







文章目录
深度学习模块汇总(一)
A2Atttention模块(2018)
论文
-
标题:《A2-Nets:Double Attention Networks》
-
地址:https://arxiv.org/pdf/1810.11579.pdf
-
解决的问题:
- CNN网络中的卷积块只能获取局部的特征关系,单个卷积块的感受野较小,虽然可以通过叠加卷积块来扩大感受野,但是这会使模型更深更庞大计算成本高,增加过拟合风险
- 前向和后向传播的远距离影响:位于远处的特征需要经过多层处理才能影响特定位置的输出,这在前向和后向传播中都增加了优化难度。
- 特征“延迟”:与某个远处位置相关的特征在模型中的体现可能是数层前的输出,这导致模型推理的时效性和准确性受限。
-
网络结构图:
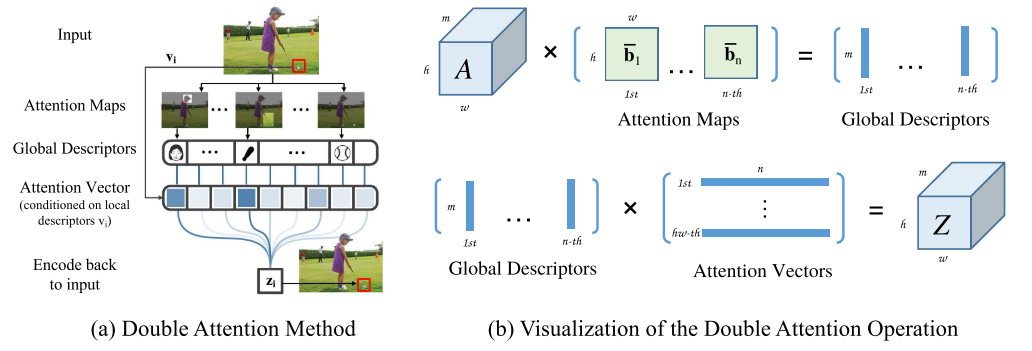
机制作用
-
机制:
- 注意力门控:用三个1*1的卷积分别生成三个特征图A,B,V.计算特征图B的softmax结果作为注意力图,然后将特征图A与这个注意力图进行矩阵乘法(batch-wise),得到全局描述符(global descriptors)
- 特征分配:计算特征图V的softmax结果作为第二个注意力向量,然后使用这个注意力向量与全局描述符进行矩阵乘法,得到最终的特征表示。
- 这种双重注意力机制先通过特征图B选择重要的特征,然后通过特征图V重新分配这些特征。
-
作用:A2-Nets通过引入双重注意力机制,有效地捕获长距离特征依赖,提高图像和视频识别任务的性能。它允许卷积层直接感知整个时空空间的特征,而==无需通过增加深度来扩大感受野,从而提高了模型的效率和性能==。
实验
-
因为该注意力模块改进对象是CNN,就以残差网络为实验对象,做了一个视频识别和一个图像识别
-
以ResNet进行消融实验,以ResNet-26,作为baseline。证明ResNet-26加入A2注意力之后效果比-29好,且计算量更低。评价指标选择FLOPs来衡量计算成本,用Params来衡量模型复杂度
-
在做对比实验上与ResNet、SENet在ImageNet-1k公开数据集上做对比实验,评价指标是top1、top5(还有当前的视频识别数据集和模型的对比实验)
-
最文章中提到将模块放置在顶层所获得的性能收益比将其放置在低层所获得的性能收益更为显著,故模块插入靠近输出层效果更好
代码
# A2-Nets: Double Attention Networks
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels, c_m, c_n, reconstruct=True):
super().__init__()
self.in_channels = in_channels# 输入通道数
self.reconstruct = reconstruct # 是否需要重构输出以匹配输入的维度
self.c_m = c_m # 第一个注意力机制的输出通道数
self.c_n = c_n # 第二个注意力机制的输出通道数
# 定义三个1x1卷积层,用于生成A、B和V特征
self.convA = nn.Conv2d(in_channels, c_m, 1)
self.convB = nn.Conv2d(in_channels, c_n, 1)
self.convV = nn.Conv2d(in_channels, c_n, 1)
# 如果需要重构,定义一个1x1卷积层用于输出重构
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)
self.init_weights()
def init_weights(self):
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
# 前向传播
b, c, h, w = x.shape
assert c == self.in_channels # 确保输入通道数与初始化时一致
A = self.convA(x) # b,c_m,h,w# 生成A特征图
B = self.convB(x) # b,c_n,h,w# 生成B特征图
V = self.convV(x) # b,c_n,h,w# 生成V特征图
# 将特征图维度调整为方便矩阵乘法的形状
tmpA = A.view(b, self.c_m, -1)
attention_maps = F.softmax(B.view(b, self.c_n, -1))
attention_vectors = F.softmax(V.view(b, self.c_n, -1))
# 步骤1: 特征门控
global_descriptors = torch.bmm(tmpA, attention_maps.permute(0, 2, 1)) # b.c_m,c_n
# 步骤2: 特征分配
tmpZ = global_descriptors.matmul(attention_vectors) # b,c_m,h*w
tmpZ = tmpZ.view(b, self.c_m, h, w) # b,c_m,h,w
