







1. 背景
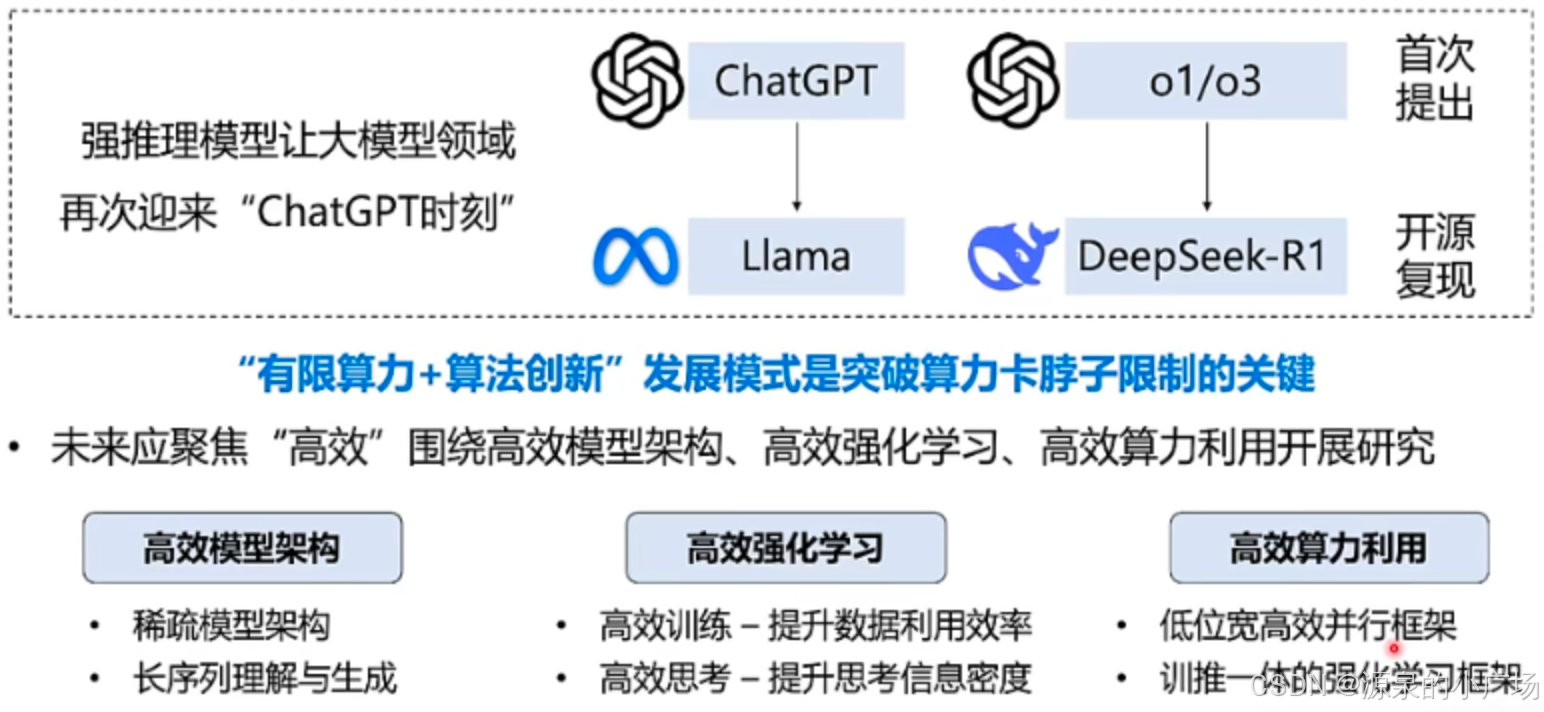
DeepSeek-R1的热度持续不减,近期也和身边很多大模型从业者做了交流,应该说这一次DeepSeek带来的影响是巨大的。很多大模型应用公司都开始切换到DeepSeek的API,所以说大模型公司技术一旦不是最领先,那就很有可能被淘汰。大模型行业应该说是当下技术最卷的行业。
当然DeepSeek(后续简称DS)之所以获得这样的成绩,可能也和该公司的定位有一定的关系。DS从一开始就决定不做垂直领域模型、不做大模型应用,只追求AGI。所以说从公司诞生,就把所有资源投入到基础AGI的研究中。
大模型行业一般还是技术为王,没有所谓的大厂非大厂的桎梏,比如OpenAI的chatgpt推出,直接证明了非大厂的顶尖技术团队,可以做出世界级的AI产品,反而大厂在技术上落后很多。这一次,DeepSeek(仅150人左右团队)同样带来了OpenAI时刻,虽然说o1是OpenAI率先推出,但因其未开源,也没有透露技术实现细节,并且也不公开thinking过程,所以大家对与o1只能是猜测。而DeepSeek仅使用强化学习就实现了效果接近o1,并且开源了其技术实现,这给大模型业界带来的价值不亚于当初LLama的开源。
【1】给出了DS的技术意义探讨,还是很赞同的。所以说非OpenAI的公司,如果技术上有突破,其实还是以开源的模式可能带来的影响力更大。
2. 从o1的可能实现角度来看大模型中的强化学习
【2,3】讨论了o1的可能技术方案。相对系统的阐述了涉及的技术要点,这里对最核心的部分做一些总结。
