






以下内容是对langchain团队制作的langsmith系列视频的翻译总结,原视频可在油管上查看
🌟 评估介绍及其在LangSmith中的应用 🌟
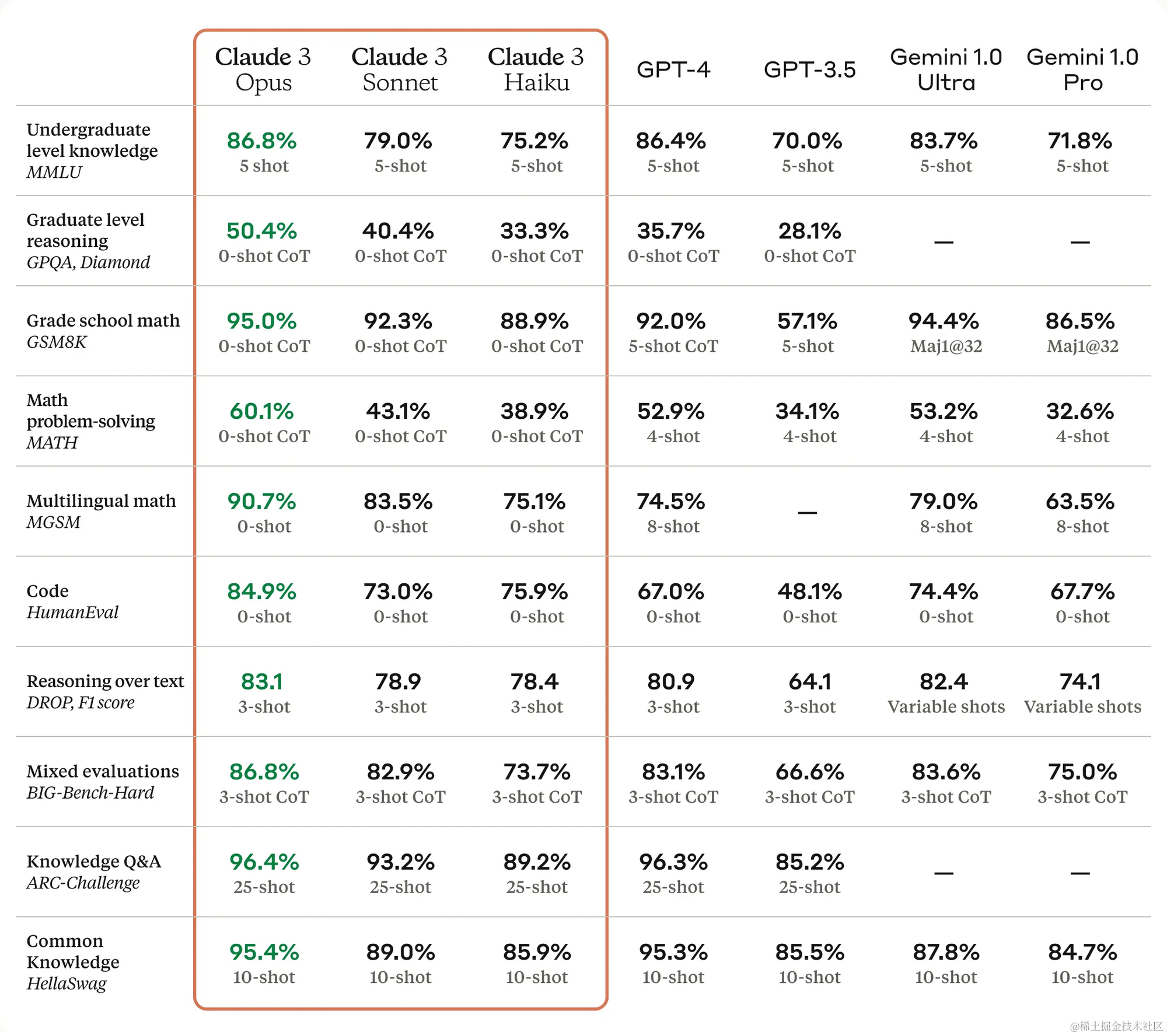
近几周和几个月以来,我们注意到用户们对评估表现出了高度的兴趣。因此,我们想开启一个简短的系列,阐述如何从零开始思考评估,并如何通过使用LangSmith自行实施评估。