







2D卷积本文介绍基本方法、常量存储器、共享存储器三种方法。具体3种方法的访存差异与上篇博客介绍的原理一致,在此不多赘述,可参考【CUDA】 1D卷积 1D Convolution
Code
Host代码用随机值初始化输入矩阵和mask,并调用kernel执行2D卷积。
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include "Convolution2D.cuh"
#include "helper_cuda.h"
#include "error.cuh"
const int FORTIME = 50;
void check_res(float* h_out, float* d_out, int img_w, std::string kernel_name) {
bool success = true;
for (int i = 0; i < img_w; ++i) {
if (fabs(h_out[i] - d_out[i]) > 0.001) {
std::cout << "Error at " << i << ": " << h_out[i] << " != " << d_out[i] << std::endl;
success = false;
break;
}
}
std::cout << "Test (" << kernel_name << "): " << (success ? "PASSED" : "FAILED") << std::endl;
}
int main(void) {
int img_h, img_w, img_c, mask_h, mask_w, tile_w, mask_h_radius, mask_w_radius;
img_h = 1024;
img_w = 1024;
img_c = 3;
mask_h = 11;
mask_w = 11;
tile_w = 32;
mask_h_radius = mask_h / 2;
mask_w_radius = mask_w / 2;
thrust::host_vector<float> h_img(img_h * img_w * img_c);
thrust::host_vector<float> h_mask(mask_h * mask_w);
thrust::host_vector<float> h_out(img_h * img_w * img_c);
thrust::host_vector<float> h_dout(img_h * img_w * img_c);
srand(time(NULL));
for (int i = 0; i < img_h * img_w * img_c; ++i)
h_img[i] = (rand() % 256) / 255.0;
for (int i = 0; i < mask_h * mask_w; ++i)
h_mask[i] = (rand() % 256) / 255.0 / (mask_h * mask_w / 4.);
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < img_c; ++i)
for (int j = 0; j < img_h; ++j)
for (int k = 0; k < img_w; ++k) {
for (int l = 0; l < mask_h; ++l)
for (int m = 0; m < mask_w; ++m)
if (j + l - mask_h_radius >= 0 && j + l - mask_h_radius < img_h && k + m - mask_w_radius >= 0 && k + m - mask_w_radius < img_w)
h_out[j * img_w * img_c + k * img_c + i] += h_img[(j + l - mask_h_radius) * img_w * img_c + (k + m - mask_w_radius) * img_c + i] * h_mask[l * mask_w + m];
h_out[j * img_w * img_c + k * img_c + i] = clamp(h_out[j * img_w * img_c + k * img_c + i]);
}
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
float elapsed_time;
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("CPU Time = %g ms.\n", elapsed_time);
thrust::device_vector<float> d_img = h_img;
thrust::device_vector<float> d_mask = h_mask;
thrust::device_vector<float> d_out(img_h * img_w * img_c);
cudaMemcpyToSymbol(M, thrust::raw_pointer_cast(d_mask.data()), mask_h * mask_w * sizeof(float));
dim3 block_dim(tile_w, tile_w);
dim3 grid_dim((img_w + block_dim.x - 1) / block_dim.x, (img_h + block_dim.y + 1) / block_dim.y);
//cudaEvent_t start, stop;
//checkCudaErrors(cudaEventCreate(&start));
//checkCudaErrors(cudaEventCreate(&stop));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_2D_basic_kernel <<< grid_dim, block_dim >>> (
thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_mask.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_h, mask_w, img_h, img_w, img_c);
}
cudaDeviceSynchronize();
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
//float elapsed_time;