2.1 大模型场景下的强化学习
在大模型场景,大模型其实就充当了Agent的角色,action则是predict next token。其中核心的关键点主要有四个:策略初始化、奖励设计、搜索、学习。
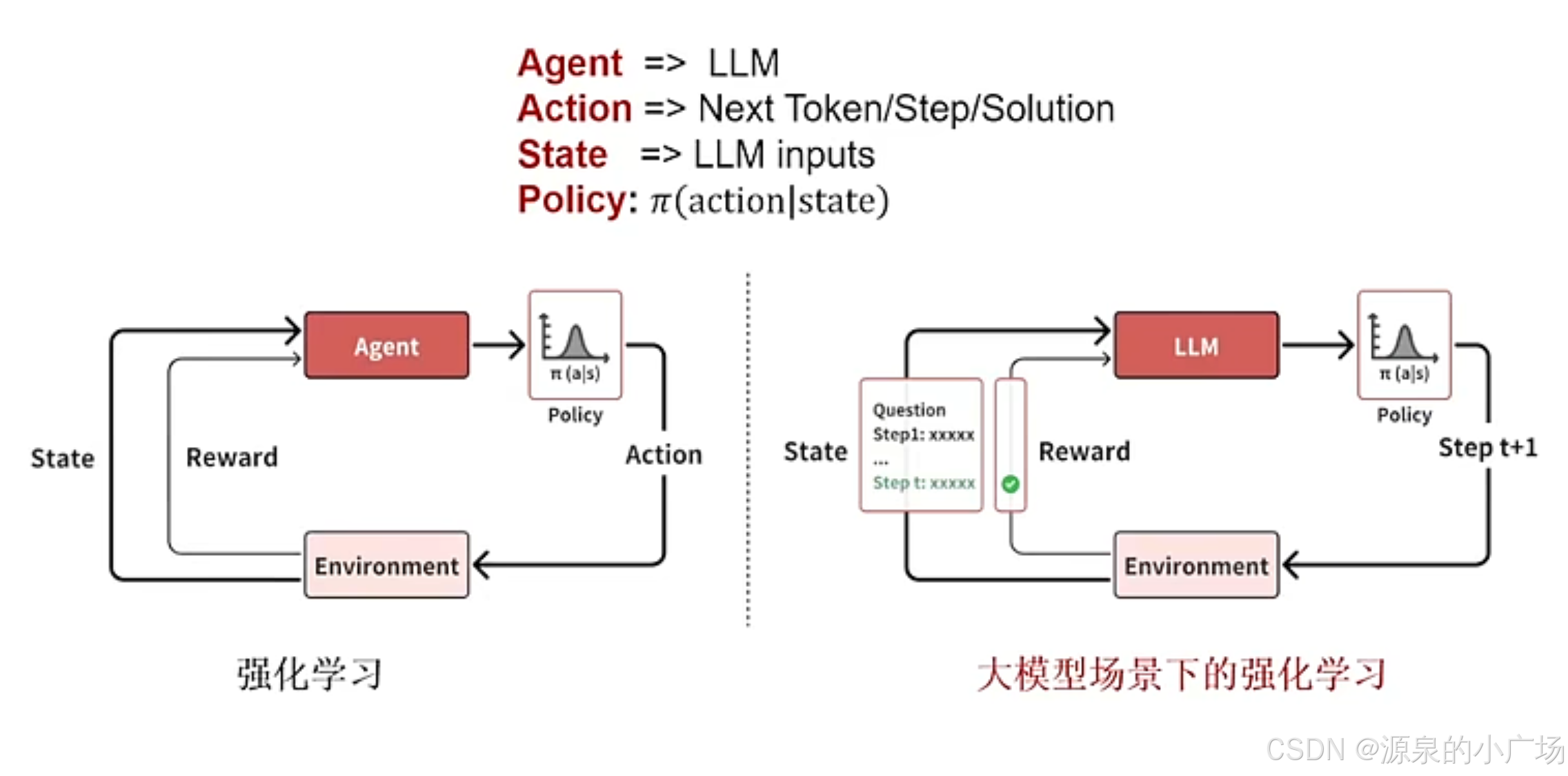
2.2 策略初始化
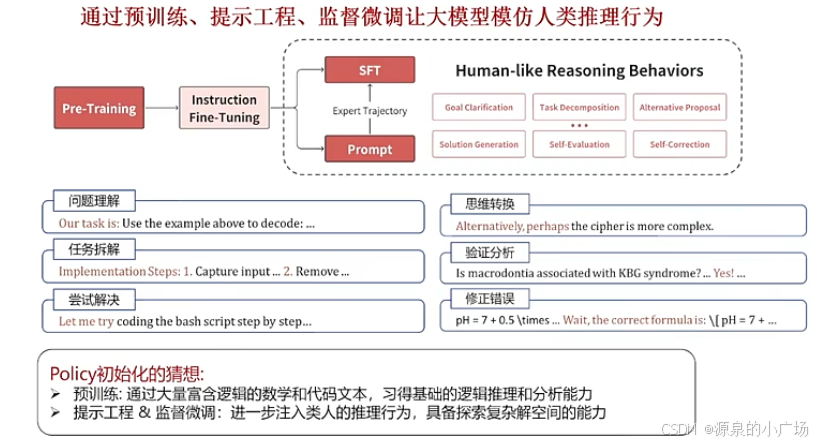
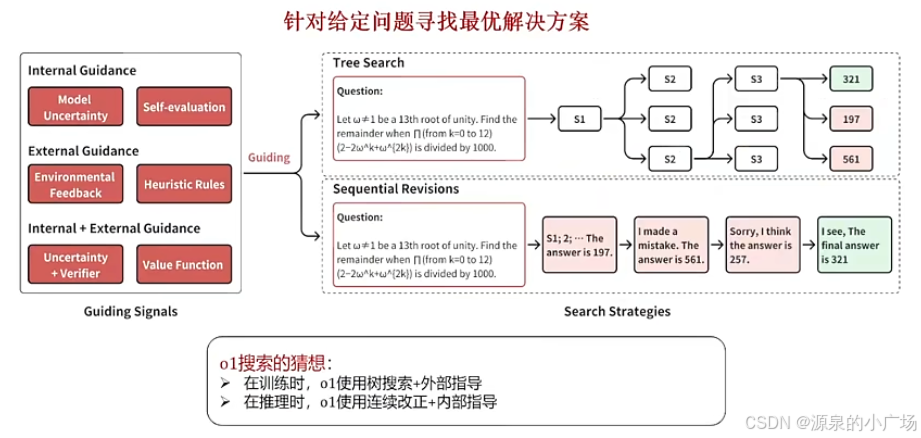
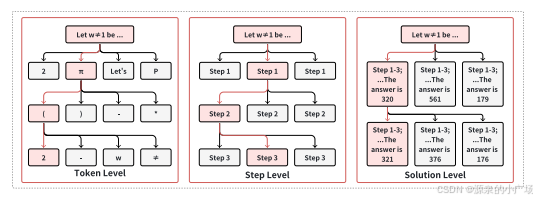
在强化学习中,策略定义了Agent如何根据环境状态选择行动。大模型在三个粒度级别上操作:解决方案级别、步骤级别和token级别。解决方案级别的行动代表最粗的粒度,将整个解决方案视为单一行动。步骤级别的行动在中间粒度上操作,其中单个步骤作为离散行动。token级别的行动提供最细的粒度,将每个单独的token视为行动。以token级别行动为例,行动空间包含词汇表中的数千个token,建立有效的初始化策略对于有效模型性能很重要。
如下图所示,大模型的初始化过程包括两个主要阶段:预训练和指令微调。在预训练期间,模型通过在大规模网络语料库上的自监督学习发展基本的语言理解,遵循计算资源与性能之间已建立的幂律关系。指令微调随后将大模型从简单的下一个token预测转变为生成与人类对齐的响应。对于像o1这样的模型,融入人类般的推理行为有助于更复杂地探索解决方案空间。这里总结了可以通过提示激活或通过从大模型中提炼专家轨迹学习的六种关键行为。
