







卷积操作
卷积是一种在许多应用中使用的热门数组操作。它被用于图像处理、信号处理和机器学习。本文介绍1D卷积的CUDA实现,2D卷积请参考【CUDA】 2D卷积 2DConvolution
图1展示了一个卷积操作的示例:
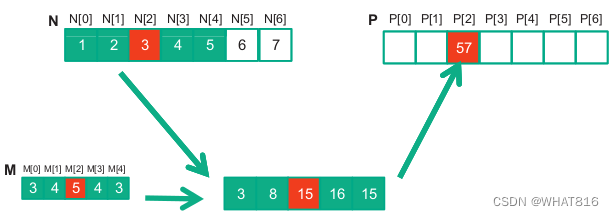
图1
基本方法、常数存储器、共享存储器和Caching
基本方法
在基本方法中,卷积是通过逐次访问数组并为每个元素计算卷积来计算的。这种方法很简单,但效率不高。原因在于卷积操作需要多次访问输入数组和mask (掩膜,卷积核,掩码)。
常量存储器
为了避免多次访问mask ,我们可以将mask 的元素存储到常量内存中。这将使硬件能够将mask 元素缓存到L2缓存内存中。这将大大减少全局内存访问,并提高kernel的性能。
共享存储器
共享存储器方法利用共享内存缓存输入数组。由于卷积操作多次访问相同的输入元素,我们可以将输入元素的块缓存到共享内存中,这样相邻的线程就不会从全局内存中加载相同的元素。
Caching
Caching处理方式是共享存储器处理方式的一个变种。唯一的区别是将halo(边角)元素如图2从全局内存中访问。我们之所以这样做是因为halo单元来自相邻块的内部单元。这意味着这些元素可能已经在L2缓存中找到,这将使我们再次避免全局内存访问的同时简化代码。
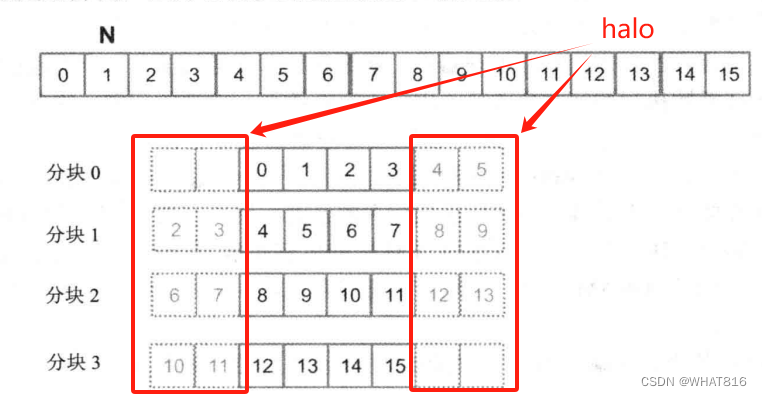
图2
以上四种方法再介绍完Code后分析访存差异。
Code
Host代码用随机值初始化输入向量和mask,并调用kernel执行1D卷积。
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include "Convolution1D.cuh"
#include "helper_cuda.h"
#include "error.cuh"
const double EPSILON = 1.0e-10;
const int FORTIME = 50;
void check_res(float* h_out, float* d_out, int img_w, std::string kernel_name) {
bool success = true;
for (int i = 0; i < img_w; ++i) {
if (fabs(h_out[i] - d_out[i]) > 0.001) {
std::cout << "Error at " << i << ": " << h_out[i] << " != " << d_out[i] << std::endl;
success = false;
}
}
std::cout << "Test (" << kernel_name << "): " << (success ? "PASSED" : "FAILED") << std::endl;
}
int main(void)
{
int img_w, mask_w, tile_w, mask_w_radius;
img_w = 4194304;
//img_w = 1024;