if self.reconstruct:
tmpZ = self.conv_reconstruct(tmpZ)# 如果需要,通过重构层调整输出通道数
return tmpZ
# 输入 N C H W, 输出 N C H W
if __name__ == '__main__':
block = DoubleAttention(64, 128, 128)
input = torch.rand(1, 64, 64, 64)
output = block(input)
print(input.size(), output.size()) # 打印输出形状
SEAttention(2018)
论文
-
标题:《Squeeze-and-Excitation Networks》 挤压与激励网络
-
解决的问题:
- 希望寻找更强大的特征表示,这种特征表示只捕捉给定任务中最显著的图像属性,从而提高性能。
-
网络结构图:
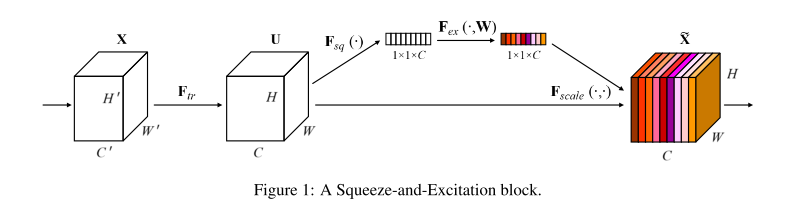
-
创新点:
- 研究了网络设计的一个不同方面——通道之间的关系。
- 设计一种新的架构单元——“Squeeze-and-Excitation” (SE)块,其目标是通过显式建模卷积特征通道之间的相互依赖来提高网络产生的表征的质量。(相当于特征做了提纯,使得特征表达能力更强)
- 本文提出了一种机制,允许网络进行特征重新校准,通过该机制网络可以学习使用全局信息,选择性地强调信息特征和抑制无用的特征
-
SE模块的特点:
(1)简单地堆叠一组SE块就可以构建一个SE网络(SENet)。
(2)SE块可用作网络架构中一定深度的原始块的替代品。
(3)SE模块的模板是通用的,但SE模块在整个网络的不同深度所扮演的角色不同。
(4)SE模块的结构很简单。
(5)SE块在计算上是轻量级的。
机制作用
- 压缩操作:
SE模块首先通过全局平均池化操作对输入特征图的空间维度(高度H和宽度W)进行聚合,为每个通道生成一个通道描述符。这一步有效地将全局空间信息压缩成一个通道向量,捕获了通道特征响应的全局分布。这一全局信息对于接下来的重新校准过程至关重要。
- 激励操作:
在压缩步骤之后,应用一个激励机制,该机制本质上是由两个全连接(FC)层和一个非线性激活函数(通常是sigmoid)组成的自门控机制。第一个FC层降低了通道描述符的维度,应用ReLU非线性激活,随后第二个FC层将其投影回原始通道维度。这个过程建模了通道间的非线性交互,并产生了一组通道权重。
- 特征重新校准:
激励操作的输出用于重新校准原始输入特征图。输入特征图的每个通道都由激励输出中对应的标量进行缩放。这一步骤有选择地强调信息丰富的特征,同时抑制不太有用的特征,使模型能够专注于任务中最相关的特征。
实验
- ImageNet分类:数据集使用的是ImageNet-2012公开数据集,比较了SE-ResNet和不同深度ResNet以及各种不同的分类模型做对比,评价指标按照ImageNet参考
- Places365-Challenge场景数据集分类:以ResNet-152作为基线,数据集评价指标超过当前最先进的型Places-365-CNN
- COCO上的目标检测:coco 40k数据集上的结果,但在coco数据集上依旧是与ResNet不同深度的模型做对比,评价指标是在AP@IoU与AP
- 最后实验中放了SE-ResNet-50不同模块激发引起的激活,这一块可以注意一下,比较新颖的实验方法,实验证明较低层级中特征与输入类别无关,随着层级加深特征变得与输入类别强相关,到追后两层时达到饱和,所以可以省略掉
代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
# 初始化SE模块,channel为通道数,reduction为降维比率
def __init__(self, channel=512, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化层,将特征图的空间维度压缩为1x1
self.fc = nn.Sequential( # 定义两个全连接层作为激励操作,通过降维和升维调整通道重要性
nn.Linear(channel, channel // reduction, bias=False), # 降维,减少参数数量和计算量
nn.ReLU(inplace=True), # ReLU激活函数,引入非线性
nn.Linear(channel // reduction, channel, bias=False), # 升维,恢复到原始通道数
nn.Sigmoid() # Sigmoid激活函数,输出每个通道的重要性系数
)
# 权重初始化方法
def init_weights(self):
for m in self.modules(): # 遍历模块中的所有子模块
if isinstance(m, nn.Conv2d): # 对于卷积层
init.kaiming_normal_(m.weight, mode='fan_out') # 使用Kaiming初始化方法初始化权重