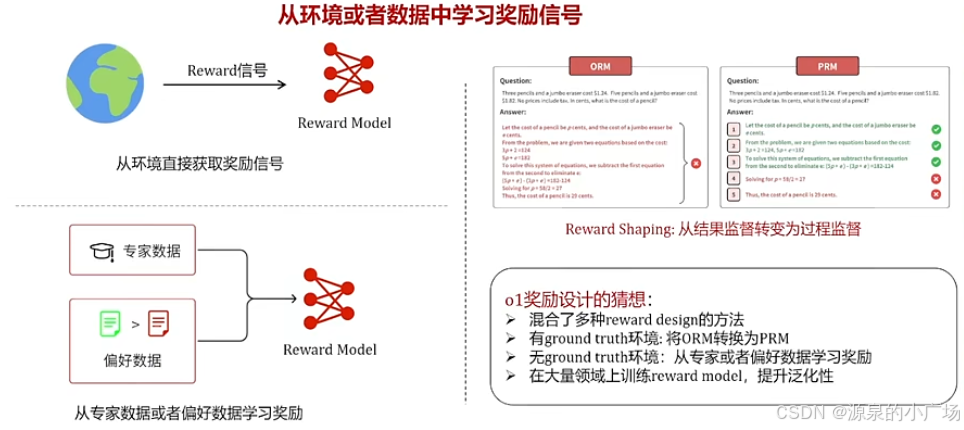
2.3 奖励设计
在强化学习中,Agent从环境接收以奖励信号形式的反馈,并通过改进其策略来寻求最大化其长期奖励。奖励函数,表示为 ,代表在时间步 t 时,Agent在状态
下采取行动
所关联的奖励。奖励信号用于指导训练和推理过程,因为它通过数值评分定义了Agent的期望行为。虽然可以从各种奖励设计中学到相同的最佳策略,但一个设计良好的奖励信号可以加速学习的收敛和搜索过程的效率。
2.4 搜索
对于大模型而言,在生成过程中进行随机采样是提高输出质量的主流方法。观察到,随着模型样本数量的增加,pass@k指标持续改善。即使是小型模型,通过利用搜索也能超越大型模型。这表明语言模型具有通过在推理期间进行更多采样来探索正确解决方案的潜力,这需要消耗更多的推理时间计算。搜索指的是通过多次尝试或基于某些指导,如奖励或启发式规则,进行探索以找到正确解决方案的过程。对于像o1这样设计用于解决复杂推理任务的模型来说,搜索可能在训练和推理过程中都扮演着重要角色。
搜索通常依赖于指导信号,因此可以被视为策略迭代的过程,称之为搜索策略。与简单采样相比,搜索策略通常更有可能找到更好的解决方案。由搜索策略生成的解决方案可以直接用作最终输出,或融入训练算法中,如专家迭代,以迭代改进策略。
从强化学习角度看o1的路线图。在训练阶段,在线强化学习中的试错过程也可以被视为一种搜索过程,其中Agent基于自身策略进行简单采样并学习产生高奖励的解决方案。然而,由于o1涉及更长的推理长度并包含类似人类的推理行为,搜索空间变得庞大,简单采样可能变得低效。