







一、2.1数据操作
1、运⾏本节中的代码。将本节中的条件语句X == Y更改为X < Y或X > Y,然后看看你可以得到什么样的张量。
回答: 都是输出结果比较的张量
X==Y时
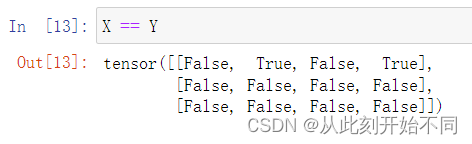
X<Y时:
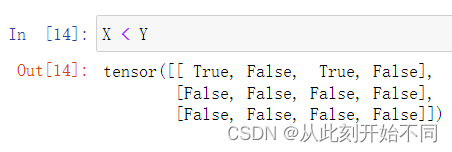
X>Y时:

2、⽤其他形状(例如三维张量)替换⼴播机制中按元素操作的两个张量。结果是否与预期相同?
回答: 不一定,得看张量的大小,根据具体情况具体分析。
可以参考这个博客的分析:pytorch的广播机制
二、2.2数据预处理
1、删除缺失值最多的列。
回答: 可以利用isnull对缺失值进行统计,然后利用sum和idxmax找到对应的列序号,最后进行删除。
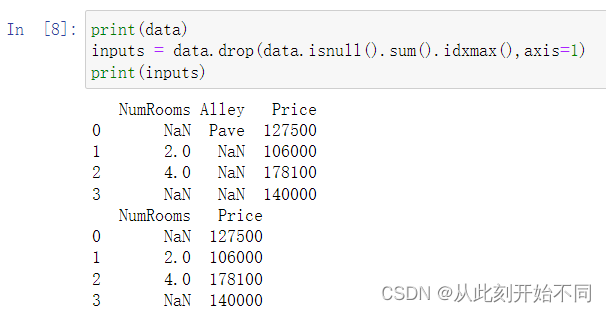
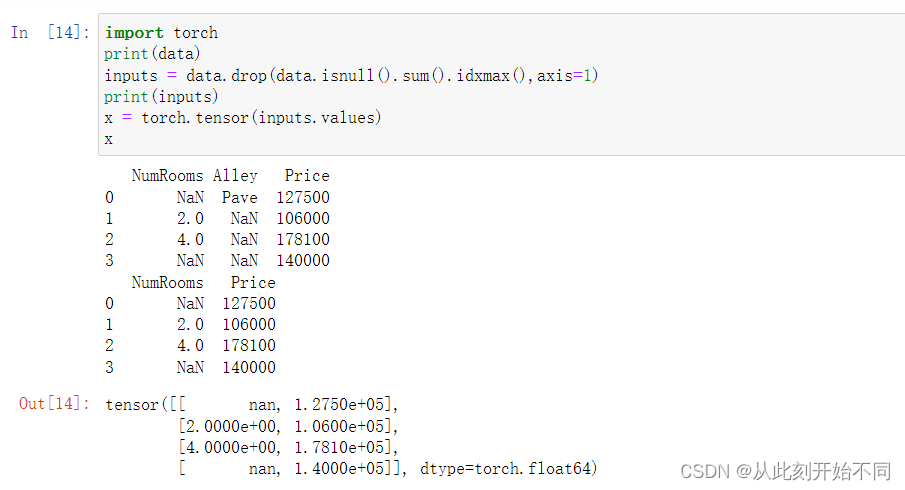
2、将预处理后的数据集转换为张量格式。
回答: 主要是利用torch.tensor进行转换
三、2.3线性代数
1、证明一个矩阵 𝐀的转置的转置是 𝐀 ,即
(
A
T
)
T
=
A
(A^T)^T=A
(AT)T=A 。
回答: 设
B
=
A
T
,则
B
j
i
=
A
i
j
,设
C
=
B
T
=
(
A
T
)
T
,则可知
C
i
j
=
B
j
i
,故
C
i
j
=
A
i
j
,所以
(
A
T
)
T
=
A
。
B =A^T,则B_{ji} =A_{ij},设C=B^T=(A^T)^T,则可知C_{ij}=B_{ji},故C_{ij} =A_{ij},所以(A^T)^T=A。
B=AT,则Bji=Aij,设C=BT=(AT)T,则可知Cij=Bji,故Cij=Aij,所以(AT)T=A。
2、给出两个矩阵 𝐀和 𝐁 ,证明“它们转置的和”等于“它们和的转置”,即
A
T
+
B
T
=
(
A
+
B
)
T
。
A^T+B^T = (A+B)^T。
AT+BT=(A+B)T。
回答:
设
A
T
+
B
T
=
C
。则
C
i
j
=
A
j
i
+
B
j
i
,又设
D
=
(
A
+
B
)
,则
D
j
i
=
A
j
i
+
B
j
i
,故
C
=
D
T
,所以
A
T
+
B
T
=
(
A
+
B
)
T
得证。
设 A^T+B^T = C。则C_{ij}=A_{ji}+B_{ji},又设D=(A+B),则D_{ji}=A_{ji}+B_{ji},故C=D^T,所以A^T+B^T = (A+B)^T得证。
设AT+BT=C。则Cij=Aji+Bji,又设D=(A+B),则Dji=Aji+Bji,故C=DT,所以AT+BT=(A+B)T得证。
3、给定任意方阵
A
,
A
+
A
T
A, A+A^T
A,A+AT总是对称的吗?为什么?
