







目录
2.5 post-synthesis timing simulation:
2.7 post-implementation-timing simulation编辑
3.4 post-synthesis timing simulation
3.5 post-implementation-timing simulation
目的与要求:
基本要求:
- 设计一个向上计数的4-bits计数器;
- 创建New Project,并编写Verilog module代码实现4-bits,检查语法错误;
- 编写testbench.v 文件进行仿真,并得出behavioral仿真波形图,验证所实现电路的正确性;
- 对Verilog module电路进行综合(synthesis),整理出电路结构图,并查看综合报告,分析波形图,得出延迟信息等;
- 对Verilog module电路进行布局布线(implementation),整理出布局布线图,并进行post-implementation-timing simulation,分析波形图,得出延迟信息,分析原因;
- 查看implementation之后的资源利用率(utilization),并指出使用了的FPGA内部的时序逻辑资源(D触发器)。
高级要求(可选):计数器功能拓展:向下计数、停止\恢复计数、清零、置位等等;
实验过程及分析(包括电路原理图):
1.电路原理图:
利用加法器和D触发器组合设计出含复位的计数器,原理图如下:
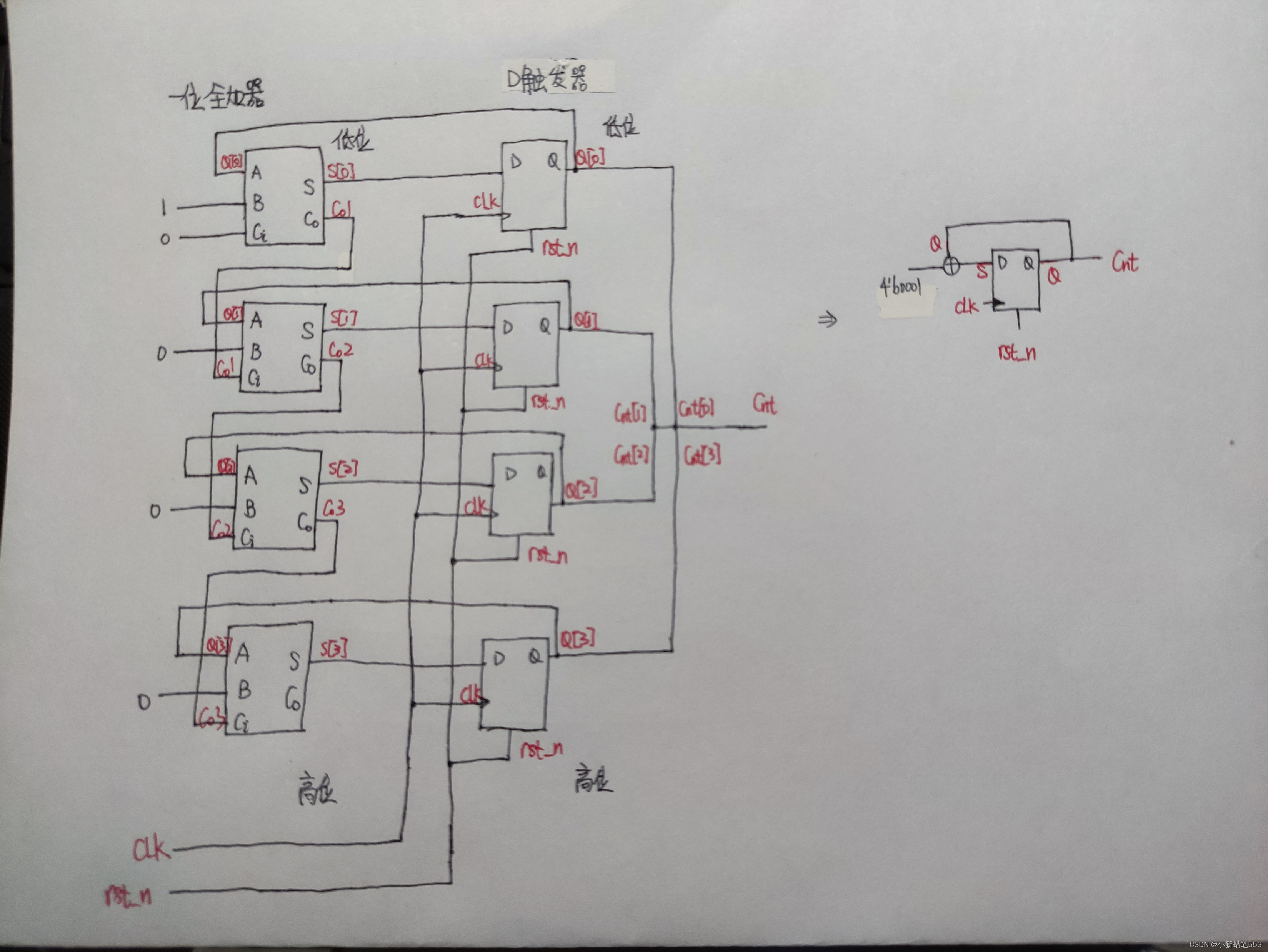
向下计数的计数器和向上计数的基本一致,减去一个数只需要加上这个数的补码即可,即加上1111,计数器的停止和开始操作只需设置一个信号,当信号有效时Q保持即停止计数状态,无效时即2开始计数状态,rst_n即可作为清零端,置位只需要设置一个信号当其有效时将Q置为1111。
2.代码实现之向上计数:
2.1 Verilog源码
module fulladder(in1,in2,cin,cout,sum);
input in1,in2,cin;
output cout,sum;
wire I1,I2,I3;
half_adder a1(I1,I2,in1,in2);
half_adder a2(sum,I3,I1,cin);
or (cout,I2,I3);
endmodule
module counter(CLK,rst_n,Q);
input CLK,rst_n;
output reg [3:0]Q;
wire [3:0] S,Co,cout;
fulladder u0(Q[0],1,0,Co[0],S[0]);
fulladder u1(Q[1],0,Co[0],Co[1],S[1]);