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()), thrust::raw_pointer_cast(h_dout.data()), img_h * img_w * img_c, "Convolution 2D Basic Kernel");
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_2D_constant_memory_kernel <<<grid_dim, block_dim >>> (
thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_h, mask_w, img_h, img_w, img_c);
}
cudaDeviceSynchronize();
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_h * img_w * img_c, "Convolution 2D Constant Memory Kernel");
//(block_dim.x - mask_w + 1)每个线程块计算的元素个数。
grid_dim = dim3((img_w + block_dim.x - mask_w) / (block_dim.x - mask_w + 1),
(img_h + block_dim.y - mask_h) / (block_dim.y - mask_h + 1));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++) {
convolution_2D_tiled_kernel <<<grid_dim, block_dim, block_dim.y* block_dim.x * sizeof(float) >>> (
thrust::raw_pointer_cast(d_img.data()),
thrust::raw_pointer_cast(d_out.data()),
mask_h, mask_w, img_h, img_w, img_c);
}
cudaDeviceSynchronize();
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time / FORTIME);
h_dout = d_out;
check_res(thrust::raw_pointer_cast(h_out.data()),
thrust::raw_pointer_cast(h_dout.data()),
img_h * img_w * img_c, "Convolution 2D Tiled Kernel");
return 0;
}Note:
helper_cuda.h 与error.cuh头文件为错误查验工具。后续会发布到Github。
去除checkCudaErrors等错误查验函数不影响程序运行。
基本方法
__global__
void convolution_2D_basic_kernel(float *N, float *M, float *P,
int mask_height, int mask_width,
int height, int width, int channels) {
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if(i >= height || j >= width) return;
int ni_start_point = i - (mask_height / 2);
int nj_start_point = j - (mask_width / 2);
for(int c = 0; c < channels; ++c){
float Pvalue = 0;
for(int k = 0; k < mask_height; ++k)
for(int l = 0; l < mask_width; ++l)
if (ni_start_point + k >= 0 && ni_start_point + k < height &&
nj_start_point + l >= 0 && nj_start_point + l < width)
Pvalue += N[((ni_start_point + k) * width + nj_start_point + l) * channels + c] * M[k * mask_width + l];
P[(i * width + j) * channels + c] = clamp(Pvalue);
}
}2D kernel的逻辑与1D内核类似。唯一的区别是数组是2D的,具有多个通道。mask是2D的,卷积操作针对每个通道计算。
kernel首先计算输入数组的两个维度的起始点。
int ni_start_point = i - (mask_height / 2);
int nj_start_point = j - (mask_width / 2);然后通过迭代遍历mask来计算卷积,将输入数组和mask的乘积添加到输出数组中,每个通道都存储在输出数组中。
for(int c = 0; c < channels; ++c){
float Pvalue = 0;
for(int k = 0; k < mask_height; ++k)
for(int l = 0; l < mask_width; ++l)
if (ni_start_point + k >= 0 && ni_start_point + k < height &&
nj_start_point + l >= 0 && nj_start_point + l < width)
Pvalue += N[((ni_start_point + k) * width + nj_start_point + l) * channels + c] * M[k * mask_width + l];
P[(i * width + j) * channels + c] = clamp(Pvalue);
}常量存储器
kernel代码与基本方法完全相同,但mask存储在常量内存中,而不是作为参数传递给kernel。mask的声明如下所示:
#define MAX_MASK_WIDTH A_NUMBER
__constant__ float M[MAX_MASK_WIDTH];
__global__
void convolution_2D_constant_memory_kernel(float *N, float *P,
int mask_height, int mask_width,
int height, int width, int channels) {
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if(i >= height || j >= width) return;