当像Cloud3这样的新模型发布时,你经常会看到许多公开的评估报告。例如,这是Claude 3展示了各种不同的评估结果,并将它们与其他流行的LLMs进行了比较。
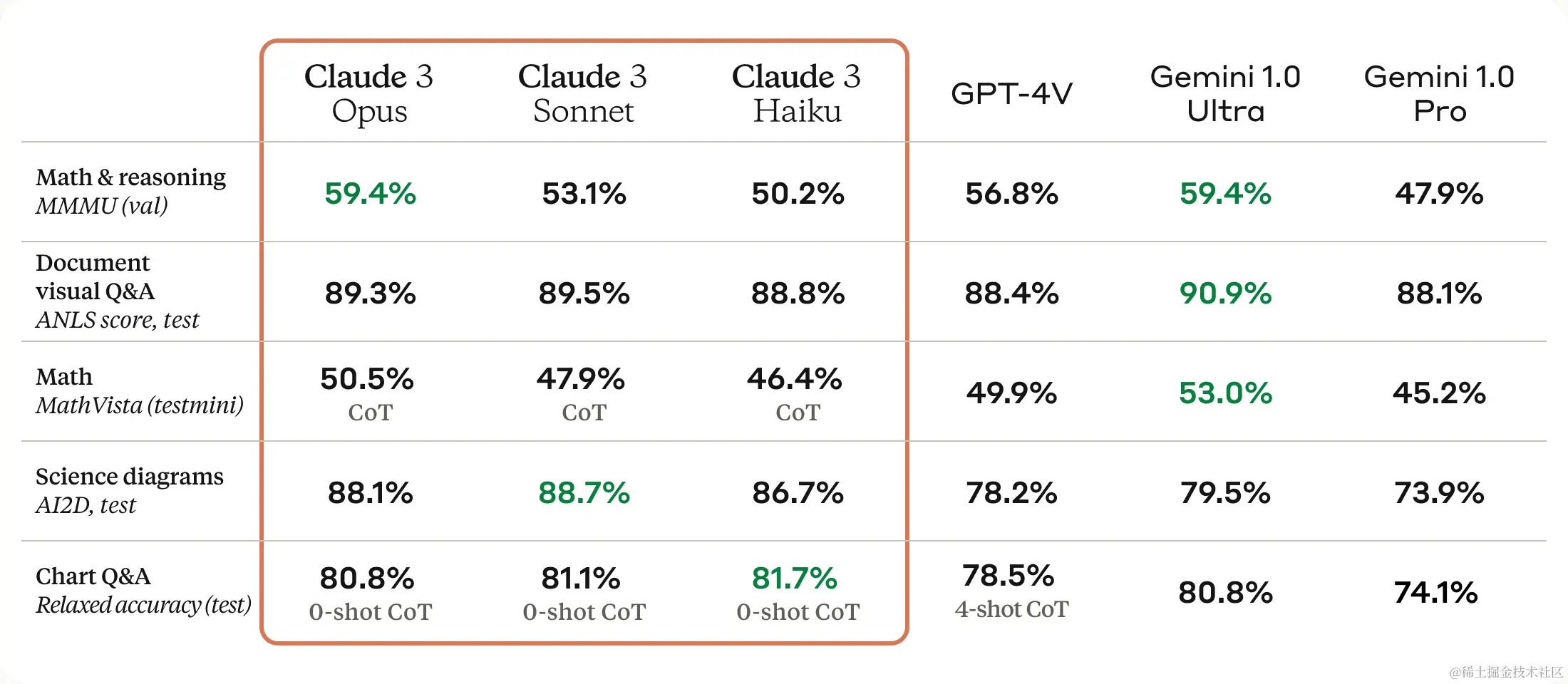
你也可能见过像Chatbot arena这样的平台,现在它的榜首是Cloud3 opus。
但问题在于,这些评估是什么,应该如何思考它们,我又该如何自行实施它们呢?