回答:
设
B
=
A
+
A
T
,则
B
i
j
=
A
i
j
+
A
j
i
,
B
j
i
=
A
j
i
+
A
i
j
=
B
i
j
,所以总是对称的得证
设B = A+A^T ,则B_{ij} = A_{ij} + A_{ji},B_{ji} = A_{ji} + A_{ij} = B_{ij},所以总是对称的得证
设B=A+AT,则Bij=Aij+Aji,Bji=Aji+Aij=Bij,所以总是对称的得证
4、本节中定义了形状 (2,3,4)的张量X。len(X)的输出结果是什么?
回答: 2,返回第一维度的长度
5、对于任意形状的张量X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?
回答: 返回第一维度
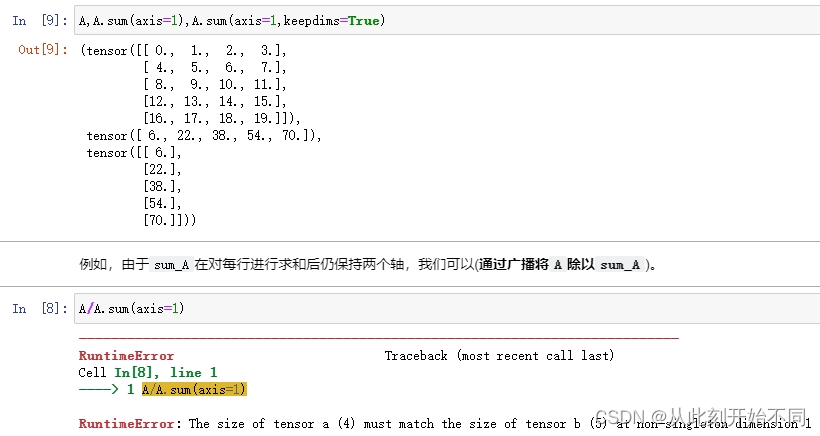
6、运行A/A.sum(axis=1),看看会发生什么。请分析一下原因?
回答: 报错,因为轴数变了,原来的A.sum(axis=1, keepdims=True)保持住了轴数。因此根据广播的原理则进行了复制,从而可以顺利计算,但是没有使用keepdims的话则会计算成一个1*5的向量,这个时候直接做除法会变成用每一行去除以这一行,从而报错,因为只有四列,没有第五列可以用来除。
7、考虑一个具有形状 (2,3,4)的张量,在轴0、1、2上的求和输出是什么形状?
回答: [3,4],[2,4],[2,3]

8、为linalg.norm函数提供3个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?
回答: 计算的结果就是所有值的平方和再开方。

四、2.4微积分
1、绘制函数 𝑦=𝑓(𝑥)=𝑥
3
−
1
x
^3-\frac{1}{x}
3−x1 和其在 𝑥=1处切线的图像。
回答: 需要修改的地方及最后的结果如下图


2、求函数 𝑓(𝐱)=3𝑥
1
2
+
5
e
x
2
^2_1+5e^{x_2}
12+5ex2的梯度。
回答: 【6
x
1
,
5
e
x
2
x_1,5e^{x_2}
x1,5ex2】
3、函数 𝑓(𝐱)=‖𝐱‖2的梯度是什么?