if m.bias is not None:
init.constant_(m.bias, 0) # 如果有偏置项,则初始化为0
elif isinstance(m, nn.BatchNorm2d): # 对于批归一化层
init.constant_(m.weight, 1) # 权重初始化为1
init.constant_(m.bias, 0) # 偏置初始化为0
elif isinstance(m, nn.Linear): # 对于全连接层
init.normal_(m.weight, std=0.001) # 权重使用正态分布初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 偏置初始化为0
# 前向传播方法
def forward(self, x):
b, c, _, _ = x.size() # 获取输入x的批量大小b和通道数c
y = self.avg_pool(x).view(b, c) # 通过自适应平均池化层后,调整形状以匹配全连接层的输入
y = self.fc(y).view(b, c, 1, 1) # 通过全连接层计算通道重要性,调整形状以匹配原始特征图的形状
return x * y.expand_as(x) # 将通道重要性系数应用到原始特征图上,进行特征重新校准
# 示例使用
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7) # 随机生成一个输入特征图
se = SEAttention(channel=512, reduction=8) # 实例化SE模块,设置降维比率为8
output = se(input) # 将输入特征图通过SE模块进行处理
print(output.shape) # 打印处理后的特征图形状,验证SE模块的作用
CBAM模块(2018)
论文
-
标题:《CBAM: Convolutional Block Attention Module》
-
解决的问题:
- 关注重要的特征,压制不必要的特征,突出关注‘什么’和‘哪里’
-
网络结构图:
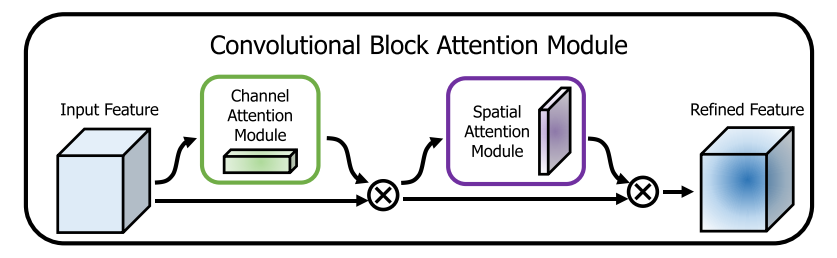
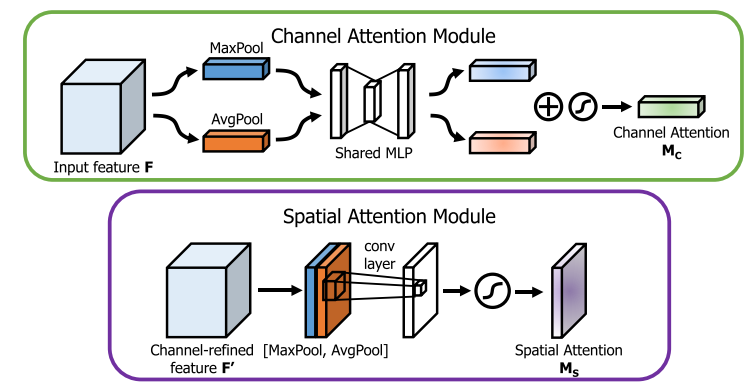
-
创新点:
- CBAM首次将通道注意力(Channel Attention)和空间注意力(Spatial Attention)顺序结合起来,对输入特征进行两阶段的精炼。这种设计让模型先关注于“哪些通道是重要的”,然后再关注于“空间上哪些位置是重要的”,从而更加全面地捕获特征中的关键信息。
机制作用
1、通道注意力模块(Channel Attention Module):
通过利用特征之间的通道关系来生成通道注意力图。每个通道的特征图被视为一个特征探测器,通道注意力关注于给定输入图像中“什么”是有意义的。为了有效地计算通道注意力,CBAM首先对输入特征图的空间维度进行压缩,同时使用平均池化和最大池化操作来捕获不同的空间上下文描述符,这些被送入共享的多层感知机(MLP)以产生通道注意力图。
2、空间注意力模块(Spatial Attention Module):
利用特征之间的空间关系来生成空间注意力图。与通道注意力不同,空间注意力关注于“在哪里”是一个有信息的部分,这与通道注意力是互补的。为了计算空间注意力,CBAM首先沿着通道轴应用平均池化和最大池化操作,然后将它们连接起来生成一个高效的特征描述符。在该描述符上应用一个卷积层来生成空间注意力图。
3、按先后顺序分别使用通道注意力和空间注意力加权输入的特征图
实验
- 做了多组消融实验,第一组以ResNet50为baseline加入平均池化和最大池化作比较,证明同时对通道注意力中使用平均池化与最大池化效果较好;调换两个注意力顺序做实验,证明还是先通道后空间效果好;
- ImageNet分类:数据集使用的是ImageNet 1k公开数据集,比较了多种不同的分类模型,评价指标按照ImageNet参考
- MS COCO ,VOC2017 公开数据集对目标检测的性能进行验证,评价指标map50,map50-95
- 另外这篇文章使用了Grad-CAM热力图进行证明该注意力模块能够更好的提取出目标区域特征
代码
import torch
from torch import nn
# 通道注意力模块
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.max_pool = nn.AdaptiveMaxPool2d(1) # 自适应最大池化
# 两个卷积层用于从池化后的特征中学习注意力权重
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) # 第一个卷积层,降维
self.relu1 = nn.ReLU() # ReLU激活函数
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) # 第二个卷积层,升维
self.sigmoid = nn.Sigmoid() # Sigmoid函数生成最终的注意力权重
