










2.Build the model 建立模型
类&对象

1.蜥蜴类让我们知道对象有颜色和长度,但它没有告诉我们颜色和长度是多少,因为类只描述对象。
2.一个类就像一个对象的蓝图,我们可以从同一个类中创建尽可能多的不同对象。
1.类被认为是包含代码和数据的自包含单元,可以看作是把属性和方法打包在一起,然后把它们封装到类中。

Class:声明类并指定类名,如Lizard
__init__:类构造器,当类的新实例被创建为这个构造器的参数(如name)时,就会调用构造器
self:一个特殊的参数,它使我们能够创建存储或封装在类对象中的属性值,当我们调用构造器或其他方法时,Python自动传递self参数
1.传递给构造器的东西在默认情况下会被丢弃,但是在self内的任何东西会一直被记住,只要这个对象存在。

torch.nn

import torch.nn as nn1.torch.nn包含了构建神经网络所需的所有典型组件。我们需要构建一个神经网络的重要组件是层(layer),torch.nn包含了帮助我们构造层的类。
2.神经网络的每个层有两个重要组成部分,第一个是转换(transformation),第二个是权重的集合(collection of weights)。回想面向对象编程(OOP),我们可能会看到转换是用代码(code)表示的,权重的集合是用数据(data)表示的 ,这一事实使层成为使用OOP的类表示的优秀候选者。
3.在神经网络包里,有一个称为Module的特殊类,它是所有神经网络模块的父类。这意味着所有Pytorch的层都扩展(extend)了nn.Module类并继承了所有Pytorch的内置函数。在OOP中,这个概念被称为继承(inheritance)。
前向方法
1.张量通过每个层转换向前流动,直到张量到达输出层。这个过程被称为前向传输(forward pass)。
每个层都有它自己的转换,张量通过每个层的转换前向传输。所有单独的层的前向传输的组合定义了网络自身整体的前向传输转换。
2.这一切对于Pytorch的意义在于每一个nn.Module都有一个前向方法(forward method)来代表前向传输,所以我们在构建层和网络时,我们必须提供前向方法的实现。前向方法就是实际的转换,无论是对于一个层还是一个神经网络。
3.当我们实现nn.Module子类的前向方法时,我们通常使用来自nn.functional包的函数。这个包为我们提供了许多当我们实现我们的前向函数时需要的神经网络操作。
构建神经网络

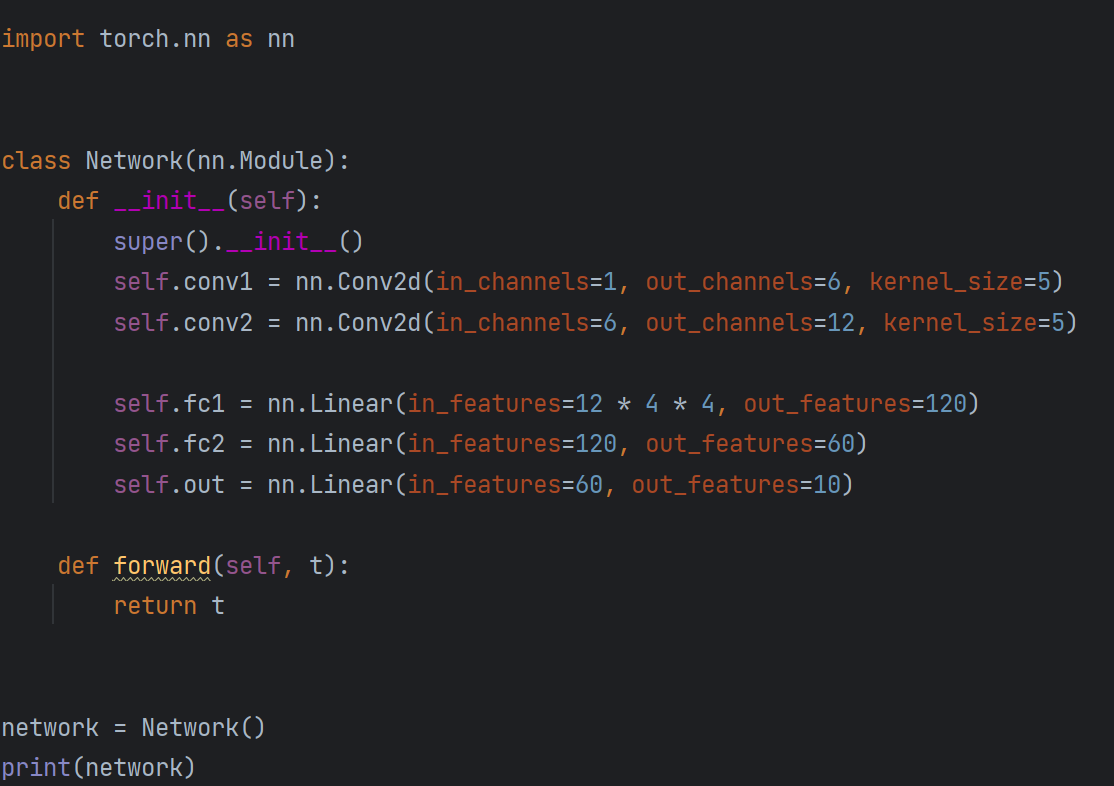
1.扩展nn.Module基类。
2.在类构造器中将网络的层定义为类属性。
3.使用网络层属性和nn.functional API的操作来定义网络的前向传输。

1.这为我们提供了一个简单的网络类,它在构造器中有一个虚拟层,并为前向函数提供了一个虚拟实现。
2.前向函数的实现采用张量t,并使用虚拟层对其进行转换。在张量转换后,新的张量被返回。
3.但是这个类还没有扩展nn.Module类,我们需要在class的()中指定nn.Module类,并在构造器中插入对super类构造器的调用。
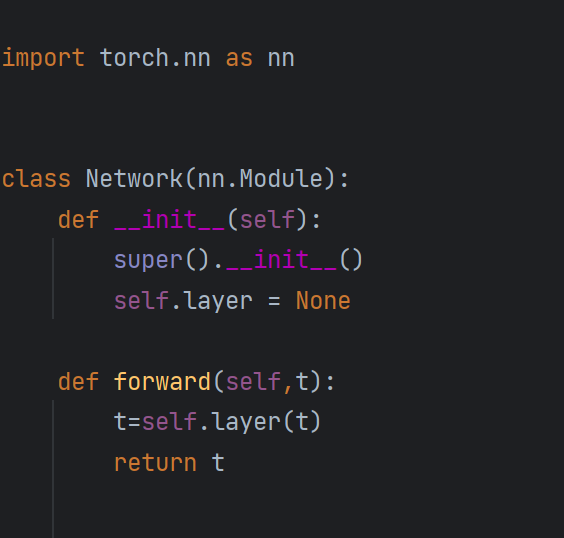
1.这些更改将我们的简单网络转换为Pytorch神经网络,因为我们扩展了nn.Module类。
2.这样做的好处是在覆盖之下,nn.Module类可以保持跟踪每个层中包含的网络的权重,当权重需要更新时,这个特性在训练过程中会非常方便。
3.如果没有扩展nn.Module类,类会默认扩展Python的object基类。
形参和实参
parameter 形参:在函数定义中使用,可以看作占位符(placeholder)
argument 实参:当函数被调用时传递给函数的实际值
超参数
1.超参数(hyperparameter)是手动和任意选择值的参数。
2.这意味着作为神经网络程序员,我们选择超参数值主要基于试验和错误,并且越来越多地利用过去被证明有效的值。

