






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**本文将采用CNN实现多云、下雨、晴、日出四种天气状态的识别。较上篇文章,本文为了增加模型的泛化能力,新增了Dropout层并且将最大池化层调整成了平均池化层
一、模型跑通
1.1环境配置
编译器:pycharm community
语言环境:Python 3.9.19
深度学习环境:TensorFlow 2.9.0
1.2模型搭建步骤
- GPU 设置:检查是否有 GPU 可用,并设置显存按需增长。
- 数据目录设置:设置数据目录,统计图片总数。
- 数据集参数设置:设置批次大小、图像高度和宽度。
- 加载数据集:使用
tf.keras.preprocessing.image_dataset_from_directory加载训练和验证数据集。 - 数据集缓存和预取:缓存和预取数据,以提高训练效率。
- 构建模型:定义神经网络模型,包括卷积层、池化层和全连接层。
- 编译模型:指定优化器、损失函数和评估指标。
- 训练模型:使用训练数据集训练模型,并使用验证数据集评估模型性能。
- 可视化:绘制训练和验证的准确率与损失曲线,帮助分析模型的表现。
先放出全部代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import tensorflow as tf
import tarfile
import numpy as np
import pickle
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
import pathlib
from PIL import Image # 导入PIL模块
# GPU设置
gpus = tf.config.list_physical_devices('GPU')
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True) # 设置显存按需增长
tf.config.set_visible_devices([gpu0], "GPU")
print("GPU available.")
else:
print("GPU cannot be found, using CPU instead.")
# 数据目录设置
data_dir = "D:/others/pycharm/pythonProject/weather_photos"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
# 显示一张示例图片
roses = list(data_dir.glob('sunrise/*.jpg'))
Image.open(str(roses[0])).show() # 使用PIL打开并显示图片
# 数据集参数设置
batch_size = 32
image_height = 180
image_width = 180
# 加载训练数据集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(image_height, image_width),
batch_size=batch_size
)
# 加载验证数据集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(image_height, image_width),
batch_size=batch_size
)
# 打印类别名称
class_names = train_ds.class_names
print(class_names)
# 显示一些示例图片
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(4, 5, i + 1) # 4行5列,显示20张图片
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
# 数据集缓存和预取
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
num_classes = 4
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(image_height, image_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu'), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3), # 让神经元以一定的概率停止工作,防止过拟合,提高模型的泛化能力
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
检验:

输出全部内容:
D:\others\anaconda\envs\deep_learning_env\python.exe D:\others\pycharm\pythonProject\T3_wether_recognition.py
GPU cannot be found, using CPU instead.
图片总数为: 1125
Found 1125 files belonging to 4 classes.
Using 900 files for training.
2024-06-13 21:07:43.503321: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-06-13 21:07:43.508042: I tensorflow/core/common_runtime/process_util.cc:146] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