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) # 对平均池化的特征进行处理
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) # 对最大池化的特征进行处理
out = avg_out + max_out # 将两种池化的特征加权和作为输出
return self.sigmoid(out) # 使用sigmoid激活函数计算注意力权重
# 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7' # 核心大小只能是3或7
padding = 3 if kernel_size == 7 else 1 # 根据核心大小设置填充
# 卷积层用于从连接的平均池化和最大池化特征图中学习空间注意力权重
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid() # Sigmoid函数生成最终的注意力权重
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True) # 对输入特征图执行平均池化
max_out, _ = torch.max(x, dim=1, keepdim=True) # 对输入特征图执行最大池化
x = torch.cat([avg_out, max_out], dim=1) # 将两种池化的特征图连接起来
x = self.conv1(x) # 通过卷积层处理连接后的特征图
return self.sigmoid(x) # 使用sigmoid激活函数计算注意力权重
# CBAM模块
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio) # 通道注意力实例
self.sa = SpatialAttention(kernel_size) # 空间注意力实例
def forward(self, x):
out = x * self.ca(x) # 使用通道注意力加权输入特征图
result = out * self.sa(out) # 使用空间注意力进一步加权特征图
return result # 返回最终的特征图
# 示例使用
if __name__ == '__main__':
block = CBAM(64) # 创建一个CBAM模块,输入通道为64
input = torch.rand(1, 64, 64, 64) # 随机生成一个输入特征图
output = block(input) # 通过CBAM模块处理输入特征图
print(input.size(), output.size()) # 打印输入和输出的
SKAttention模块(2019)
论文
-
标题:《Selective Kernel Networks》
-
解决的问题:
- 希望使神经元能够自适应地调整其感受野大小。
-
网络结构图:
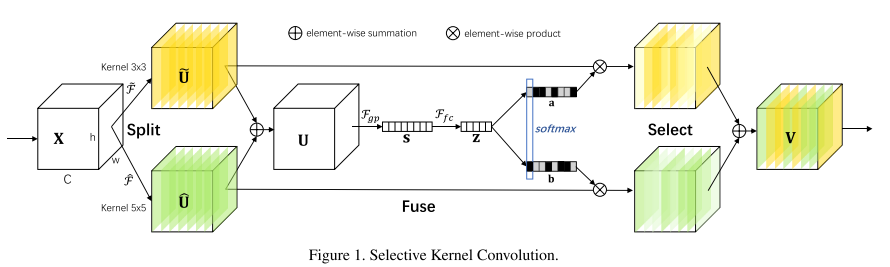
-
创新点:
1、自适应感受野:
SK卷积通过动态选择卷积核尺寸,使网络能够根据图像内容的不同自动调整其感受野大小,有效捕捉到多尺度信息。
2、注意力机制引导的选择:
通过注意力机制对不同尺寸卷积核的输出进行加权组合,能够使网络聚焦于更加重要的特征,提高了特征的表达效率。
3、增强模型泛化能力:
由于能够捕捉到更丰富的尺度信息,SKNets在多个视觉任务上展示了优于传统卷积网络的性能,增强了模型的泛化能力。
机制作用
SKNets引入了一种新颖的“选择性核”(SK)卷积技术,该技术通过动态调整卷积核的大小来适应不同的感受野需求。它通过混合不同尺寸的卷积核输出来实现,具体方法是先对输入特征图使用不同尺寸的卷积核进行处理,然后通过一个注意力机制动态地选择不同卷积核的输出组合。
实验
- ImageNet分类:数据集使用的是ImageNet 2012公开数据集,比较了多种不同的分类模型,评价指标按照ImageNet参考
- CIFAR分类: CIFAR公开数据集验证SK对小数据集效果,评价指标选择FLOPs来衡量计算成本,用Params来衡量模型复杂度
- 做了多消融实验,实验中证明模块的有效性,同时分组数M=2是首选;这里后面也是使用了通道序号与激活程度的相关图像说明
代码
import torch.nn as nn
import torch
class SKConv(nn.Module):
def __init__(self, in_ch, M=3, G=1, r=4, stride=1, L=32) -> None:
super().__init__()
# 初始化SKConv模块
# in_ch: 输入通道数
# M: 分支数量
# G: 卷积组数
# r: 用于计算d的比率,d用于确定Z向量的长度
# stride: 步长,默认为1
# L: 论文中向量Z的最小维度,默认为32
d = max(int(in_ch/r), L) # 计算d的值,确保d不小于L,以免信息损失
self.M = M # 分支数量