mask_w = 25;
tile_w = 1024;
mask_w_radius = mask_w / 2;
thrust::host_vector<float> h_img(img_w);
thrust::host_vector<float> h_mask(mask_w);
thrust::host_vector<float> h_out(img_w);
thrust::host_vector<float> h_dout(img_w);
srand(time(NULL));
for (int i = 0; i < img_w; ++i)
h_img[i] = (rand() % 256) / 255.0;
for (int i = 0; i < mask_w; ++i)
h_mask[i] = (rand() % 256) / 255.0 / (mask_w / 4.);
for (int i = 0; i < img_w; ++i) {
for (int m = 0; m < mask_w; ++m)
if (i + m - mask_w_radius >= 0 && i + m - mask_w_radius < img_w)
h_out[i] += h_img[i + m - mask_w_radius] * h_mask[m];
h_out[i] = clamp(h_out[i]);
}
thrust::device_vector<float> d_img = h_img;
thrust::device_vector<float> d_mask = h_mask;
thrust::device_vector<float> d_out(img_w);
int block_dim = tile_w;
int grid_dim = (img_w + block_dim - 1) / block_dim;
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_1D_basic_kernel <<<grid_dim, block_dim >>> (thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_mask.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_w, img_w);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
float elapsed_time;
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_w, std::string("Convolution 1D Basic Kernel"));