Found 1125 files belonging to 4 classes.
Using 225 files for validation.
['cloudy', 'rain', 'shine', 'sunrise']
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 178, 178, 16) 448
average_pooling2d (AverageP (None, 89, 89, 16) 0
ooling2D)
conv2d_1 (Conv2D) (None, 87, 87, 32) 4640
average_pooling2d_1 (Averag (None, 43, 43, 32) 0
ePooling2D)
conv2d_2 (Conv2D) (None, 41, 41, 64) 18496
dropout (Dropout) (None, 41, 41, 64) 0
flatten (Flatten) (None, 107584) 0
dense (Dense) (None, 128) 13770880
dense_1 (Dense) (None, 4) 516
=================================================================
Total params: 13,794,980
Trainable params: 13,794,980
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
29/29 [==============================] - 7s 176ms/step - loss: 1.1804 - accuracy: 0.6811 - val_loss: 0.5816 - val_accuracy: 0.7333
Epoch 2/10
29/29 [==============================] - 4s 146ms/step - loss: 0.4633 - accuracy: 0.8333 - val_loss: 0.5103 - val_accuracy: 0.7733
Epoch 3/10
29/29 [==============================] - 5s 156ms/step - loss: 0.3975 - accuracy: 0.8311 - val_loss: 0.5828 - val_accuracy: 0.7467
Epoch 4/10
29/29 [==============================] - 5s 157ms/step - loss: 0.3543 - accuracy: 0.8556 - val_loss: 0.4825 - val_accuracy: 0.8133
Epoch 5/10
29/29 [==============================] - 5s 169ms/step - loss: 0.2667 - accuracy: 0.8844 - val_loss: 0.5889 - val_accuracy: 0.7422
Epoch 6/10
29/29 [==============================] - 5s 167ms/step - loss: 0.2447 - accuracy: 0.9122 - val_loss: 0.5226 - val_accuracy: 0.7822
Epoch 7/10
29/29 [==============================] - 5s 160ms/step - loss: 0.1587 - accuracy: 0.9400 - val_loss: 0.5445 - val_accuracy: 0.8000
Epoch 8/10
29/29 [==============================] - 4s 155ms/step - loss: 0.1648 - accuracy: 0.9289 - val_loss: 0.4988 - val_accuracy: 0.8178
Epoch 9/10
29/29 [==============================] - 4s 149ms/step - loss: 0.1108 - accuracy: 0.9600 - val_loss: 0.4645 - val_accuracy: 0.8311
Epoch 10/10
29/29 [==============================] - 4s 137ms/step - loss: 0.0738 - accuracy: 0.9778 - val_loss: 0.4796 - val_accuracy: 0.8311
进程已结束,退出代码为 0二、学习积累:
2.1数据集切分
在搭建模型的一开始,便需要导入训练数据。有2种导入训练数据的方法:
- 本地数据集:需要指定数据目录,通过
pathlib.Path设置路径,然后使用tf.keras.preprocessing.image_dataset_from_directory等方法加载数据。 - 在线数据集:可以直接使用 TensorFlow 提供的内置下载和加载函数(如
datasets.mnist.load_data())来获取数据。
1.本地数据集,如果你的数据集存储在本地文件系统中(例如,你的硬盘驱动器上),你需要指定数据目录以便加载这些数据。通常使用 tf.keras.preprocessing.image_dataset_from_directory 或类似的方法从本地目录加载数据。示例如下:
