






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**写在最前:目标
1.虚拟环境的基本操作:知道如何创建环境、删除环境、用pycharm来绑定我创建的环境。
2.跑通代码
一、环境配置
编译器:pycharm community
语言环境:Python 3.9.19
深度学习环境:TensorFlow 2.9.0
1.1虚拟环境的基本操作(conda prompt)
首先,我们需要先创建一个虚拟环境,我们所有的操作都是基于虚拟环境展开的。有了虚拟环境,我们可以在base环境没有安装python和深度学习框架的的情况下训练模型。同时,所创建的环境也可以很方便地删除。
(ps:我在另外一台电脑安装环境的时候,无法通过conda create env来创建环境,,每次都卡在“wheel”包。因此我换了一个叫做“conda-forge”库来帮助我创建环境。)
1.创建虚拟环境(特别注意空格!!)
这里创建了一个名为“my_env”,使用的python版本是3.8的虚拟环境
conda create -n my_env python=3.82.列举出现有的虚拟环境
conda env list3.删除某个虚拟环境
这里删除掉了一个名为“my_env”的环境,另外建议这里需要返回到base环境里再执行这个操作
conda env remove -n my_env4.返回到base环境
conda deactivate5.激活环境
这里激活了一个名为“name”的环境。注意,激活该环境的时候,需要已经创建了。
conda activate name6.查看该环境下的python版本
python --version7.在该环境下安装TensorFlow
# 安装指定版本的 TensorFlow
pip install tensorflow-gpu==2.9
# 需要注意的是,这里的pip安装可能会出问题,原因不明,建议使用conda安装
conda install -c conda-forge tensorflow-gpu==2.9
8.查看该环境下的TensorFlow版本(特别注意空格和__!!!!)
python -c "import tensorflow as tf; print(tf.__version__)"1.2pycharm绑定环境
1.创建一个项目
file--新建项目---重命名,选择路径---创建
2.绑定环境
file---设置---项目---选择你刚刚创建的python解析器---添加解析器---添加本地解析器---conda环境---使用现有环境---选择你刚刚创建的环境---确定
二、前期准备
2.1数据集下载
由于每次训练数据集都需要下载数据,时间很长,所以索性直接将数据集下载在本地。
2.2设置gpu
这里加入了打印判别
gpus = tf.config.list_physical_devices('GPU')
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True) # 设置显存按需增长
tf.config.set_visible_devices([gpu0],"GPU")
print("GPU available.")
else:
print("GPU cannot be find,using CPU instead.")
2.3导入数据
一次性全部导入。
import tensorflow as tf
import os
import tarfile
import numpy as np
import pickle
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt2.4解压和加载本地数据集文件
这里有个有趣的事情,因为我是下载的数据集,因此我需要每次都解压。这时我们可以在代码中添加一个检查逻辑,如果数据集已经解压,就直接加载数据,而不是每次都解压。
# 解压路径
extract_path = 'D:/others/pycharm/pythonProject/cifar-10-python/cifar-10-batches-py'
# 检查文件是否已解压
if not os.path.exists(extract_path):
# 本地数据集文件路径
local_file_path = 'D:/others/pycharm/pythonProject/cifar-10-python.tar.gz' #我的文件路径
os.makedirs(extract_path, exist_ok=True)
# 解压数据集文件
with tarfile.open(local_file_path, 'r:gz') as tar:
