








文章目录
- 前言
- 1、为什么要用cache?
- 2、背景:架构的变化?
- 2、cache的层级关系 ––big.LITTLE架构(A53为例)
- 3、cache的层级关系 –-- DynamIQ架构(A76为例)
- 4、DSU / L3 cache
- 5、L1/L2/L3 cache都是多大呢
- 6、cache相关的术语介绍
- 7、cache的分配策略(alocation,write-through, write-back)
- 8、架构中内存的类型
- 9、架构中定义的cache的范围(inner, outer)
- 10、架构中内存的类型 (mair_elx寄存器)
- 11、cache的种类(VIVT,PIPT,VIPT)
- 12、Inclusive and exclusive caches
- 13、cache的查询过程(非官方,白话)
- 14、cache的组织形式(index, way, set)
- 15、cache line里都有什么
- 16、cache查询示例
- 17、cache查询原理
- 18、cache maintenance
- 19、软件中维护内存一致性 – invalid cache
- 20、软件中维护内存一致性 – flush cache
- 21、cache一致性指令介绍
- 22、PoC/PoU point介绍
- 23、cache一致性指令的总结
- 24、Kernel中使用cache一致性指令的示例
- 25、Linux Kernel Cache API
- 26、A76的cache介绍
- 27、A78的cache介绍
- 28、armv8/armv9中的cache相关的系统寄存器
- 29、多核之间的cache一致性
- 30、MESI/MOESI的介绍
前言
本文转自 周贺贺,baron,代码改变世界ctw,Arm精选, armv8/armv9,trustzone/tee,secureboot,资深安全架构专家,11年手机安全/SOC底层安全开发经验。擅长trustzone/tee安全产品的设计和开发。文章有感而发。
1、为什么要用cache?
ARM 架构刚开始开发时,处理器的时钟速度和内存的访问速度大致相似。今天的处理器内核要复杂得多,并且时钟频率可以快几个数量级。然而,外部总线和存储设备的频率并没有达到同样的程度。可以实现可以与内核以相同速度运行的小片上 SRAM块,但与标准 DRAM 块相比,这种 RAM 非常昂贵,标准 DRAM 块的容量可能高出数千倍。在许多基于 ARM 处理器的系统中,访问外部存储器需要数十甚至数百个内核周期。