回答:
x
i
∣
∣
x
∣
∣
2
\frac{x_i}{||x||_2}
∣∣x∣∣2xi
4、尝试写出函数 𝑢=𝑓(𝑥,𝑦,𝑧),其中 𝑥=𝑥(𝑎,𝑏), 𝑦=𝑦(𝑎,𝑏), 𝑧=𝑧(𝑎,𝑏)的链式法则。
回答: 链式法则的解释如下

因此易得对应的链式法则为
d
u
d
a
=
d
u
d
x
d
x
d
a
+
d
u
d
y
d
y
d
a
+
d
u
d
z
d
z
d
a
\frac{du}{da} = \frac{du}{dx}\frac{dx}{da} + \frac{du}{dy}\frac{dy}{da}+\frac{du}{dz}\frac{dz}{da}
dadu=dxdudadx+dydudady+dzdudadz
d
u
d
b
=
d
u
d
x
d
x
d
b
+
d
u
d
y
d
y
d
b
+
d
u
d
z
d
z
d
b
\frac{du}{db} = \frac{du}{dx}\frac{dx}{db} + \frac{du}{dy}\frac{dy}{db}+\frac{du}{dz}\frac{dz}{db}
dbdu=dxdudbdx+dydudbdy+dzdudbdz
五、2.5自动微分
1、为什么计算二阶导数比一阶导数的开销要更大?
回答: 根据链式法则,二阶导数需要求两次导,所以开销要比一阶来得更大。
2、在运行反向传播函数之后,立即再次运行它,看看会发生什么。
回答: 会报错,因为中间的那些参数已经在第一次计算后被释放了,所以无法进行第2次计算。

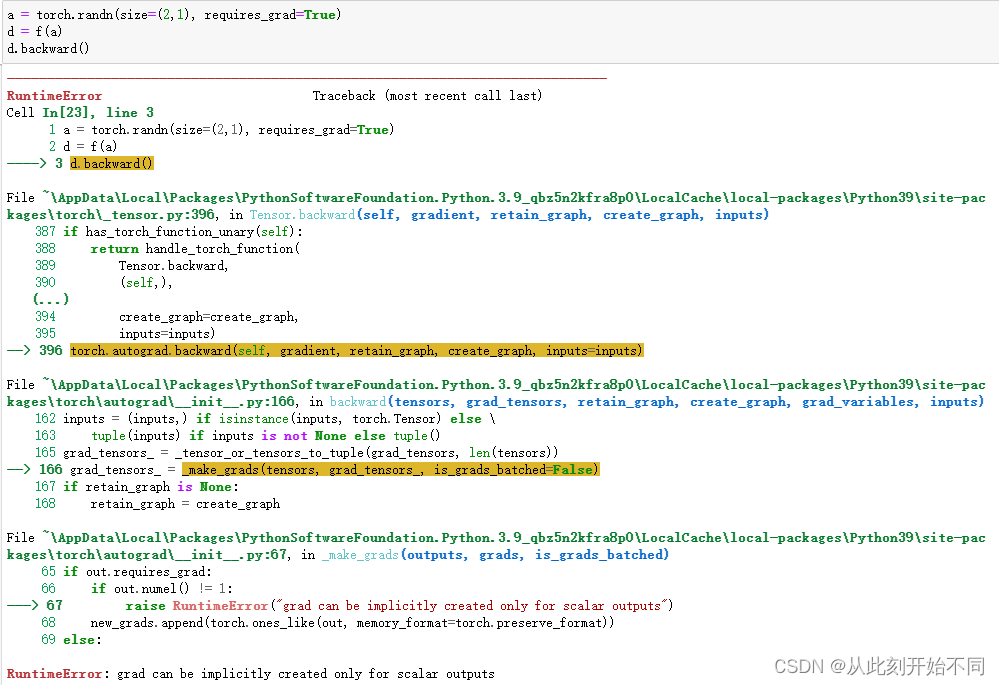
3、在控制流的例子中,我们计算d关于a的导数,如果将变量a更改为随机向量或矩阵,会发生什么?