版本更迭导致的变动:super(子类,self)已改为super()
kernel_size:卷积核大小,kernel(核)与filter(滤波器)同义
out_channels:卷积核数量,一个卷积核产生一个输出通道(output channel),输出通道与特征图(feature map)同义
out_features:输出特征,设置输出张量大小
依赖于数据的超参数
1.第一个卷积层(convolution layer)的in_channels,依赖于构成数据集的图像内部的颜色通道数
2.最后一个线性层(linear layer)的out_features,线性层与全连接层同义(fully connected layer),依赖于数据集中类的数量
可学习参数
1.可学习参数(learnable parameter)是值在训练过程中习得的参数。当网络学习时,可学习参数会以迭代的方式更新。
2.事实上,当我们说一个网络正在学习,我们的意思是可学习参数正在习得合适的值,合适的值是指最小化损失函数的值。
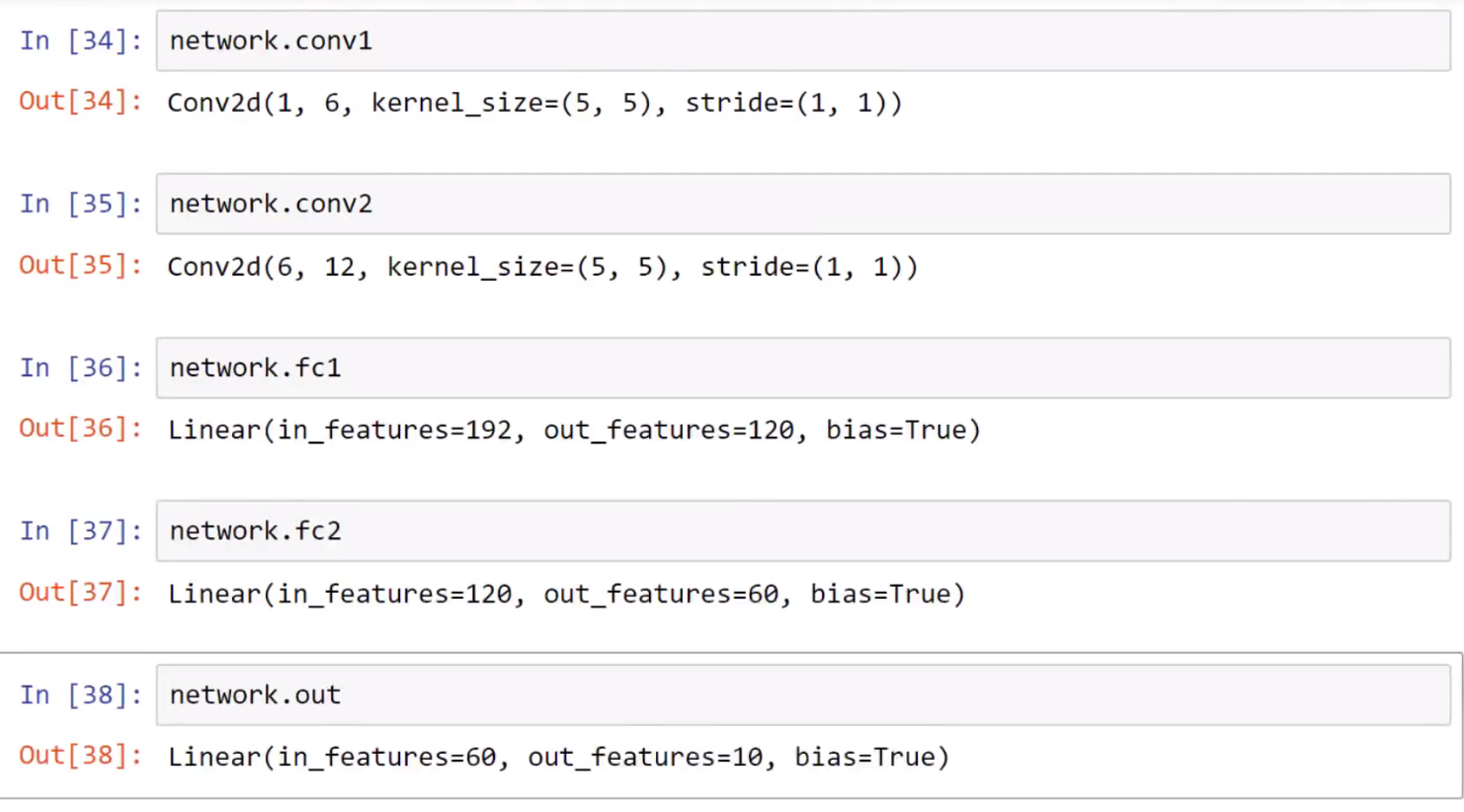
查看神经网络
打印神经网络
输入:
输出:

stride 步长:在整个卷积过程中,每个操作之后滤波器应该滑动的距离,如(1, 1)表示向右移动一个单位,且向下移动一个单位
bias 偏置:即ω x+b的b
打印层
重写__repr__
输入:
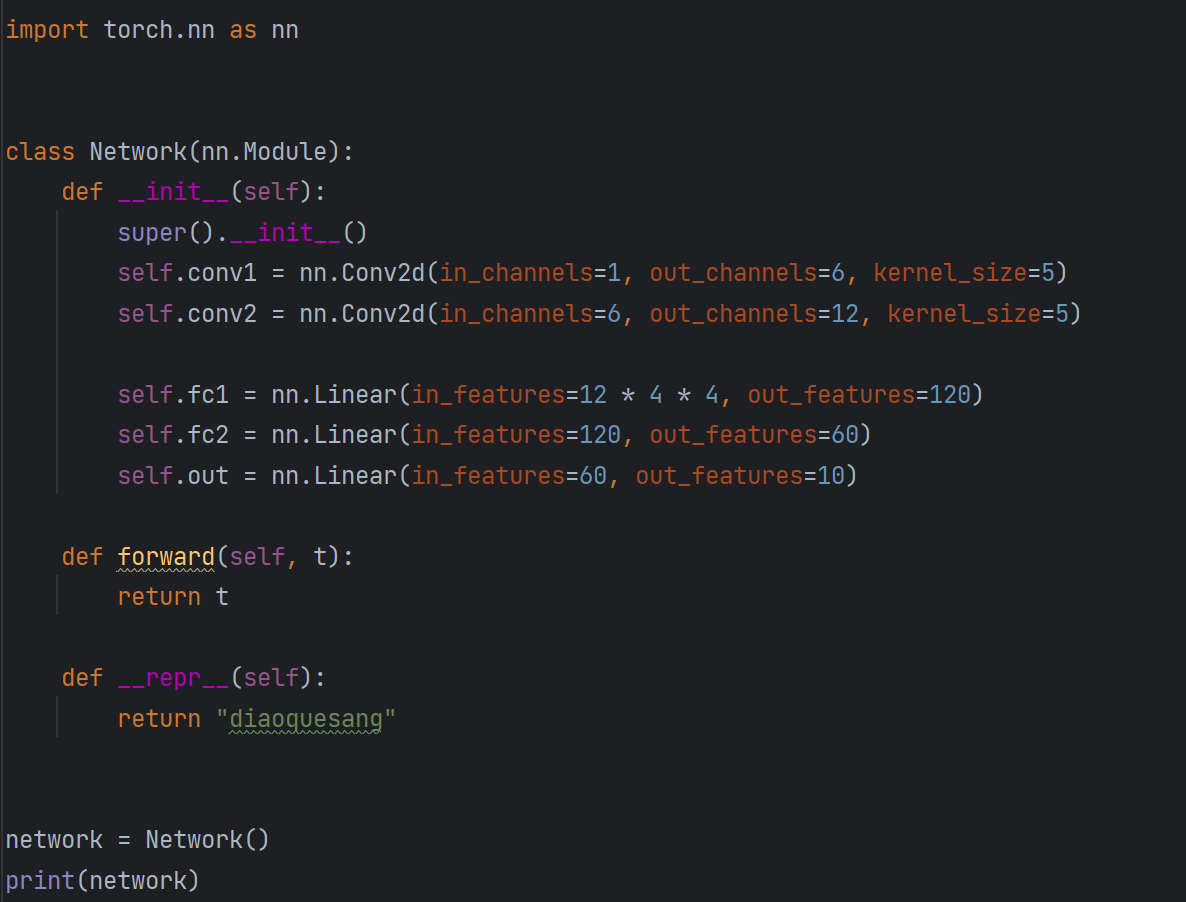
输出:

打印权重
卷积层的权重:
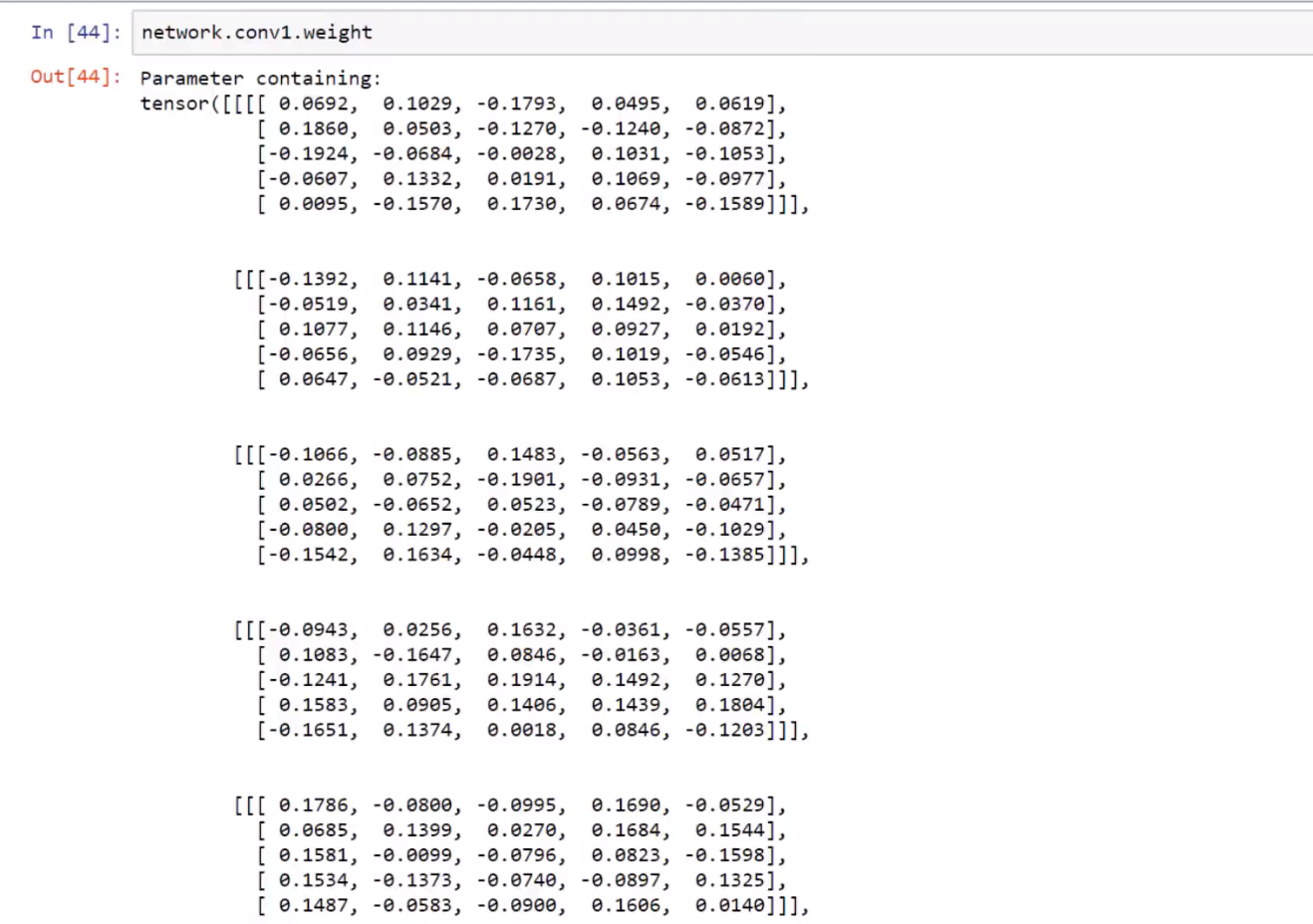
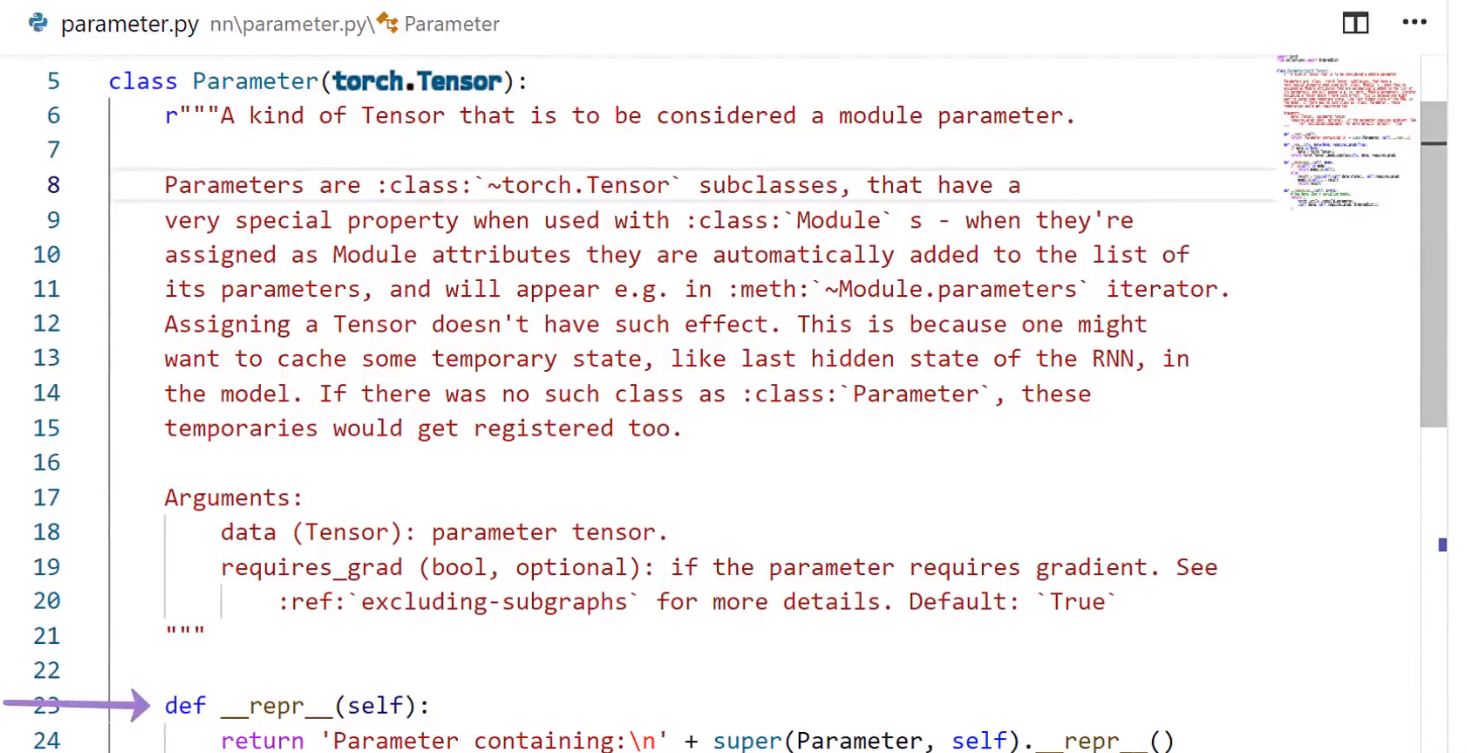
版本更迭导致的变动:super(子类,self)已改为super()
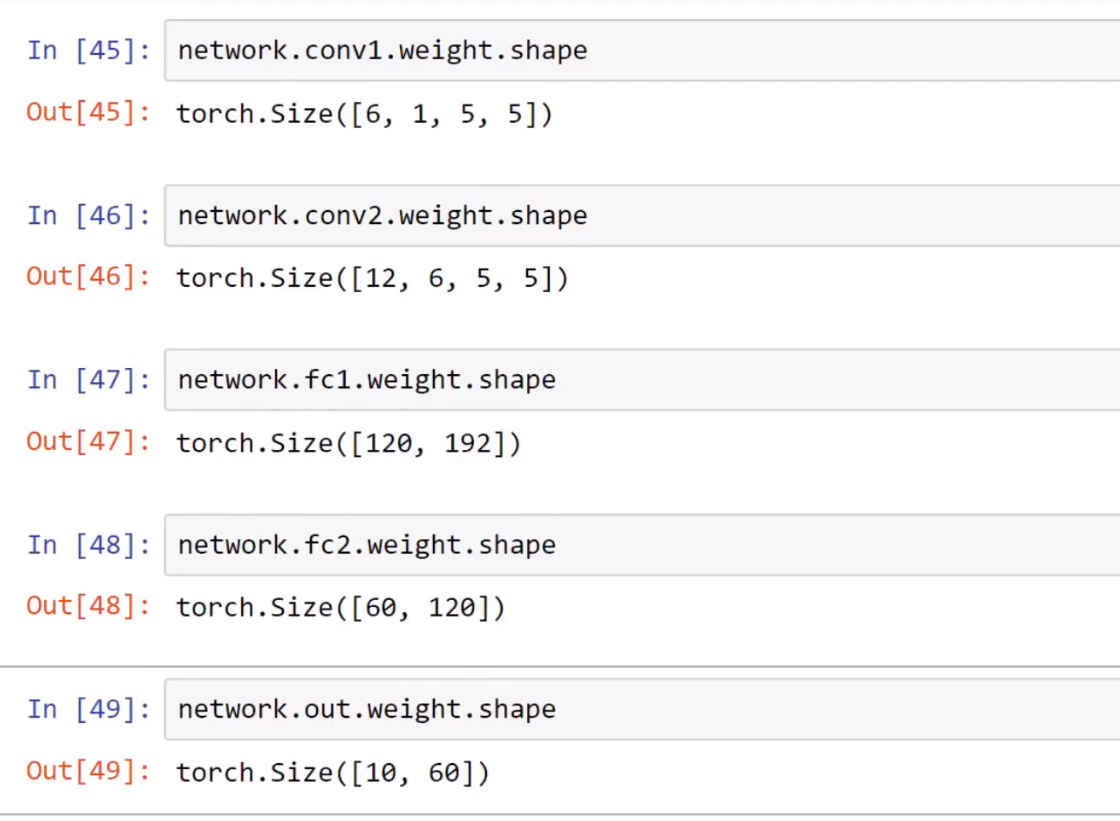
1.公式:torch.Size([输出,输入,卷积核高度,卷积核宽度])。


