






以下内容是对langchain团队制作的langsmith系列视频的翻译总结,原视频可在油管上查看
欢迎来到LangSmith实战系列的第二篇教程!我们将继续深入探讨构建和理解LangSmith的核心原理——基础组件。
在我们之前的教程中,我们介绍了如何对LLM进行评估,并探讨了构建数据集、实施评估器、应用评估和明确我们所关心任务的重要性。
这次,我们将从基础开始,一步步构建这个理解。
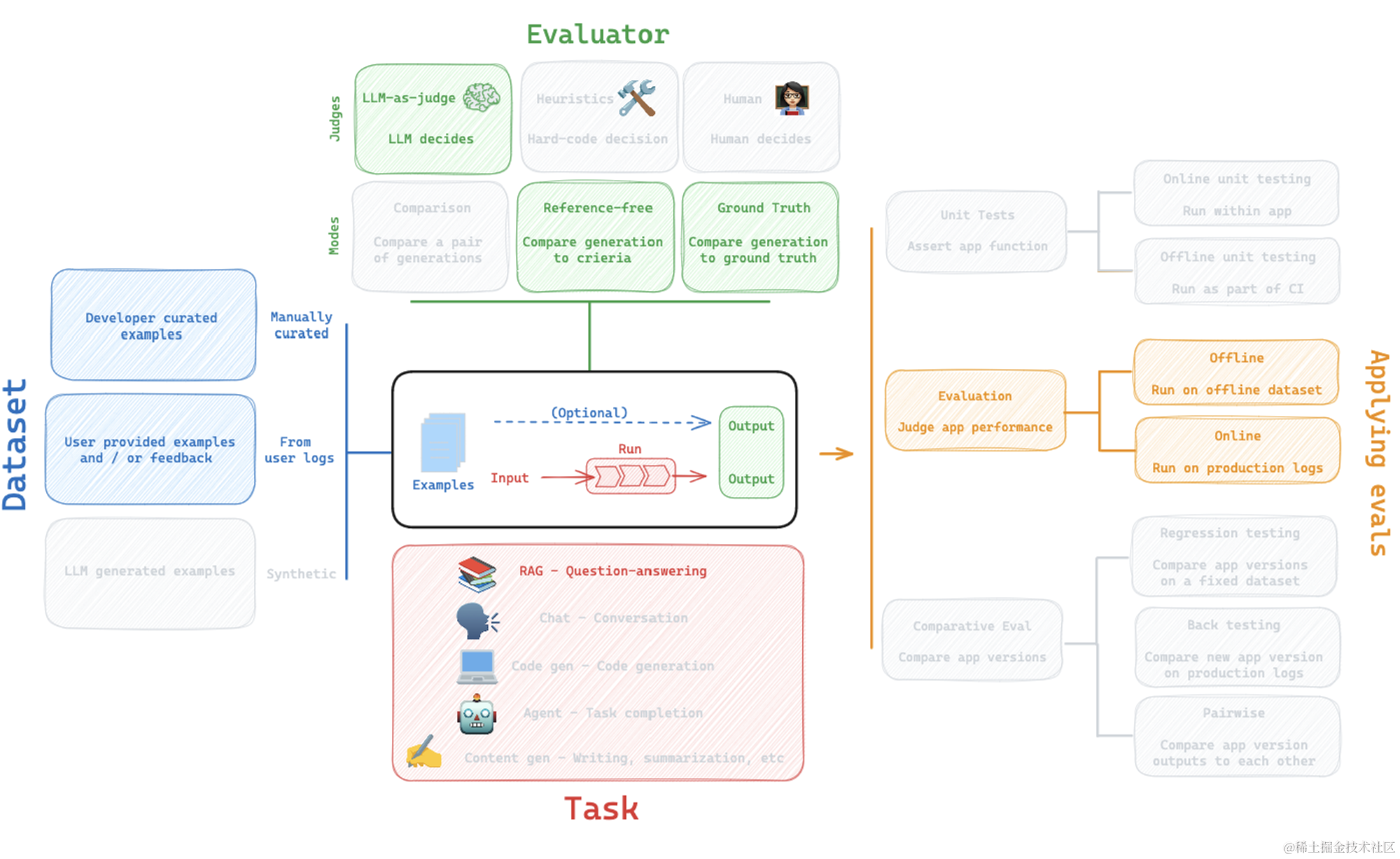
🚀 从应用到项目的旅程
假设我们正在处理一个LLM应用,如一个RAG应用,它非常适合作为一个实例。
