







1.GPU与CPU运算性能对比
在面对并行任务处理时,CPU与GPU的体系结构在设计理念上有着根本的区别。CPU注重通用性来处理各种不同的数据类型,同时支持复杂的控制指令,比如条件转移、分支、循环、逻辑判断及子程序调用等,因此 CPU微架构的复杂性高,是面向指令执行的高效率而设计的。GPU最初是针对图形处理领域而设计的。图形运算的特点是大量同类型数据的密集运算,因此GPU微架构是面向这种特点的计算而设计的。
设计理念的不同导致CPU和GPU在架构上相差甚远。CPU内核数量较少,常见的有4核和8核等,而GPU则由数以千计的更小、更高效的核心组成。这些核心专为同时处理多任务而设计,因此GPU也属于通常所说的众核处理器。多核CPU和众核GPU的架构对比如图1所示。
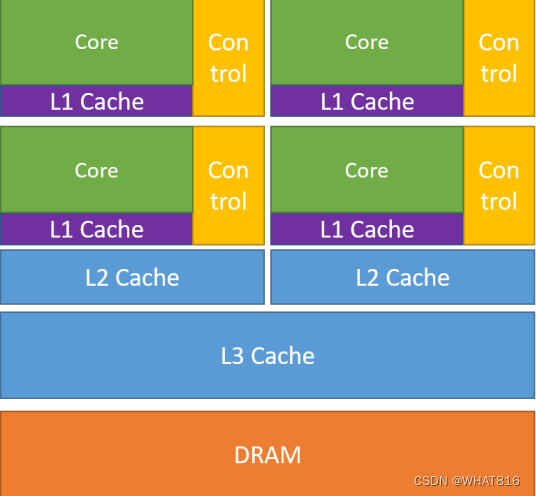
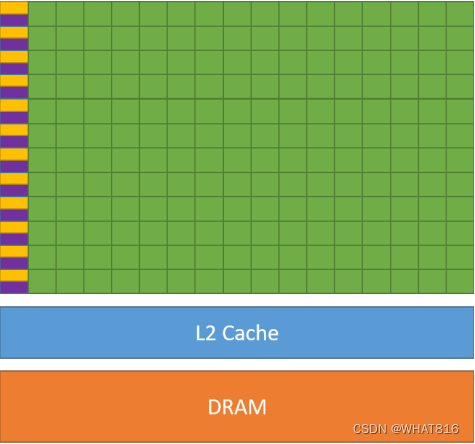
图1 多核CPU(左)和众核GPU(右)的架构对比
可以看到,CPU中大部分晶体管用于构建控制电路和存储单元,只有少部分的晶体管用来完成实际的运算工作,这使得CPU在大规模并行计算能力上极受限制,但更擅长逻辑控制,能够适应复杂的运算环境。由于CPU一般处理的是低延迟任务所以需要大量如图1所示的一级(L1)、二级(L2)、三级(L3)高速缓存(cache)空间来减少访问指令和数据时产生的延迟。CPU使用了大量缓存,一方面可以减少访问复杂应用程序的指令和数据时产生的延时,另一方面还能够节约带宽。但无论是缓存还是控制逻辑,都不利于提升峰值计算速度。
GPU的控制则相对简单,对高速缓存的需求相对较小,所以大部分品体管可以组成各类专用电路、多条流水线,使得GPU的计算能力有了突破性的飞跃。图形渲染的高度并行性,使得GPU可以通过简单增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。
2.GPU与CPU存储带宽对比
CPU的设计目标则是尽量缩短单个线程的执行时间。最后一级片上高速缓存通常有较大的容量,用于缓存经常访问的数据,缩短一些内存访问的延迟。算术单元和操作数传输逻辑也希望减少操作延迟,但更复杂的器件消耗了更多的芯片面积,同时带来了更大的功耗。通过减少单个线程内所有操作的延迟,CPU缩短了单个线程的执行时间。然而,大容量缓存、低延迟算术单元和高效的操作数传输逻辑消耗了大量的芯片面积和功耗,从而减少了算术运算单元和内存访问通道。这种设计风格通常被视为是面向延迟的设计。
到目前为止,GPU普遍都采用多线程来提升运算速度与吞吐量。通过支持流水化的存储器通道和允许较长的算术运算延迟,这种设计节省了大量的芯片面积和功耗。这样芯片可以通过增加器件提高整体吞吐量。
在执行多线程应用程序时,硬件可以充分利用因为等待访问内存或者算术运算而产生较长延时的大量线程,从而减少了控制逻辑中需要执行的线程,极大地简化了控制逻辑。小型缓存则可以满足应用程序中多线程对带宽的要求,访问相同内存数据的多个线程没必要全部访问DRAM存储器,而是从小型缓存中直接读取。这种设计风格通常被看成是面向吞吐量的设计,因为它不关注单个线程的执行时间,而是致力于最大限度地提高大量线程总的吞吐量。
GPU是并行的、面向吞吐量的计算部件,可能有些在CPU上能高效执行的任务在GPU上效率很低。对于只有一个或者几个线程的程序来说,操作延迟较低的CPU可以获得比GPU更高的性能。当程序包含大量线程时,具有较高执行吞吐量的GPU就能获得比CPU更高的性能。
因此,应该让大多数应用能充分利用CPU和GPU,在CPU上执行串行部分,而在 GPU上执行数据密集型计算。
参考文献:
1、大规模并行处理器编程实战(第2版)
2、通用图形处理器设计

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