因此,需要一些先进的搜索策略来更高效地探索更好的解决方案,并使用它们作为训练数据来更新策略模型。这个过程可以在训练期间迭代进行。在推理阶段,o1表明通过在推理时增加计算量,花费更多时间思考,可以持续提高模型性能。o1的这种更多思考方式可以被视为一种搜索,使用更多的推理时间计算来找到更好的答案。
搜索的两个关键方面是搜索的指导信号和获取候选解决方案的搜索策略。搜索策略用于获取候选解决方案或行动,而指导信号用于进行选择。指导信号分为内部和外部指导。搜索策略分为树搜索和顺序修订。这两个分类维度是正交的,例如,树搜索方法可以利用内部或外部指导信号。
2.5 强化学习
训练数据是无限的,这些数据来自与环境的互动。相比之下,人类专家数据是有限的且成本高昂。强化学习有潜力实现超越人类的性能,因为它从试错中学习,而不是从人类专家数据中学习。虽然人类专家数据捕捉了人类的行为和知识,但强化学习可以导致发现人类可能无法实现的策略。
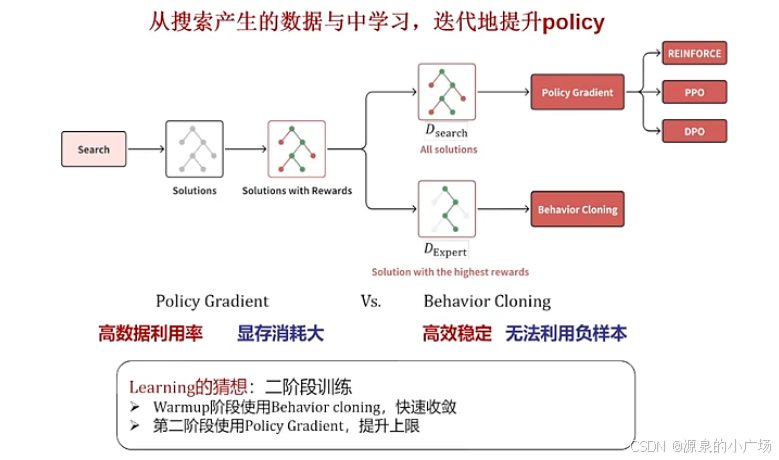
强化学习通常通过策略对轨迹进行采样,并根据接收到的奖励来改进策略。在o1的背景下,假设强化学习过程通过搜索算法生成轨迹,而不是单纯依赖采样。搜索方法的一个优势是,与随机采样相比,能够探索更优的状态或解决方案。例如,束搜索优先考虑具有最高预期行动价值的行动。因此,搜索技术可以提供比简单采样更高质量的训练数据。在这个假设下,o1的强化学习可能涉及搜索和学习的迭代过程。在每次迭代中,学习阶段利用搜索生成的输出作为训练数据来增强策略,而改进后的策略随后应用于下一轮的搜索过程。