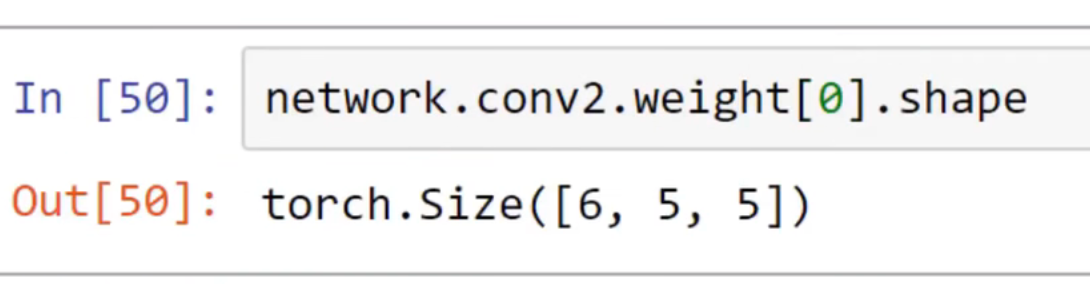
单个卷积核的权重:
线性层的权重:

1.公式:torch.Size([输出,输入])。
打印参数
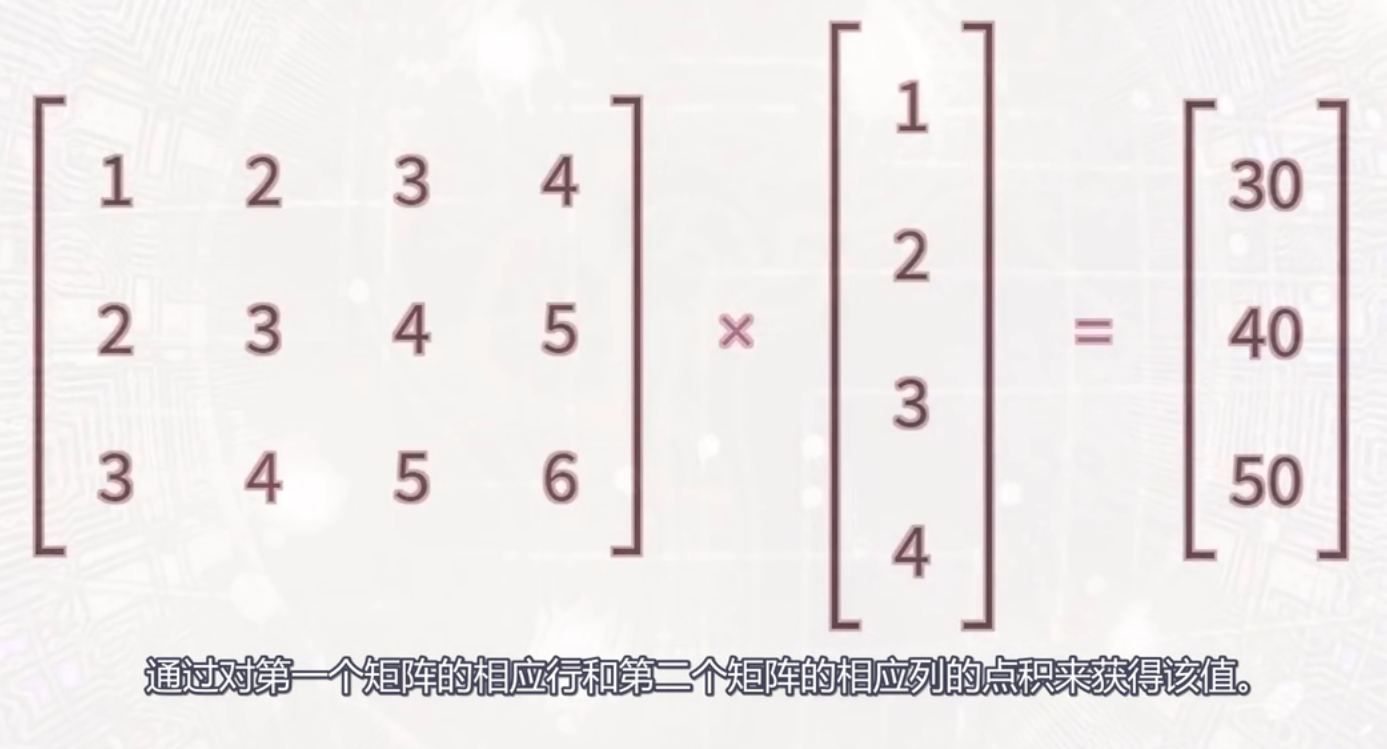
矩阵乘法

