







1. Kimi-1.5与DeepSeek-R1的对比
DeepSeek-R1火出圈,这个是不争的事实,但在背后,其实也隐藏了一位有力的竞争者Kimi-1.5。先让我们一起来看下两位选手的对比。
1.1 技术报告呈现的效果对比
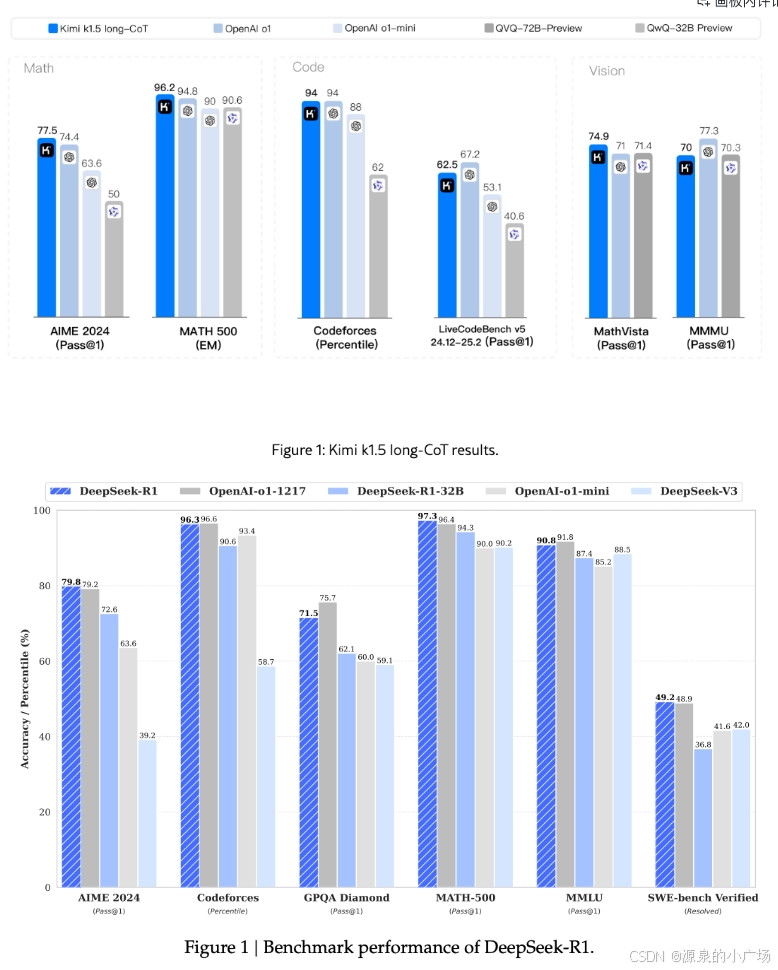
上图是Kimi-1.5【1】,下图是DeepSeek-R1【2】。从同样的数据集(AIME 2024、MATH 500、 Codeforces)测试来看,两者非常接近,与OpenAI的o1的差距也很接近。
1.2 官网使用
kimi官网同样已经开放K1.5的使用,而且大家的界面长得都一样,和OpenAI的chatgpt也一模一样。形式上总体看趋同。目前智谱清言还是没有趋同,有自己的风格,以多场景的智能体形式提供服务。不过对于C端用户来说,kimi和deepseek的ui会更顺手一些,操作和理解的门槛也会更低。

老样子,还是用一个古诗标注拼音的任务来对比下两者,之前我们在《DeepSeek-R1与O1复现的技术路线对比及R1展现出OpenAI Moment的价值探讨》中用该任务提示语对比了DeepSeek-R1和GLM-Zero-Preview的效果,总体上还是DeepSeek-R1更优。
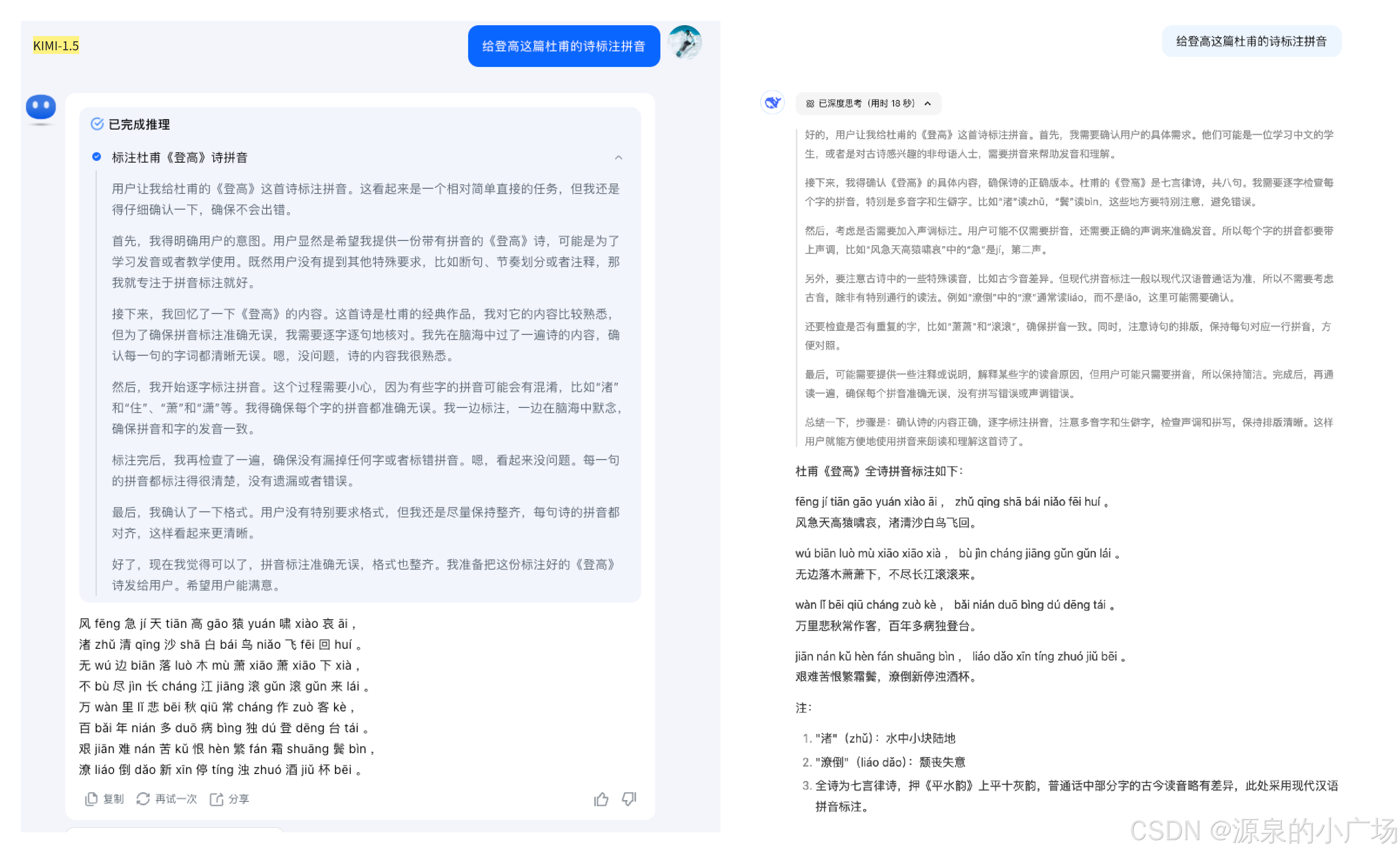
首先从结果来看,两者都正确。其次从thinking的篇幅来看,也想近,表现都还可以。结果输出的格式,deepseek稍微更符合习惯一些。能力基本打平。
1.3 技术路线对比
关于DeepSeek-R1的实现,可以参考《DeepSeek-R1:引入冷启动的强化学习》、《DeepSeek-R1-Zero之关键技术GRPO解析》、《DeepSeek-R1与O1复现的技术路线对比》。
