







1、主要解决问题:
多边形多机器人导航的避障问题具有高度复杂性。现有研究通常采用对机器人外形的简化方法,或者将其抽象为机器人之间存在正距离约束的优化问题,但这两种方法对于实时控制性和可扩展性存在一定的限制。此外,由于多边形之间存在隐式且不可微的距离函数,使得多边形机器人之间的避障导航更加困难。针对于此问题,论文对多边形机器人速度障碍(Velocity Obstacle, VO)原理进行了扩展,并提出了一种新的构建VO的方法。
2、研究方法:
论文提出了一种新的多边形分布式多机器人避障方法,该方法包括高效率多边形VO计算方法和分布式多机器人系统导航方法。
针对高效率多边形VO计算方法,论文首先介绍了基于圆形的VO方法(如图1所示),以此为基础又介绍了两种基于圆形VO方法的变式:RVO和HRVO方法。
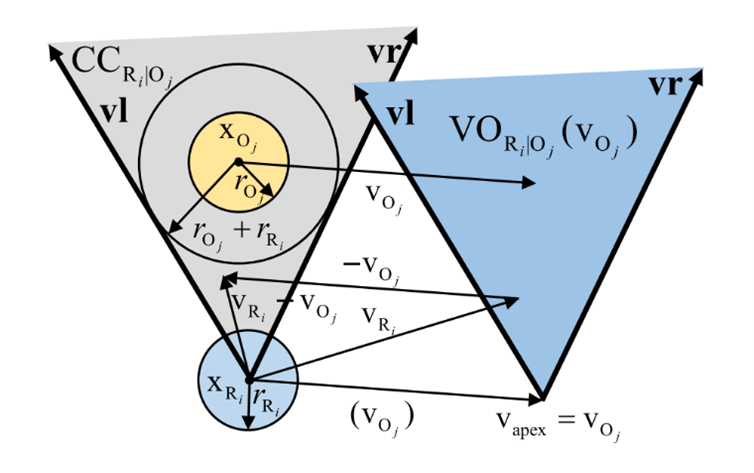
图1 基于圆形的VO方法
然而基于圆形的避障方法,往往会导致多机器人的锁死状态。因此,论文基于多边形避障提出了新的VO方法(如图2所示)。首先,分别在机器人和障碍物上依次选取顶点构建顶点对,并将两点连接形成向量,可以得到所有向量与x轴之间的夹角。然后,根据夹角的最小值和最大值,可以计算VO圆锥区域两侧的方向向量。最后,根据障碍物速度构建基于多边形的VO区域。
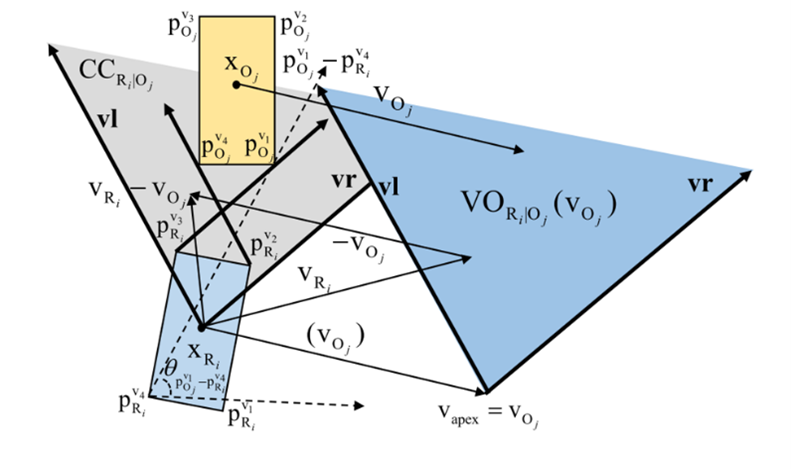
图2 基于多边形的VO方法
针对分布式多机器人系统导航方法,论文假设所有机器人都使用相同的策略导航到目标位置。因此,其关键在于为每个机器人选择合适的速度(如图3所示)。首先,为每个机器人构建复合VO(所有VO区域的并集),机器人需要在复合VO之外选择一个速度。其次,为机器人构建速度选择函数,需要尽可能的接近每个机器人的目标方向,同时考虑与障碍物的预期碰撞时间。
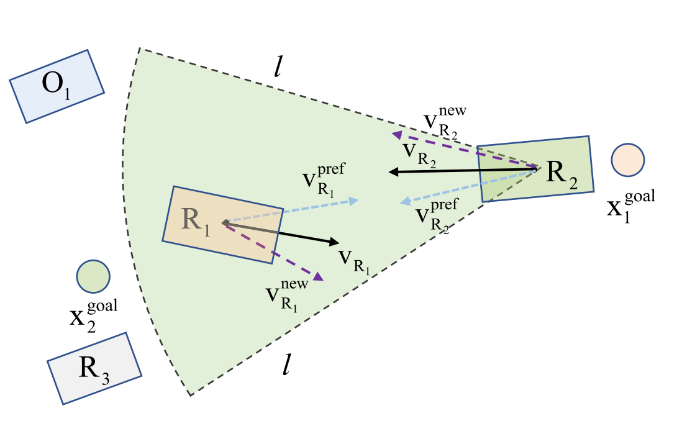
图3 多机器人系统分布式导航示意图
论文的实验部分对所提出的多边形避障VO方法的可行性与先进性进行了评估。首先,论文构建了一个10m×10m的仿真场景,仿真时间步长Δt=0.1s,循环的最大时间tmax=30s,机器人由实时线速度v和角速度ω控制。实验使用8个不同的多边形机器人,均布于半径为8m的圆周上,以中心对称点作为目标位置进行避障导航,实验证明了所提出方法的可行性(如图4所示)。

图4 基于论文方法的圆形场景仿真结果
其次,为了验证所提出方法的先进性,论文在相同设置下,构建了包含两个静态障碍物和两个动态障碍物的新仿真环境(如图5所示),以完成率、锁死率、平均行进距离作为评价指标,同时对比VO、RVO、HRVO方法分别在基于圆形与基于论文多边形避障方法的性能(如图6所示)。

图5 多边形避障仿真环境示意图

图6 不同方法的性能数值
3、结论:
论文提出了一种基于速度障碍的多机器人导航方法,该方法应用于多边形分布式机器人系统。首先,论文介绍了一种无需进行优化的多边形VO方法,通过构建两个多边形物体之间的速度障碍来实现碰撞避免。随后,论文提出了一种基于VO原理的多机器人导航方法,并在多种具有挑战性的场景中进行了验证。数值仿真结果表明,该方法在导航性能方面表现出色,并且在任务完成率、锁死率以及平均行进距离等方面均优于当前技术水平。















 4597
4597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