训练时搜索与测试时搜索不同。测试时搜索在所有候选解决方案中输出具有最大奖励或置信度的解决方案。但在训练时,搜索生成的所有候选解决方案都可能被学习利用。将从搜索输出的状态-行动对集合表示为Dsearch,将搜索得到的最佳解决方案中的状态-行动对集合表示为Dexpert。因此,Dexpert是Dsearch的子集。下图可视化展示了Dsearch和Dexpert之间的差异。
3. DeepSeek的技术路线
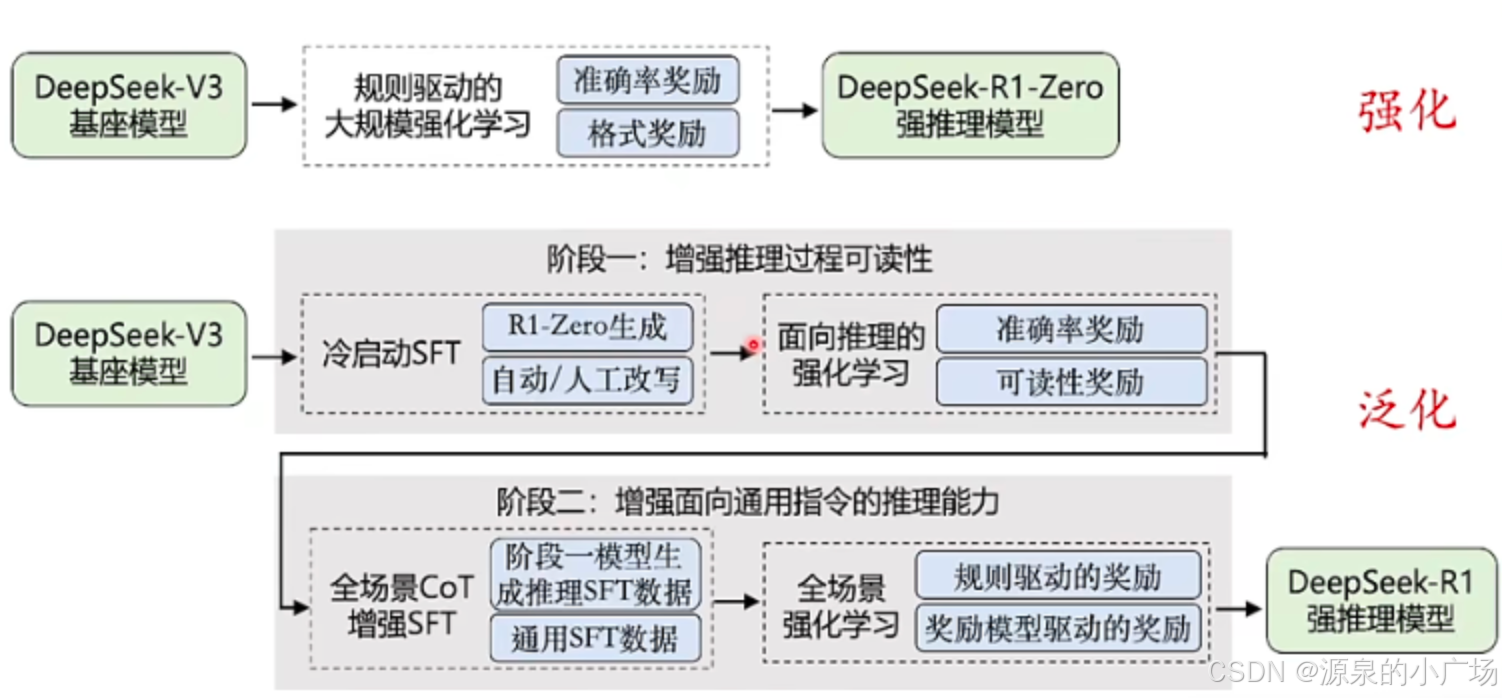
我们在《最近大火的DeepSeek-R1初探(原理及使用)》、《DeepSeek-R1-Zero之关键技术GRPO解析》、《DeepSeek-R1:引入冷启动的强化学习》三篇文章中讨论了部分DeepSeek-R1的技术实现点。下图从强化、泛化两个角度,提出DeepSeek这一轮模型的价值,不仅仅局限在数学、代码等,还可以提升文字写作等能力。
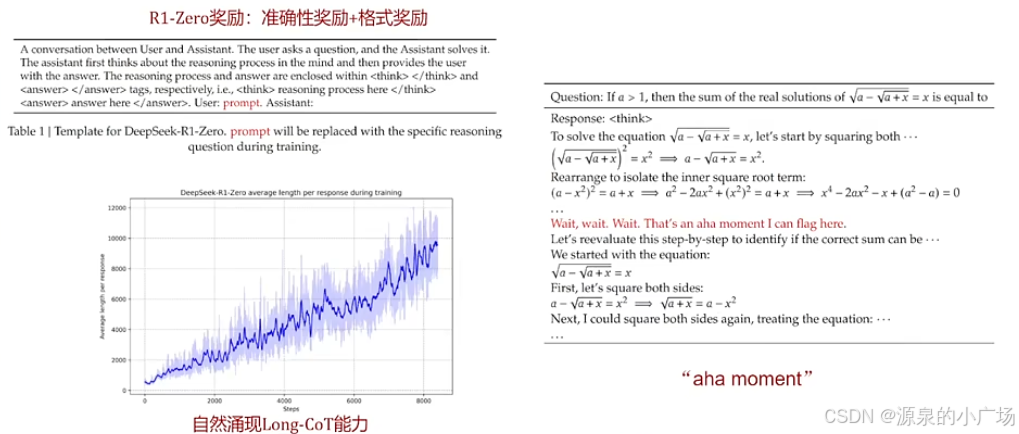
在R1论文中,有一张图非常有意思,也非常关键,如下所示,通过引入强化学习,R1-ZERO(纯RL驱动的推理模型)涌现出Long-CoT的能力,之前我们都是需要手动设计一些多步推理的引导提示语,随着Long-CoT能力的涌现,也许以后prompt也不需要人类干预了。不得不说,大模型技术发展实在太快了,前段时间还在讨论基于专家prompt进行创业的想法。
 【4】可视化展示了DeepSeek-R1-Zero、DeepSeek-R1-Distill、DeepSeek-R1三种模型的训练pipeline。接下里我们再详细描述下R1的训练过程,【3】也给出了一些启发,这里也做一下分享。