cudaMemcpyToSymbol(M, thrust::raw_pointer_cast(d_mask.data()), mask_w * sizeof(float));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_1D_constant_memory_kernel <<<grid_dim, block_dim >>> (thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_w, img_w);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_w, std::string("Convolution 1D Constant Memory Kernel"));
int shared_mem_size = (tile_w + mask_w - 1) * sizeof(float);
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_1D_tiled_kernel<<<grid_dim, block_dim, shared_mem_size>>> (
thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_w, img_w);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_w, std::string("Convolution 1D Tiled Kernel"));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_1D_tiled_caching_kernel <<<grid_dim, block_dim, block_dim * sizeof(float) >>> (
thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_w, img_w);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_w, std::string("Convolution 1D Tiled Caching Kernel"));
return 0;
}
Note:
helper_cuda.h 与error.cuh头文件为错误查验工具。后续会发布到Github。
去除checkCudaErrors等错误查验函数不影响程序运行。
使用的clamp宏是将卷积结果限制在0到1之间(包括0和1)。
#define clamp(x) (min(max((x), 0.0), 1.0))基本方法
__global__
void convolution_1D_basic_kernel(float *N, float *M, float *P, int mask_width, int width) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i >= width) return;
float Pvalue = 0;
int n_start_point = i - (mask_width / 2);
for (int j = 0; j < mask_width; ++j)
if (n_start_point + j >= 0 && n_start_point + j < width)
