







简单循环网络(Simple Recurrent Network,SRN)只有一个隐藏层的神经网络.
1.实现SRN
(1)使用Numpy
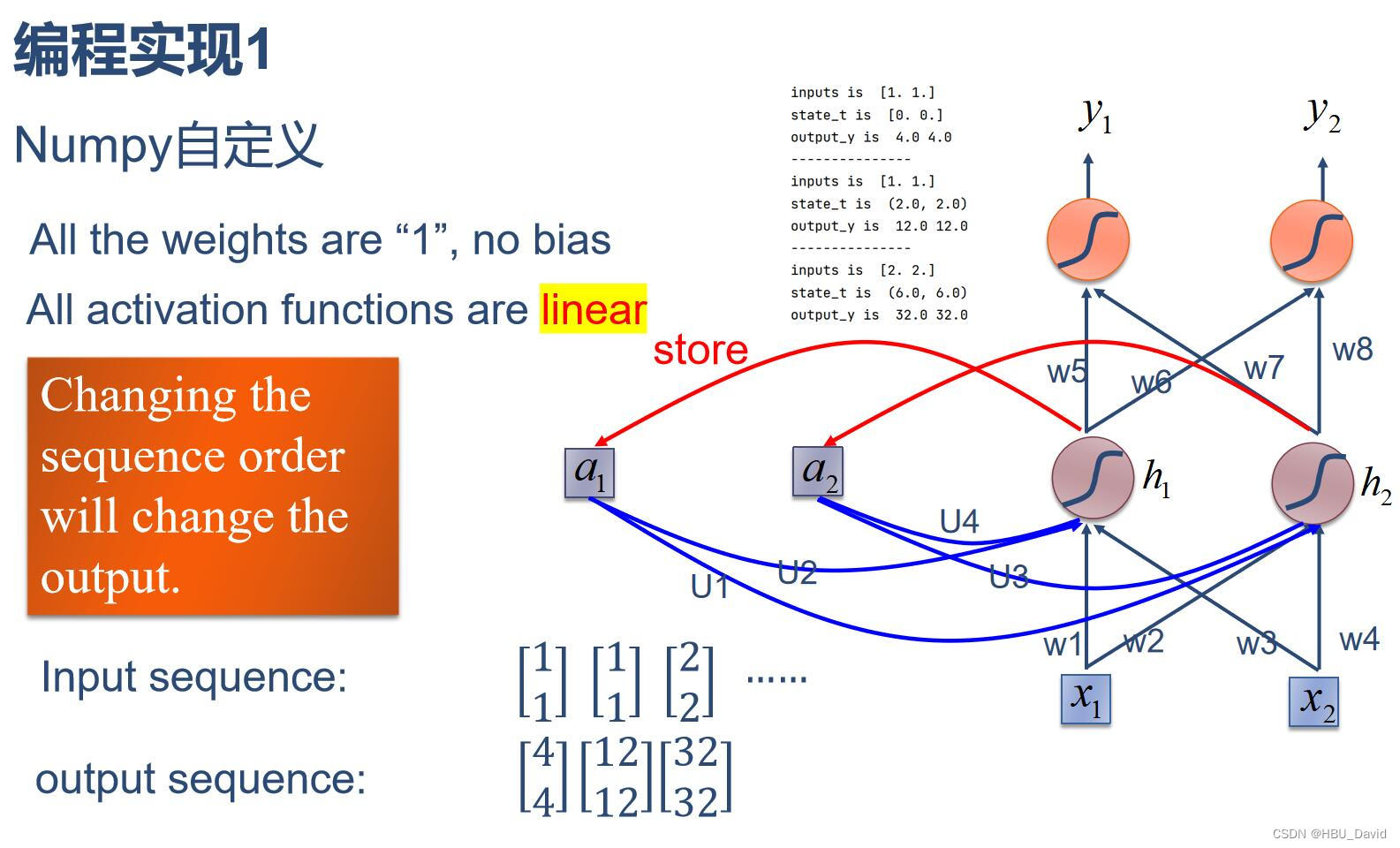
程序展示 :
import numpy as np
inputs=np.array([[1.,1.],[1.,1.],[2.,2.]])