本篇章主要分析下Kimi-1.5的实现方案。
关于k1.5的设计与训练,有以下几个关键要素。
• 长文本上下文扩展
将强化学习的上下文窗口扩展至128k,并观察到随着上下文长度的增加,性能持续提升。我们方法的一个关键理念是利用部分回放(rollouts)来提高训练效率——即通过重用之前轨迹的大部分来采样新的轨迹,避免从头生成新轨迹的成本。我们的观察确定了上下文长度是强化学习与大型语言模型持续扩展的关键维度。
• 改进的策略优化
推导出一种结合长推理链(CoT)的强化学习公式,并采用在线镜像下降的一种变体进行稳健的策略优化。通过有效的采样策略、长度惩罚以及数据配方的优化,该算法得到了进一步改进。
• 简洁的框架
长文本上下文扩展与改进的策略优化方法相结合,为使用大型语言模型进行学习建立了一个简洁的强化学习框架。由于能够扩展上下文长度,所学到的推理链展现出规划、反思和纠错的特性。上下文长度的增加相当于增加了搜索步骤的数量。
因此,k1.5也证明了无需依赖蒙特卡洛树搜索、价值函数和过程奖励模型等更复杂的技术,能实现强大的性能。
• 多模态
初次之外,模型在文本和视觉数据上进行联合训练,具备对这两种模态进行联合推理的能力。
k1.5还提出了有效的从长到短(long2short)方法,这些方法利用长推理链技术来改进短推理链模型。具体而言,该方法包括对长推理链激活应用长度惩罚以及模型合并。
在k1.5论文中,提到长 CoT 监督微调。kimi利用 RL 提示集,通过提示工程构建了一个小型但高质量的长 CoT 预热数据集,包含针对文本和图像输入的准确验证推理路径。这种方法类似于拒绝采样(RS),但侧重于通过提示工程生成长 CoT 推理路径。