🤔 如何思考评估
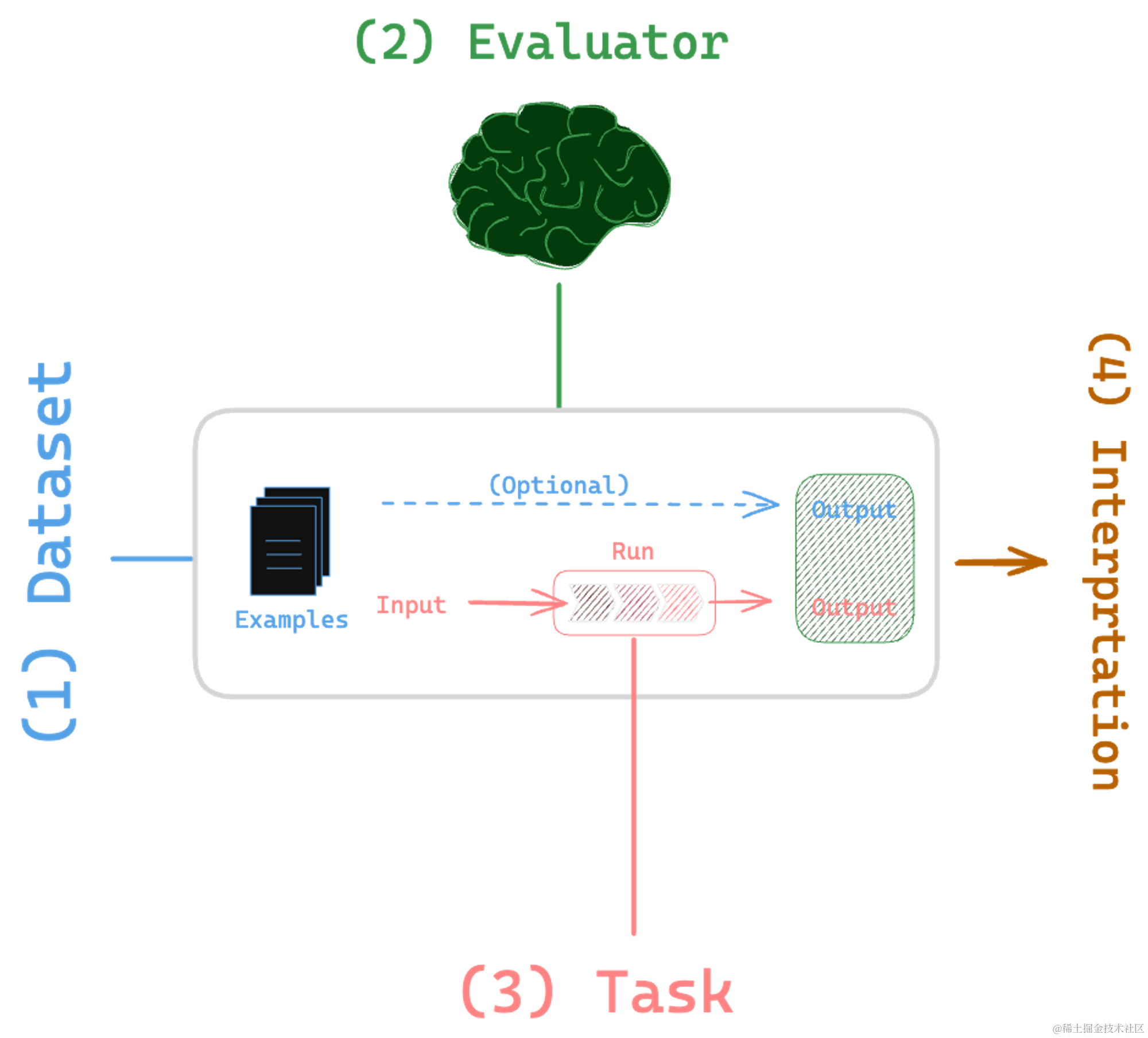
评估可以被分解为四个部分。首先,有一个数据集,其次是某种评估者,接着是一个任务,最后是解释结果的手段。让我们通过观察一下在这些公共模型上运行的各种评估来具体了解。
📈 OpenAI的一个好例子-“标准答案”(Ground Truth)
- 2021年,OpenAI发布了一个包含165个编程问题的数据集,主要与Code generation任务相关。评估方法在这里可以从两个角度来看:评判者和评估方式。在这个例子中,评估方式是以每个编码问题的“正确答案”为基准的,通过某种程序化的方式(如单元测试)来指定正确性。结果通常以条形图的形式报告。
🤖 Chatbot Arena的比较实例-“人工评估”(Human Eval)
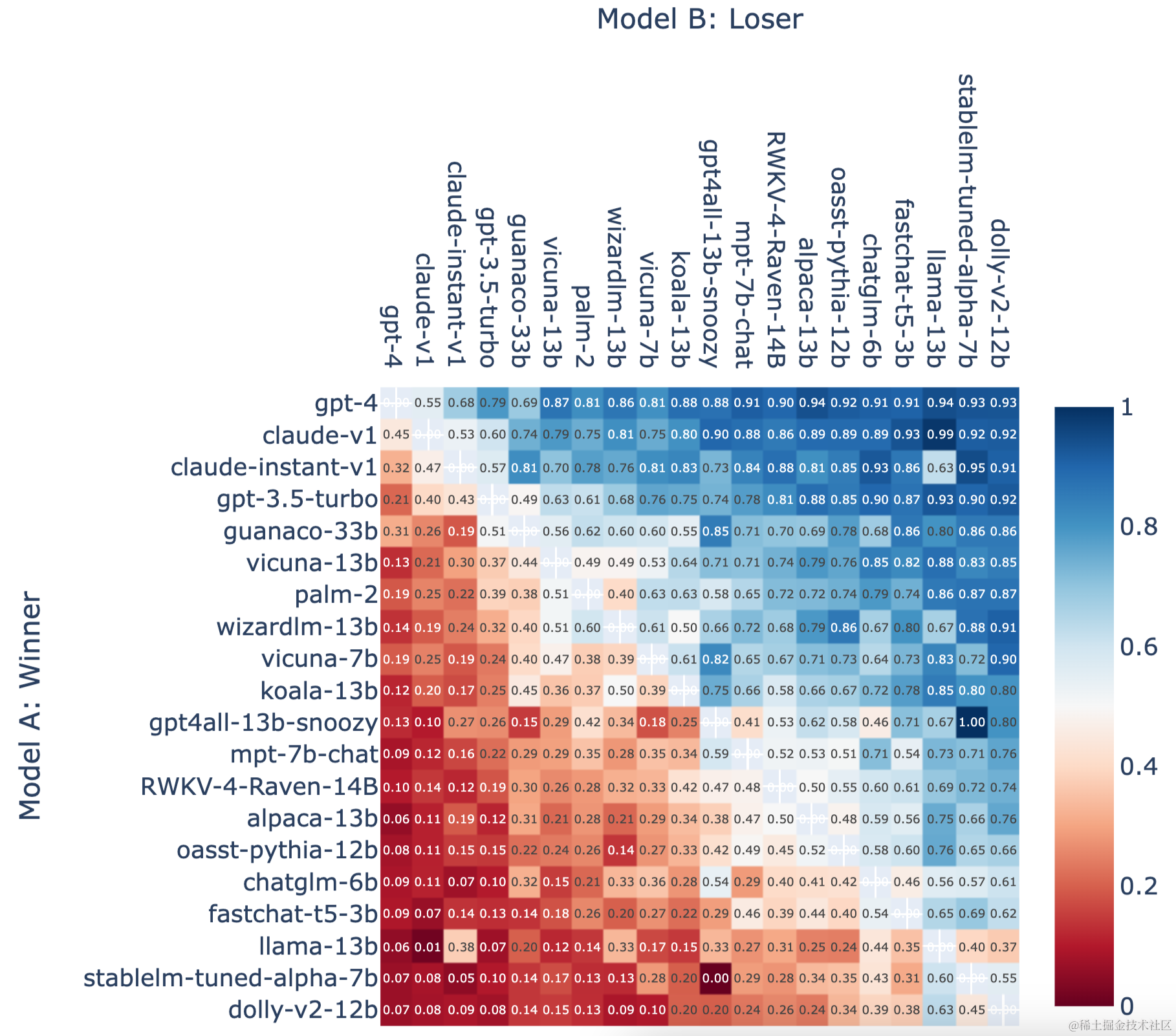
- 在Chatbot Arena的案例中,实际上没有静态数据集。这是通过用户互动动态生成的。用户被呈现两个不同的LLMs,他们对两者都进行提示,并选择他们更喜欢的响应。在这种情况下,评判者是人类,而评估模式不是基于固定真理的,而是比较性评估。在指标方面,他们经常报告这些对比图,基本上展示了一个模型与所有其他模型的比较,并且统计数据告诉你一个模型打败另一个模型的可能性。
🛠 构建个性化测试和评估
