







之前我进行了对大模型的KV Cache方法和W4A16 量化以及使用了W4A16 量化后得到的模型再使用KV Cache三种形式的量化,发现模型的显存占用是有明显的下降的,而在降低显存的同时,一般还能带来性能的提升,因为更小精度的浮点数要比高精度的浮点数计算效率高,而整型要比浮点数高很多。
我们采用W4A16后保持FP16,只对参数进行 4bit 量化,同时将已经生成序列的 KV 变成 Int8的模型作为量化后的模型,与量化前进行对比。
模型速度的测试
首先计算量化之前的速度测试:
给定一个测试例子,进行速度测试
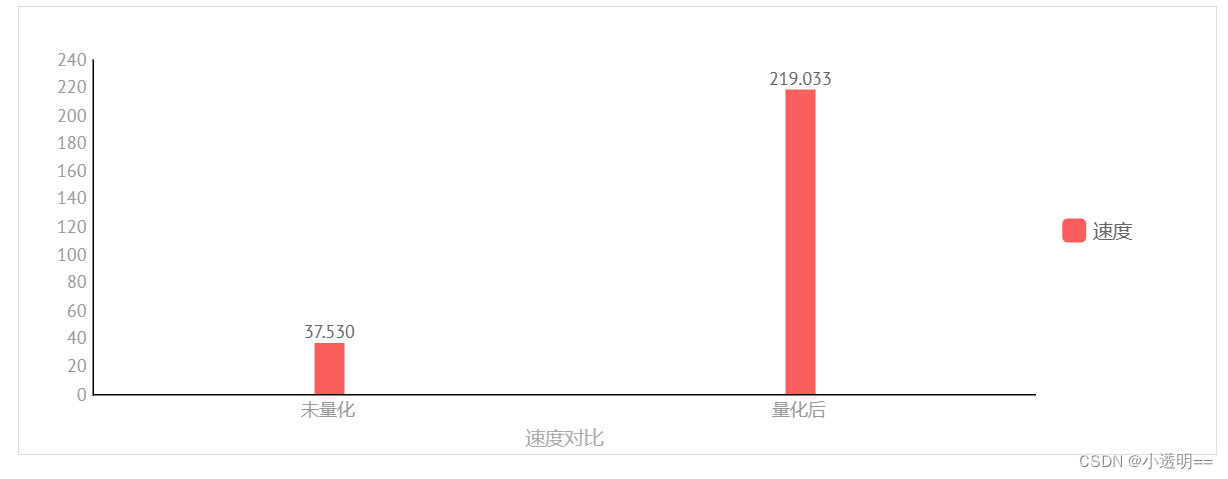
得到测试前速度:37.530 words/s

对量化后的速度测试:
得到量化后速度:219.033 words/s

我们发现:在进行了两种方式结合的量化后,模型速度有了很大幅度的提升。
总结:
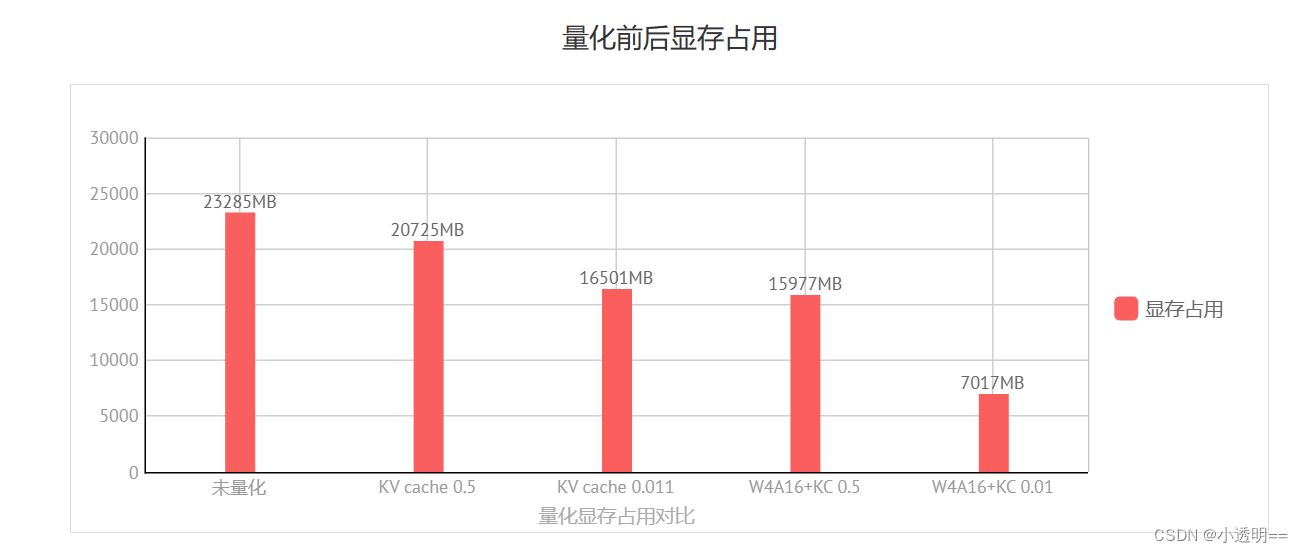
服务部署和量化是没有直接关联的,量化的最主要目的是降低显存占用,主要包括两方面的显存:模型参数和中间过程计算结果,前者使用W4A16 量化、后者使用KV Cache量化。
量化过程我们采用最佳实践过程,如下图所示,再使用了KV Cache的基础上我们还进行了W4A16量化得到了参数量化后的新模型。

最后得到了比较满意的结果,随着量化的进行,我们模型的显存占用越来越低,显存降低的同时,也给我们模型的性能带来的较大程度的提升:对比最终版本与量化前的版本的计算速度后我们发现量化后的速度有了很大提升。

















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