Pvalue += N[n_start_point + j] * M[j];
P[i] = clamp(Pvalue);
}kernel首先通过计算输入数组的起始索引来开始卷积操作。这是通过从当前索引减去mask 宽度的一半来完成的。
int n_start_point = i - (mask_width / 2);通过迭代地遍历mask 并将输入数组和mask 的乘积添加到输出数组中来计算卷积。
for (int j = 0; j < mask_width; ++j)
if (n_start_point + j >= 0 && n_start_point + j < width)
Pvalue += N[n_start_point + j] * M[j];最终结果被存储在输出数组中。
P[i] = clamp(Pvalue);Code可以观察出两点。第一,会出现控制流多样性。计算靠近输出矩阵P左边和右边的线程需要处理halo元素。因此,它们在if语句中将有不同的决策。计算P[0]的线程将跳过大约一半的乘法累加计算时间,而计算P[1]的线程将跳过一次乘加计算的时间,以此类推。控制多样性的开销取决于 Width 的大小、输入数组的大小和 MaskWidth(mask 数组的大小)。
对于大型输入数组和小型掩码数组,控制多样性仅会出现在很少一部分输出元素上,带来的影响也会很小。由于卷积经常运用在大型图像和空间数据上,通常希望多样性的影响是温和、微不足道的。
更为严重的问题是存储器带宽。kernel函数中浮点算术运算和全局存储器访问的比率仅为1.0。这个简单的kermel函数仅能发挥峰值性能很小的一部分。
常量存储器
核心代码与基本方法完全相同,但mask 存储在常量内存中,不作为参数传递给kernel函数。mask 的声明如下所示。
#define MAX_MASK_WIDTH A_NUMBER
__constant__ float M[MAX_MASK_WIDTH];Note:声明建议放在头文件kernel声明前。
__global__
void convolution_1D_constant_memory_kernel(float *N, float *P, int mask_width, int width) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float Pvalue = 0;
int n_start_point = i - (mask_width / 2);
for (int j = 0; j < mask_width; j++)
if (n_start_point + j >= 0 && n_start_point + j < width)
Pvalue += N[n_start_point + j] * M[j];
P[i] = clamp(Pvalue);
