








项目任务要点:
- 统计3年考研政治真题、模拟题,约1000道。
- 对于输入的问题准确无误给出答案和解析,解析不少于30字,错题率不超过10%(比未微调的模型表达更加简洁精炼、相关度高)。
- 能够同时开设多个对话。
- 有简洁明了的交互界面。
针对我们项目的需求,我们制作一个用于训练大模型的数据集,首先我进行了数据集相关知识的学习。引用自什么是数据集?-CSDN博客
数据集
数据集知识
数据集是指一组相关的数据样本,通常用于机器学习、数据挖掘、统计分析等领域。数据集可以是数字、文本、图像、音频或视频等形式的数据,用于训练和测试机器学习算法和模型。
在机器学习中,数据集通常被划分为训练集、验证集和测试集三个子集。训练集用于训练机器学习模型,验证集用于选择和调整模型的超参数和结构,测试集用于评估模型的性能和准确度。
数据集的质量对机器学习算法和模型的性能和准确度有很大的影响。一个好的数据集应该包含足够的样本,具有代表性,样本之间应该相互独立,且标签应该正确和一致。
1.训练集
训练集是用于训练机器学习模型的数据集,它通常是数据集中的大部分数据。在训练集上,机器学习模型通过学习数据样本的特征和规律来调整自己的参数和权重,以便更好地拟合数据。
例如,如果我们想要训练一个分类模型,我们可以把训练集中的每个数据样本都标上正确的标签,然后通过训练集中的数据样本来调整模型的参数和权重,以便让模型在预测未知数据时能够正确地分类。
2.验证集
验证集是用于调整模型的超参数和结构的数据集。超参数是指那些需要手动设置的参数,例如学习率、正则化参数等。在训练模型时,我们需要调整超参数的值,以便让模型能够更好地拟合数据。
验证集通常是从训练集中独立出来的一部分数据,但与测试集不同,它不用于最终评估模型的性能。在调整超参数时,我们可以使用验证集来评估不同超参数下模型的性能表现,从而找到最优的超参数组合。
3.测试集
测试集是用于测试机器学习模型性能和准确度的数据集。测试集通常是从数据集中独立出来的一部分数据,它不参与模型的训练和调整过程。在使用机器学习模型对新数据进行预测时,我们需要评估模型的性能和准确度,以便选择最优的模型。
测试集的结果可以帮助我们评估模型的准确度、泛化能力等指标,从而帮助我们选择最佳的模型。在评估模型性能时,我们可以使用一些指标,例如准确率、召回率、F1分数等,来评估模型的性能和准确度。
优秀的数据集

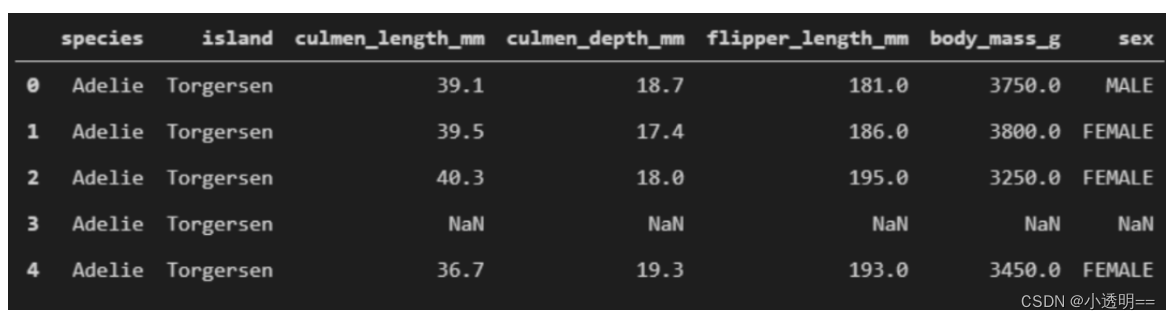
显然,在该数据集中,数据为三个岛屿上的三种不同种类的企鹅,数据集中的数据即为这些企鹅,包括这些企鹅的各种属性。参考一些优秀的数据集并进行学习后,我们开始了我们的数据集设计。
数据集设计
由于我们的项目为考研政治知识题库系统,因此我们需要大量的考研政治题目来训练我们的大模型,我们的数据集就是各种考研政治题目的集合。数据属性为:题号、题目类型、题干、答案、解析等属性。在大模型的训练过程,我们使用肖4肖8模拟题来制作训练集。后期检测、测试过程中,我们使用近10年的考研政治真题来进行测试。
收集好对应的数据后,使用python将docx文件中的文本内容转换为符合项目要求的coversation形式,以供训练大模型。















 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