我们看到了对个性化测试和评估的兴趣。例如,尽管有数百种公共基准,人们还是想要构建自己的基准来测试模型。在考虑数据集时,有一些类别,比如人为策划的(如人工评估)、从生产应用中收集的用户互动,以及使用LLMs合成地生成数据集。
🔍 评估的不同形式
- 在评估方面,我们看到了使用人类作为评判者的例子,使用单元测试或启发式方法针对正确的代码解决方案进行评判,以及使用LLMs作为评判者。这些评判者可以针对一般标准进行评判,考虑到没有固定的参考答案,但可以让LLM评估不同的方面,例如简洁性。
- 最后,这些通常如何被应用?可以考虑几个类别,如单元测试、评估和A/B测试。单元测试是软件工程中常规和简单的功能断言。A/B测试是一种比较性评估,回归测试则关注随时间的变化或实验性测试评估不同的参数。
🚀 如何开始 - 引入LangSmith
LangSmith提供了UI和SDK来构建数据集、版本管理、编辑以及定义你自己的评估者或实现/使用自定义评估者。
我们将在接下来的视频中详细讨论这些概念,让你从零开始掌握构建自己的评估方法。重要的是,LangSmith并不要求使用LangChain,但当然,你也可以将其与LangChain配合使用。
在接下来的视频中,我们将仔细研究每个部分,逐步建立从头开始构建自己的评估的理解。感谢大家观看!

















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