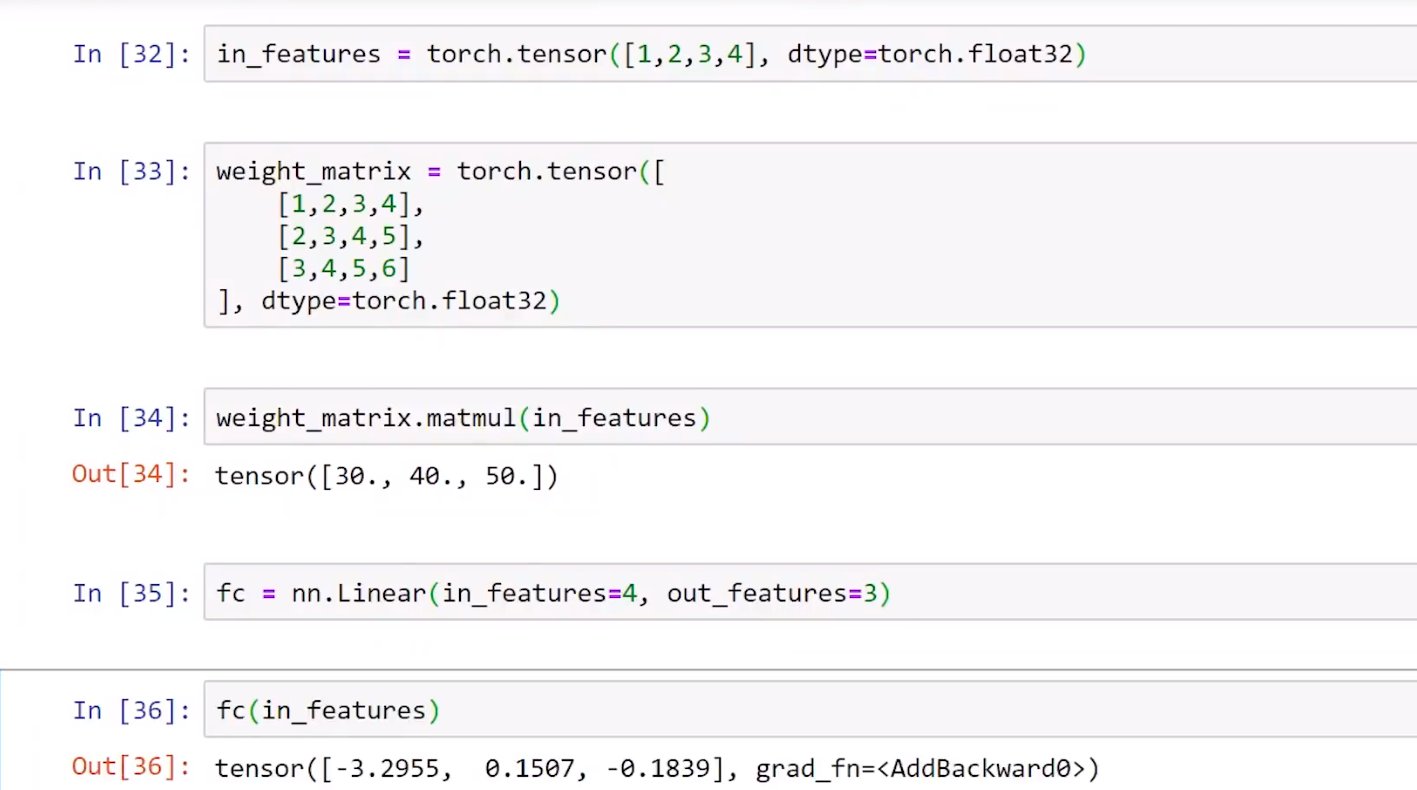
1.Pytorch创建了一个权重矩阵和偏置,并用随机的值来初始化它。
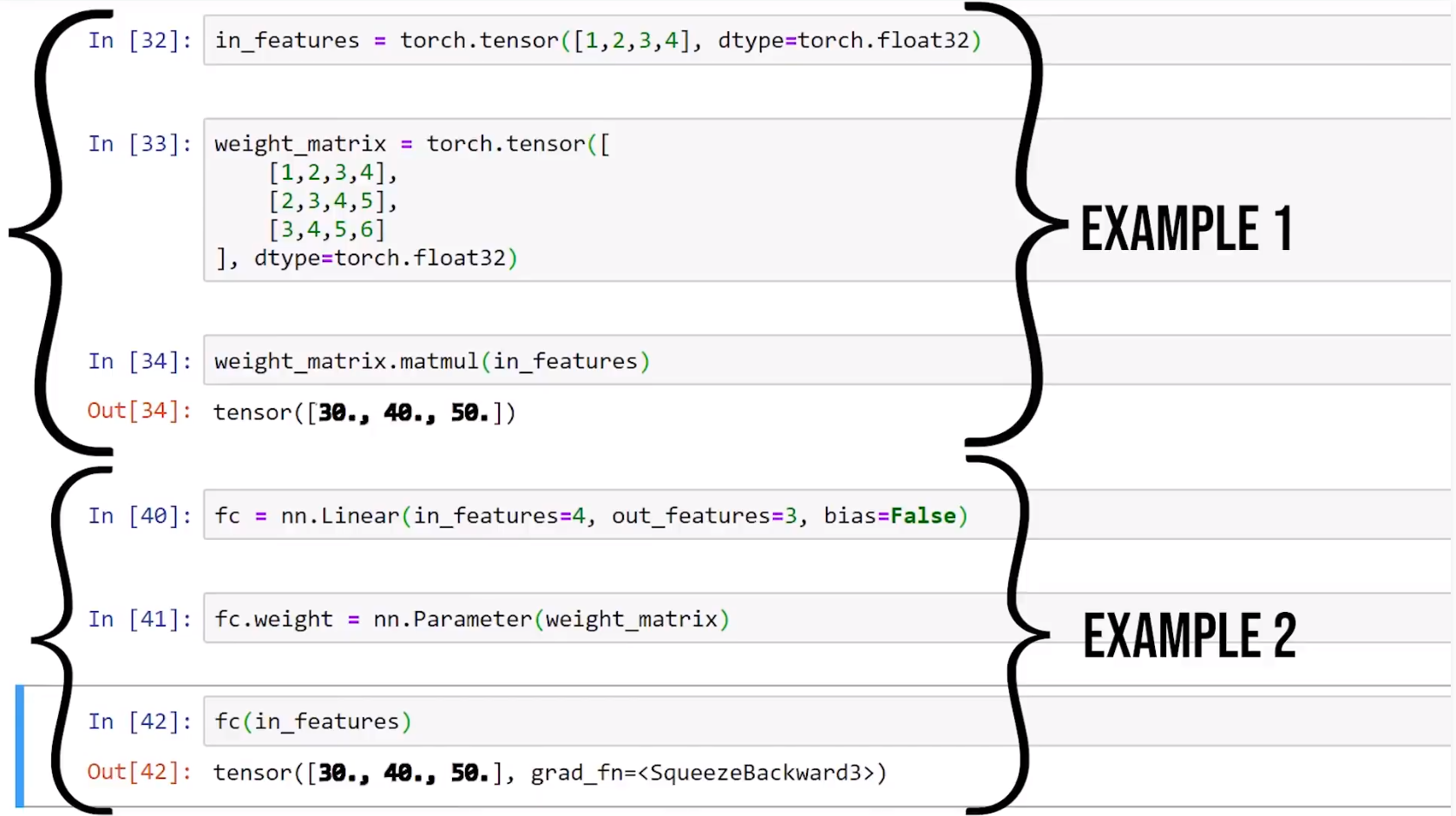
1.更换权重矩阵并关闭偏置后,上下结果一致。
调用方法