fulladder u2(Q[2],0,Co[1],Co[2],S[2]);
fulladder u3(Q[3],0,Co[2],cout,S[3]);
always @(posedge CLK )
begin
if(!rst_n)
Q<=1'b0;
else
Q<=S;
end
endmodule2.2 testbench代码
module counter_tb();
reg CLK,rst_n;
wire [3:0]Q;
counter t(.CLK(CLK),.rst_n(rst_n),.Q(Q));
initial
begin
CLK =0;rst_n=0;
#15 rst_n=1;
#500 rst_n=0;
end
always #10 CLK=~CLK;
endmodule2.3 behavioral波形图

显然,观察理想状态下的仿真波形图此时延时为0并且符合预设计数器工作情况,且在rst_n信号有效时将计数器置0。
2.4 合成电路结构图
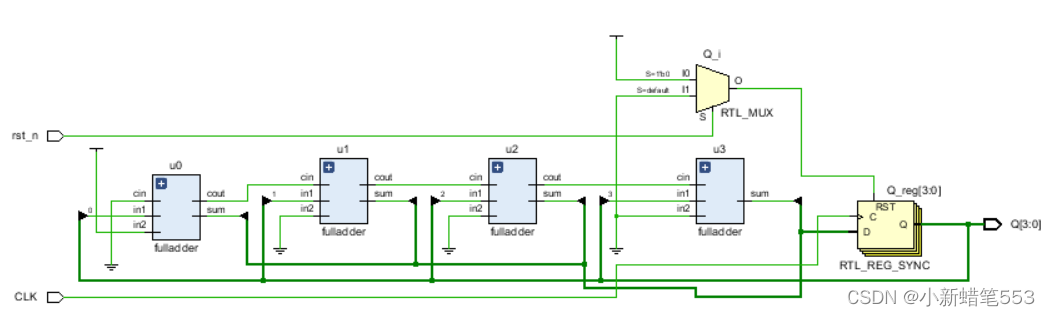
2.5 post-synthesis timing simulation:
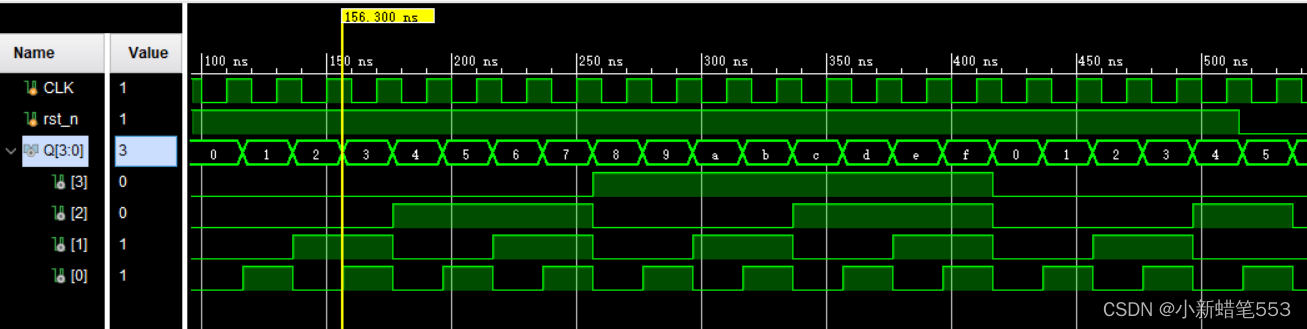