缓存是位于核心和主内存之间的小而快速的内存块。它在主内存中保存项目的副本。对高速缓冲存储器的访问比对主存储器的访问快得多。每当内核读取或写入特定地址时,它首先会在缓存中查找。如果它在高速缓存中找到地址,它就使用高速缓存中的数据,而不是执行对主存储器的访问。通过减少缓慢的外部存储器访问时间的影响,这显着提高了系统的潜在性能。通过避免驱动外部信号的需要,它还降低了系统的功耗
2、背景:架构的变化?
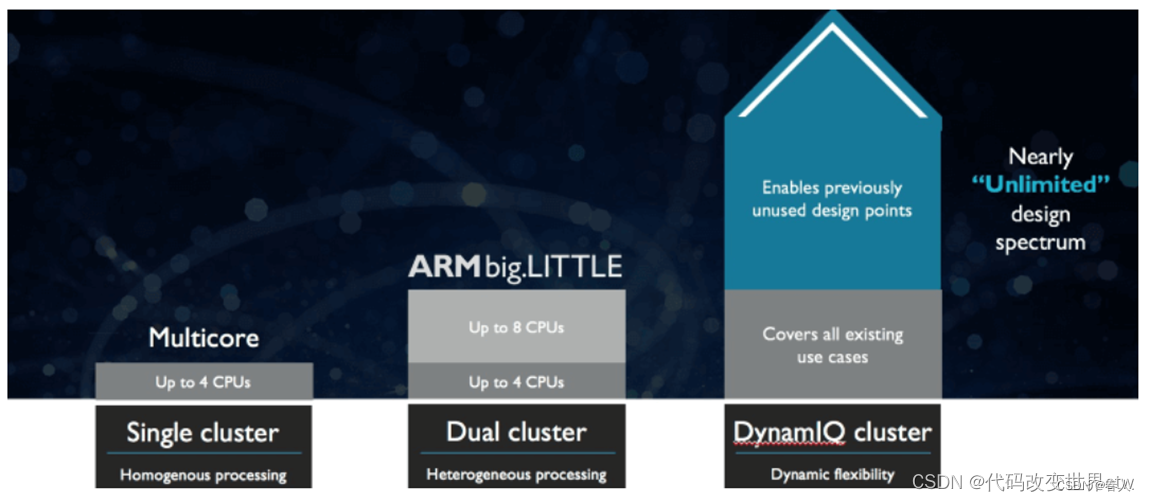
-
DynamIQ是Arm公司2017年发表的新一代多核心微架构(microarchitecture)技术,正式名称为DynamIQ big.LITTLE(以下简称为DynamIQ),取代使用多年的big.LITTLE技术
-
big.LITTLE技术将多核心处理器IP分为两个clusters,每个cluster最多4个核,两个cluster最多4+4=8核,而DynamIQ的一个cluster,最多支持8个核
-
big.LITTLE大核和小核必须放在不同的cluster,例如4+4(4大核+4小核),DynamIQ的一个cluster中,可同时包含大核和小核,达到cluster内的异构(heterogeneous cluster),而且大核和小核可以随意排列组合,例如1+3、1+7等以前无法做到的弹性配置。