self.in_ch = in_ch # 输入通道数
self.convs = nn.ModuleList([]) # 存储不同分支的卷积操作
for i in range(M):
# 为每个分支添加卷积层,卷积核大小随i增加而增加
self.convs.append(
nn.Sequential(
nn.Conv2d(in_ch, in_ch, kernel_size=3+i*2, stride=stride, padding=1+i, groups=G),
nn.BatchNorm2d(in_ch),
nn.ReLU(inplace=True)
)
)
self.fc = nn.Linear(in_ch, d) # 一个全连接层,将特征图平均后的特征降维到d
self.fcs = nn.ModuleList([]) # 存储每个分支的全连接层,用于生成注意力向量
for i in range(M):
self.fcs.append(nn.Linear(d, in_ch))
self.softmax = nn.Softmax(dim=1) # Softmax激活,用于归一化注意力向量
def forward(self, x):
# 前向传播函数
feas = None
for i, conv in enumerate(self.convs):
# 对输入x应用每个分支的卷积操作
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
# 将不同分支的特征图拼接在一起
feas = torch.cat([feas, fea], dim=1)
# 将所有分支的特征图相加,得到一个统一的特征图fea_U
fea_U = torch.sum(feas, dim=1)
# 对fea_U进行全局平均池化,得到特征向量fea_s
fea_s = fea_U.mean(-1).mean(-1)
# 通过全连接层fc将fea_s映射到向量fea_z
fea_z = self.fc(fea_s)
attention_vectors = None
for i, fc in enumerate(self.fcs):
# 为每个分支生成注意力向量
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
# 将不同分支的注意力向量拼接在一起
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
# 对注意力向量应用Softmax激活,进行归一化处理
attention_vectors = self.softmax(attention_vectors).unsqueeze(-1).unsqueeze(-1)
# 将注意力向量应用于拼接后的特征图feas,通过加权求和得到最终的输出特征图fea_v
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
if __name__ == "__main__":
x = torch.randn(16, 64, 256, 256)
sk = SKConv(in_ch=64, M=3, G=1, r=2)
out = sk(x)
print(out.shape)
# in_ch 数据输入维度,M为分指数,G为Conv2d层的组数,基本设置为1,r用来进行求线性层输出通道的。
SGE模块(2019)
论文
-
标题:《Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks》
-
地址:https://arxiv.org/pdf/1905.09646.pdf
-
解决的问题:
- 一个完整的特征图是由许多子图组成的,并且这些子特征会以组的形式分布在每一层的特征图里,但是这些子特征会经由相同方式处理,且都会有背景噪声影响。这样会导致错误的识别和定位结果。
-
网络结构图:
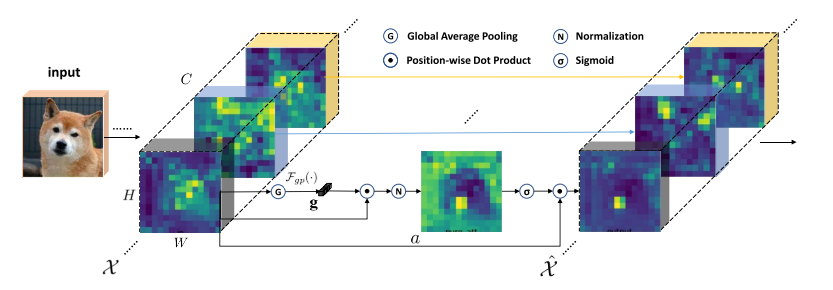
-
创新点:
提出了一个空间群智能增强(SGE)模块,该模块使其每个特征组能够自主增强其学习的语义表示并抑制可能的噪声,几乎不需要引入额外的参数和计算复杂性。
机制作用
将通道分为若干组,然后对每个组进行空间注意力。它通过在在每个组里生成注意力因子,这样就能得到每个子图的重要性,每个组也可以有针对性的学习和抑制噪声。这个注意力因子仅由各个组内全局和局部特征之间的相似性来决定,所以SGE非常轻量级。经由训练之后发现,SGE对于一些高阶语意非常有效。由作者实验发现,它可以显著提高图像识别任务性能。
实验
- 因为都是用于CNN网络的所以实验与前面模块相同,分别做分类和检测指标的对比
代码
import torch
import torch.nn as nn
class sSE(nn.Module): # 空间(Space)注意力
def __init__(self, in_ch) -> None:
super().__init__()
self.conv = nn.Conv2d(in_ch, 1, kernel_size=1, bias=False) # 定义一个卷积层,用于将输入通道转换为单通道