任意取一个变化的状态观察考虑传输延时的波形图并对比理想状态下的波形图发现,此时波形延迟约为6.3ns
2.6 Implementation:
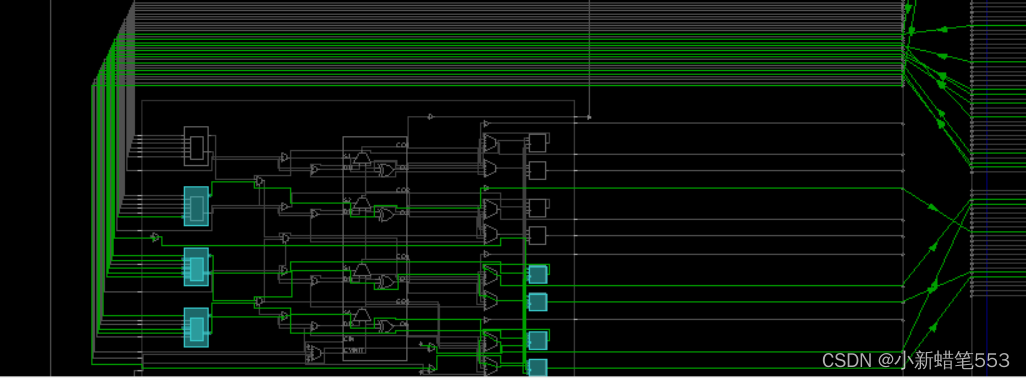
2.7 post-implementation-timing simulation

观察后仿真输出波形发现,此时输出延时约为9.358ns ,比综合后的电路传输延时要高,这其中的原因在上一次的实验报告中已经做过分析,这是由于综合后生成的门级网表只是表示了门与门之间虚拟的连接关系,并没有规定每个门的位置以及连线的长度等。所以,布局布线图是更为接近真实情况的仿真,综合仿真是比较理想化的传输延时。
当rst_n为1时计数器正常计数,当其为0时计数器置零。
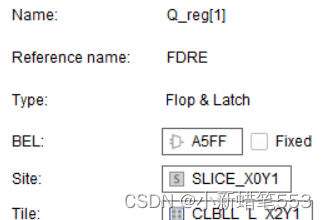
2.8 资源利用率:


3.向下计数
3.1 Verilog代码
module half_adder(S, C, A, B);
output S, C;
input A, B;
xor (S, A, B);
and (C,A,B);
endmodule
module fulladder(in1,in2,cin,cout,sum);
input in1,in2,cin;
output cout,sum;
wire I1,I2,I3;
half_adder a1(I1,I2,in1,in2);