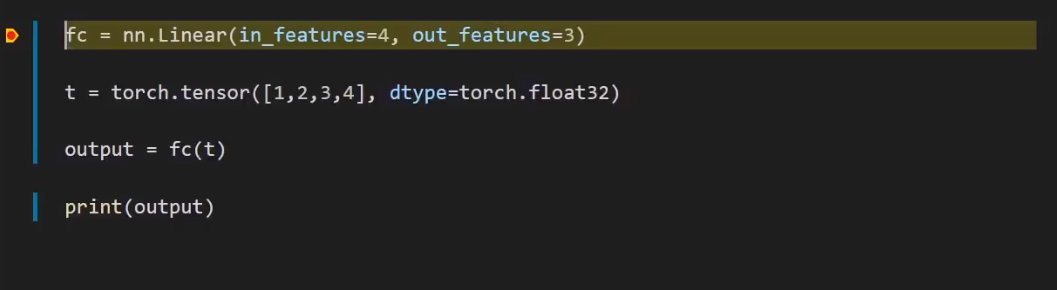
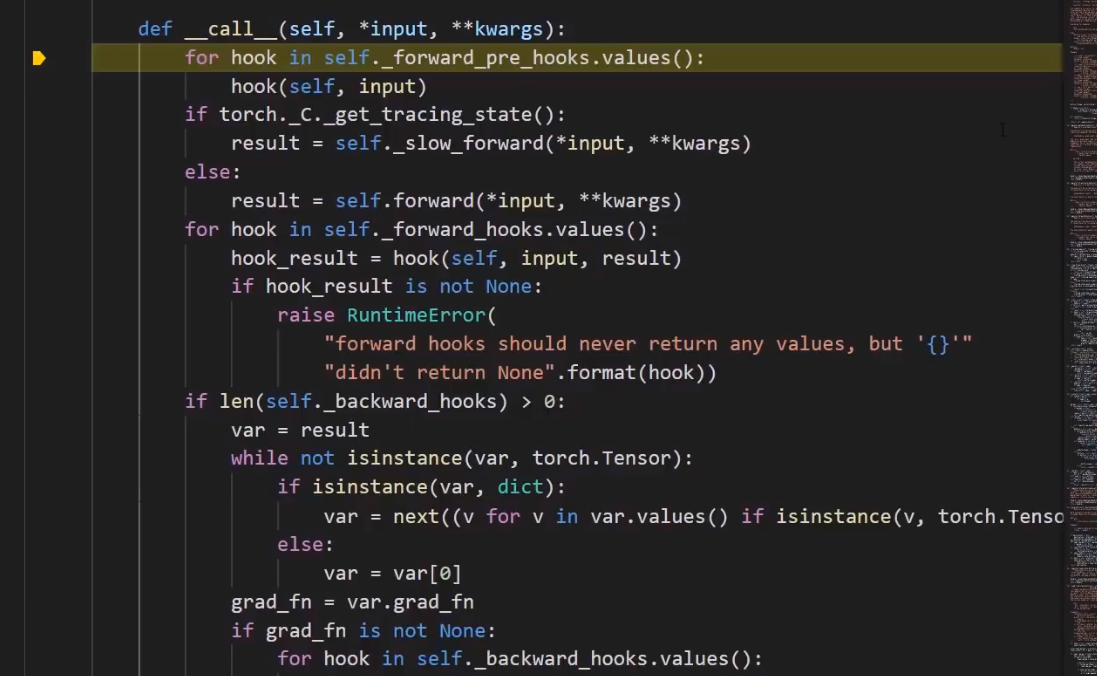
1.Pytorch在调用方法(call method)中运行的额外代码是我们从未直接调用forward方法的原因。
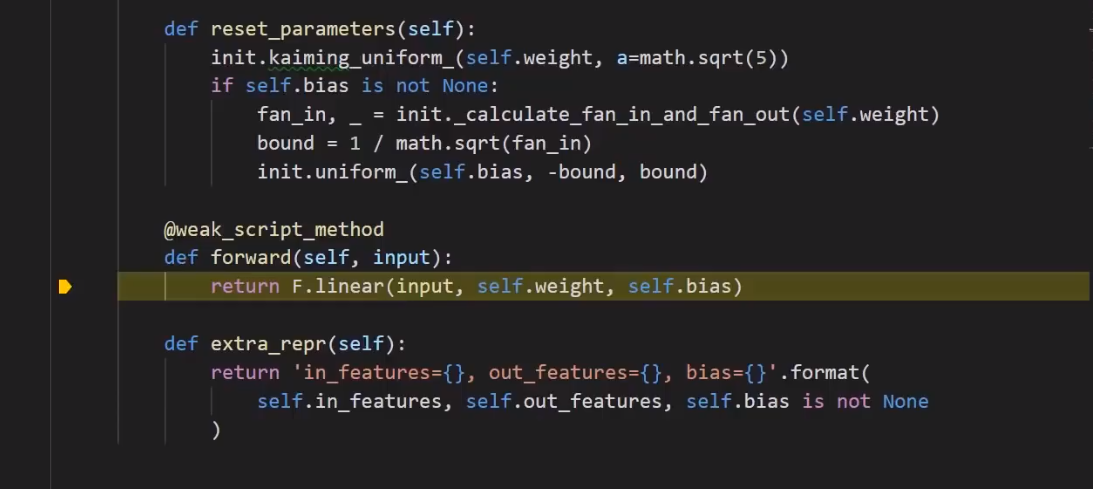
1.F代表torch.functional。
前向方法的实现
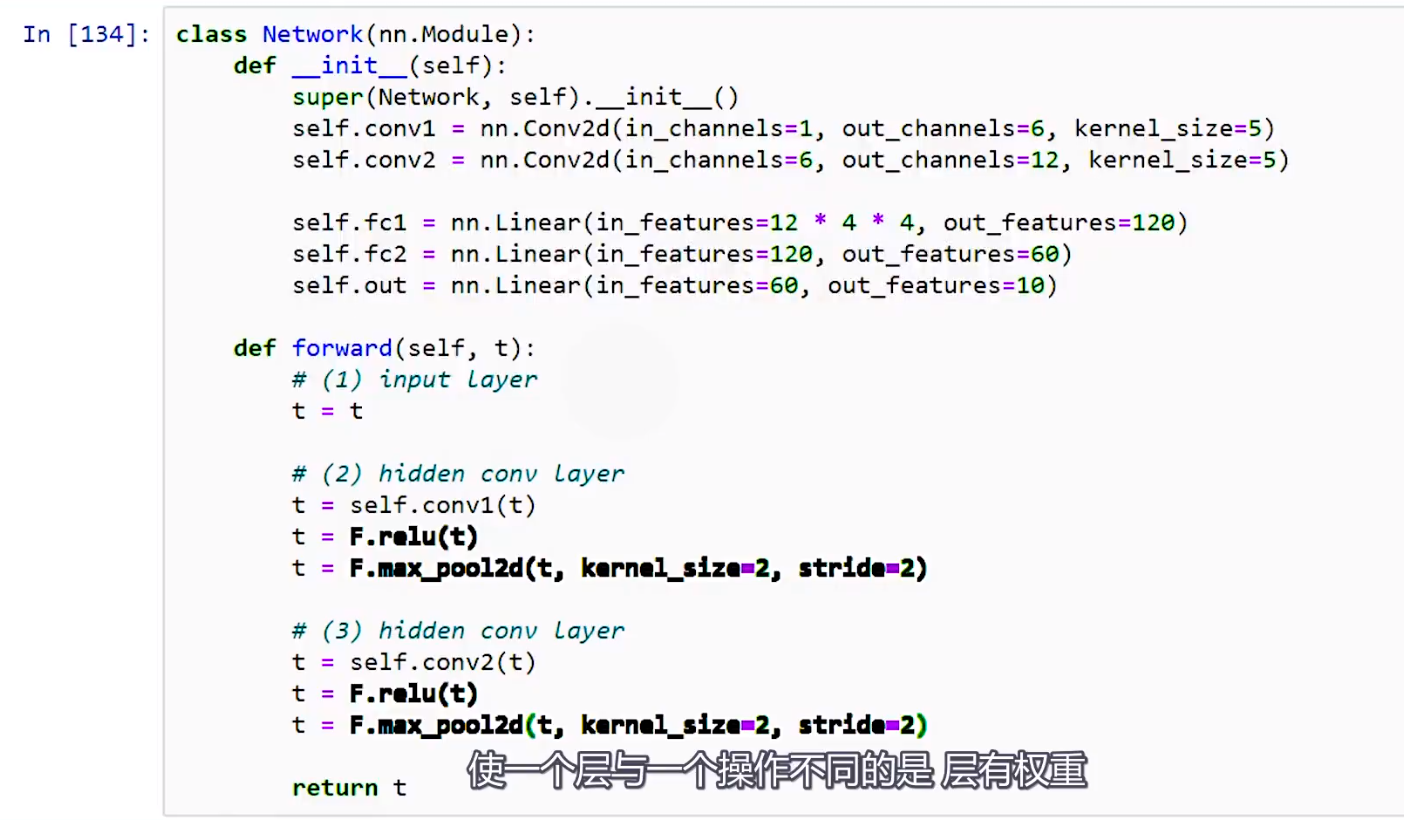
1.激活和池化均没有权重,属于操作,不同于层,这是我们直接从nn.functional API调用它们的原因。