}卷积计算中用到的mask数组M,可以观察出3个有趣的现象。第一,M数组的尺寸通常都很小。大多数卷积mask数组在每个维度上都少于10个元素。即使是在三维卷积中,mask数组的元素个数通常也少于1000。第二,在kernel函数执行期间,数组M的内容不会改变。第三,所有线程需要访问mask数组元素。更好的是,所有线程访问都是以相同的顺序访问数组M,从M[0]开始,每次循环移动一个元素。这两个特性使得mask数组能够充分利用常量存储器和高速缓存。
与全局存储器变量一样,常量存储器变量同样存储在DRAM中。然而,由于CUDA运行时系统知道常数存储器变量在kernel函数执行期间不会改变,所以它会直接将常量存储器变量放到高速缓存中。
了解使用常量存储器的好处,需要现代处理器中存储器和高速缓存的层次结构的前置知识。请阅读后续博客。或者阅读《大规模并行处理器编程实战(第2版)》P152。
共享存储器
__global__
void convolution_1D_tiled_kernel(float *N, float *P, int mask_width, int width) {
extern __shared__ float N_ds[];
int i = blockIdx.x * blockDim.x + threadIdx.x;
int n = mask_width / 2;
int halo_index_left = (blockIdx.x - 1) * blockDim.x + threadIdx.x;
if (threadIdx.x >= blockDim.x - n)
N_ds[threadIdx.x - (blockDim.x - n)] = (halo_index_left < 0) ? 0 : N[halo_index_left];
N_ds[n + threadIdx.x] = N[blockIdx.x * blockDim.x + threadIdx.x];
int halo_index_right = (blockIdx.x + 1) * blockDim.x + threadIdx.x;
if (threadIdx.x < n)
N_ds[n + blockDim.x + threadIdx.x] = (halo_index_right >= width) ? 0 : N[halo_index_right];
__syncthreads();
float Pvalue = 0;
for (int j = 0; j < mask_width; j++)
Pvalue += N_ds[threadIdx.x + j] * M[j];
P[i] = clamp(Pvalue);
}kernel需要从前一块、下一块加载边界单元格,以及当前块的内部单元格,参考图2。首先计算前一块的边界单元格的索引。
int halo_index_left = (blockIdx.x - 1) * blockDim.x + threadIdx.x;最后n个线程会从前一个块的加载左边的halo元素,如图3:
if (threadIdx.x >= blockDim.x - n)
N_ds[threadIdx.x - (blockDim.x - n)] = (halo_index_left < 0) ? 0 : N[halo_index_left];
图3
所有线程将从当前块加载内部单元。