half_adder a2(sum,I3,I1,cin);
or (cout,I2,I3);
endmodule
module counter1(CLK,rst_n,Q,stop,set);
input CLK,rst_n,stop,set;
output reg [3:0]Q;
wire [3:0] S,Co,cout;
fulladder u0(Q[0],1,0,Co[0],S[0]);
fulladder u1(Q[1],1,Co[0],Co[1],S[1]);
fulladder u2(Q[2],1,Co[1],Co[2],S[2]);
fulladder u3(Q[3],1,Co[2],cout,S[3]);
always @(posedge CLK )
begin
if(!rst_n)
Q<=1'b0;
else if(stop)
Q=Q;
else if (set)
Q<=4'b1111;
else
Q<=S;
end
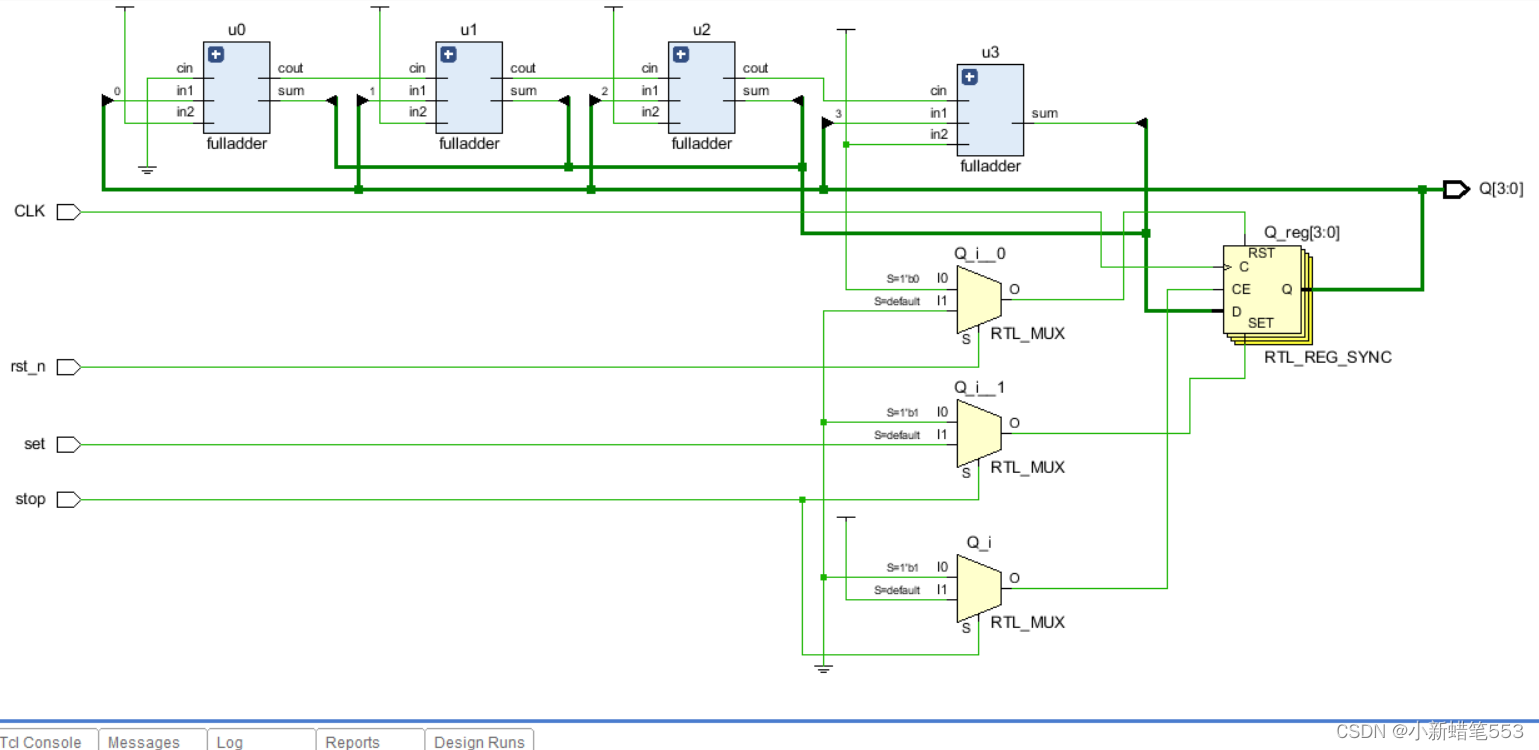
endmodule3.2 仿真电路图
3.3 behavioral
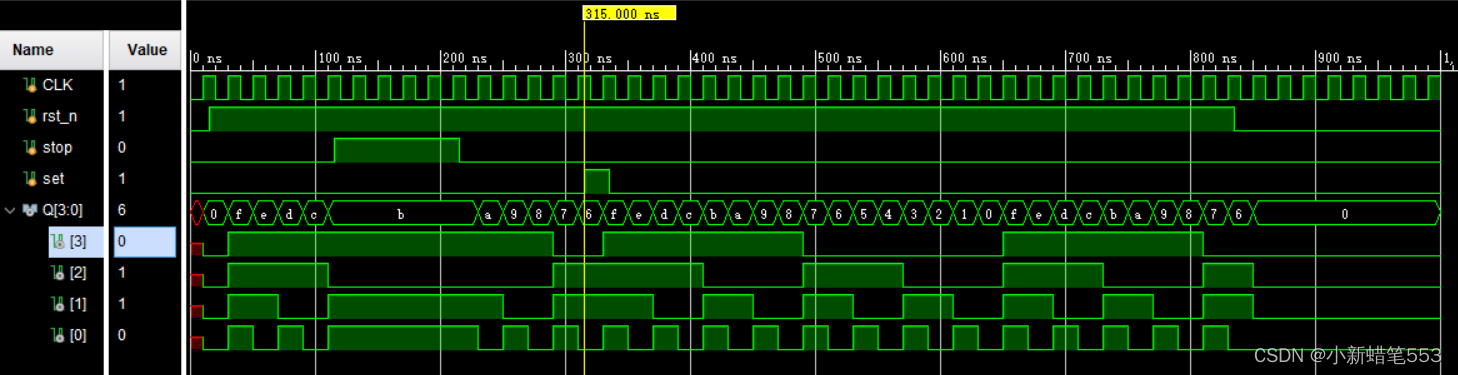
3.4 post-synthesis timing simulation