tar.extractall(path=os.path.dirname(extract_path))
# 加载解压后的数据集
def load_cifar10_batch(cifar10_dataset_folder_path, batch_id):
with open(os.path.join(cifar10_dataset_folder_path, 'data_batch_' + str(batch_id)), mode='rb') as file:
batch = pickle.load(file, encoding='latin1')
features = batch['data'].reshape((len(batch['data']), 3, 32, 32)).transpose(0, 2, 3, 1)
labels = np.array(batch['labels'])
return features, labels
2.5加载数据
这里有点不懂,需要后续花时间搞懂一下
# 加载解压后的数据集
def load_cifar10_batch(cifar10_dataset_folder_path, batch_id):
with open(os.path.join(cifar10_dataset_folder_path, 'data_batch_' + str(batch_id)), mode='rb') as file:
batch = pickle.load(file, encoding='latin1')
features = batch['data'].reshape((len(batch['data']), 3, 32, 32)).transpose(0, 2, 3, 1)
labels = np.array(batch['labels'])
return features, labels
def load_cifar10_test_batch(cifar10_dataset_folder_path):
with open(os.path.join(cifar10_dataset_folder_path, 'test_batch'), mode='rb') as file:
batch = pickle.load(file, encoding='latin1')
features = batch['data'].reshape((len(batch['data']), 3, 32, 32)).transpose(0, 2, 3, 1)
labels = np.array(batch['labels'])
return features, labels
cifar10_dataset_folder_path = extract_path
# 加载训练数据
train_images = []
train_labels = []
for i in range(1, 6):
features, labels = load_cifar10_batch(cifar10_dataset_folder_path, i)
train_images.append(features)
train_labels.append(labels)
train_images = np.concatenate(train_images)
train_labels = np.concatenate(train_labels)
# 加载测试数据
test_images, test_labels = load_cifar10_test_batch(cifar10_dataset_folder_path)2.6 归一化
# 归一化
train_images, test_images = train_images / 255.0, test_images / 255.0
2.7可视化归一结果
# keshi打印归一化后的图像尺寸
print(train_images.shape, test_images.shape, train_labels.shape, test_labels.shape)
# 显示前 20 张图像
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(20, 10))
for i in range(20):
plt.subplot(5, 10, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
三、搭建模型(CNN)
3.1模型结构
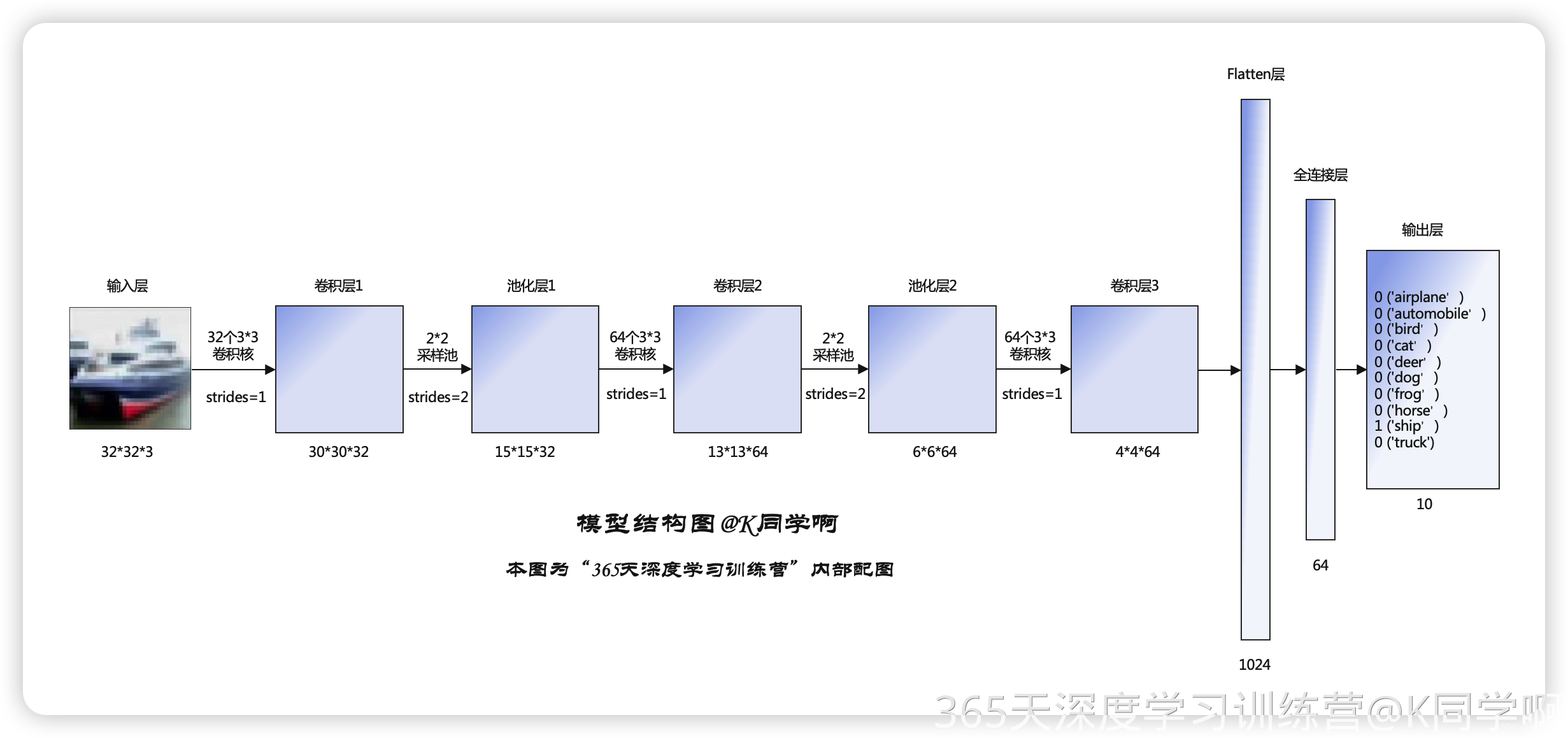
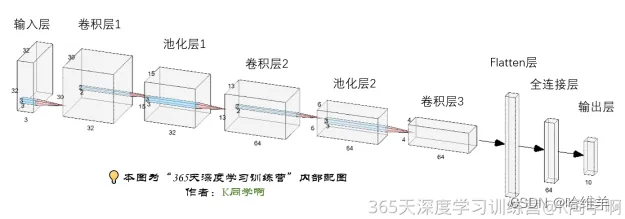
