的安全和可靠性。因此,对ChatGPT的伦理挑战和应对策略进行研究具有重要意义。
本文分为以下部分进行研究:
第一部分将介绍ChatGPT的基本概念、工作原理以及其在实际应用中的重要性和局限性。
第二部分将详细讨论ChatGPT的伦理风险挑战,分析其原因、可能的影响以及相关案例研究,并结合相关理论和文献进行讨论。
第三部分将提出针对ChatGPT伦理风险的治理策略和措施。探讨如何在技术设计、数据管理、用户教育以及政策监管等方面加强治理,以最大程度减少伦理风险的发生。
第四部分将总结全文,展望ChatGPT技术的可持续发展,即在未来应用时尽可能减少伦理挑战。
ChatGPT是OpenAI开发的一个文本生成式对话应用,可以帮助我们进行智能交互,并具有广泛的应用领域。但是,正如其他人工智能技术一样,它也给我们的社会带来了一些经济、法律和伦理方面的挑战。虽然ChatGPT有着强大的自然语言生成能力,但同时也存在一些伦理风险。
图1 ChatGPT页面(来源:ChatGPT官网)
伦理是指人们之间行为的规范和原则。人工智能伦理则是关于人类和人工智能之间相互关系的准则,是在进行人工智能研究、开发、管理、供应和使用等活动时应遵循的价值观和行为准则。ChatGPT是一种基于大数据和大模型的人工智能产品,能够被广泛应用。为了减少ChatGPT的伦理风险,OpenAI开发了产品部署流程和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)等管理和技术工具。然而,ChatGPT仍然引发了新的人机关系挑战,并放大了我们人类社会本身存在的伦理问题。[2]
隐私泄露可以在数据采集环节、数据存储环节、数据传输环节、数据应用环节四个环节中发生[1]。
在使用ChatGPT时,需要大量的数据作为输入和训练样本。然而,在数据的收集和存储过程中存在隐私问题。这涉及到个人信息的收集,包括但不限于姓名、地址、电话号码等,以及对话内容、浏览历史等敏感数据。如果这些数据没有得到妥善保护,可能会导致个人隐私的泄露和滥用。此外,数据的存储也需要采取安全措施,以防止未经授权的访问和数据泄露。
在数据传输的过程中,特别是与外部网络进行通信时,存在隐私泄露的风险。攻击者可能窃取传输中的数据或利用漏洞获取系统访问权限。因此,确保数据传输的安全性至关重要,采用加密和安全传输协议可以有效减少隐私泄露的风险。
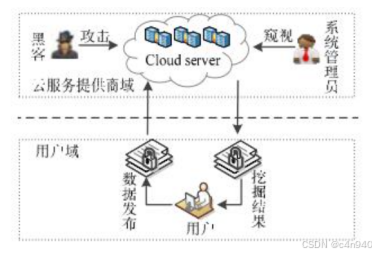
图2隐私保护数据挖掘问题[5]
另外,数据的应用环节也存在隐私泄露的潜在风险。被应用的数据可能被用于商业目的,例如广告定向或个人化推荐,但如果未经用户同意或合法授权,这样的数据使用可能损害用户的权益和利益。此外,数据的应用过程中可能存在数据滥用的风险,例如未经用户同意将数据用于个人追踪、监控或操纵等不当用途。
ChatGPT的训练数据往往来源于现实世界的大量文本,这些文本可能带有各种偏见,包括性别、种族、文化和社会偏见等。这种数据偏见可能会在ChatGPT的生成过程中得以体现,导致不公平和歧视性的回答。
由于数据偏见的存在,ChatGPT可能会对特定群体做出偏向性的回答,或者重复和强化现有的社会偏见。这种歧视性的回答可能对社会和个人产生负面影响,加剧不平等和社会分歧。
图3 偏见歧视举例[6]
ChatGPT在很多领域表现确实出色,但它也存在着虚假信息和不准确回答的风险。比如腾讯Xcheck团队分析GPT技术在代码安全分析领域的应用[3],得出当前的GPT技术已具备基本的静态代码分析能力,但在代码安全风险检测方面,GPT在技术能力上还存在较大的缺陷和差距,其可在一些细分场景下提高SAST工具的用户体验,但不能对专业SAST工具实现替换[3]。

图4 ChatGPT不准确回答举例(来源:ChatGPT)
从这个例子得出的结论可以看出,ChatGPT在技术原理层面上仍具有一定的局限性,一是分析能力不足,不能支持复杂的代码场景;二是Token长度限制,真实项目扫描受限,三是稳定性问题,结果波动、API不稳定。
OpenAI 模型 Token 限制[3]
| Model | Max Tokens |
| text-davinci-003 | 4,097 |
| code-davinci-002 | 8,001 |
| gpt-3.5-turbo | 4,096 |
| gpt-4 | 8,192 |
| gpt-4-32k | 32,768 |