import pathlib
# 指定数据目录
data_dir = pathlib.Path("path/to/your/local/dataset")
# 使用 TensorFlow 的 image_dataset_from_directory 方法加载数据集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
train_dir, # 数据所在的目录路径
validation_split=0.2, # 数据集划分的比例,将20%的数据用作验证集
subset="training", # 指定这个数据集是训练集
seed=123, # 随机种子,用于数据集划分的一致性
image_size=(image_height, image_width), # 图像的尺寸,将所有图像调整到相同的尺寸
batch_size=batch_size # 每个批次的大小
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
train_dir, # 数据所在的目录路径,注意这里依旧是train_dir而不是val_dir,因为validation_split已经处理了拆分
validation_split=0.2, # 数据集划分的比例,将20%的数据用作验证集
subset="validation", # 指定这个数据集是验证集
seed=123, # 随机种子,用于数据集划分的一致性
image_size=(image_height, image_width), # 图像的尺寸,将所有图像调整到相同的尺寸
batch_size=batch_size # 每个批次的大小
)
2.在线数据集
如果你的数据集可以通过网络直接下载(例如,MNIST、CIFAR-10 等常用的数据集),你可以使用 TensorFlow 提供的内置函数下载和加载这些数据集,而无需指定本地目录。示例如下:
from tensorflow.keras import datasets
# 下载并加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 下载并加载 CIFAR-10 数据集
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
关于:tf.keras.preprocessing.image_dataset_from_directory 方法
由于数据集需要拆分成训练集和验证集,而人为拆分会导致数据缺乏一致性,因此采用tf.keras.preprocessing.image_dataset_from_directory 能够自动处理数据的划分,你只需要提供一次数据目录路径,并指定划分比例。这样做的好处是避免了手动将数据集拆分为训练集和验证集,并确保划分的一致性。
因此我们可以看到,在以上tf.keras.preprocessing.image_dataset_from_directory 代码中,train_ds和val_ds都是同一个根文件夹,也就是data_dir,这样可以让机器自动从同一个目录中创建训练集和验证集。
另外,在代码中,validation_split和subset 参数的用法值得注意,
validation_split 参数的值是指要从数据集中划分为验证集的比例,而不是训练集的比例。subset 参数则决定了你要从数据集中获取的是训练集部分还是验证集部分。
validation_split:表示将多少比例的数据用作验证集。比如0.2表示 20% 的数据作为验证集,剩下的 80% 作为训练集。subset:表示你要获取的是训练集部分还是验证集部分。可以是"training"或"validation"。validation_split=0.2:意味着 20% 的数据用作验证集,80% 的数据用作训练集。subset="training":表示从划分后的数据集中获取训练集部分(80%)。subset="validation":表示从划分后的数据集中获取验证集部分(20%)。
2.2随机种子
随机种子(Random Seed)是用于初始化随机数生成器的值。随机种子并没有一个固定的标准,只需要是整数即可。也就是说,任何整数都可以是随机种子。比如123,42等等。
2.3数据集缓存和预取
对于一些数据量大的数据集,需要进行数据集缓存和预取。如果没有这些步骤,训练时间会变长,硬件资源的利用率会降低,尤其是在处理大数据集和复杂模型时,这些问题会更加明显。
但是在T1:实现mnist手写数字识别中就不需要,因为MNIST数据集较小,可以在内存中直接加载和处理,不会遇到显著的 I/O (输入/输出)瓶颈。
2.3.1精简版
先上代码:
# 数据集缓存和预取
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)- shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
- prefetch():预取数据,加速运行
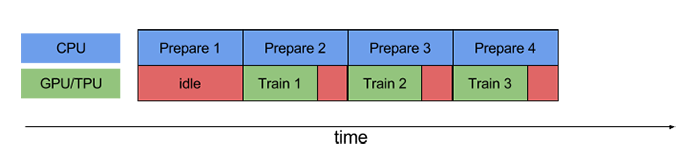
prefetch()功能详细介绍:CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:

使用prefetch()可显著减少空闲时间:
●cache():将数据集缓存到内存当中,加速运行
2.3.2易懂版
当然这段代码也可以简单易懂地写出来:
# 自动调整预取缓冲区大小
AUTOTUNE = tf.data.AUTOTUNE
# 对训练数据集进行缓存、打乱和预取操作
train_ds = train_ds.cache() # 缓存数据到内存中