【4】可视化展示了DeepSeek-R1-Zero、DeepSeek-R1-Distill、DeepSeek-R1三种模型的训练pipeline。接下里我们再详细描述下R1的训练过程,【3】也给出了一些启发,这里也做一下分享。
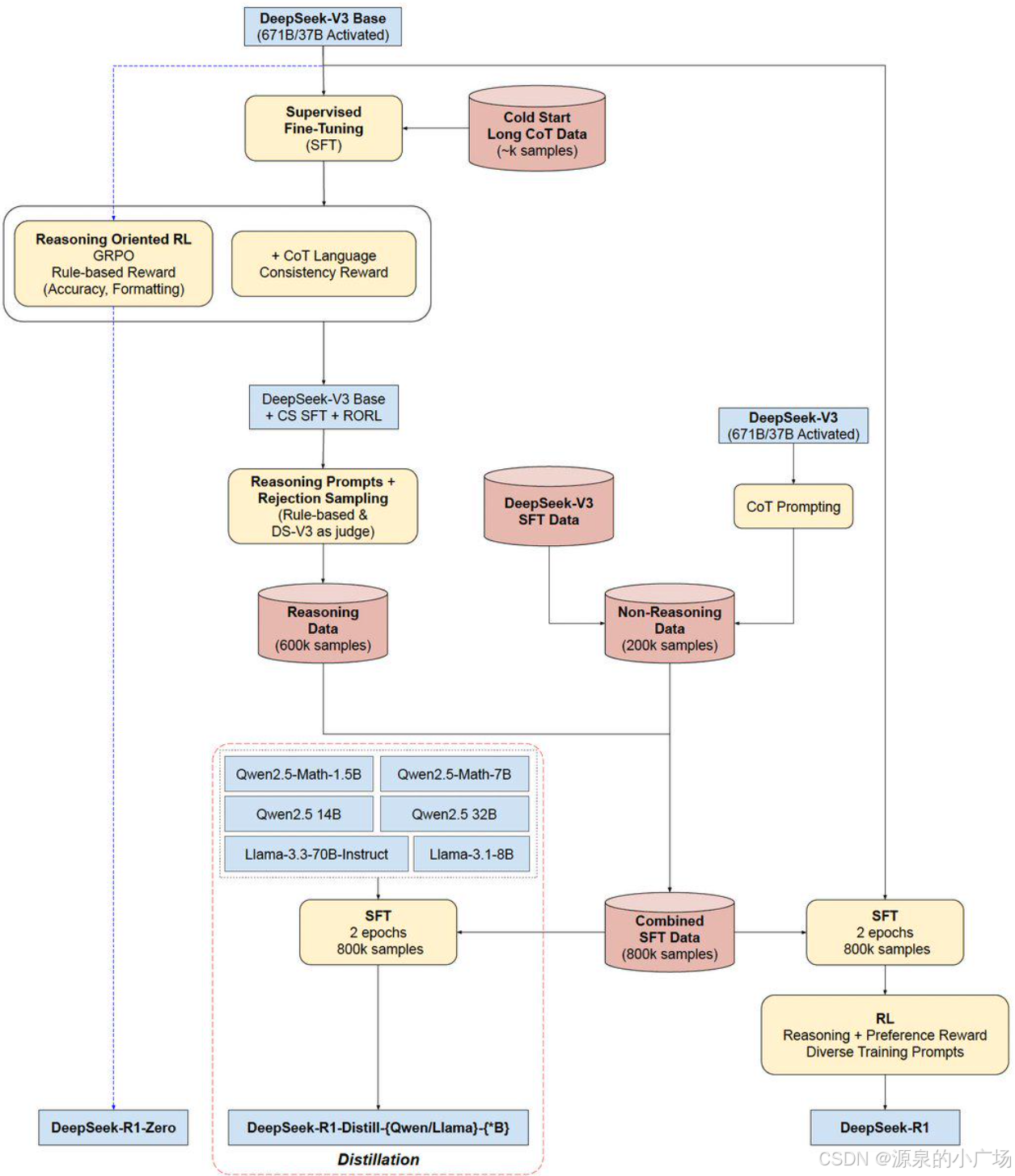
R1的训练由四个阶段组成:
冷启动
构建并收集少量Long-CoT数据来微调模型,防止RL训练早期不稳定和可读性差问题。
推理导向的强化学习
以DeepSeek-V3为基础,针对编码、数学、科学和逻辑推理等推理密集型任务,采用与R1-Zero相同的大规模RL来进行训练。为了缓解语言混杂的问题, 引入语言一致性奖励(CoT中目
标语言单词的比例)。
拒绝抽样和监督微调
第一阶段模型的抽样,结合其他领域的SFT数据,增强模型在写作、角色扮演和其他通用任务中的能力。适用于所有场景的强化学习
以DeepSeek-V3为基础,提高模型的有用性和无害性,同时完善其推理能力。
对于推理任务,利用基于规则的奖励来指导。
对于一般任务,采用奖励模型来对齐人类偏好。
4. R1与O1复现技术路线对比讨论
4.1 实现路线差异及后续可能的方向
R1/R1-zero的技术路线和社区对o1复现存在差异,社区对o1的复现基本都会涉及到蒸馏和搜索。而R1-Zero没有SFT,没有过程监督,没有搜索,也能训练出类似o1的效果。