所得的预热数据集用于封装人类推理的关键认知过程,如规划(模型在执行前系统地概述步骤)、评估(对中间步骤进行批判性评估)、反思(使模型重新考虑和完善其方法)和探索(鼓励考虑替代解决方案)。通过对该预热数据集进行轻量级 SFT,可以有效地使模型内化这些推理策略。结果,微调后的长 CoT 模型在生成更详细和逻辑连贯的响应方面表现出改进的能力,从而提高了其在多样化推理任务中的性能。
这个过程极其类似DeepSeek-R1的cold-start过程。从两篇对轮对比来看,有很多相似的地方,甚至我都一度怀疑他们中部分同学私底下有技术交流。
并且Kimi提到对于RL中的奖励设计,对于可验证的问题,奖励直接由预定义的标准或规则确定。例如,在编程问题中,评估答案是否通过了测试用例。对于具有自由形式真值的问题,训练一个奖励模型 r(x,y,y∗) 来预测答案是否与真值匹配。给定一个问题 x,模型 πθ 通过采样过程 z∼πθ(⋅∣x),y∼πθ(⋅∣x,z) 生成 CoT 和最终答案。生成的 CoT 的质量通过其是否能导致正确的最终答案来评估。这也非常类似DeepSeek-R1中的Reward设计。两家公司的实现有异曲同工之妙,可以参考着来看。两篇文章都是同一天发表的,只能说很巧合。
2. Long2short: Context Compression for Short-CoT Models
这个是kimi1.5中提出的技术,非常有意思。尽管长推理链(Long-CoT)模型能够实现强大的性能,但其在测试时消耗的token数量相比标准的短 CoT 大型语言模型(LLM)更多。那么是否有可能将长 CoT 模型的思维先验转移到短 CoT 模型中,从而即使在测试时token预算有限的情况下也能提升性能。针对long2short问题,kimi提出了几种方法,包括模型合并、最短拒绝采样、DPO以及long2short强化学习(RL)。