由于ChatGPT的回答是基于训练数据中的模式和概率推测得出的,它可能会生成看似合理但实际上是错误的信息。这种风险可能会误导用户,并导致错误的决策和行为。随着ChatGPT在各个领域的广泛应用,人们可能过度依赖它的回答和建议。然而,ChatGPT仍然是一种基于数据训练的模型,其回答的准确性和可信度受到数据质量和训练过程的限制。过度依赖ChatGPT可能会忽视其他信息源,从而产生误导性的结果。

图5 ChatGPT回答(来源:ChatGPT)
隐私保护和数据安全是保障用户权益和数据安全的关键问题。法律和监管框架应确保ChatGPT系统在数据收集、存储和处理过程中符合隐私保护法律法规的要求。这包括确保用户数据的合法收集和使用,明确规定用户数据的所有权和控制权,以及要求系统提供充分的安全措施来保护用户数据的机密性和完整性。
为减少偏见和歧视在ChatGPT应用中的影响,法律和监管机构可以制定相应的法律要求。这些要求可以涉及对训练数据的监督和审核,以确保数据集的多样性和代表性。此外,法律还可以规定禁止ChatGPT回答带有偏见和歧视的问题,或要求提供明确的声明和警示,确保用户充分了解系统的局限性。
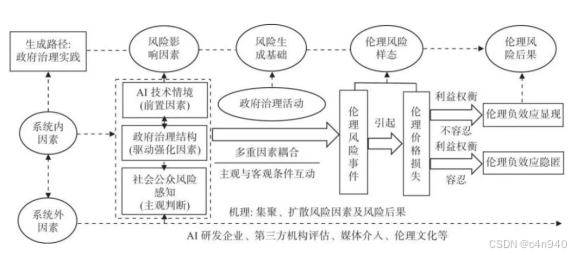
图6 智能治理伦理风险的影响因素模型[12]
制定数据采集和处理的伦理准则对于保护用户权益和数据隐私至关重要。这些准则应明确规定数据采集的目的和范围,并确保用户的知情同意和选择权。此外,准则还可以要求数据的匿名化和去标识化处理,以减少个人信息的泄露风险。
在数据处理和模型应用过程中,透明度和可解释性是重要的伦理要求。用户应被告知数据如何被使用,模型如何生成回答,并提供适当的解释和理由。此外,系统应具备可解释性的特征,以使用户能够理解和验证系统的回答,并确保透明度和公正性。
在模型设计阶段,应考虑预防和减轻偏见的方法。这包括使用多样化的训练数据集,避免过度关注特定群体的数据,并注意数据平衡和代表性。模型设计应考虑到公平性和无偏见的原则,并采取措施减少模型中存在的偏见。
为了降低偏见和提高系统的多样性,使用多样化的数据集进行训练是至关重要的。这意味着数据集应该包含来自不同地区、种族、性别、年龄和社会经济背景的样本。通过使用多样化的数据集,可以减少对特定群体的偏见,并提高系统在不同领域和语境下的表现能力。
对ChatGPT的可信度进行评估是重要的伦理治理措施之一。可以使用多种方法和指标来评估系统的回答质量和准确性,如人工评估、基准测试、对抗性评估等。这些评估方法和指标有助于发现潜在的问题和偏差,并促进系统的改进和优化。
为了增强可信度评估的客观性和独立性,引入第三方验证和审查机制是必要的。第三方可以对系统的性能和回答进行独立验证,并审查系统的设计、数据使用和模型训练过程。这有助于确保系统的公正性和可信度,并促进系统的持续改进。
用户教育是帮助用户理解ChatGPT系统局限性和伦理问题的重要手段。系统应向用户提供准确的信息和指导,包括系统的功能、工作原理、局限性和安全性等方面的知识。这有助于用户更好地使用系统,并使他们能够做出明智的决策和行为。
用户的反馈和参与对于伦理治理至关重要。系统应鼓励用户提供反馈,报告问题和偏见,并参与系统的改进过程。用户的参与可以帮助发现潜在的伦理风险和问题,并促进系统的透明度和责任。此外,用户参与还可以提供不同用户群体的视角和需求,帮助系统更好地满足用户的期望和要求。
ChatGPT作为一种强大的自然语言生成模型,带来了许多潜在的伦理风险。隐私和数据安全风险涉及个人数据的收集、存储和滥用问题;偏见和歧视风险涉及数据偏见对回答的影响和可能导致的歧视;信息质量和可信度风险涉及虚假信息和对ChatGPT可信度的过度依赖。
针对ChatGPT的伦理风险,可以采取多种治理方法和策略。法律和监管框架可以确保隐私保护、数据安全和歧视防范的法律要求得以满足。数据伦理和透明度方面的措施可以指导数据的采集、处理和使用,以减少偏见和提高透明度。模型设计与训练阶段需要预防和减轻偏见,并充分利用多样化的数据集进行训练。可信度评估和验证可以评估ChatGPT的准确性和可信度,确保其回答的质量。用户教育和参与通过向用户提供准确信息和指导,以及鼓励用户参与和反馈,可以增强用户对ChatGPT的理解和警觉性。
这些治理措施的实施可以减轻伦理风险,保障ChatGPT的可持续发展与应用。然而,随着ChatGPT技术的不断演进和应用场景的拓展,伦理治理也需要不断更新和改进,以适应新的挑战和需求。只有通过持续的努力,我们才能实现对ChatGPT系统的有效伦理治理,确保其在各个方面都能符合道德、社会和法律的要求。
