







在深度学习中,卷积层是许多深度神经网络的主要构建块。该设计的灵感来自视觉皮层,其中单个神经元对视野的受限区域(称为感受野)做出反应。这些区域的集合重叠以覆盖整个可见区域。
虽然卷积层最初应用于计算机视觉,但其平移不变特性使卷积层可以应用于自然语言处理、时间序列、推荐系统和信号处理。
理解卷积的最简单方法是将其视为应用于矩阵的滑动窗口函数。本文将了解一维卷积的工作原理并探讨每个参数的影响。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、卷积是如何工作的?(核大小 = 1)
卷积(convolution)是一种线性运算,涉及将权重与输入相乘并产生输出。乘法是在输入数据数组和权重数组 — 称为核(kernel)—之间执行的。在输入和核之间应用的运算是元素点积的总和。每个运算的结果都是一个值。
让我们从最简单的示例开始,当你拥有 1D 数据时使用 1D 卷积。对 1D 数组应用卷积会将核中的值与输入向量中的每个值相乘。
假设核中的值(也称为“权重”)为“2”,我们将输入向量中的每个元素逐个乘以 2,直到输入向量的末尾,并得到输出向量。输出向量的大小与输入的大小相同。
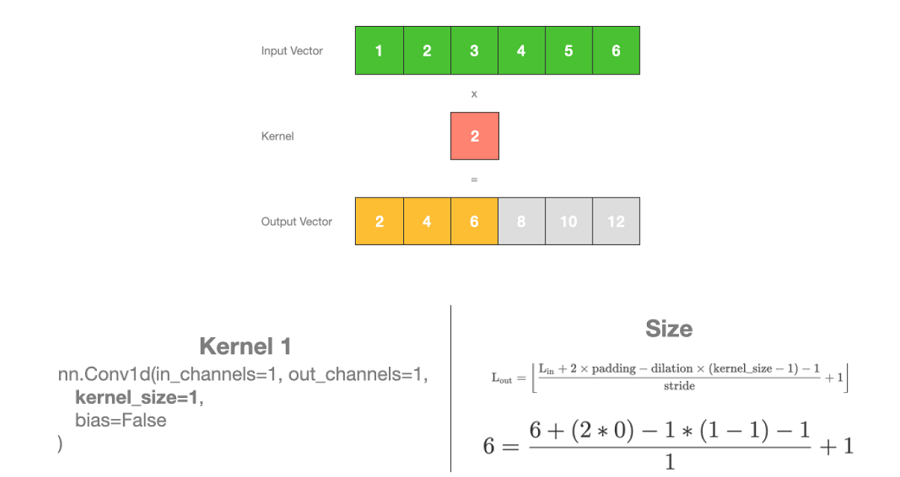
首先,我们将 1 乘以权重 2,得到第一个元素的值为“2”。然后我们将核移动 1 步,将 2 乘以权重 2,得到“4”。我们重复此操作直到最后一个元素 6,然后将 6 乘以权重,得到“12”。此过程生成输出向量。
class TestConv1d(nn.Module):
def __init__(self):
super(TestConv1d, self).__init__()
self.conv = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=1, bias=False)
self.init_weights()
def forward(self, x):
return self.conv(x)
def init_weights(self):
self.conv.weight[0,0,0] = 2.
in_x = torch.tensor([[[1,2,3,4,5,6]]]).float()
print("in_x.shape", in_x.shape)
print(in_x)
net = TestConv1d()
out_y = net(in_x)
print("out_y.shape", out_y.shape)
print(out_y)输入如下:
in_x.shape torch.Size([1, 1, 6])
tensor([[[1., 2., 3., 4., 5., 6.]]])
out_y.shape torch.Size([1, 1, 6])
tensor([[[ 2., 4., 6., 8., 10., 12.]]], grad_fn=<SqueezeBackward1>)2、核大小的影响(核大小 = 2)
不同大小的核将检测输入中不同大小的特征,进而产生不同大小的特征图(feature map)。让我们看另一个示例,其中核大小为 1x2,权重为“2”。像以前一样,我们将核滑过输入向量的每个元素。我们通过将每个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8601
8601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