print("inputs is :",inputs)
state_t=np.zeros(2,)
print("state_t is ",state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('-------------------------')
for input_t in inputs:
print('input is ',input_t)
print('state_t is ',state_t)
in_h1=np.dot([w1,w3],input_t)+np.dot([U2,U4],state_t)
in_h2=np.dot([w2,w4],input_t)+np.dot([U1,U3],state_t)
state_t=in_h1,in_h2 #更新存储器
output_y1=np.dot([w5,w7],[in_h1,in_h2])
output_y2=np.dot([w6,w8],[in_h1,in_h2])
print('output_y is ',output_y1,output_y2)
print('---------------------------')运行结果:
inputs is : [[1. 1.]
[1. 1.]
[2. 2.]]
state_t is [0. 0.]
-------------------------
input is [1. 1.]
state_t is [0. 0.]
output_y is 4.0 4.0
---------------------------
input is [1. 1.]
state_t is (2.0, 2.0)
output_y is 12.0 12.0
---------------------------
input is [2. 2.]
state_t is (6.0, 6.0)
output_y is 32.0 32.0
---------------------------
(2) 在1的基础上,增加激活函数tanh.
程序展示:
import numpy as np
inputs=np.array([[1.,1.],[1.,1.],[2.,2.]])
print("inputs is :",inputs)
state_t=np.zeros(2,)
print("state_t is ",state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('-------------------------')
for input_t in inputs:
print('input is ',input_t)
print('state_t is ',state_t)
in_h1=np.dot([w1,w3],input_t)+np.dot([U2,U4],state_t)
in_h1=np.tanh(in_h1)#增加激活函数
in_h2=np.dot([w2,w4],input_t)+np.dot([U1,U3],state_t)
in_h2=np.tanh(in_h2)#增加激活函数
state_t=in_h1,in_h2 #更新存储器
output_y1=np.dot([w5,w7],[in_h1,in_h2])
output_y2=np.dot([w6,w8],[in_h1,in_h2])
print('output_y is ',output_y1,output_y2)
print('---------------------------')运行结果:
inputs is : [[1. 1.]
[1. 1.]
[2. 2.]]
state_t is [0. 0.]
-------------------------
input is [1. 1.]
state_t is [0. 0.]
output_y is 1.9280551601516338 1.9280551601516338
---------------------------
input is [1. 1.]
state_t is (0.9640275800758169, 0.9640275800758169)
output_y is 1.9984510891336251 1.9984510891336251
---------------------------
input is [2. 2.]
state_t is (0.9992255445668126, 0.9992255445668126)
output_y is 1.9999753470497836 1.9999753470497836
---------------------------(3)使用nn.RNNCell实现。
torch.nn.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh', device=None, dtype=None)
使用方法:

import torch
batch_size=1
seq_len=3
input_size=2
hidden_size=2
output_size=2
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
for name,param in cell.named_parameters():
if name.startswith('weight'):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
liner=torch.nn.Linear(hidden_size,output_size)
liner.weight.data=torch.Tensor([[1,1],[1,1]])
liner.bias.data=torch.Tensor([0.0])
seq=torch.Tensor([[[1,1]],[[1,1]],[[2,2]]])
hidden=torch.zeros(batch_size,hidden_size)
output=torch.zeros(batch_size,output_size)
for idx,input in enumerate(seq):
print('='*20,idx,'='*20)
print('Input :',input)
print('hidden :',hidden)
hidden=cell(input,hidden)
output=liner(hidden)
print('output :',output)运行结果:
==================== 0 ====================
Input : tensor([[1., 1.]])
hidden : tensor([[0., 0.]])
output : tensor([[1.9281, 1.9281]], grad_fn=<AddmmBackward0>)
==================== 1 ====================
Input : tensor([[1., 1.]])