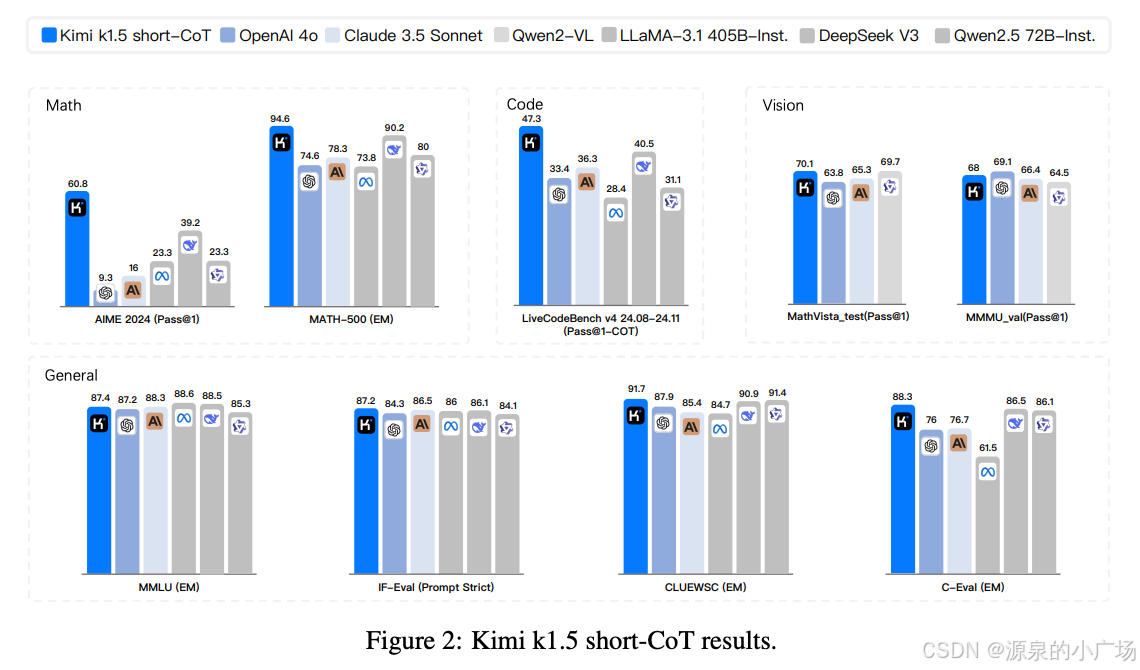
以下是这些方法的详细描述:
模型合并
模型合并已被证明在保持泛化能力方面非常有用。当合并一个长 CoT 模型和一个短 CoT 模型时,它在提高token效率方面也非常有效。这种方法通过将一个长 CoT 模型与一个较短的模型合并,从而在无需训练的情况下获得一个新的模型。具体而言,通过简单地平均两个模型的权重来实现合并。
最短拒绝采样
对于同一个问题,模型生成的响应长度存在较大差异。基于这一点,设计最短拒绝采样方法。该方法对同一个问题进行 n 次采样(在实验中,n = 8),并选择最短的正确响应用于监督微调。
DPO
与最短拒绝采样类似,利用长 CoT 模型生成多个响应样本。最短的正确解决方案被选为正样本,而较长的响应(包括错误的较长响应和比选定的正样本长 1.5 倍的正确较长响应)被视为负样本。这些正负样本对构成了用于 DPO 训练的成对偏好数据。
long2short强化学习
在标准的强化学习训练阶段之后,选择一个在性能和token效率之间提供最佳平衡的模型作为基础模型,并进行一个独立的long2short RL 训练阶段。在这一第二阶段,应用长度惩罚,并显著缩短了最大展开长度,以进一步惩罚超出预期长度但可能正确的响应。
3. 参考材料
【1】KIMI K1.5: SCALING REINFORCEMENT LEARNING WITH LLMS
【2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning



















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