self.norm = nn.Sigmoid() # 应用Sigmoid激活函数进行归一化
def forward(self, x):
q = self.conv(x) # 使用卷积层减少通道数至1:b c h w -> b 1 h w
q = self.norm(q) # 对卷积后的结果应用Sigmoid激活函数:b 1 h w
return x * q # 通过广播机制将注意力权重应用到每个通道上
class cSE(nn.Module): # 通道(channel)注意力
def __init__(self, in_ch) -> None:
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1) # 使用自适应平均池化,输出大小为1x1
self.relu = nn.ReLU() # ReLU激活函数
self.Conv_Squeeze = nn.Conv2d(in_ch, in_ch // 2, kernel_size=1, bias=False) # 通道压缩卷积层
self.norm = nn.Sigmoid() # Sigmoid激活函数进行归一化
self.Conv_Excitation = nn.Conv2d(in_ch // 2, in_ch, kernel_size=1, bias=False) # 通道激励卷积层
def forward(self, x):
z = self.avgpool(x) # 对输入特征进行全局平均池化:b c 1 1
z = self.Conv_Squeeze(z) # 通过通道压缩卷积减少通道数:b c//2 1 1
z = self.relu(z) # 应用ReLU激活函数
z = self.Conv_Excitation(z) # 通过通道激励卷积恢复通道数:b c 1 1
z = self.norm(z) # 对激励结果应用Sigmoid激活函数进行归一化
return x * z.expand_as(x) # 将归一化权重乘以原始特征,使用expand_as扩展维度与原始特征相匹配
class scSE(nn.Module):
def __init__(self, in_ch) -> None:
super().__init__()
self.cSE = cSE(in_ch) # 通道注意力模块
self.sSE = sSE(in_ch) # 空间注意力模块
def forward(self, x):
c_out = self.cSE(x) # 应用通道注意力
s_out = self.sSE(x) # 应用空间注意力
return c_out + s_out # 合并通道和空间注意力的输出
x = torch.randn(4, 16, 4, 4) # 测试输入
net = scSE(16) # 实例化模型
print(net(x).shape) # 打印输出形状
SCConv自校正卷积(2019)
论文
-
标题:《Improving Convolutional Networks with Self-Calibrated Convolutions》
-
地址:http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
-
解决的问题:
传统的卷积核存在以下问题:
- 每个输出的特征图都是通过所有通道求和来计算的,所有的特征图都是通过重复同一公式得到。
- 每个空间位置的感受野主要由预定义的卷积核大小控制。
-
网络结构图:
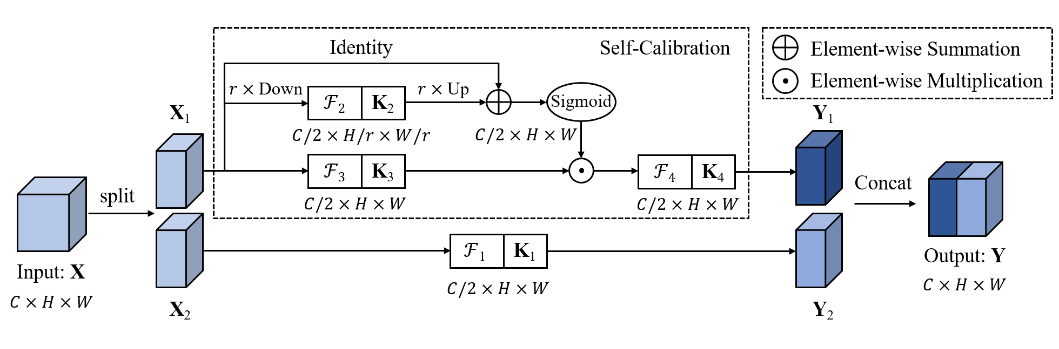
-
创新点:
该论文提出了一种自校准的模块(多个卷积注意力组合的模块),替换基本的卷积结构,在不增加额外参数和计算量的情况下,该模块能够产生全局的感受野。相比于标准卷积,该模块产生的特征图更具有区分度。
机制作用
第一步,输入特征图X为C* H* W大小,拆分为两个C/2 * H *W大小的X1,X2;
第二步,卷积核K的维度为C *C *H * W,将K分为4个部分,每份的作用各不相同,分别记为K1,K2,K3,K4,其维度均为C/2 * C/2 * H * W;
为了有效地收集每个空间位置的丰富的上下文信息,作者提出在两个不同的尺度空间中进行卷积特征转换:原始尺度空间中的特征图(输入共享相同的分辨率)和下采样后的具有较小分辨率的潜在空间(用于自校正) 。利用下采样后特征具有较大的感受野,因此在较小的潜在空间中进行变换后的嵌入将用作参考,以指导原始特征空间中的特征变换过程。
原文链接:https://blog.csdn.net/PLANTTHESON/article/details/134112887
实验
- 在ImageNet-1k数据集上对比不同分类框架的结果
- 在ImageNet-1k数据集上以ReNet50为基线加入各种其他注意力模块,对比准确率
- 后面在coco数据集上验证了其模型在目标检测、分割、关键点检测方法的优越性
代码
import torch
from torch import nn