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)), # 卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(10) # 输出层,输出预期结果
])
model.summary() # 打印网络结构输出
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
进程已结束,退出代码为 03.2模型编译
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])3.3模型训练
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))训练结果如下:
2024-06-05 20:53:33.335456: W tensorflow/core/framework/cpu_allocator_impl.cc:82] Allocation of 614400000 exceeds 10% of free system memory.
Epoch 1/10
2024-06-05 20:53:35.138652: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8100
1563/1563 [==============================] - 15s 5ms/step - loss: 1.5403 - accuracy: 0.4383 - val_loss: 1.2772 - val_accuracy: 0.5382
Epoch 2/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1675 - accuracy: 0.5840 - val_loss: 1.1246 - val_accuracy: 0.5962
Epoch 3/10
1563/1563 [==============================] - 7s 4ms/step - loss: 1.0179 - accuracy: 0.6398 - val_loss: 1.0707 - val_accuracy: 0.6224
Epoch 4/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.9142 - accuracy: 0.6777 - val_loss: 0.9220 - val_accuracy: 0.6748
Epoch 5/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.8465 - accuracy: 0.7021 - val_loss: 0.8923 - val_accuracy: 0.6891
Epoch 6/10
1563/1563 [==============================] - 7s 5ms/step - loss: 0.7853 - accuracy: 0.7248 - val_loss: 0.8956 - val_accuracy: 0.6873
Epoch 7/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.7328 - accuracy: 0.7426 - val_loss: 0.8921 - val_accuracy: 0.6965
Epoch 8/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6911 - accuracy: 0.7557 - val_loss: 0.8859 - val_accuracy: 0.6994
Epoch 9/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6505 - accuracy: 0.7705 - val_loss: 0.8903 - val_accuracy: 0.6986
Epoch 10/10
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6148 - accuracy: 0.7841 - val_loss: 0.8611 - val_accuracy: 0.7093
进程已结束,退出代码为 0可以发现,这里的准确率最后达到了78%。















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









