






目录
1.微积分
拟合模型的任务分解为两个关键问题:
• 优化(optimization):⽤模型拟合观测数据的过程;
• 泛化(generalization):数学原理和实践者的智慧,能够指导我们⽣成出有效性超出⽤于训练的数据集 本⾝的模型。
1.1导数和微分
在深度学习中,我们通常选择对于 模型参数可微的损失函数。简⽽⾔之,对于每个参数,如果我们把这个参数增加或减少⼀个⽆穷⼩的量,可 以知道损失会以多快的速度增加或减少,假设我们有⼀个函数f : R → R,其输⼊和输出都是标量。如果f的导数存在,这个极限被定义为

如果f ′ (a)存在,则称f在a处是可微(differentiable)的。如果f在⼀个区间内的每个数上都是可微的,则此 函数在此区间中是可微的。我们可以将 (2.4.1)中的导数f ′ (x)解释为f(x)相对于x的瞬时(instantaneous)变 化率。所谓的瞬时变化率是基于x中的变化h,且h接近0。
导数的⼏个等价符号:给定y = f(x)
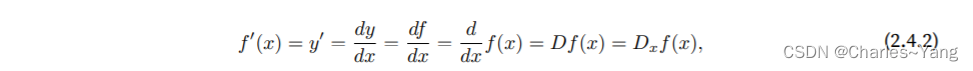
其中符号和D是微分运算符,表⽰微分操作。我们可以使⽤以下规则来对常⻅函数求微分:

一些微分求导法则:
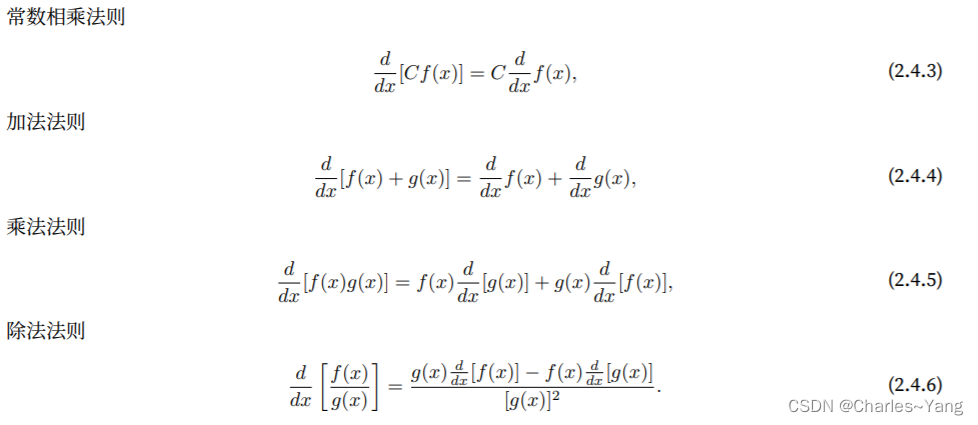
1.2偏导数
将微分的思想推⼴到多元函数(multivariate function)上。
设y = f(x1, x2, . . . , xn)是⼀个具有n个变量的函数。y关于第i个参数xi的偏导数(partial derivative)为:
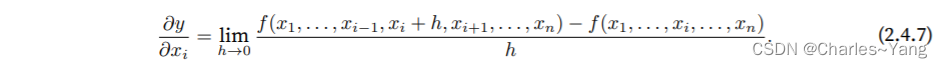
为了计算 ,我们可以简单地将x1, . . . , xi−1, xi+1, . . . , xn看作常数,并计算y关于xi的导数。对于偏导数的 表⽰,以下是等价的:

1.3梯度
我们可以连结⼀个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。具体⽽⾔,设 函数f : →
的输⼊是⼀个n维向量x = [x1, x2, . . . , xn]
,并且输出是⼀个标量。函数f(x)相对于x的梯度 是⼀个包含n个偏导数的向量:
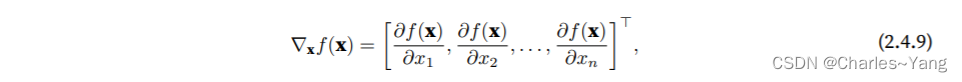
其中通常在没有歧义时被
取代。 假设x为n维向量,在微分多元函数时经常使⽤以下规则:

同样,对于任何矩阵X,都有 = 2X。正如我们之后将看到的,梯度对于设计深度学习中的优化算法 有很⼤⽤处。
1.4链式法则
然⽽,上⾯⽅法可能很难找到梯度。这是因为在深度学习中,多元函数通常是复合(composite)的,所以难 以应⽤上述任何规则来微分这些函数。幸运的是,链式法则可以被⽤来微分复合函数。
让我们先考虑单变量函数。假设函数y = f(u)和u = g(x)都是可微的,根据链式法则:

现在考虑⼀个更⼀般的场景,即函数具有任意数量的变量的情况。假设可微分函数y有变量u1, u2, . . . , um,其 中每个可微分函数ui都有变量x1, x2, . . . , xn。注意,y是x1, x2 . . . , xn的函数。对于任意i = 1, 2, . . . , n,链式 法则给出
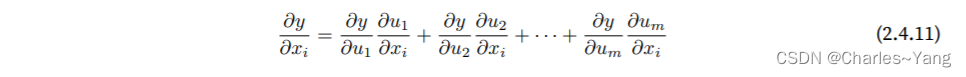
1.5小结
• 微分和积分是微积分的两个分⽀,前者可以应⽤于深度学习中的优化问题。
• 导数可以被解释为函数相对于其变量的瞬时变化率,它也是函数曲线的切线的斜率。
• 梯度是⼀个向量,其分量是多变量函数相对于其所有变量的偏导数。
#梯度这一块的规则还不是很清楚,要补补课。
• 链式法则可以⽤来微分复合函数。
1.6练习
1. 绘制函数y = f(x) = x 3 − 1 x和其在x = 1处切线的图像。
2. 求函数f(x) = 3x 2 1 + 5e x2的梯度。
3. 函数f(x) = ∥x∥2的梯度是什么?
4. 尝试写出函数u = f(x, y, z),其中x = x(a, b),y = y(a, b),z = z(a, b)的链式法则。
2.自动微分
深度学习框架通过⾃动计算导数,即⾃动微分(automatic differentiation)来加快求导。实际中,根据设计 好的模型,系统会构建⼀个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来 产⽣输出。⾃动微分使系统能够随后反向传播梯度。这⾥,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
2.1一个简单的例子
作为⼀个演⽰例⼦,假设我们想对函数y = 2关于列向量x求导。⾸先,我们创建变量x并为其分配⼀个初 始值。
import torch
x = torch.arange(4.0)
x
tensor([0., 1., 2., 3.])
在我们计算y关于x的梯度之前,需要⼀个地⽅来存储梯度。重要的是,我们不会在每次对⼀个参数求导时都 分配新的内存。因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗 尽。注意,⼀个标量函数关于向量x的梯度是向量,并且与x具有相同的形状。
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None现在计算y。
y = 2 * torch.dot(x, x)
ytensor(28., grad_fn=<MulBackward0>)
x是⼀个⻓度为4的向量,计算x和x的点积,得到了我们赋值给y的标量输出。接下来,通过调⽤反向传播函数 来⾃动计算y关于x每个分量的梯度,并打印这些梯度。
y.backward()
x.gradtensor([ 0., 4., 8., 12.])
函数y = 22关于x的梯度应为4x。让我们快速验证这个梯度是否计算正确。
x.grad == 4 * xtensor([True, True, True, True])
现在计算x的另⼀个函数。
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
tensor([1., 1., 1., 1.])
2.2非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最⾃然解释是⼀个矩阵。对于⾼阶和⾼维的y和x,求导的结果可以 是⼀个⾼阶张量。
然⽽,虽然这些更奇特的对象确实出现在⾼级机器学习中(包括深度学习中),但当调⽤向量的反向计算时, 我们通常会试图计算⼀批训练样本中每个组成部分的损失函数的导数。这⾥,我们的⽬的不是计算微分矩阵, ⽽是单独计算批量中每个样本的偏导数之和。
# 对⾮标量调⽤backward需要传⼊⼀个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递⼀个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.gradtensor([0., 2., 4., 6.])
2.3分离计算
有时,我们希望将某些计算移动到记录的计算图之外。例如,假设y是作为x的函数计算的,⽽z则是作为y和x的 函数计算的。想象⼀下,我们想计算z关于x的梯度,但由于某种原因,希望将y视为⼀个常数,并且只考虑 到x在y被计算后发挥的作⽤。
这⾥可以分离y来返回⼀个新变量u,该变量与y具有相同的值,但丢弃计算图中如何计算y的任何信息。换句 话说,梯度不会向后流经u到x。因此,下⾯的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理, ⽽不是z=x*x*x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
tensor([True, True, True, True])
由于记录了y的计算结果,我们可以随后在y上调⽤反向传播,得到y=x*x关于的x的导数,即2*x。
x.grad.zero_()
y.sum().backward()
x.grad == 2 * xtensor([True, True, True, True])
2.4Python控制流的梯度计算
使⽤⾃动微分的⼀个好处是:即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数 调⽤),我们仍然可以计算得到的变量的梯度。在下⾯的代码中,while循环的迭代次数和if语句的结果都取 决于输⼊a的值。
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
让我们计算梯度。
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()我们现在可以分析上⾯定义的f函数。请注意,它在其输⼊a中是分段线性的。换⾔之,对于任何a,存在某个 常量标量k,使得f(a)=k*a,其中k的值取决于输⼊a,因此可以⽤d/a验证梯度是否正确。
a.grad == d / atensor(True)
2.5小结
深度学习框架可以⾃动计算导数:我们⾸先将梯度附加到想要对其计算偏导数的变量上,然后记录⽬ 标值的计算,执⾏它的反向传播函数,并访问得到的梯度。
2.6练习
1. 为什么计算⼆阶导数⽐⼀阶导数的开销要更⼤?
2. 在运⾏反向传播函数之后,⽴即再次运⾏它,看看会发⽣什么。
3. 在控制流的例⼦中,我们计算d关于a的导数,如果将变量a更改为随机向量或矩阵,会发⽣什么?
4. 重新设计⼀个求控制流梯度的例⼦,运⾏并分析结果。
5. 使f(x) = sin(x),绘制f(x)和df(x) dx 的图像,其中后者不使⽤f ′ (x) = cos(x)。














 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