train_ds = train_ds.shuffle(1000) # 打乱数据
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE) # 异步加载数据
# 对验证数据集进行缓存和预取操作
val_ds = val_ds.cache() # 缓存数据到内存中
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE) # 异步加载数据
数据集缓存 (cache())
什么是缓存?
缓存是一种将数据存储在高速访问的存储器(如 RAM)中的技术。目的是为了加快数据读取速度,减少访问时间。
cache() 方法的作用
在 TensorFlow 数据集处理中,cache() 方法用于将数据集缓存到内存中。这样,数据在第一次读取后会被存储在内存中,后续访问时会非常快。
代码解释
train_ds = train_ds.cache()
val_ds = val_ds.cache()
train_ds.cache():将训练数据集缓存到内存中。val_ds.cache():将验证数据集缓存到内存中。
优点
- 减少 I/O 操作:只在第一次遍历数据集时从磁盘读取数据,后续访问直接从内存读取。
- 加快数据读取速度:内存访问速度远高于磁盘,显著减少数据读取时间。
- 提高训练效率:减少数据加载的瓶颈,让 GPU 更加高效地进行训练。
数据集预取 (prefetch())
什么是预取?
预取是指在当前数据被处理的同时,提前加载后续需要的数据。这样可以确保处理数据时不会因为等待新数据而中断,提高整体处理效率。
prefetch() 方法的作用
在 TensorFlow 数据集处理中,prefetch() 方法用于在训练过程中异步加载数据。这样,当 GPU 处理当前批次数据时,CPU 可以同时准备下一个批次的数据。
代码解释
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
train_ds.prefetch(buffer_size=AUTOTUNE):异步加载训练数据集的下一个批次。AUTOTUNE让 TensorFlow 自动选择合适的缓冲区大小。val_ds.prefetch(buffer_size=AUTOTUNE):异步加载验证数据集的下一个批次。AUTOTUNE让 TensorFlow 自动选择合适的缓冲区大小。
优点
- 并行数据加载和处理:GPU 在处理当前批次时,CPU 同时准备下一个批次数据,减少等待时间。
- 提高 GPU 利用率:确保 GPU 不会因为数据加载而空闲,最大化利用 GPU 计算能力。
- 加快训练速度:整体训练过程更流畅和高效,减少训练时间。
总结
- 缓存 (
cache()):将数据集缓存到内存中,减少重复 I/O 操作,加快数据读取速度。 - 预取 (
prefetch()):异步加载数据,确保 GPU 在处理当前批次时,CPU 已经准备好下一个批次的数据,提高 GPU 利用率和训练速度。
通过这些操作,你可以显著提高数据加载和处理的效率,尤其是在处理大数据集和复杂模型时,效果更加明显。
2.4构建模型
该模型具有卷积层、池化层、丢弃层和全连接层。
关于卷积核:卷积的计算_卷积核2x2-CSDN博客
关于丢弃层:Dropout层 tf.keras.layers.Dropout() 介绍_keras.layers.dropout参数-CSDN博客
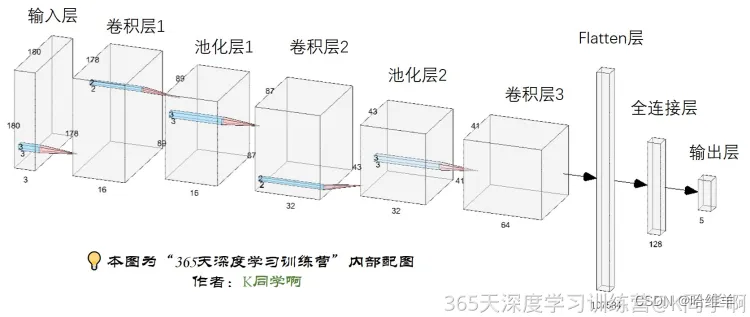
num_classes = 4 # 定义分类数
model = models.Sequential([
# 预处理层,将像素值缩放到 [0, 1] 范围内
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(image_height, image_width, 3)),
# 第一个卷积层,使用 16 个 3x3 的卷积核,激活函数为 ReLU
layers.Conv2D(16, (3, 3), activation='relu'),
# 第一个池化层,使用 2x2 的平均池化
layers.AveragePooling2D((2, 2)),
# 第二个卷积层,使用 32 个 3x3 的卷积核,激活函数为 ReLU
layers.Conv2D(32, (3, 3), activation='relu'),
# 第二个池化层,使用 2x2 的平均池化
layers.AveragePooling2D((2, 2)),
# 第三个卷积层,使用 64 个 3x3 的卷积核,激活函数为 ReLU
layers.Conv2D(64, (3, 3), activation='relu'),
# 丢弃层,以 30% 的概率让神经元停止工作,防止过拟合
layers.Dropout(0.3),
# 展平层,将多维输入展平为一维
layers.Flatten(),
# 全连接层,包含 128 个神经元,激活函数为 ReLU
layers.Dense(128, activation='relu'),
# 输出层,包含 num_classes 个神经元
layers.Dense(num_classes)
])
2.5编译模型
在深度学习中,“编译模型”是指对模型进行配置,以便它可以在训练过程中进行优化和评估。编译模型包括定义损失函数、优化器和评估指标。这一步是必要的,因为它指定了模型如何从数据中学习(优化器)、如何衡量学习的效果(损失函数)以及如何评估模型的性能(评估指标)。
在 TensorFlow/Keras 中,编译模型的典型步骤如下:
-
优化器(Optimizer):
- 优化器是用于更新模型权重的算法。常用的优化器包括
adam、sgd(随机梯度下降)等。 - 例如,