N_ds[n + threadIdx.x] = N[blockIdx.x * blockDim.x + threadIdx.x];下一个区块中halo元素的索引被计算。
int halo_index_right = (blockIdx.x + 1) * blockDim.x + threadIdx.x;前n线程将从下一个块中加载右边的halo元素,如图4:
if (threadIdx.x < n)
N_ds[n + blockDim.x + threadIdx.x] = (halo_index_right >= width) ? 0 : N[halo_index_right];
图4
共享内存同步,以确保所有线程都已加载数据。
__syncthreads();然后,通过遍历mask并将输入数组和掩码的乘积添加到输出数组中来计算卷积。
float Pvalue = 0;
for (int j = 0; j < mask_width; j++)
Pvalue += N_ds[threadIdx.x + j] * M[j];最终结果存储在输出数组中。
P[i] = clamp(Pvalue);分块1D维卷积算法的kernel函数明显要比基本kernel函数更长、更复杂。通过引进额外的复杂性减少了对数组N的DRAM的访问次数。最终目标是提高算术运算和访存之间的比率,使获得的性能不再受限于或部分受限于DRAM的带宽。
kernel中,存在两种情况。
1、对于那些不处理halo元素的线程块来说,每个线程访问数组N的次数是MaskWidth。这样,每个线程块访问数组的总次数是blockDim.x*MaskWidth 或者 blockDim.x*(2n+1)。n为MaskWidth/2取整。
例如,如果 MaskWidth等于5,每个线程块含有1024个线程,则每个线程块总共访问5120次。
2、对于第一个和最后一个线程块中需要处理halo元素的线程来说,不存在对halo元素的访存操作。这减少了访存操作的次数。通过枚举每个halo元素被使用的线程个数,便能计算出减少的访存次数。
对于内部线程块来说,基本算法与共享存储器卷积算法的访存次数的比值是:
(blockDim.x * (2n + 1))/(blockDim.x + 2n)
而边界线程块的比值为:
(blockDim.x * (2n + 1) - n (n + 1) / 2) / (blockDim.x + n)
在大多数情况下,blockDim.x的值比n大得多。两个比率可以通过消除小项n(n+1)/2和n而得到近似值:
(blockDim.x * (2n + 1) / blockDim.x = 2n + 1 = MaskWidth
这是一个很直观的结果。在基础算法中,每个数组N元素大约被MaskWidth个线程冗余加载。也就是说,访存减少的比率大致与掩码数组的大小成正比。
然而,在实践中,比值表达式中较小的项可能是显著的,并且不能被忽略。例如,如果blockDim.x为128、n为5,则内部线程块的比率为:
(128 * 11 - 10) / (128 + 10) = 1398 / 138 = 10.13