import torch.nn.functional as F
class SCConv(nn.Module):
def __init__(self, inplanes, planes, stride, padding, dilation, groups, pooling_r, norm_layer):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k3 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k4 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
def forward(self, x):
identity = x
out = torch.sigmoid(
torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:]))) # sigmoid(identity + k2)
out = torch.mul(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out
# 输入 N C H W, 输出 N C H W
if __name__ == '__main__':
scconv = SCConv(64, 64, stride=1, padding=2, dilation=2, groups=1, pooling_r=4, norm_layer=nn.BatchNorm2d)
input = torch.rand(3, 64, 32, 32)
output = scconv(input)
print(input.size(), output.size())
ResNeSt 分散注意力(2020)
论文
-
标题:《ResNeSt: Split-Attention Networks》
-
地址:https://arxiv.org/abs/2004.08955
-
解决的问题:
传统的卷积核存在以下问题:
- 缺乏跨通道特征表示:传统的CNN主要依赖于局部卷积操作,这限制了它们在捕捉跨通道特征表示(cross-channel feature-map representations)方面的能力。这意味着CNN在处理需要跨通道信息的任务时表现不佳。
- 缺乏长距离连接:传统的CNN缺乏长距离连接(long-range connections),这限制了它们在捕捉全局信息和复杂特征关系方面的能力。
- 网络外推能力不足:传统的CNN在处理与训练任务不同的下游任务时,网络的外推能力(network surrogacy)不足。这意味着CNN在迁移学习和多任务学习中的表现可能不理想。
- 多任务的适应性差:传统的CNN在特定任务上的表现可能很好,但在多个任务上同时表现出色的能力有限。这限制了它们在多任务学习中的应用。
- 信息传递的局限性:传统的CNN在信息传递上存在局限性,特别是在需要跨通道信息传递的任务中表现不佳。
-
网络结构图:
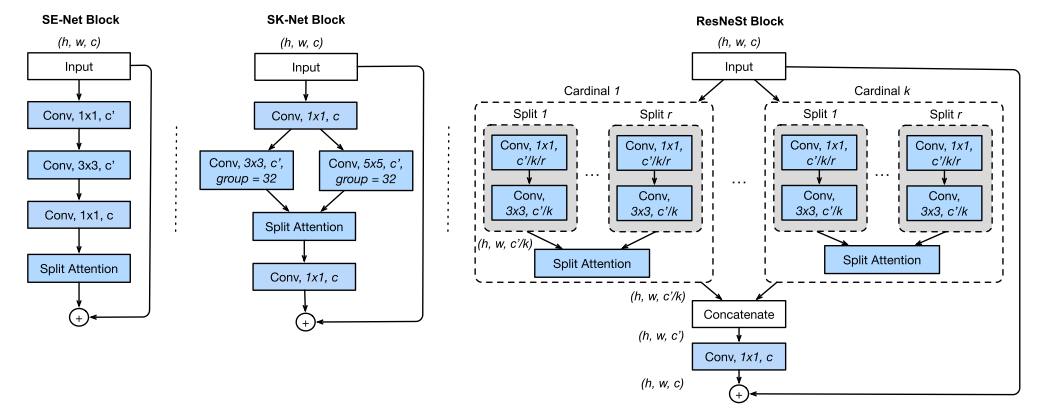
-
创新点:
ResNest主要贡献是设计了一个Split-Attention模块,可以实现跨通道注意力。通过以ResNet样式堆叠Split-Attention块,获得了一个ResNet的变体。ResNest网络保留了完整的ResNet结构,可以直接用下游任务,而不会引起额外的计算成本。ResNest在分类、FasterRCNN、DeeplabV3上都有提升。
机制作用
Resnest将输入先分成K个组,每个组我们称为Cardinal, 每个Cardinal内的block又被划分成R个组,我们称被划分的组为Radix,所以可以看到最后Radix中的输入通道数为C/K/R。而上面的两次划分,实质上可以由一次1X1的卷积进行划分,所以第一步split即是一个1X1的卷积可以完成。而在每个Cardinal里的注意力操作其实就是SKNet的扩展,可以看前面讲的Split Attention的操作,就是先对划分出的R个组进行相加得到U,然后接上两个全连接层得到注意力权重。对注意力权重经过softmax后Split成R个组和原始的分支进行相乘后再相加就完成了split attention的操作。
实验
- 在ImageNet-2012数据集上对比不同分类框架的结果,并且后面做消融实验
- 与其他先进的ResNet变体模型做对比实验
- 使用迁移学习(载入与训练模型)对模型进行目标检测、分割等任务的实验
代码
import torch
from torch import nn
import torch.nn.functional as F
def make_divisible(v, divisor=8, min_value=None, round_limit=.9):
min_value = min_value or divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < round_limit * v:
new_v += divisor