由图,延时为6.3ns
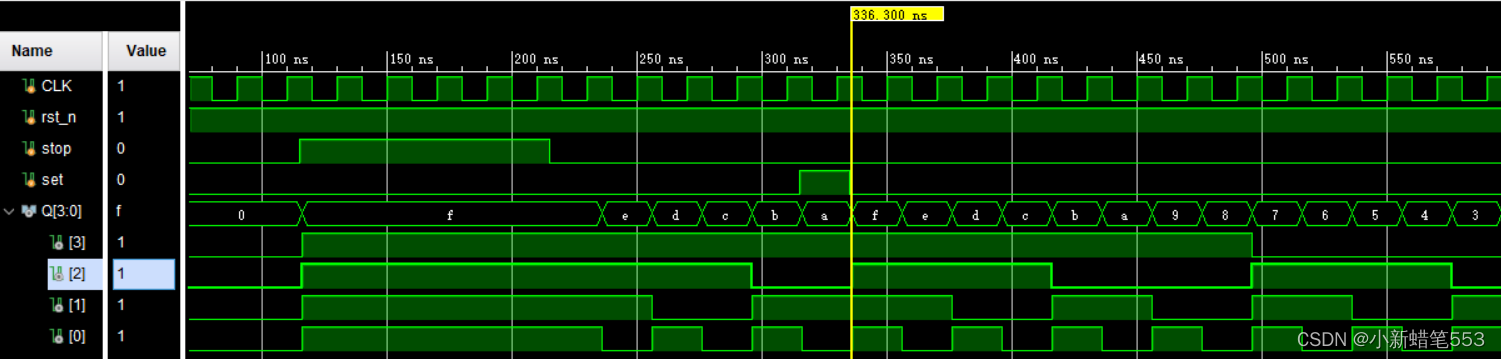
3.5 post-implementation-timing simulation
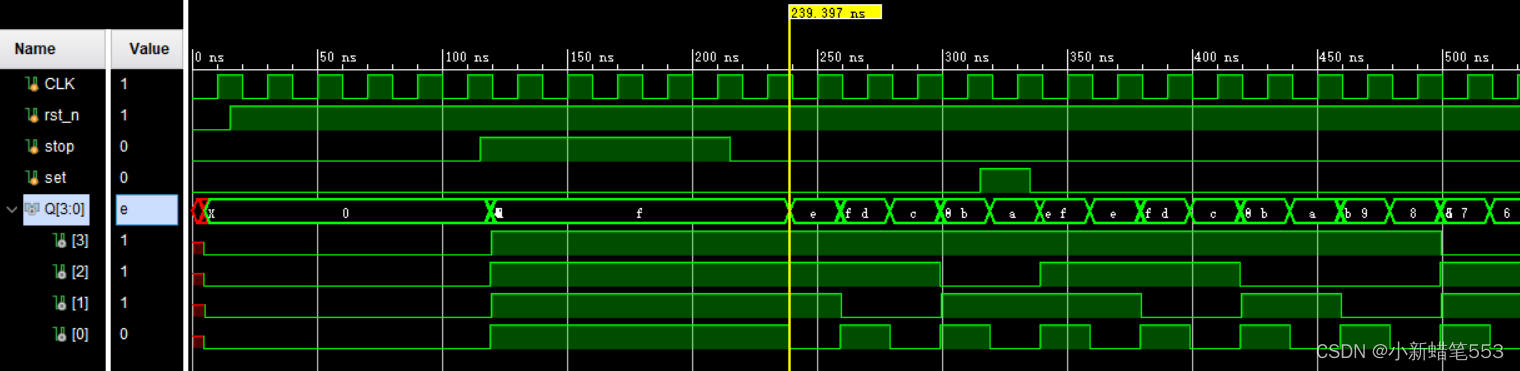
由图,延时约为9.397ns
当stop有效时计数器停止,当stop=0时计数器又重新开始计数,当set有效时,时钟信号上升沿来到时计数器被置为1111
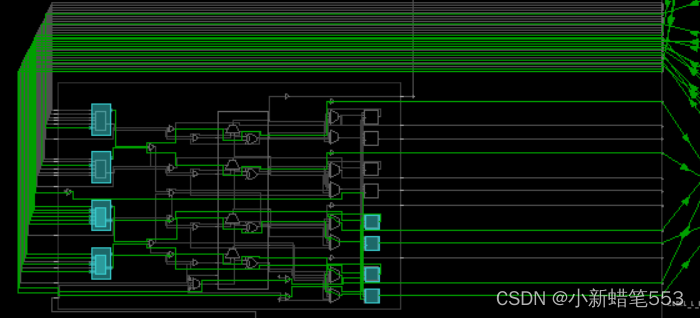
3.6 布局布线图
3.7资源利用率:



结论:
观察普通向上计数和多功能的向下计数器的波形图发现,两者的基本功能要求已经达到。对比延时发现第二个计数的延时略高于第一个,是由于第二个计数器增加了功能导致逻辑门电路的增多故传输延时增加。查看资源利用率报告看出两者使用的D触发器都是FDRE,即带使能功能的同步清除D触发器,相比与FDR多了一个使能接口,当同步复位接口为高电平时覆盖所有其他输出,时钟的上升沿触发寄存器复位(置0);当同步时钟接口为低电平且使能接口为高电平时,时钟的上升沿触发寄存器装载数据接口的数据。


















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