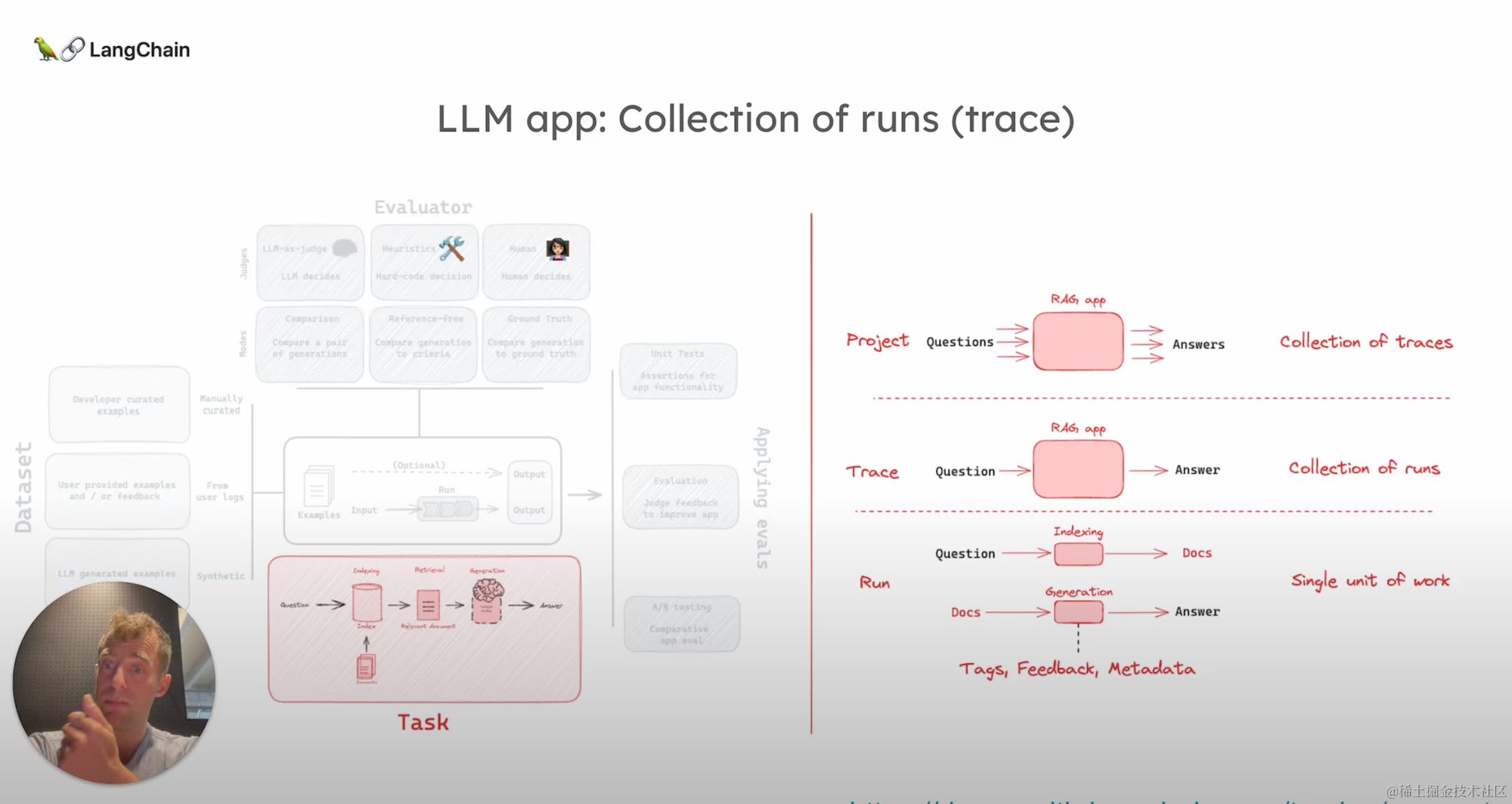
该应用通过索引或者检索,然后基于检索到的文档生成答案的过程,实现了从问题到答案的转换。
这一过程被分解为我们所称的“运行”(Run),具体到这个案例中,包括从问题到文档的运行,以及从文档到答案的运行。
运行不仅可被标记,还可以获得反馈和添加元数据。我们会在后续讨论这些高级功能。
而多个运行会被汇总成“轨迹”(Trace),一个轨迹则代表了从输入到输出的完整路径。
在RAG应用的例子中,一个轨迹会包含检索和生成的两个运行。进一步地,一个“项目”(Project)则是多个轨迹的集合,它将所有使用该应用的轨迹记录下来。