-
big.LITTLE每个cluster只能用一种电压,也因此同一个cluster内的各核心CPU只有一种频率,DynamIQ内的每个CPU核心都可以有不同的电压和不同的频率
-
big.LITTLE每个cluster内的CPU核,共享同一块L2 Cache,DynamIQ内的每个CPU核心,都有专属的L2 Cache,再共享同一块L3 Cache,L2 Cache和L3 Cache的容量大小都是可以选择的,各核专属L2 Cache可以从256KB~512KB,各核共享L3 Cahce可以从1MB~4MB。这样的设计大幅提升了跨核数据交换的速度。 L3 Cache是DynamIQ Shared Unit(DSU)的一部分
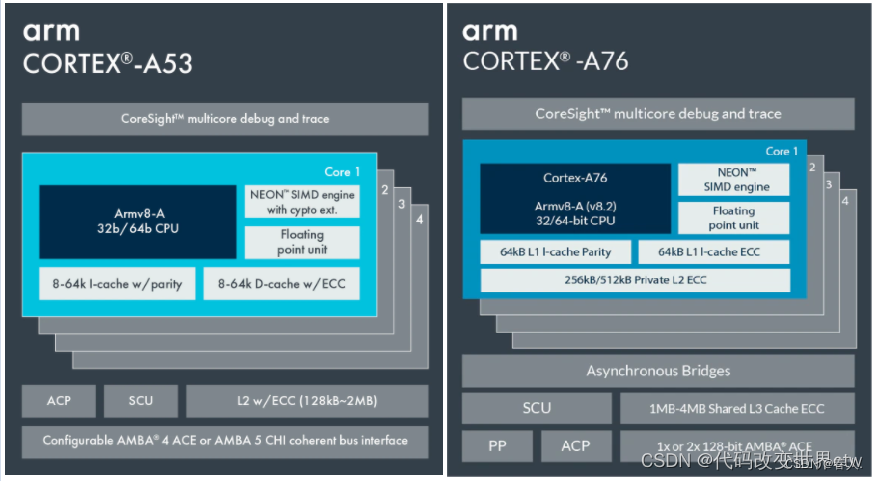
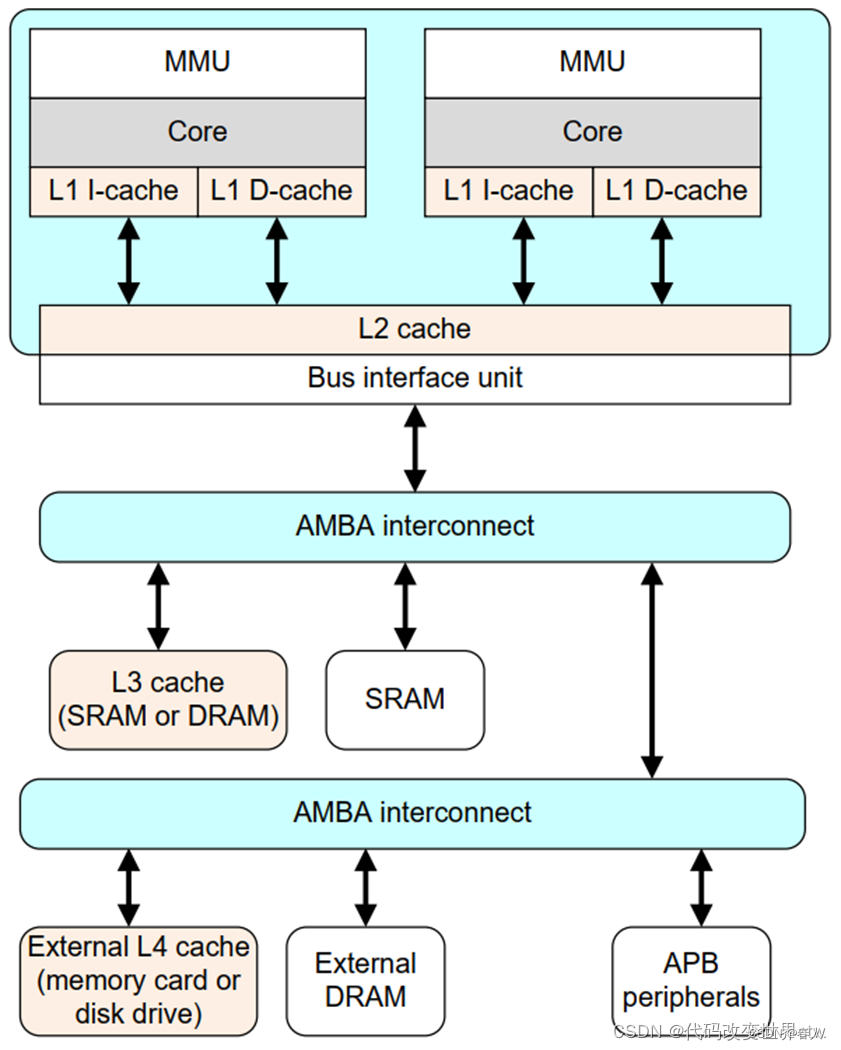
2、cache的层级关系 ––big.LITTLE架构(A53为例)
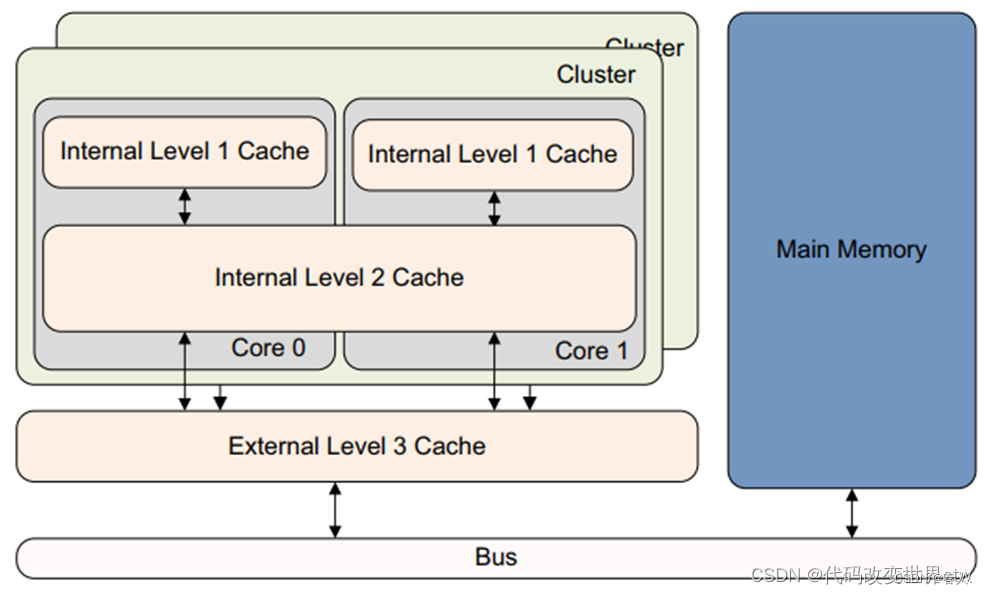
3、cache的层级关系 –-- DynamIQ架构(A76为例)
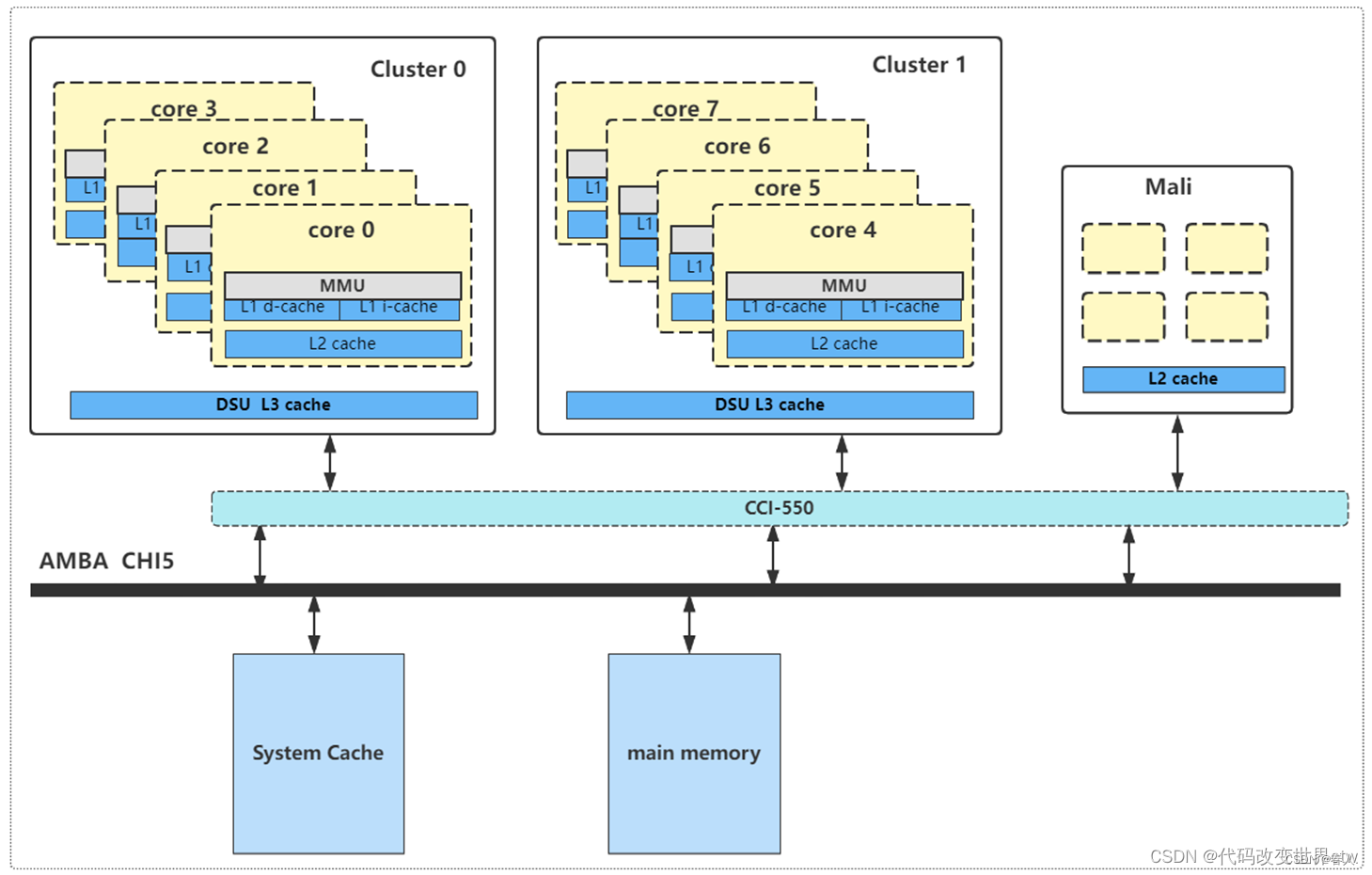