回答: 会报错,表示只能为标量隐式创建梯度
4、重新设计一个求控制流梯度的例子,运行并分析结果。
回答: 设计如下
def f(a):
b = a * 2
while b.exp() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
a.grad==d/a
我只是将其中的norm函数这一判断条件修改成了exp这一函数,结果还是一样满足线性,所以输出true。
5、使 𝑓(𝑥)=sin(𝑥),绘制 𝑓(𝑥)和
d
f
(
x
)
d
x
\frac{df(x)}{dx}
dxdf(x) 的图像,其中后者不使用 𝑓′(𝑥)=cos(𝑥)。
回答:
import torch
import matplotlib.pyplot as plt
from matplotlib_inline import backend_inline
from d2l import torch as d2l
x = torch.arange(-3,3,0.1)
x.requires_grad_(True)
y = torch.sin(x)
y.sum().backward()
plt.plot(x.detach(), y.detach(), label='y=sin(x)')
plt.plot(x.detach(), x.grad, label='dsin(x)=cos(x)')
plt.legend(loc='upper center')
plt.show()
注意事项1:这里必须使用y.sum(),因为只有标量才可以反向传播回去
注意事项2:这里必须使用detach,因为涉及了计算图的计算,如果不适用detach直接使用原来的x和y,可能会影响计算图的计算。
这两个注意事项其实在2.5.2和2.5.3中都有体现。
参考网址:相关作业
六、2.6概率
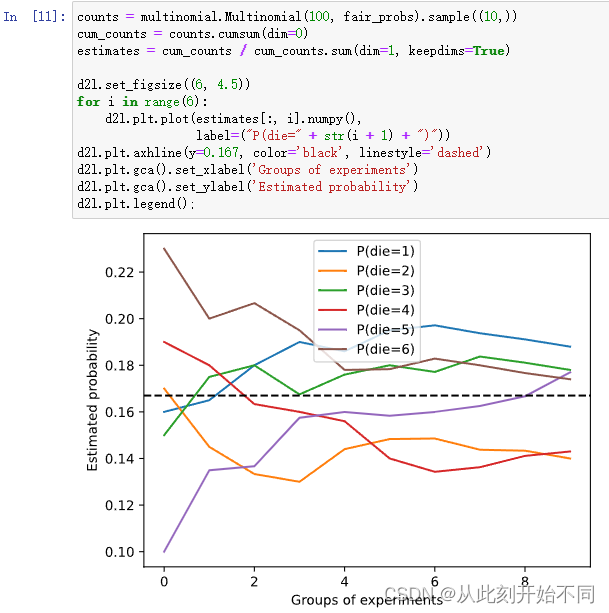
1、进行 𝑚=500组实验,每组抽取 𝑛=10个样本。改变 𝑚和 𝑛,观察和分析实验结果。
回答: 将m改为10000
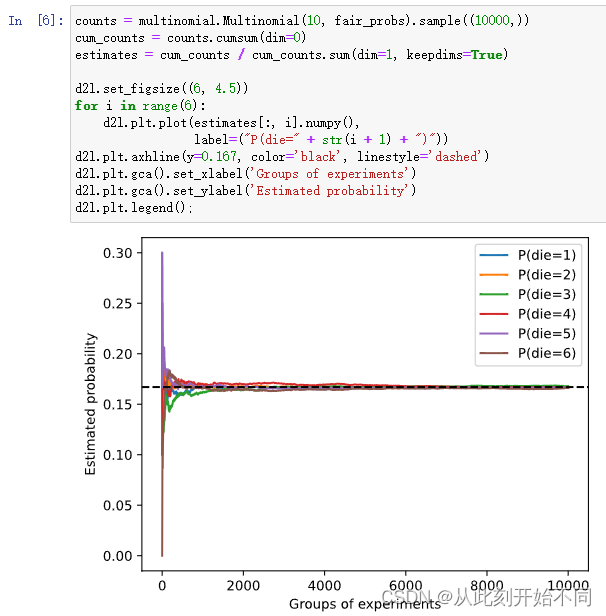
改为1和10时
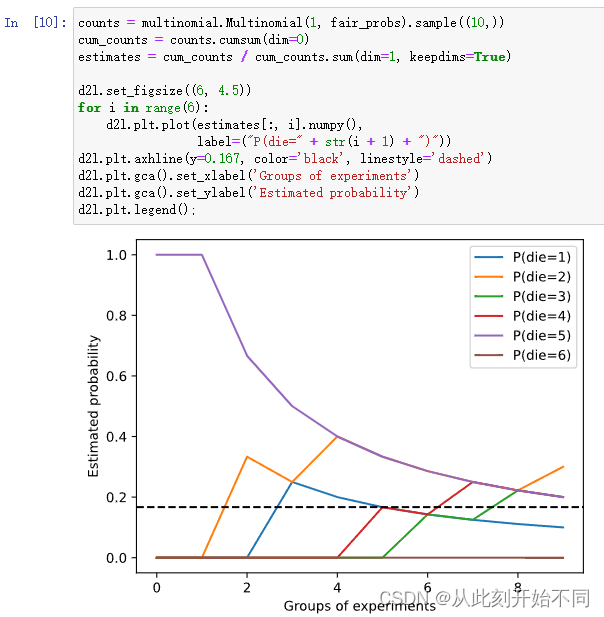
改为100和10时