📚 数据集的构建和应用
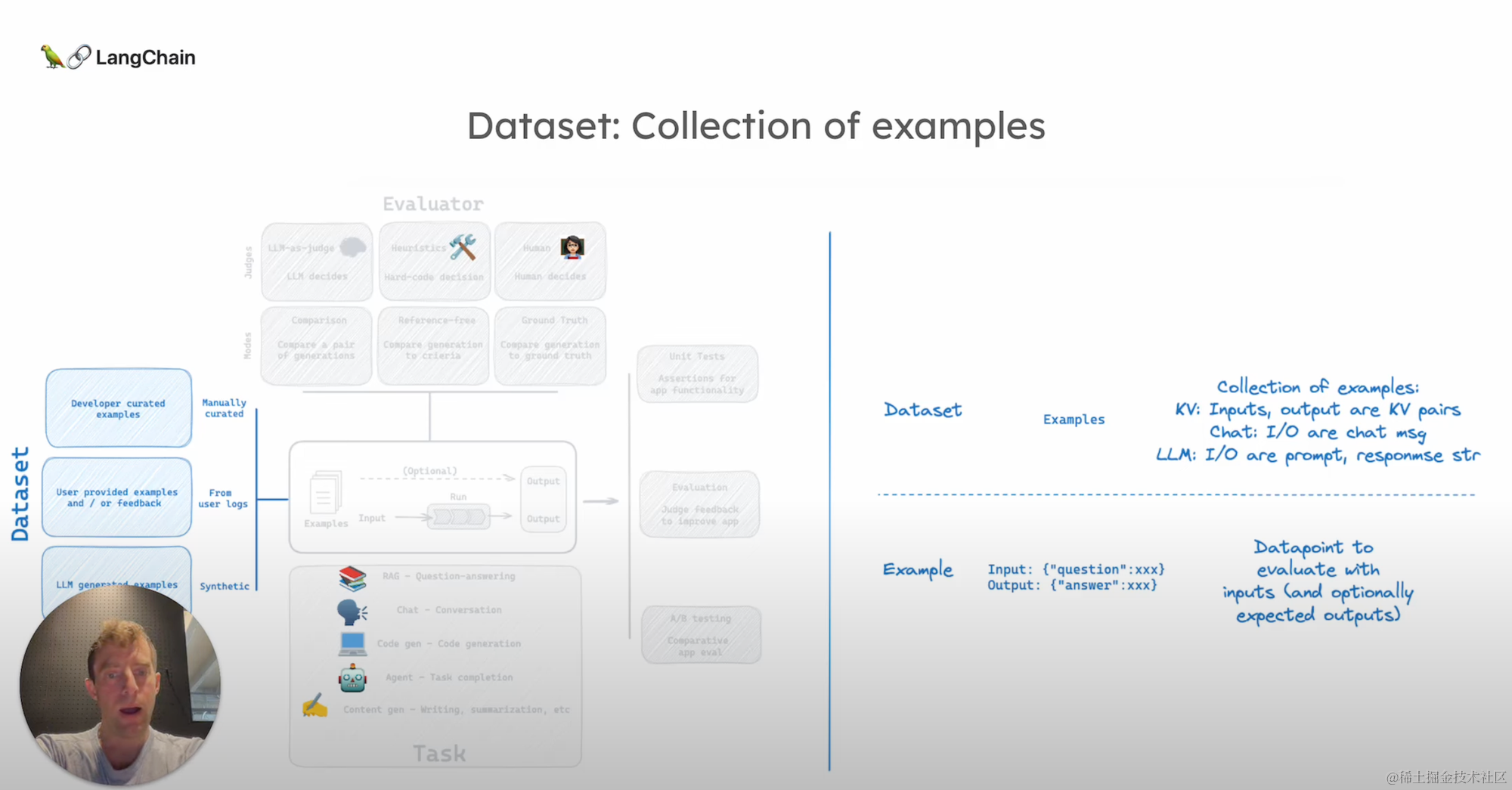
我们再看数据集,数据集可以是人工策划的、从日志中提取的,或是合成的。
原则上,一个数据集非常简单——它包含一个输入(input)以及一个可选的输出(output)。
例如,在RAG应用中,数据集可能是问题和答案对。
输入输出数据通常呈现为键值对——你的问题和对应的答案。一个数据集实际上是这样一些实例的集合。
对于特定的应用场景,如聊天大语言模型,数据集可能需要特定格式的数据,这在进行微调等操作时尤其重要。然而,对于许多应用程序来说,简单的键值对格式已经足够使用。