return new_v
class RadixSoftmax(nn.Module):
def __init__(self, radix, cardinality):
super(RadixSoftmax, self).__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
x = F.softmax(x, dim=1)
x = x.reshape(batch, -1)
else:
x = x.sigmoid()
return x
class SplitAttn(nn.Module):
"""Split-Attention (aka Splat)
"""
def __init__(self, in_channels, out_channels=None, kernel_size=3, stride=1, padding=None,
dilation=1, groups=1, bias=False, radix=2, rd_ratio=0.25, rd_channels=None, rd_divisor=8,
act_layer=nn.ReLU, norm_layer=None, drop_block=None, **kwargs):
super(SplitAttn, self).__init__()
out_channels = out_channels or in_channels
self.radix = radix
self.drop_block = drop_block
mid_chs = out_channels * radix
if rd_channels is None:
attn_chs = make_divisible(
in_channels * radix * rd_ratio, min_value=32, divisor=rd_divisor)
else:
attn_chs = rd_channels * radix
padding = kernel_size // 2 if padding is None else padding
self.conv = nn.Conv2d(
in_channels, mid_chs, kernel_size, stride, padding, dilation,
groups=groups * radix, bias=bias, **kwargs)
self.bn0 = norm_layer(mid_chs) if norm_layer else nn.Identity()
self.act0 = act_layer()
self.fc1 = nn.Conv2d(out_channels, attn_chs, 1, groups=groups)
self.bn1 = norm_layer(attn_chs) if norm_layer else nn.Identity()
self.act1 = act_layer()
self.fc2 = nn.Conv2d(attn_chs, mid_chs, 1, groups=groups)
self.rsoftmax = RadixSoftmax(radix, groups)
def forward(self, x):
x = self.conv(x)
x = self.bn0(x)
if self.drop_block is not None:
x = self.drop_block(x)
x = self.act0(x)
B, RC, H, W = x.shape
if self.radix > 1:
x = x.reshape((B, self.radix, RC // self.radix, H, W))
x_gap = x.sum(dim=1)
else:
x_gap = x
x_gap = x_gap.mean(2, keepdims=True).mean(3, keepdims=True)
x_gap = self.fc1(x_gap)
x_gap = self.bn1(x_gap)
x_gap = self.act1(x_gap)
x_attn = self.fc2(x_gap)
x_attn = self.rsoftmax(x_attn).view(B, -1, 1, 1)
if self.radix > 1:
out = (x * x_attn.reshape((B, self.radix,
RC // self.radix, 1, 1))).sum(dim=1)
else:
out = x * x_attn
return out
# 输入 N C H W, 输出 N C H W
if __name__ == '__main__':
block = SplitAttn(64)
input = torch.rand(3, 64, 32, 32)
output = block(input)
print(input.size(), output.size())


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