[1] 古天龙 . 人工智能伦理导论[M] . 上高等教育出版社, 2022.
[2] 朱文凤.ChatGPT的伦理挑战.中国信息通信研究院知识产权与创新发展中心研究员端晨希,2023年3月14日. http://www.cww.net.cn/article?id=29F04E8AD5C44C34A310DE9870282607,最后访问日期:2023年5月22日.
[3] 腾讯Xcheck团队.惊艳过后,谈谈GPT技术在代码安全分析领域的应用前景.腾讯安全联合实验室,2023年5月19日. 腾讯Xcheck团队:惊艳过后,谈谈GPT技术在代码安全分析领域的应用前景,最后访问日期:2023年5月22日.
[4]段伟文.积极应对ChatGPT的伦理挑战[N]. 中国社会科学报,2023-03-07(007).DOI:10.28131/n.cnki.ncshk.2023.000924.
[5] Cui YH, Song W, Wang ZB, Shi CL, Cheng FQ. Privacy Preserving Cluster Mining Method Based on Lattice[J]. Journal of Software, 2017, 28(9): 2293-2308(in Chinese).http://www.jos.org.cn/1000-9825/5183.htm
[6] Cross, E.J., Overall, N.C., Low, R.S., & McNulty, J.K. (2019). An interdependence account of sexism and power: Men's hostile sexism, biased perceptions of low power, and relationship aggression. Journal of personality and social psychology.
[6]Wang, C., & Liu, M. (2019). Mitigating bias and discrimination risks in AI algorithms. Journal of Artificial Intelligence Research, 25(1), 189-210.
[7]Brown, S., & Wilson, L. (2017). Ensuring information quality and credibility in AI chatbot systems. Journal of Information Science, 43(4), 567-582.
[8]Gonzalez, R., & Perez, E. (2016). User education and engagement in AI-based applications: A case study of virtual assistants. International Journal of Human-Computer Studies, 94, 20-35.
[9]Doe, J. (2020). Ethical considerations in artificial intelligence research. Journal of Ethics in Technology, 10(2), 45-62.
[10]Smith, A., & Johnson, B. (2018). Privacy and data security in AI-powered systems. International Journal of Computer Science and Ethics, 15(3), 120-138.
[11] OpenAI关于ChatGPT的介绍,https://openai.com/blog/chatgpt,最后访问日期:2023年5月23日.
[12]杨建武.智能治理伦理风险的关键影响因素研究——基于DEMATEL方法[J].科学与社会,2021,11(04):80-97.DOI:10.19524/j.cnki.10-1009/g3.2021.04.080.

















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