hidden : tensor([[0.9640, 0.9640]], grad_fn=<TanhBackward0>)
output : tensor([[1.9985, 1.9985]], grad_fn=<AddmmBackward0>)
==================== 2 ====================
Input : tensor([[2., 2.]])
hidden : tensor([[0.9992, 0.9992]], grad_fn=<TanhBackward0>)
output : tensor([[2.0000, 2.0000]], grad_fn=<AddmmBackward0>)(4)使用nn.RNN实现
nn.RNN使用方法:

import torch
batch_size=1
seq_len=3
input_size=2
hidden_size=2
num_layer=1
output_size=2
cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layer)
for name,param in cell.named_parameters():
if name.startswith('weight'):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
liner=torch.nn.Linear(hidden_size,output_size)
liner.weight.data=torch.Tensor([[1,1],[1,1]])
liner.bias.data=torch.Tensor([0.0])
seq=torch.Tensor([[[1,1]],[[1,1]],[[2,2]]])
hidden=torch.zeros(num_layer,batch_size,hidden_size)
out,hidden=cell(seq,hidden)
print('Input ',seq[0])
print('hidden ',0,0)
print('Output ',liner(out[0]))
print('-'*10)
print('Input ',seq[1])
print('hidden ',out[0])
print('Output ',liner(out[1]))
print('-'*10)
print('Input ',seq[2])
print('hidden ',out[1])
print('Output ',liner(out[2]))
print('-'*10)运行结果:
Input tensor([[1., 1.]])
hidden 0 0
Output tensor([[1.9281, 1.9281]], grad_fn=<AddmmBackward0>)
----------
Input tensor([[1., 1.]])
hidden tensor([[0.9640, 0.9640]], grad_fn=<SelectBackward0>)
Output tensor([[1.9985, 1.9985]], grad_fn=<AddmmBackward0>)
----------
Input tensor([[2., 2.]])
hidden tensor([[0.9992, 0.9992]], grad_fn=<SelectBackward0>)
Output tensor([[2.0000, 2.0000]], grad_fn=<AddmmBackward0>)
----------2. 实现“序列到序列”
实现视频P12中的教学案例
实例实现:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(batch_size, seq_len, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('Output size:', out.shape)
print('Output:', out)
print('Hidden size: ', hidden.shape)
print('Hidden: ', hidden)运行结果:
Output size: torch.Size([1, 3, 2])
Output: tensor([[[ 0.3788, -0.9660],
[-0.9741, -0.8697],
[-0.3348, -0.2719]]], grad_fn=<TransposeBackward1>)
Hidden size: torch.Size([1, 1, 2])
Hidden: tensor([[[-0.3348, -0.2719]]], grad_fn=<StackBackward0>)序列到序列程序:
import torch
input_size=4
hidden_size=4
batch_size=1
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]
x_one_hot=[one_hot_lookup[x] for x in x_data]
inputs=torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels=torch.LongTensor(y_data).view(-1,1)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(Model,self).__init__()
self.batch_size=batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnncell=torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)
def forward(self,input,hidden):
hidden=self.rnncell(input,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net=Model(input_size,hidden_size,batch_size)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(15):
loss=0
optimizer.zero_grad()
hidden=net.init_hidden()
print('Predicted string:',end='')
for input,label in zip(inputs,labels):
hidden=net(input,hidden)
loss+=criterion(hidden,label)