4、DSU / L3 cache
DSU-AE 实现了系统控制寄存器,这些寄存器对cluster中的所有core都是通用的。 可以从cluster中的任何core访问这些寄存器。 这些寄存器提供:
-
控制cluster的电源管理。
-
L3 cache控制。
-
CHI QoS 总线控制和scheme ID分配。
-
有关DSU‑AE 硬件配置的信息,包括指定的Split‑Lock 集群执行模式。
-
L3 缓存命中和未命中计数信息
L3 cache
-
cache size可选 : 512KB, 1MB, 1.5MB, 2MB, or 4MB. cache line = 64bytes
-
1.5MB的cache 12路组相连
-
512KB, 1MB, 2MB, and 4MB的caches 16路组相连
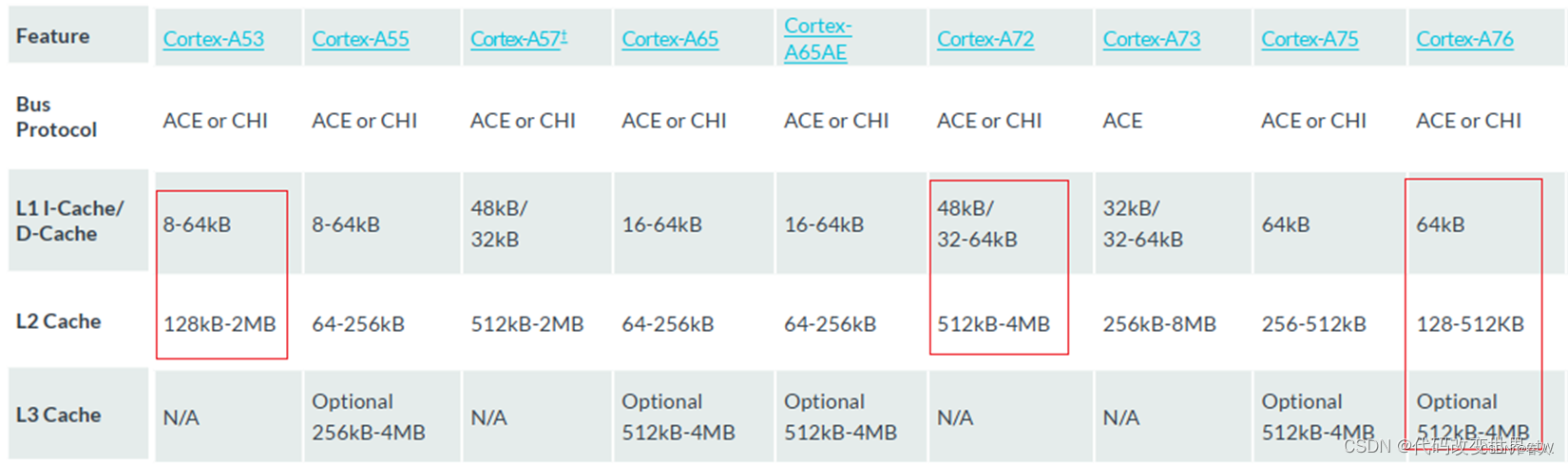
5、L1/L2/L3 cache都是多大呢
需要参考ARM文档,其实每一个core的cache大小都是固定的或可配置的。
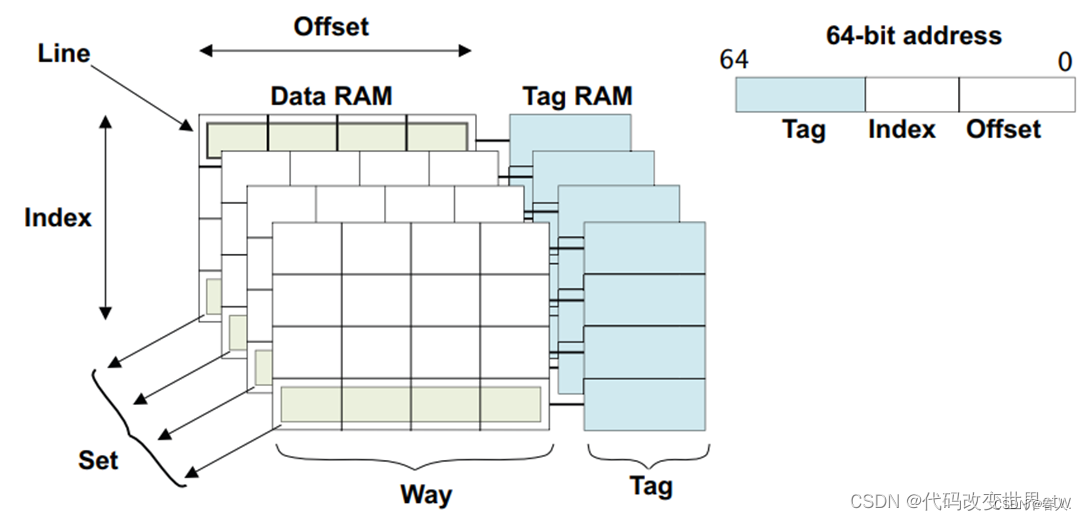
6、cache相关的术语介绍
思考 :什么是Set、way、TAG 、index、cache line、entry?