改为10000和10时
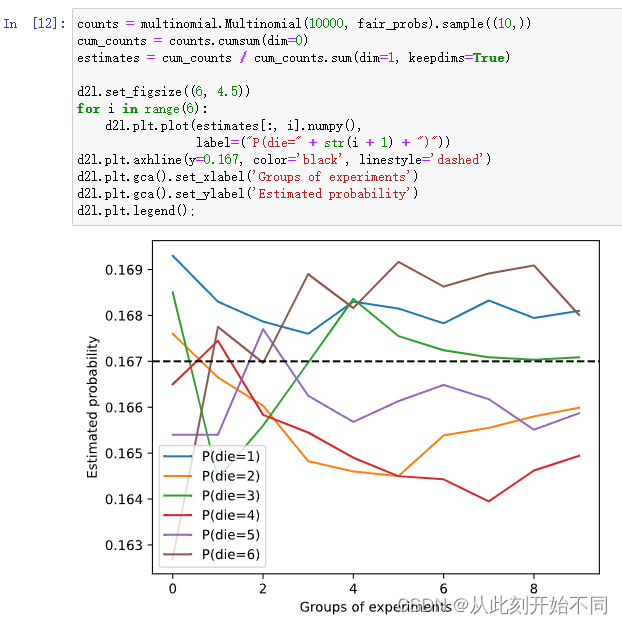
结论:n越大,一开始越接近1/6的概率,次数m越大,则越来越收敛。
2、给定两个概率为 𝑃(A) 和 𝑃(B) 的事件,计算 𝑃(A∪B) 和 𝑃(A∩B) 的上限和下限。(提示:使用友元图来展示这些情况。)
回答: 上限是两者无关的情况,下限是两者强相关,其中一个是另一个的子事件的情况。
m
a
x
(
P
(
A
)
,
P
(
B
)
)
≤
P
(
A
∪
B
)
≤
P
(
A
)
+
P
(
B
)
max(P(A),P(B))≤ P(A∪B)≤P(A)+P(B)
max(P(A),P(B))≤P(A∪B)≤P(A)+P(B)
上限是两者强相关,其中一个是另一个的子事件的情况,下限是两者无关的情况。
0
≤
P
(
A
∩
B
)
≤
m
i
n
(
P
(
A
)
,
P
(
B
)
)
0 ≤ P(A∩B)≤min(P(A),P(B))
0≤P(A∩B)≤min(P(A),P(B))
友元图画起来比较麻烦,所以就不画了。
3、设我们有一系列随机变量,例如 𝐴 、 𝐵 和 𝐶 ,其中 𝐵 只依赖于 𝐴 ,而 𝐶 只依赖于 𝐵 ,能简化联合概率 𝑃(𝐴,𝐵,𝐶) 吗?(提示:这是一个马尔可夫链。)
回答: 马尔可夫性质——下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
P
(
A
,
B
,
C
)
=
P
(
C
∣
B
)
P
(
B
∣
A
)
P
(
A
)
P(A,B,C) = P(C|B)P(B|A)P(A)
P(A,B,C)=P(C∣B)P(B∣A)P(A)
4、在2.6.2节中,第一个测试更准确。为什么不运行第一个测试两次,而是同时运行第一个和第二个测试?
回答: 用不同的测试才具有条件独立性,假设现在第一个测试的流程是有问题的,那么两次之间是有相关性的,因而不能利用条件独立性来求解。
七、2.7查阅文档
1、在深度学习框架中查找任何函数或类的文档。请尝试在这个框架的官方网站上找到文档。
直接搜索pytorch或者点击这里pytorch官方文档















 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