而比率约为11。应该清楚的是,如果blockDim.x的值变小,比率也会变小。例如,如果blockDim为32、n为5,则内部线程块的比率变为:
(32 * 11 - 10) / (32 + 10) = 8.14
在使用较小线程块和分块时应该小心。较小的尺寸带来的访存减少比率可能会大大低于预期。在实践中,较小的分块尺寸经常用在片上存储器容量不足的情况下,特别是在计算二维和三维卷积时,对片上存储器的需求随着分块尺寸的增长而快速增长的情况下。
Caching
__global__
void convolution_1D_tiled_caching_kernel(float *N, float *P, int mask_width, int width) {
extern __shared__ float N_ds[];
int i = blockIdx.x * blockDim.x + threadIdx.x;
N_ds[threadIdx.x] = N[i];
__syncthreads();
int this_tile_start_point = blockIdx.x * blockDim.x;
int next_tile_start_point = (blockIdx.x + 1) * blockDim.x;
int n_start_point = i - (mask_width / 2);
float Pvalue = 0;
for (int j = 0; j < mask_width; j++) {
int n_index = n_start_point + j;
if (n_index >= 0 && n_index < width) {
if ((n_index >= this_tile_start_point) && (n_index < next_tile_start_point))
Pvalue += N_ds[threadIdx.x + j - (mask_width / 2)] * M[j];
else
Pvalue += N[n_index] * M[j];
}
}
P[i] = clamp(Pvalue);
}kernel首先将当前块中的元素加载到共享内存中。
N_ds[threadIdx.x] = N[i];
__syncthreads();当前区块的起始点和下一个区块的起始点被计算出来。
int this_tile_start_point = blockIdx.x * blockDim.x;
int next_tile_start_point = (blockIdx.x + 1) * blockDim.x;输入数组的起点被计算。
int n_start_point = i - (mask_width / 2);卷积是通过检查加载是否来自当前块或相邻块(以加载边界单元)来计算的。
1、如果加载来自当前块,则从共享内存加载元素。
2、如果加载来自相邻块,则从全局内存加载元素(希望是从 L2 缓存加载)。
float Pvalue = 0;
for (int j = 0; j < mask_width; j++) {
int n_index = n_start_point + j;
if (n_index >= 0 && n_index < width) {