之前有尝试再小模型上仅仅基于强化学习,没有获得足够的预期效果,说明只有基模型足够强, RL才能取得较好的效果。R1强调MCTS没有效果,但是简单的majority vote能大幅提升R1的效果,说明搜索仍然是重要的。也许下一篇R2论文中就会出现引入搜索之后的能力提升。
这里也给一下DeepSeek-V3模型的参数说明:
DeepSeek V3模型参数:
671B参数(GPT-3:175B、GPT-4:1.76T?)
每个token激活37B参数、~5.5%
61层Transformer、Hidden dimension : 7168
FFN→MoE:1共享专家(sharedexpert)+256路由专家(routed experts)
每个token激活8个路由专家
4.2 策略初始化
R1-zero是一个比较好的尝试,不依赖SFT。但是R1是用到了SFT,也就是冷启动阶段,大概几千条,之后再进行GRPO,这么看,少量训练用于SFT可能还是必须的,有一些指导性信息,不至于一开始就让模型自己胡乱探索方向。所以必要的方向指引能够让模型后续训练更符合预期,也能加速收敛。
4.3 奖励模型
R1的奖励设计跟普通的后训练没特别大的区别,有ground truth用ground truth做EM,否则用RM。为了方便理解,这里对概念做一些介绍。
RM (Reward Model) 和 EM (Expectation Maximization):
RM (Reward Model):通常指的是用于训练强化学习模型中的奖励模型。奖励模型是指一个系统,它会根据模型输出的行为给出一个“奖励”分数,用于指导模型学习。简单来说,RM 是在强化学习框架下,评估行为好坏的“反馈机制”,也可以理解为训练过程中的一部分,用于优化模型的行为。