_,idx=hidden.max(dim=1)
print(idx2char[idx.item()],end='')
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss=%.4f'%(epoch+1,loss.item()))程序结果:
Predicted string:oohho,Epoch [1/15] loss=6.7046
Predicted string:oollo,Epoch [2/15] loss=5.4569
Predicted string:oolll,Epoch [3/15] loss=4.7231
Predicted string:ohlll,Epoch [4/15] loss=4.3367
Predicted string:ohlll,Epoch [5/15] loss=4.0202
Predicted string:ohlll,Epoch [6/15] loss=3.7117
Predicted string:ohlll,Epoch [7/15] loss=3.4333
Predicted string:ohlll,Epoch [8/15] loss=3.2008
Predicted string:ohlll,Epoch [9/15] loss=3.0112
Predicted string:ohlll,Epoch [10/15] loss=2.8448
Predicted string:ohlll,Epoch [11/15] loss=2.6876
Predicted string:ohlol,Epoch [12/15] loss=2.5409
Predicted string:ohlol,Epoch [13/15] loss=2.4235
Predicted string:ohlol,Epoch [14/15] loss=2.3449
Predicted string:ohlol,Epoch [15/15] loss=2.29323. “编码器-解码器”的简单实现

程序:
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
letter=[c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx={n: i for i ,n in enumerate(letter)}
seq_data=[['man','women'],['black','white'],['king','queen'],['girl','boy'],['up','down'],['high','low']]
n_step=max([max(len(i),len(j)) for i,j in seq_data])
n_hidden=128
n_class=len(letter2idx)
batch_size=3
def make_data(seq_data):
enc_input_all,dec_input_all,dec_output_all=[],[],[]
for seq in seq_data:
for i in range(2):
seq[i]=seq[i]+'?'*(n_step-len(seq[i]))
enc_input=[letter2idx[n] for n in (seq[0]+'E')]
dec_input=[letter2idx[n] for n in ('S'+seq[1])]
dec_output=[letter2idx[n] for n in (seq[1]+'E')]
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output)
return torch.Tensor(enc_input_all),torch.Tensor(dec_input_all),torch.LongTensor(dec_output_all)
enc_input_all,dec_input_all,dec_output_all=make_data(seq_data)
class TranslateDataSet(Data.Dataset):
def __init__(self,enc_input_all,dec_input_all,dec_output_all):
self.enc_input_all=enc_input_all
self.dec_input_all=dec_input_all
self.dec_output_all=dec_output_all
def __len__(self):
return len(self.enc_input_all)
def __getitem__(self,idx):
return self.enc_input_all[idx],self.dec_input_all[idx],self.dec_output_all[idx]
loader=Data.DataLoader(TranslateDataSet(enc_input_all,dec_input_all,dec_output_all),batch_size,True)
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder=nn.RNN(input_size=n_class,hidden_size=n_hidden,dropout=0.5)
self.decoder=nn.RNN(input_size=n_class,hidden_size=n_hidden,dropout=0.5)
self.fc=nn.Linear(n_hidden,n_class)
def forward(self,enc_input,enc_hidden,dec_input):
enc_input=enc_input.transpose(0,1)
dec_input=dec_input.transpose(0,1)
_,h_t=self.encoder(enc_input,enc_hidden)
outputs,_=self.decoder(dec_input,h_t)
model=self.fc(outputs)
return model
model=Seq2Seq().to(device)
criterion=nn.CrossEntropyLoss().to(device)
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
for epoch in range(5000):
for enc_input_batch,dec_input_batch,dec_output_batch in loader:
h_0=torch.zeros(1,batch_size,n_hidden).to(device)