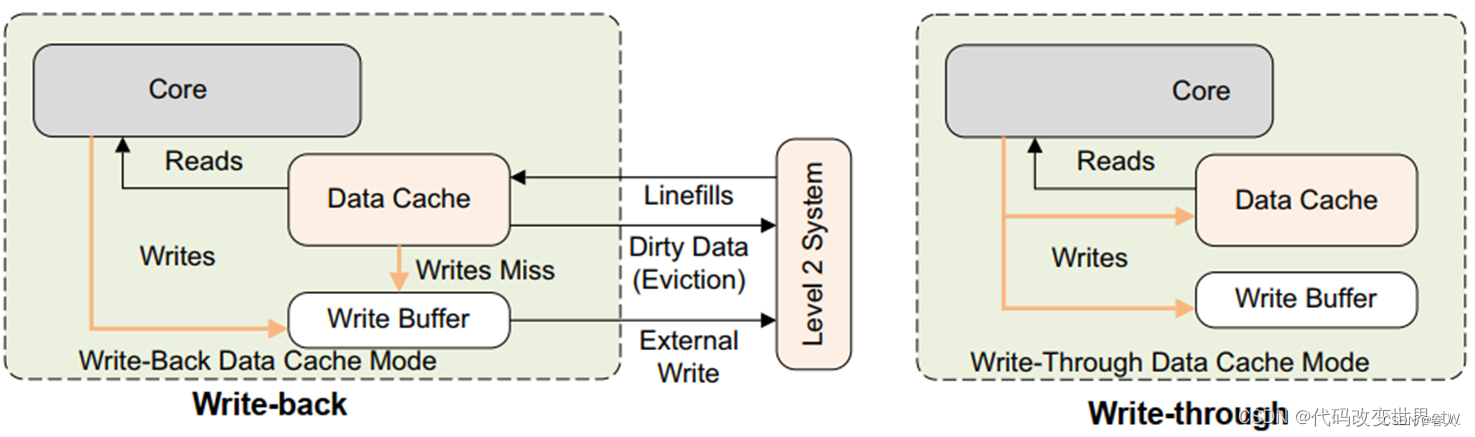
7、cache的分配策略(alocation,write-through, write-back)
-
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。 -
读分配(read allocation)写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。 -
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。 -
读分配(read allocation)写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit(翻翻前面的图片,cache line旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致
8、架构中内存的类型
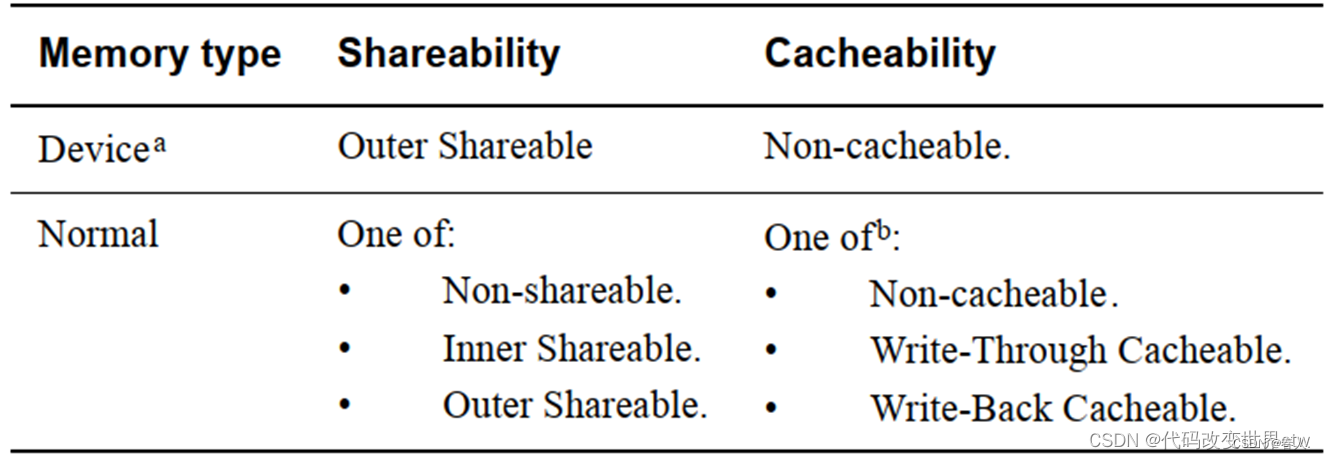
9、架构中定义的cache的范围(inner, outer)
对于cacheable属性,inner和outer描述的是cache的定义或分类。比如把L1/L1看做是inner,把L3看做是outer
通常,内部集成的cache属于i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3412
3412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