EM (Expectation Maximization):通常是指一种统计推断方法,用于寻找包含潜在变量的概率模型的参数估计。在这个背景下,EM 表示一种用“已知标签(ground truth)”的训练方式,即在训练过程中直接使用真实数据来调整模型的参数,从而最大化似然估计。
4.4 写作能力提升
相较于4o,O1在写作等任务上的提升幅度并不显著,然而R1的创作却常常给人带来耳目一新的感觉。这可能是由于强基模型在经过Scale RL后所涌现出的新能力所致,也有观点认为,这是因为R1在安全对齐方面做得相对较少,从而没有过多地限制模型的创作潜力。此外R1在一些通用领域任务上的推理效果还并不理想,强化学习的训练并不能保证泛化。
5. DeepSeek-R1与智谱GLM-Zero-Preview的对比
智谱GLM-Zero-Preview是在24年年底推出的强化推理模型【5】。首先两个模型都可以正确输出结果。但相对比来说,DeepSeek-R1简单直接,而GLM-Zero-Preview有种过度思考的感觉,核心目标不够明确,在细枝末节上思考过多。显然两种强化推理模型的训练方法存在显著差别。不过话说回来,期待国内各大模型公司百花齐放,目前离AGI还很远。
5.1 DeepSeek-R1表现

5.2 GLM-Zero-Preview表现

6. 参考材料
【1】刘知远-DeepSeek大规模强化学习技术原理与大模型技术发展研判
【2】Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