adam是一种自适应学习率优化器,通常在实践中表现良好。
- 优化器是用于更新模型权重的算法。常用的优化器包括
-
损失函数(Loss Function):
- 损失函数用于衡量模型在训练数据上的表现,表示预测值与真实值之间的差距。模型训练的目标是最小化这个损失值。
- 例如,对于分类任务,常用的损失函数包括
SparseCategoricalCrossentropy、CategoricalCrossentropy等。
-
评估指标(Metrics):
- 评估指标用于衡量模型的性能。它们不用于训练模型,而是用于评估模型的好坏。
- 例如,常用的评估指标包括
accuracy(准确率)。
在这里,模型编译是以下行:
# 设置优化器,这里定义了一个 Adam 优化器,并设置了学习率为 0.001。
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
# 编译模型,optimizer=opt:指定使用之前定义的 Adam 优化器。
#loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True):指定损失函数为 Sparse # Categorical Crossentropy,并指明输出是 logits。
# metrics=['accuracy']:使用准确率作为评估指标。
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
2.6 训练模型
训练模型的主要步骤包括使用训练数据集(train_ds)进行训练,同时使用验证数据集(val_ds)评估模型在每个训练周期后的性能。
-
设置训练周期(epochs):
- 定义模型训练过程中将遍历整个训练数据集的次数。
-
训练模型并记录历史:
- 使用训练数据集进行训练,并在每个 epoch 结束时使用验证数据集评估模型的性能。
- 将训练过程中的各种指标(如准确率和损失)记录在
history对象中,以便后续分析和可视化。
#训练模型
epochs = 10 # 设置训练周期数。epochs 表示训练过程中将遍历整个训练数据集的次数。在每个 epoch 结束时,模型会在验证数据集上进行评估。
history = model.fit(
train_ds, # 训练数据集
validation_data=val_ds, # 验证数据集
epochs=epochs # 训练周期数
# train_ds:用于训练模型的训练数据集。
# validation_data=val_ds:用于评估模型的验证数据集。在每个 epoch 结束时,模型会在验证数据集上进行评估,以监测模型的性能。
# epochs=epochs:设置训练的 epoch 数。
)
2.7 训练结果可视化
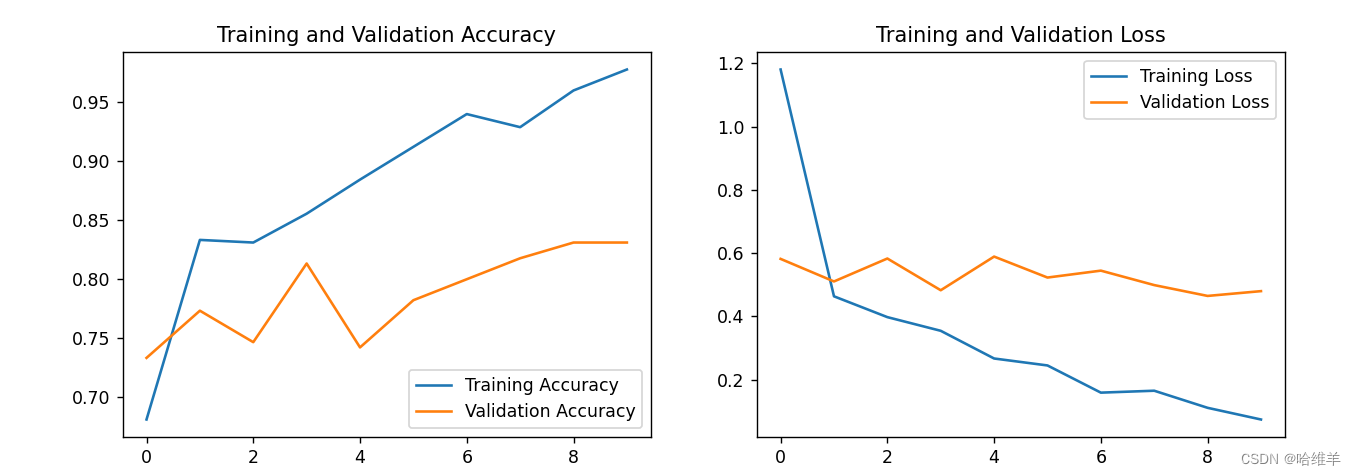
- 准确率曲线:通过观察训练准确率和验证准确率的曲线,你可以了解模型的学习效果和泛化能力。如果训练准确率很高而验证准确率较低,可能存在过拟合。
- 损失曲线:通过观察训练损失和验证损失的曲线,你可以判断模型的优化效果。如果损失曲线趋于平稳且较低,说明模型在逐渐收敛。
import matplotlib.pyplot as plt
# 从训练历史中提取指标
acc = history.history['accuracy'] # 提取训练集上的准确率
val_acc = history.history['val_accuracy'] # 提取验证集上的准确率
loss = history.history['loss'] # 提取训练集上的损失
val_loss = history.history['val_loss'] # 提取验证集上的损失
# 设置绘图范围
epochs_range = range(epochs) # 表示从 0 到 epochs 的范围,用于设置横轴的范围
# 创建一个图像,包含两个子图
plt.figure(figsize=(12, 4)) # 创建一个图像,设置图像的大小为 12 x 4 英寸
# 绘制准确率曲线
plt.subplot(1, 2, 1) # 创建一个包含 1 行 2 列的子图,并选择第一个子图
plt.plot(epochs_range, acc, label='Training Accuracy') # 绘制训练集上的准确率曲线,横轴为 epoch,纵轴为准确率
plt.plot(epochs_range, val_acc, label='Validation Accuracy') # 绘制验证集上的准确率曲线,横轴为 epoch,纵轴为准确率
plt.legend(loc='lower right') # 在图的右下角显示图例
plt.title('Training and Validation Accuracy') # 设置图的标题
# 绘制损失曲线
plt.subplot(1, 2, 2) # 选择第二个子图
plt.plot(epochs_range, loss, label='Training Loss') # 绘制训练集上的损失曲线,横轴为 epoch,纵轴为损失
plt.plot(epochs_range, val_loss, label='Validation Loss') # 绘制验证集上的损失曲线,横轴为 epoch,纵轴为损失
plt.legend(loc='upper right') # 在图的右上角显示图例
plt.title('Training and Validation Loss') # 设置图的标题
# 显示图像
plt.show() # 显示生成的图像















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