🤖 评估器的选择和实现
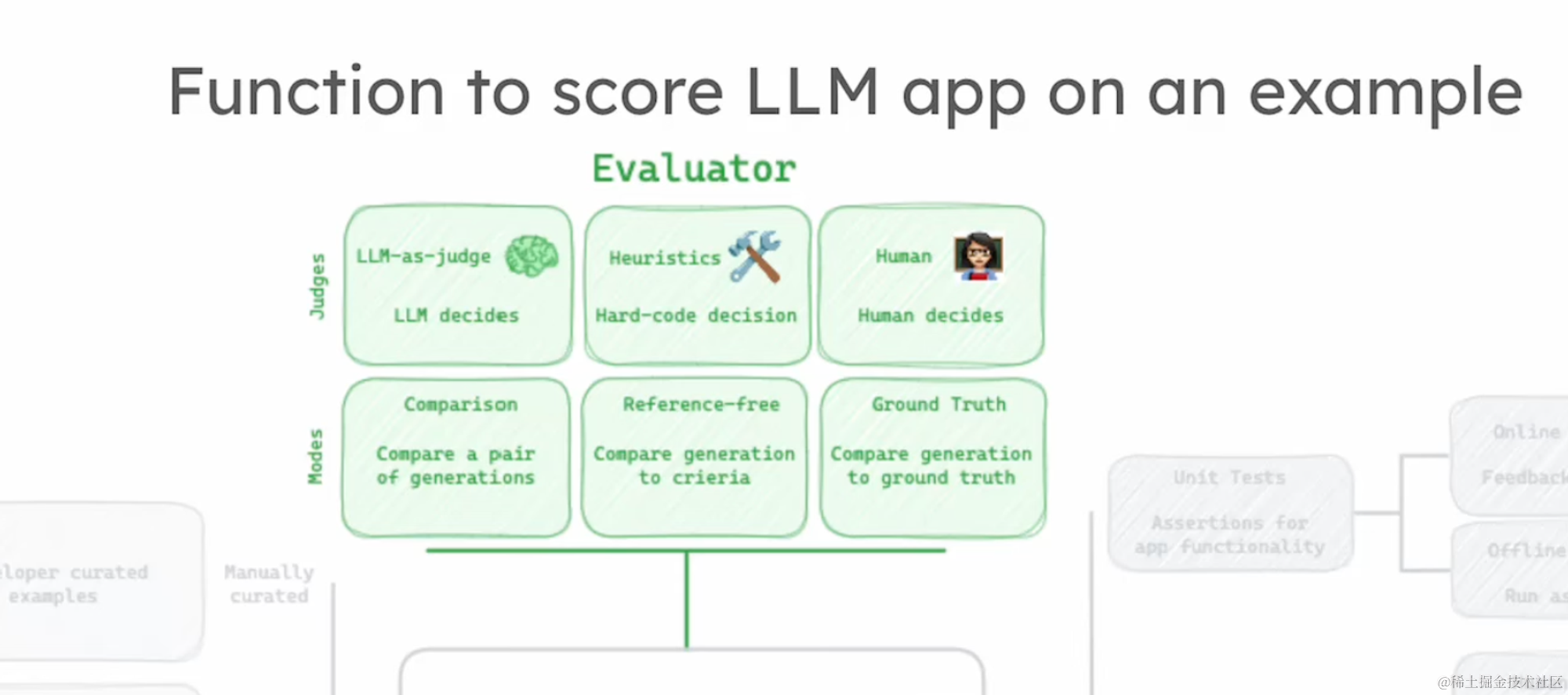
在评估方面,我们拥有多种评估器可供选择,如LLM评估器、启发式评估器、人类评估器等。
评估模式也多种多样,包括比较不同轨迹的成果、无需参考答案的自由评估等。
这一节中,我将引导大家理解如何从数据集中的实例出发,通过将输入传递给应用并产生输出,进而由评估器进行评价的整个过程。
🌟 评估机制的核心理解
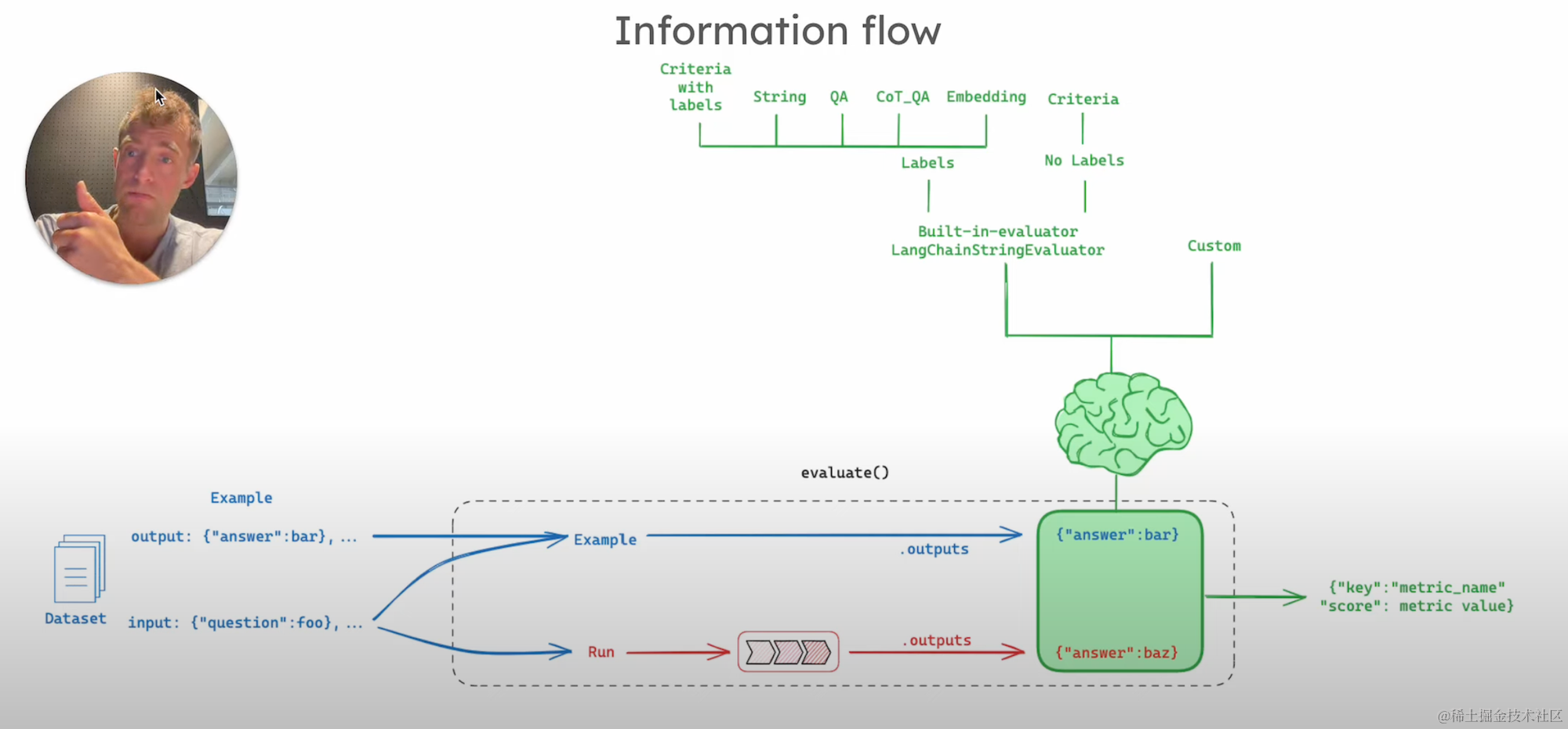
在执行评估时,我们从数据集中选取一个实例,将其输入作为应用的输入,应用处理后产生输出。
同时,数据集中实例的输出(即真实答案)也被用来进行评判。
评估器在这一过程中扮演了关键的角色,它比较应用的输出和真实答案,给出一个评分。
通过选择不同的评估器,我们可以实现对应用性能的多角度评估。
至此,我们概述了LangSmith的核心原理及其在构建应用过程中的角色和功能。
掌握了这些基础概念之后,深入理解和应用LangSmith将变得更为简单。
在下一期教程中,我们将通过更多细节和代码示例,进一步深化大家对这些概念的理解。















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