(enc_input_batch,dec_input_batch,dec_output_batch)=(enc_input_batch.to(device),dec_input_batch.to(device),dec_output_batch.to(device))
pred=model(enc_input_batch,h_0,dec_input_batch)
pred=pred.transpose(0,1)
loss=0
for i in range(len(dec_output_batch)):
loss+=criterion(pred[i],dec_output_batch[i])
if (epoch+1)%1000==0:
print('Epoch:','%04d'%(epoch+1),'cost =','{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
def translate(word):
enc_input,dec_input,_=make_data([[word,'?'*n_step]])
enc_input,dec_input=enc_input.to(device),dec_input.to(device)
hidden=torch.zeros(1,1,n_hidden).to(device)
output=model(enc_input,hidden,dec_input)
predict=output.data.max(2,keepdim=True)[1]
decoded=[letter[i] for i in predict]
translated=''.join(decoded[:decoded.index('E')])
return translated.replace('?','')
print('test')
print('man ->',translate('man'))
print('mans ->',translate('mans'))
print('king ->',translate('king'))
print('black ->',translate('black'))
print('up ->',translate('up'))
程序运行结果:
Epoch: 1000 cost = 0.002397
Epoch: 1000 cost = 0.002367
Epoch: 2000 cost = 0.000499
Epoch: 2000 cost = 0.000500
Epoch: 3000 cost = 0.000155
Epoch: 3000 cost = 0.000150
Epoch: 4000 cost = 0.000052
Epoch: 4000 cost = 0.000052
Epoch: 5000 cost = 0.000019
Epoch: 5000 cost = 0.000018
test
man -> women
mans -> women
king -> queen
black -> white
up -> down4.简单总结nn.RNNCell、nn.RNN
(1)torch.nn.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh')
- input_size – 输入
x中预期特征的数量 - hidden_size – 隐藏状态下的特征数量
h - 偏差 – 如果
False,则该层不使用偏差权重b_ih和b_hh。默认值:True - 非线性 – 使用的非线性。可以是
'tanh'或'relu'。默认:'tanh'
输入数据的格式:
- 形状
(batch, input_size)的输入:包含输入特征的张量 - 形状
(batch, hidden_size)的隐藏:包含批次中每个元素的初始隐藏状态的张量。没有说明的,就默认初始化为零。
输出数据的形状(batch,hidden_size):包含没批次中,下一个隐藏的张量。
在了解了基本的输入和输出数据的基本格式之后,至少对nn.RNNCell的使用就不成问题了。
输入分为两部分:第一部分就是批次输入的数据特征,第二部分就是隐藏状态的张量(默认为零),可以自定义隐藏状态的特征数量,也就是上面的hidden_size。
(2)torch.nn.RNN(*args, **kwargs)
参数:
- input_size – 输入
x中预期特征的数量 - hidden_size – 隐藏状态下的特征数量
h - num_layers – 循环层数。例如,设置
num_layers=2意味着将两个 RNN 堆叠在一起形成stacked RNN,第二个 RNN 接收第一个 RNN 的输出并计算最终结果。默认值:1 - 非线性 – 使用的非线性。可以是
'tanh'或'relu'。默认:'tanh' - batch_first – 如果为
True,则输入和输出张量作为(batch, seq, feature)提供。默认值:False - dropout – 如果非零,则在除最后一层之外的每个 RNN 层的输出上引入
Dropout层,dropout 概率等于dropout。默认值:0 - 双向 – 如果是
True,则成为双向 RNN。默认:False
RNN比RNNCell多了num_layers,即循环层数.
对比:

上图是RNNCell,左侧是一个单元,右边虽然是多个单元连接起来,但其实是一个单元,权值共享。这里的num_layers=1.

相同颜色的单元是一层,和前面一样,权值共享,不同颜色的是不同层,这里的num_layers=3
两者都已经有了非线性。
5.谈一谈对“序列”、“序列到序列”的理解
序列:通常指一系列有序的元素或者事件的集合。例如一个字符串是一个序列,一天中,某些时刻的天气状况组成在一起也是一个序列。
序列到序列:也称为Seq2Seq,输入和输出都是序列的模型,核心思想是把一个序列映射到另一个序列。Seq2Seq模型通常由两个主要组件组成:编码器(Encoder)和解码器(Decoder)。编码器将输入序列转换为一个固定维度的向量,也被称为上下文向量或隐藏状态。解码器接收这个上下文向量,并根据它生成目标序列。常见的应用有翻译,语音转文字,文本摘要,对一个视频进行概括等。当然也不局限于这些,只需要把握核心思想,这个模型的应用非常广泛。
6.总结本周理论课和作业,写心得体会
循环神经网络关注了前一次输入对当前输入的影响。又通过权值共享,减少了参数量。理论课上的讲解,使得我对RNN有了一定的认识和了解,通过完成作业,使得我对RNN的基础实现有了进一步的认识。RNN确实相对于前馈全连接神经网络更加抽象,它的网络模型更加复杂,要想更进一步一步理解RNN,还要有更多的积累。
参考:















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