1.在reshape的12 * 4 * 4中,4实际上12个输出通道的高度和宽度。当我们的张量到达第一个线性层时,尺寸从28x28减小到4x4,这种减小是由于卷积和池化造成的。
2.dim=1代表第1维度(沿x轴方向)概率总和为1,常用于分类问题。
3.我们将使用交叉熵损失函数,它将在其输入上隐式地执行一个softmax操作,所以我们注释掉softmax
前向传播

1.前向传播(forward propagation)是将输入张量转换为输出张量的过程。
2.前向方法的执行是前向传播的过程。
图像预测
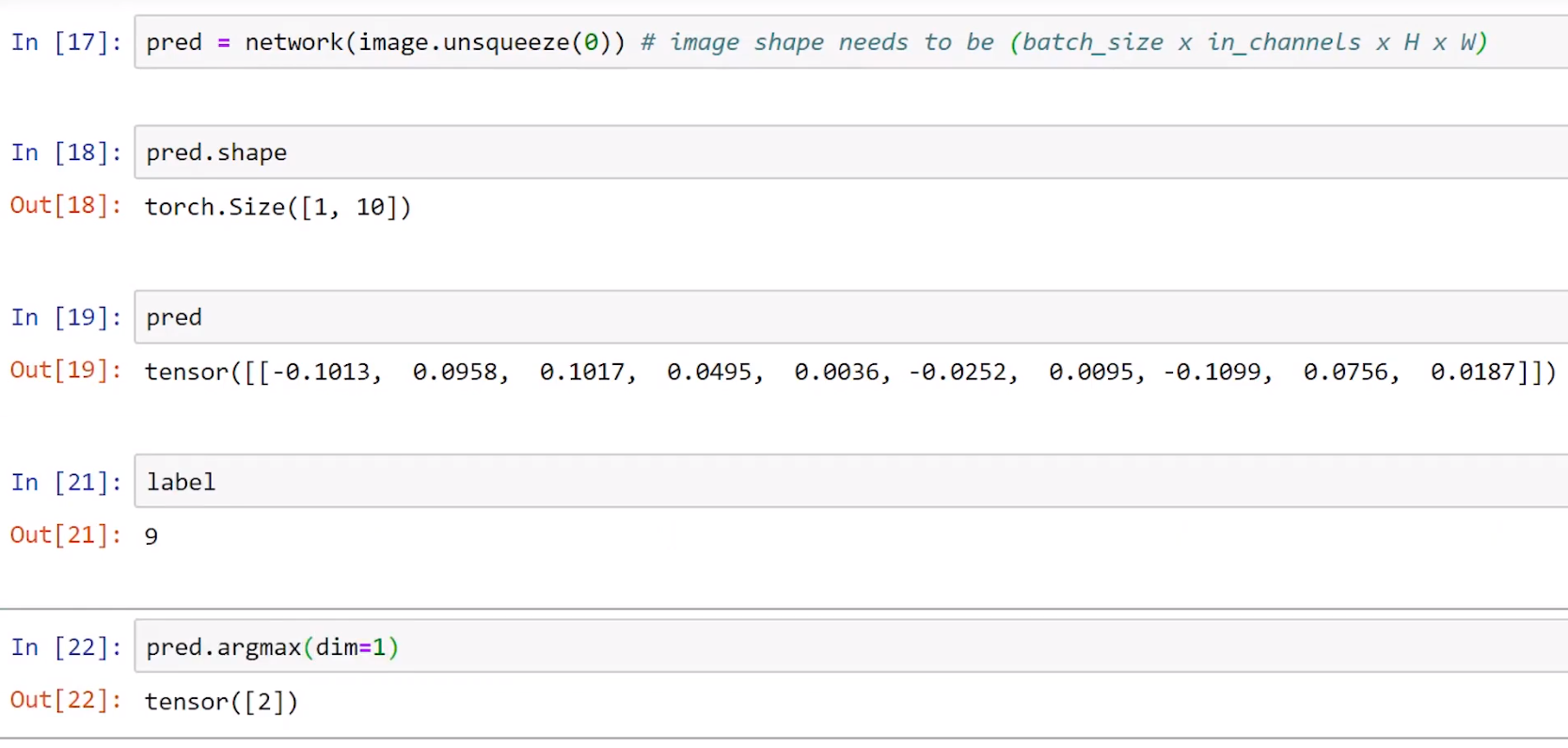