if ((n_index >= this_tile_start_point) && (n_index < next_tile_start_point))
Pvalue += N_ds[threadIdx.x + j - (mask_width / 2)] * M[j];
else
Pvalue += N[n_index] * M[j];
}
}最终结果被存储在输出数组中。
P[i] = clamp(Pvalue);共享存储器Code的大部分复杂度都集中在加载除了中间元素之外的左侧和右侧的halo元素到共享内存中。GPU存储结构,提供了通用L1和L2高速缓存,L1缓存是每个SM私有的,而L2缓存是所有SM共享的。线程块可利用这样一个事实:它们的halo元素可能存放在 L2 缓存中。
一个线程块的halo元素也是邻近线程块的内部元素。因此,很有可能在线程块1需要这些halo元素的时候,它们由于线程块0的访问而已经存储到L2缓存上。这样,对这些halo元素的访问将转化为对L2缓存的访问,减少了对DRAM的访问。Caching Code 的halo元素可以直接访问原始的数组N,而不是将它们加载到共享存储器数组Nds中。
性能分析
运行时间:
向量维度:4194304
线程块维度:1024
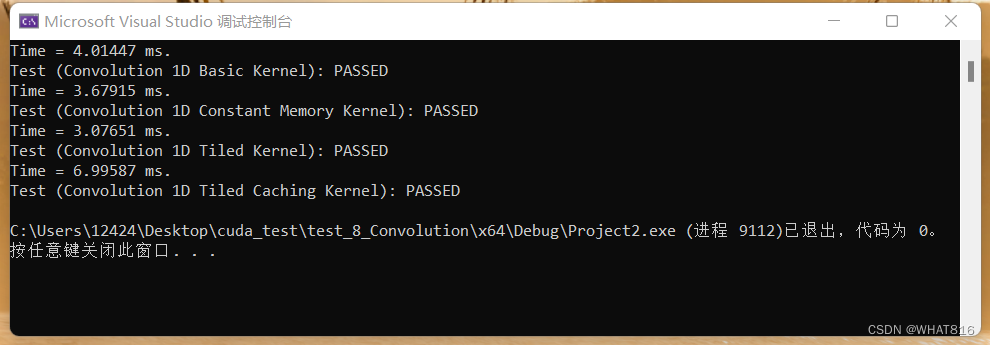
根据运行时间分析,前三种算法相差明显。但Caching算法效果不佳可能是因为虽然单一线程访问halo元素时满足Cache,但是从SIMT角度并不满足合并访存(合并访存概念请阅读博客【CUDA】 矩阵加法 Matrix Addition)。
但在共享内存的方法中,在加载输入数组时需要额外的复杂性来检查边界条件,线程之间的同步也会减慢核心速度。
Note:单次运行可能因为设备启动原因,各种算法运行时间差异较大,可采用循环20次以上取平均值。
笔者采用设备:RTX3060 6GB
PMPP项目提供的分析:
kernel的性能是使用NvBench项目在多个gpu中测量的。研究的性能测量方法有:
内存带宽:每秒传输的数据量。
内存带宽利用率:占用内存带宽的百分比。
基础方法:
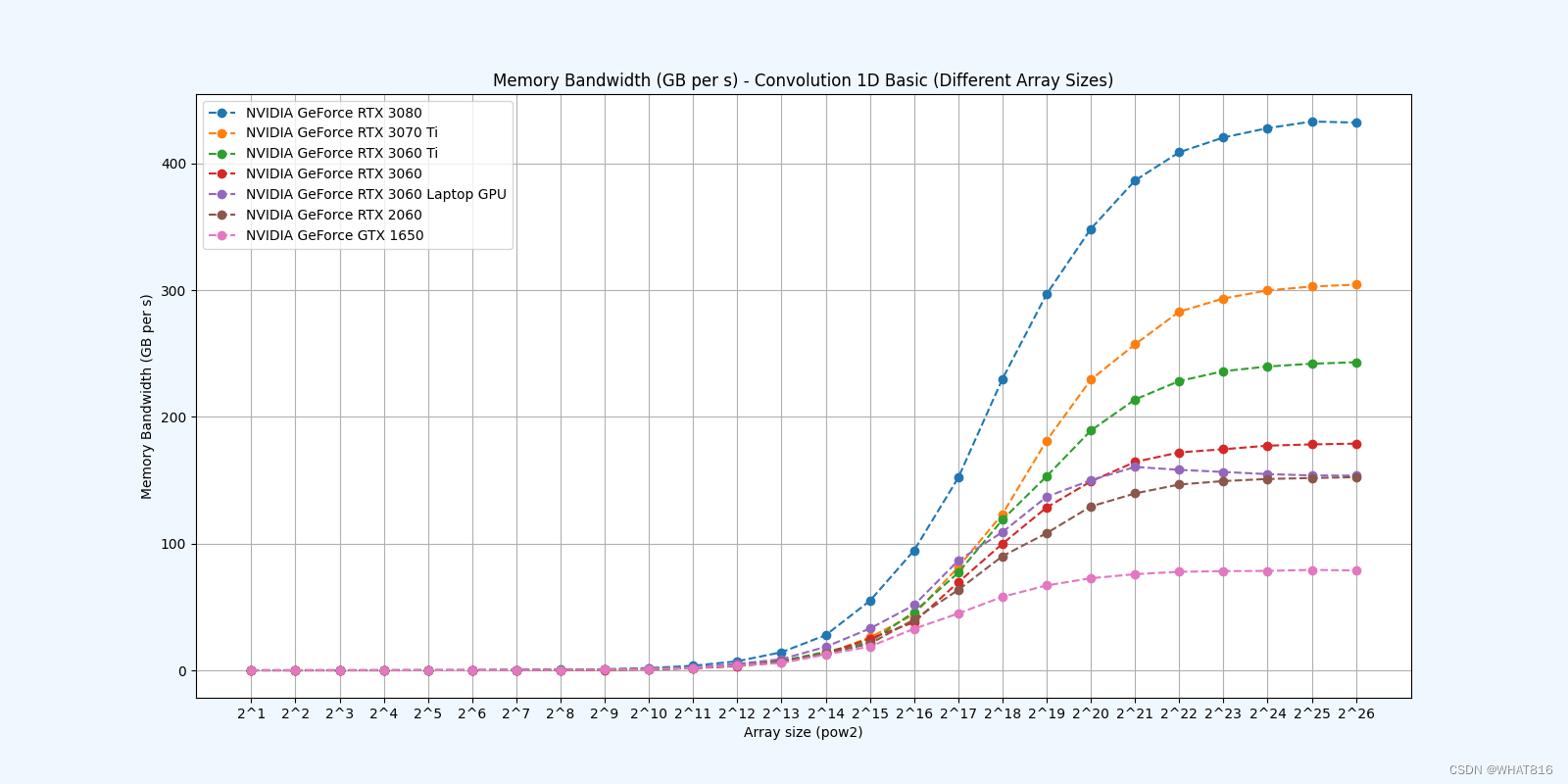
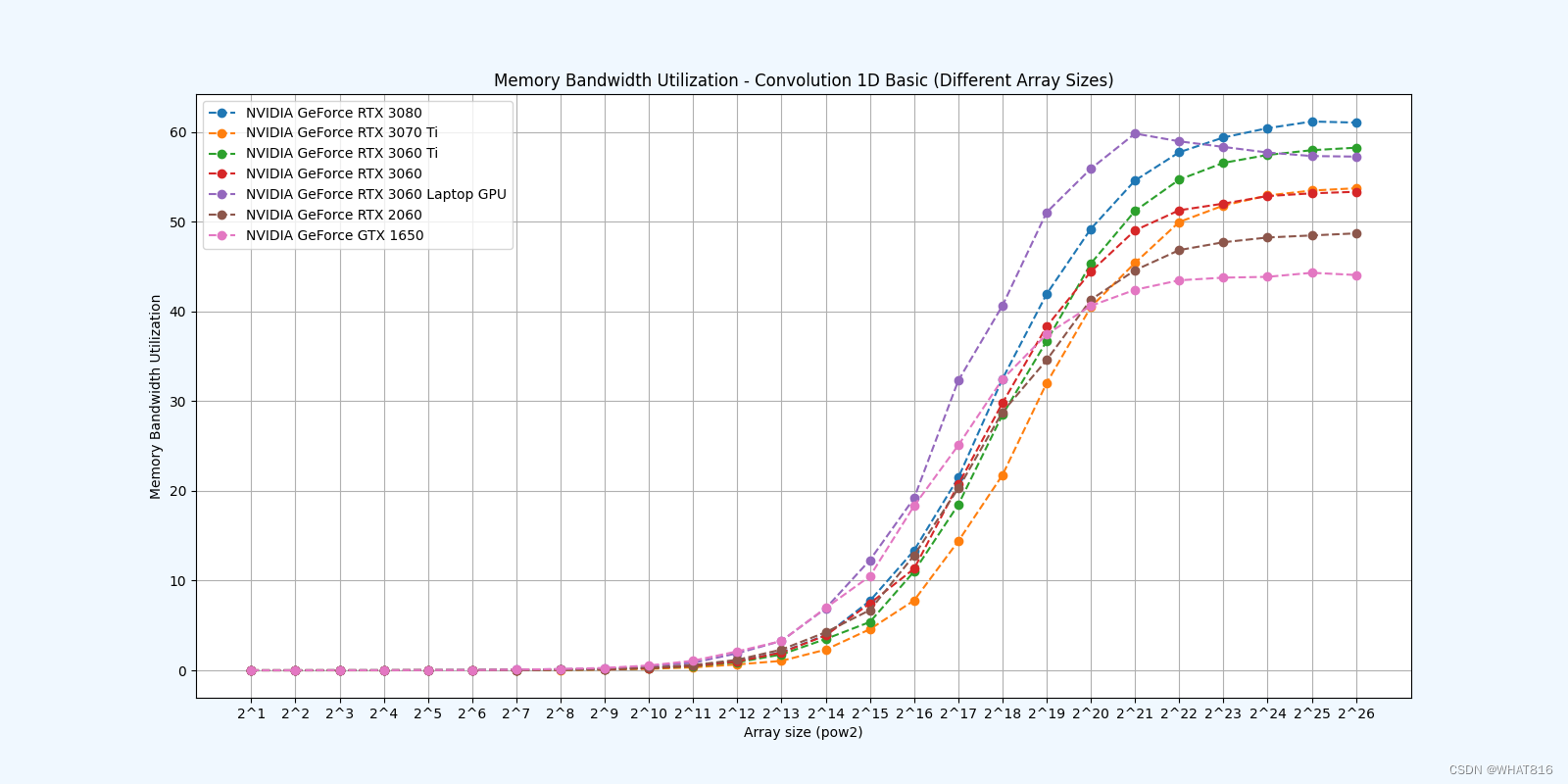
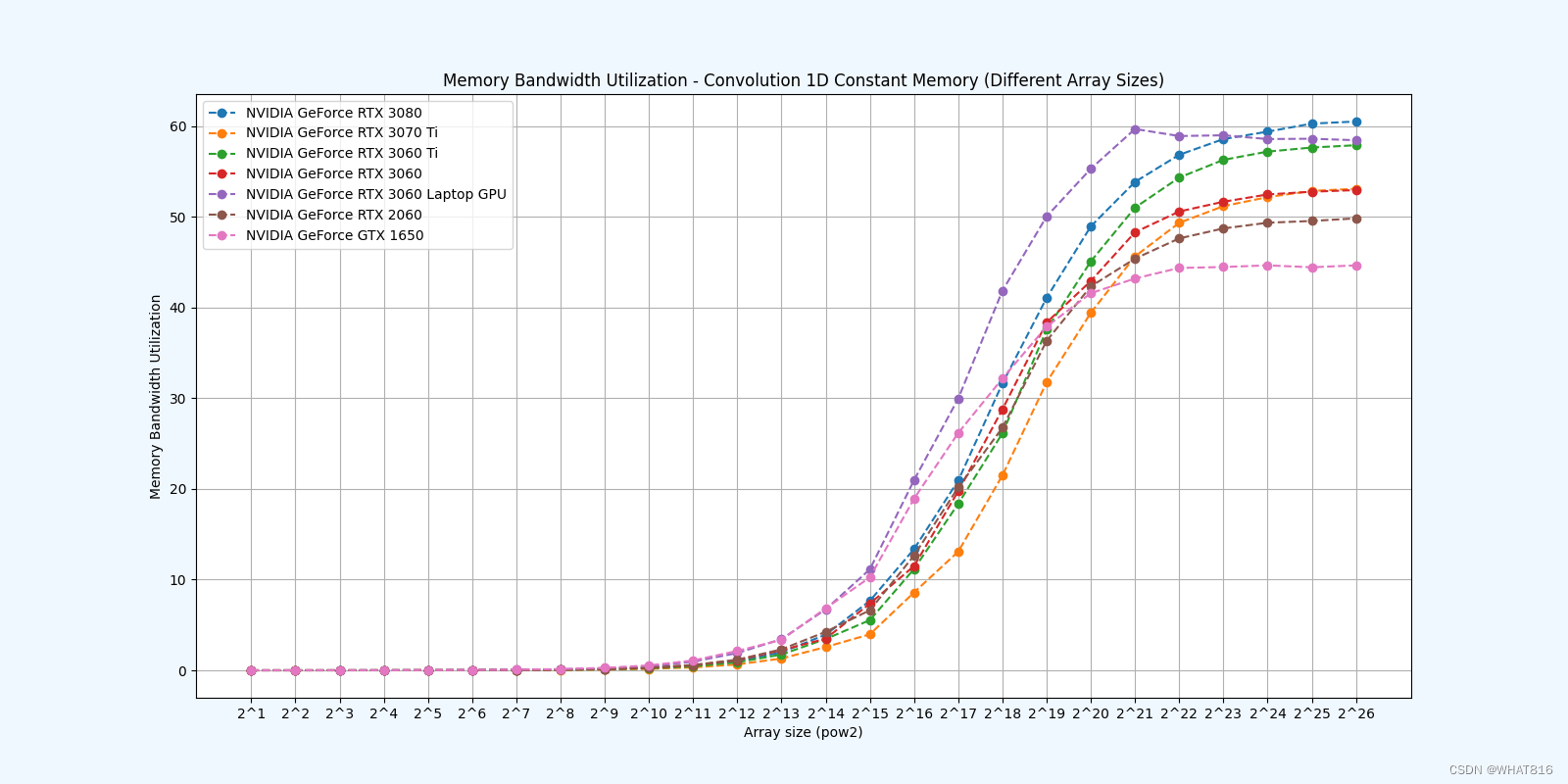
常量存储器

共享存储器
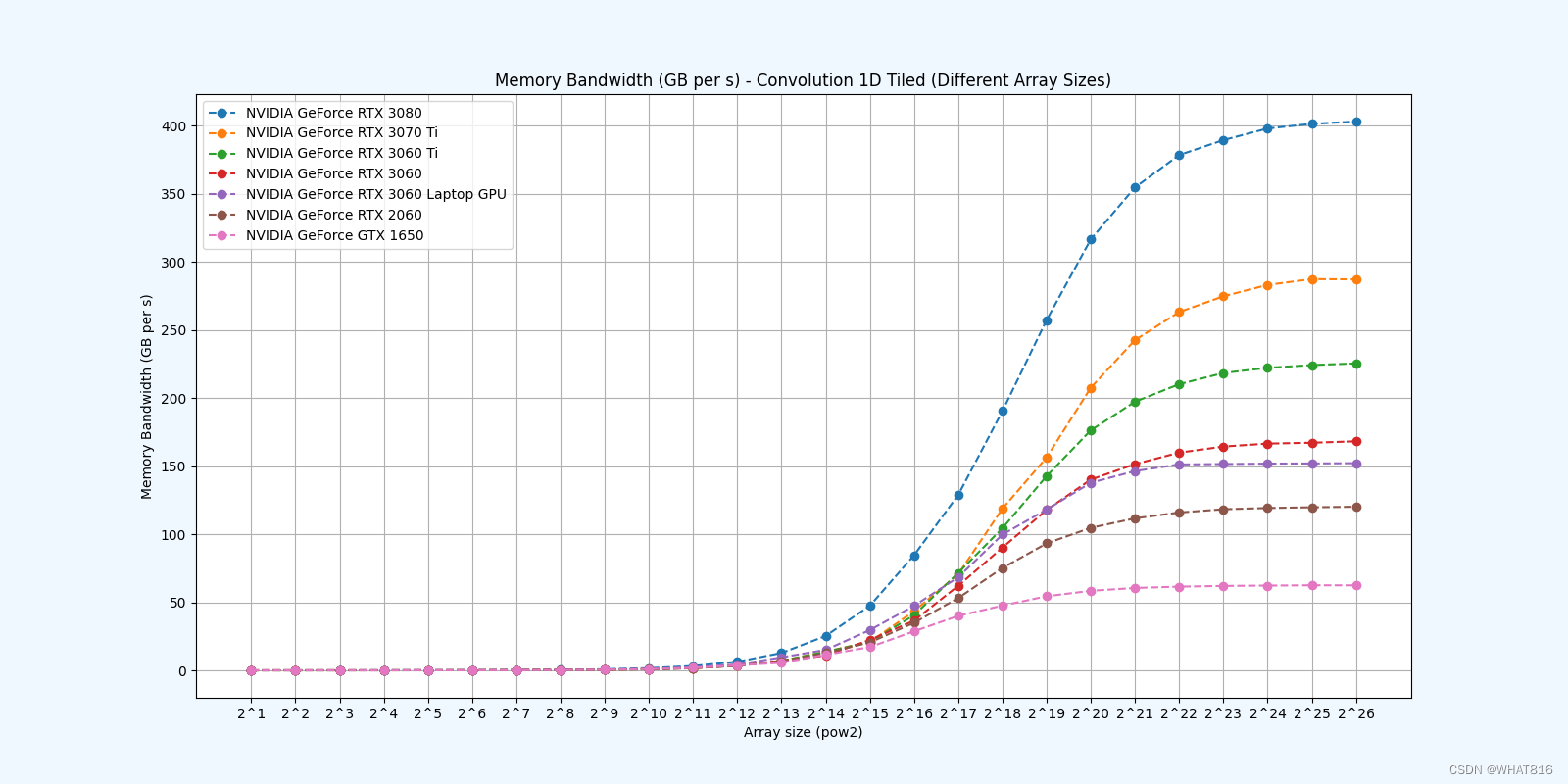
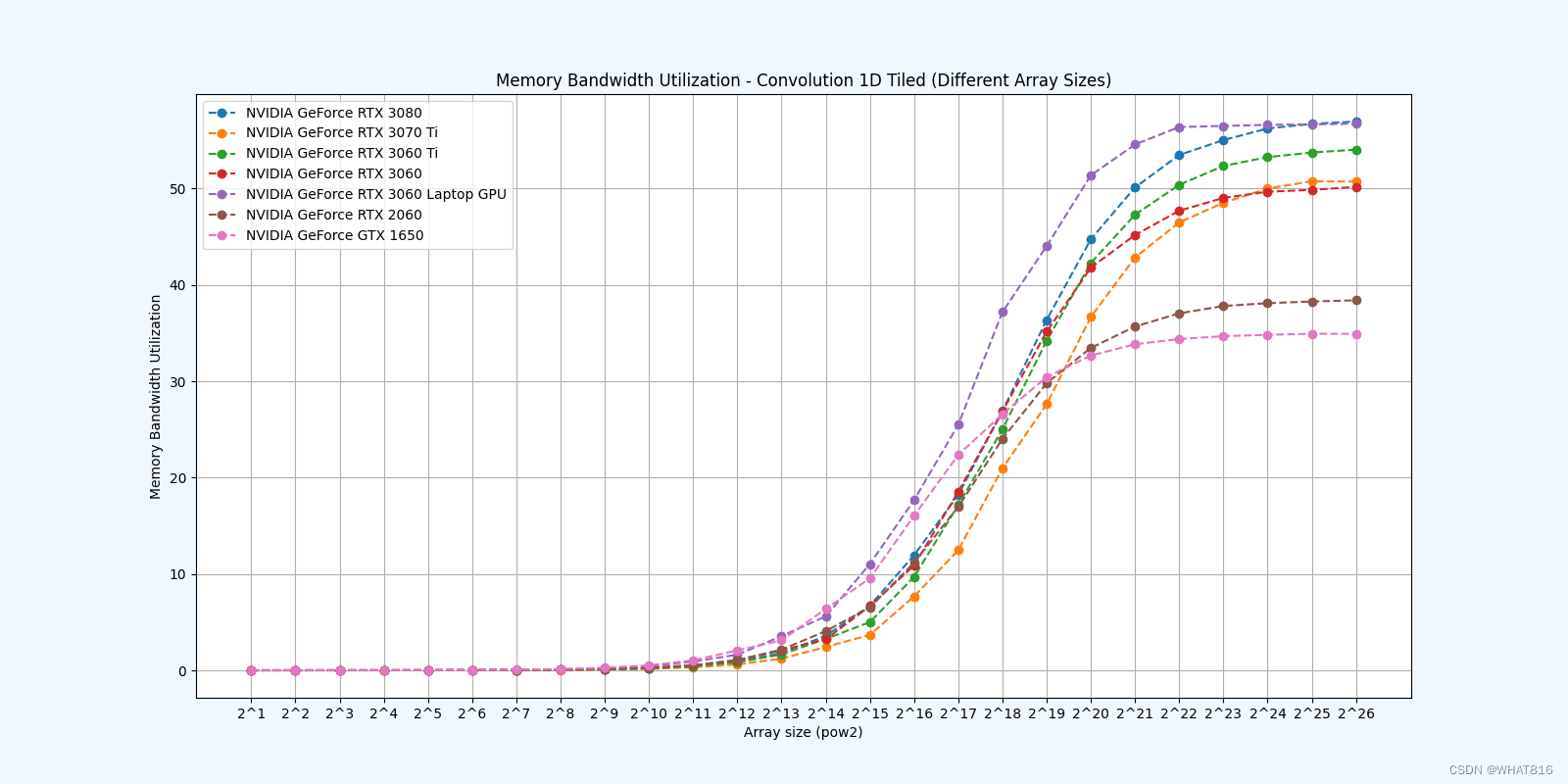
Caching
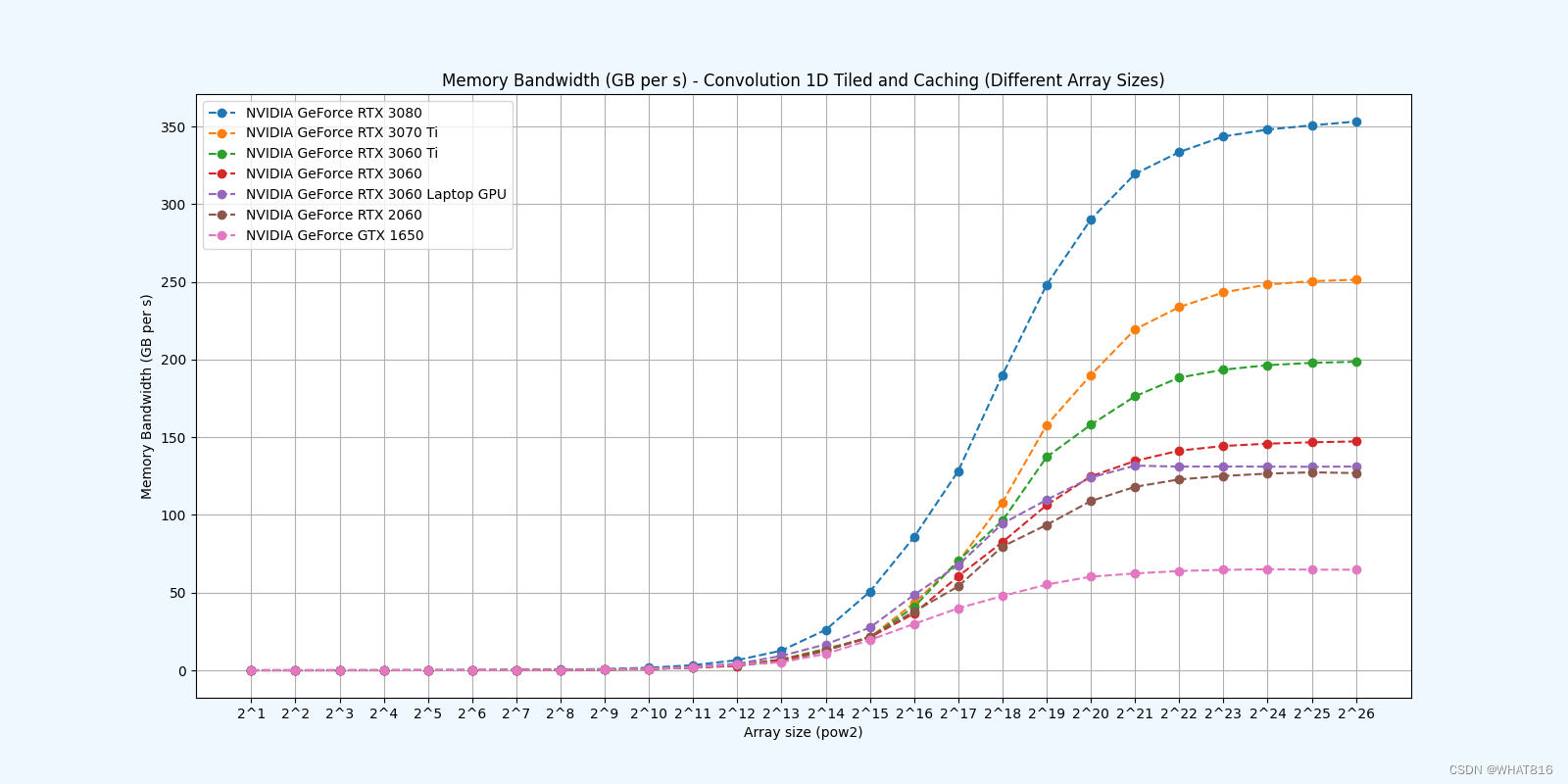
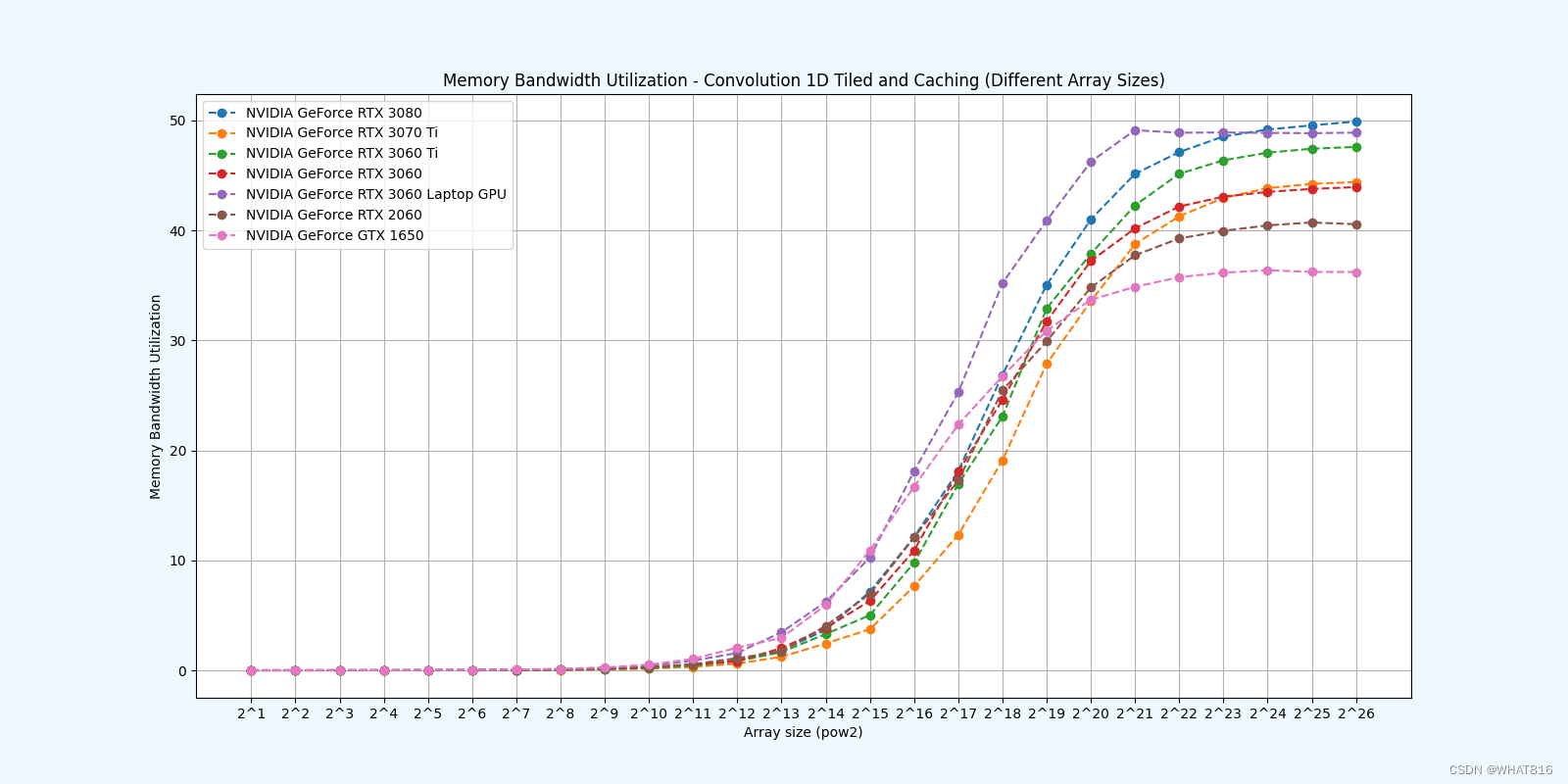
参考文献:
1、大规模并行处理器编程实战(第2版)
2、PPMP

















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