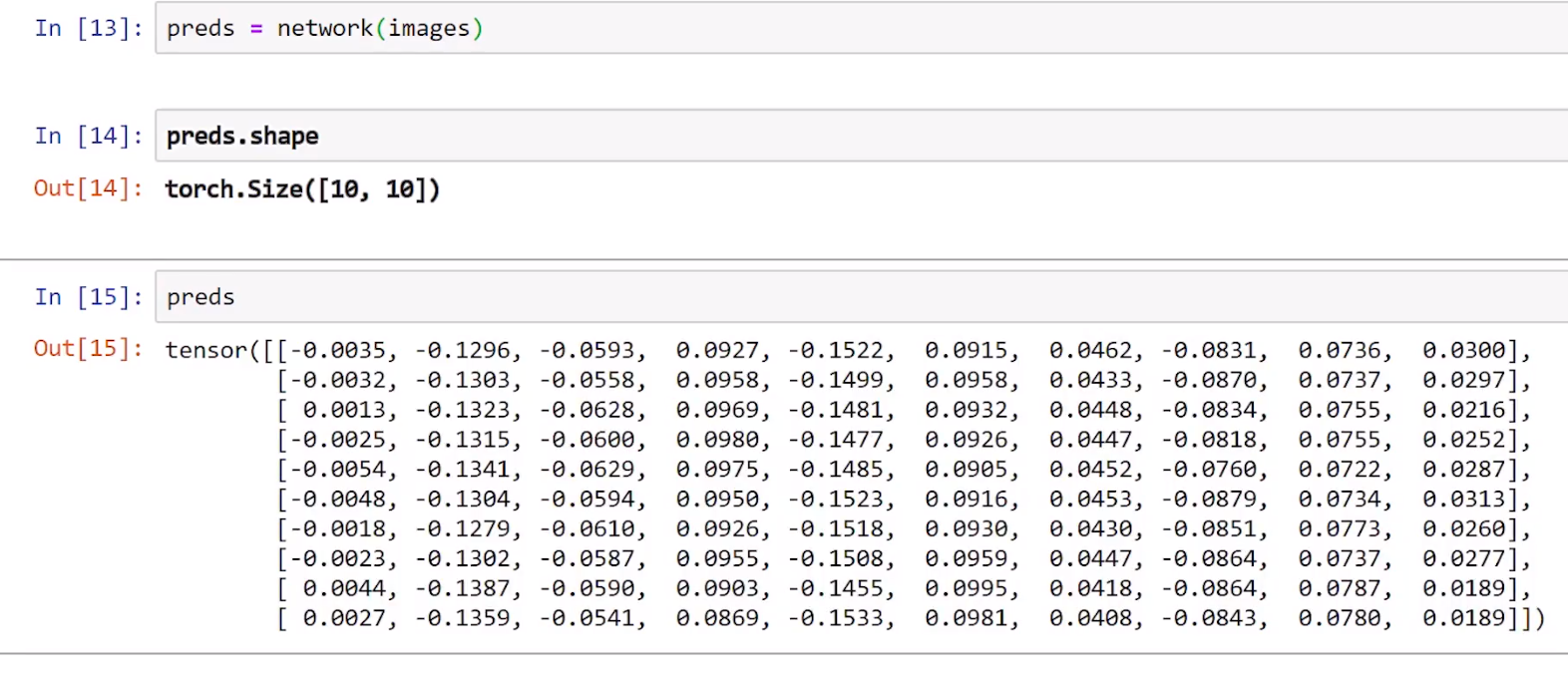
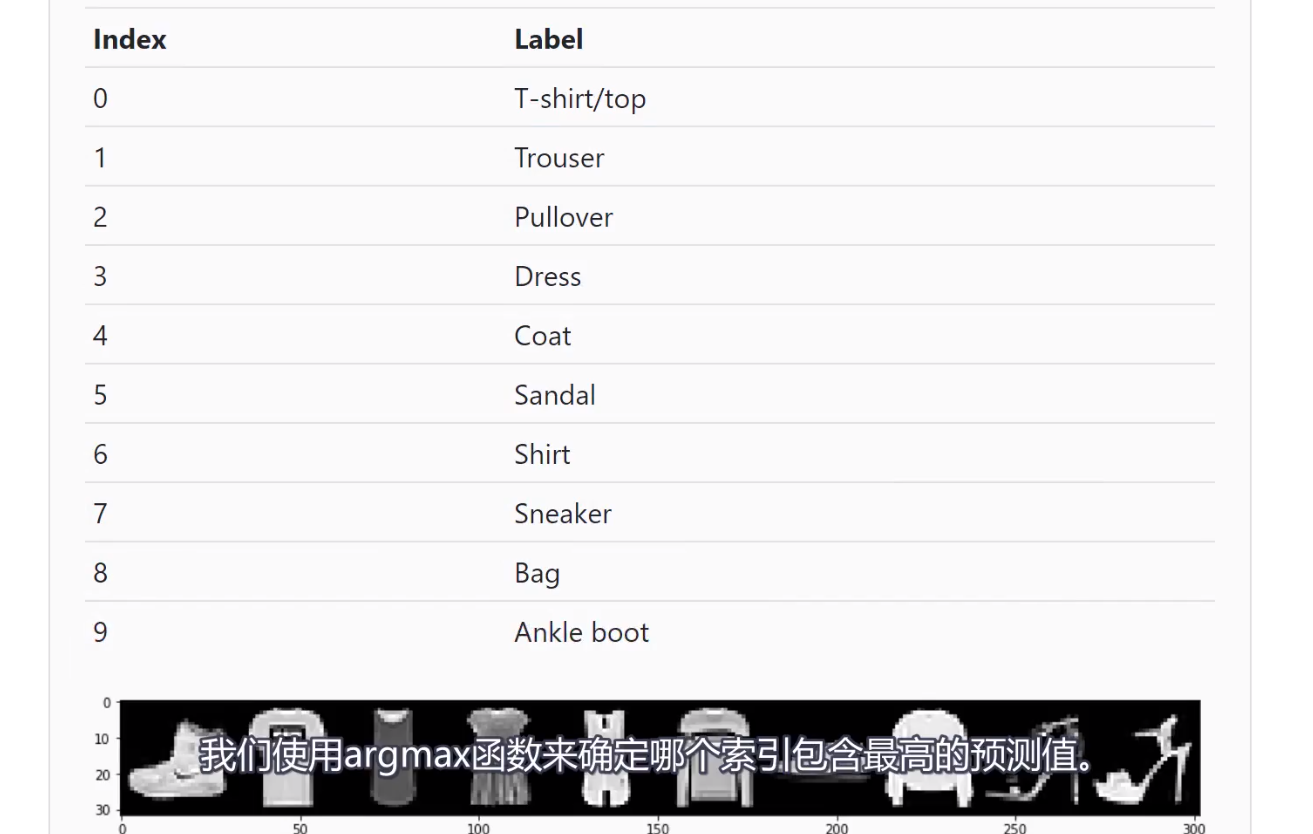


版本更迭导致的变动:tensor([0, 0, 0, 1, 0, 0, 0, 0, 1, 1], dtype=torch.uint8)已改为tensor([ False, False, False, True, False, False, False,False,True, True])

图像数值计算

1.卷积:(卷积后图像高)为(原图像高)-(卷积核高)+1,(卷积后图像高)为(原图像高)-(卷积核高)+1,(步长)=1。
2.池化:(池化后图像高)为(原图像高)/(池化核高),(池化后图像宽)为(原图像宽)/(池化核宽),(池化核高)=(池化核宽)=(步长)。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