int ni_start_point = i - (mask_height / 2);
int nj_start_point = j - (mask_width / 2);
for(int c = 0; c < channels; ++c){
float Pvalue = 0;
for(int k = 0; k < mask_height; ++k)
for(int l = 0; l < mask_width; ++l)
if (ni_start_point + k >= 0 && ni_start_point + k < height &&
nj_start_point + l >= 0 && nj_start_point + l < width)
Pvalue += N[((ni_start_point + k) * width + nj_start_point + l) * channels + c] * M[k * mask_width + l];
P[(i * width + j) * channels + c] = clamp(Pvalue);
}
}共享存储器
__global__
void convolution_2D_tiled_kernel(float *N, float *P,
int mask_height, int mask_width,
int height, int width, int channels) {
extern __shared__ float N_ds[];
int O_TILE_HEIGHT = blockDim.y - mask_height + 1;
int O_TILE_WIDTH = blockDim.x - mask_width + 1;
int ty = threadIdx.y;
int tx = threadIdx.x;
int row_o = blockIdx.y * O_TILE_HEIGHT + ty;
int col_o = blockIdx.x * O_TILE_WIDTH + tx;
int row_i = row_o - (mask_height / 2);
int col_i = col_o - (mask_width / 2);
for(int c = 0; c < channels; ++c){
if(row_i >= 0 && row_i < height && col_i >= 0 && col_i < width)
N_ds[ty * blockDim.x + tx] = N[(row_i * width + col_i) * channels + c];
else
N_ds[ty * blockDim.x + tx] = 0;
__syncthreads();
float Pvalue = 0;
if(ty < O_TILE_HEIGHT && tx < O_TILE_WIDTH && row_o < height && col_o < width) {
for(int k = 0; k < mask_height; ++k)
for(int l = 0; l < mask_width; ++l)
Pvalue += N_ds[(ty + k) * blockDim.x + tx + l] * M[k * mask_width + l];
P[(row_o * width + col_o) * channels + c] = clamp(Pvalue);
}
__syncthreads();
}
}在这个kernel中,块维度等于mask维度。 首先计算输出输出矩阵的尺寸。
int O_TILE_HEIGHT = blockDim.y - mask_height + 1;
int O_TILE_WIDTH = blockDim.x - mask_width + 1;然后计算输出矩阵的行和列
int row_o = blockIdx.y * O_TILE_HEIGHT + ty;
int col_o = blockIdx.x * O_TILE_WIDTH + tx;计算输入矩阵的行和列。
int row_i = row_o - (mask_height / 2);
int col_i = col_o - (mask_width / 2);对于每个通道,首先将输入图块加载到共享内存中。
if(row_i >= 0 && row_i < height && col_i >= 0 && col_i < width)
N_ds[ty * blockDim.x + tx] = N[(row_i * width + col_i) * channels + c];
else
N_ds[ty * blockDim.x + tx] = 0;然后,卷积仅由位于输出矩阵内部的线程计算,并将结果存储在输出数组中。
if(ty < O_TILE_HEIGHT && tx < O_TILE_WIDTH && row_o < height && col_o < width) {
for(int k = 0; k < mask_height; ++k)
for(int l = 0; l < mask_width; ++l)
Pvalue += N_ds[(ty + k) * blockDim.x + tx + l] * M[k * mask_width + l];
P[(row_o * width + col_o) * channels + c] = clamp(Pvalue);
}性能分析
运行时间:
矩阵维度:1024 × 1024
mask维度:按图片顺序 5 × 5 、7 × 7 、11 × 11
线程块维度:32 × 32
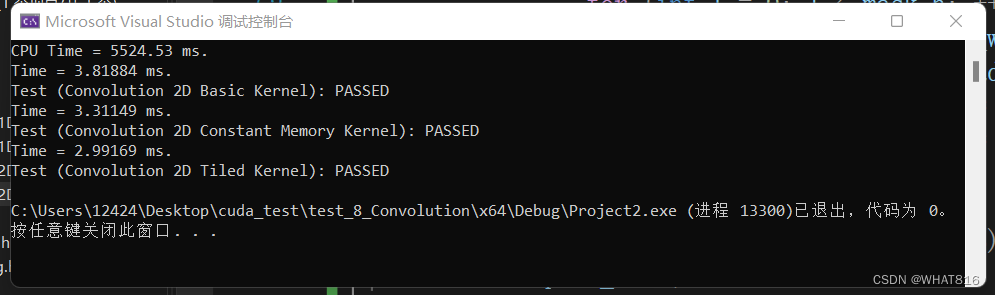
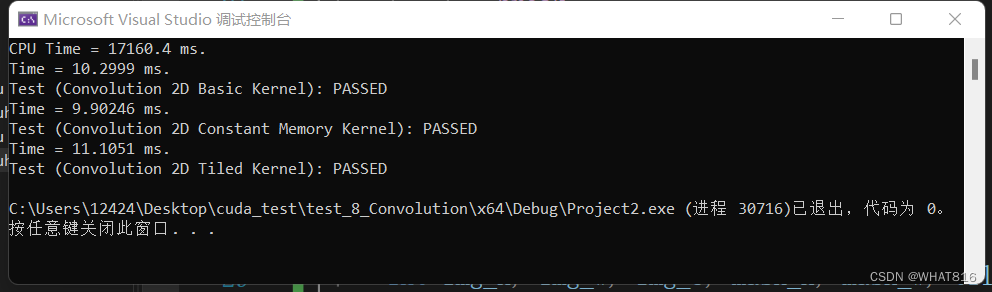
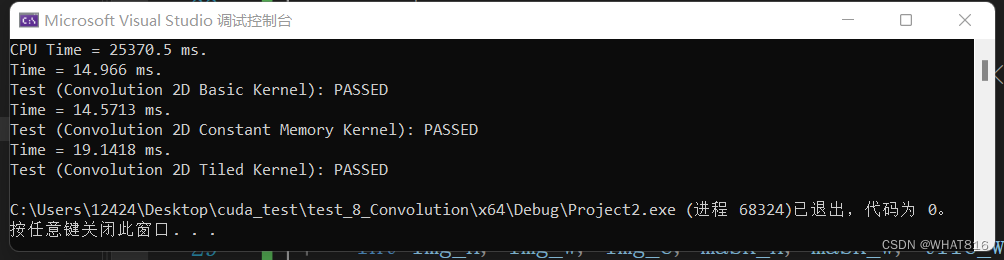
根据运行时间分析,前三种算法在mask:5 × 5时效果逐次递进。总的来说,常量内存方法的性能略优于基本方法。这是因为mask的尺寸较大,硬件无法轻松地将其缓存到L2缓存中。这为常量内存方法带来了优势。
mask:7 × 7 、11 × 11时共享内存方法表现不佳,目前考虑加载共享内存时mask越大,加载的冗余元素越多。需要额外的内存复制和数据传输操作来将数据从全局内存加载到共享内存中,增加了数据传输的开销;
理论上2D空间比1D空间更适合共享内存。这是因为2D空间不容易缓存到L2缓存中。只是kernel的复杂性增加会减慢速度,共享内存相对于基本方法的优势并不是那么大。
具体情况尚未可知,有大佬了解请评论补充。
Note:单次运行可能因为设备启动原因,各种算法运行时间差异较大,可采用循环20次以上取平均值。
笔者采用设备:RTX3060 6GB
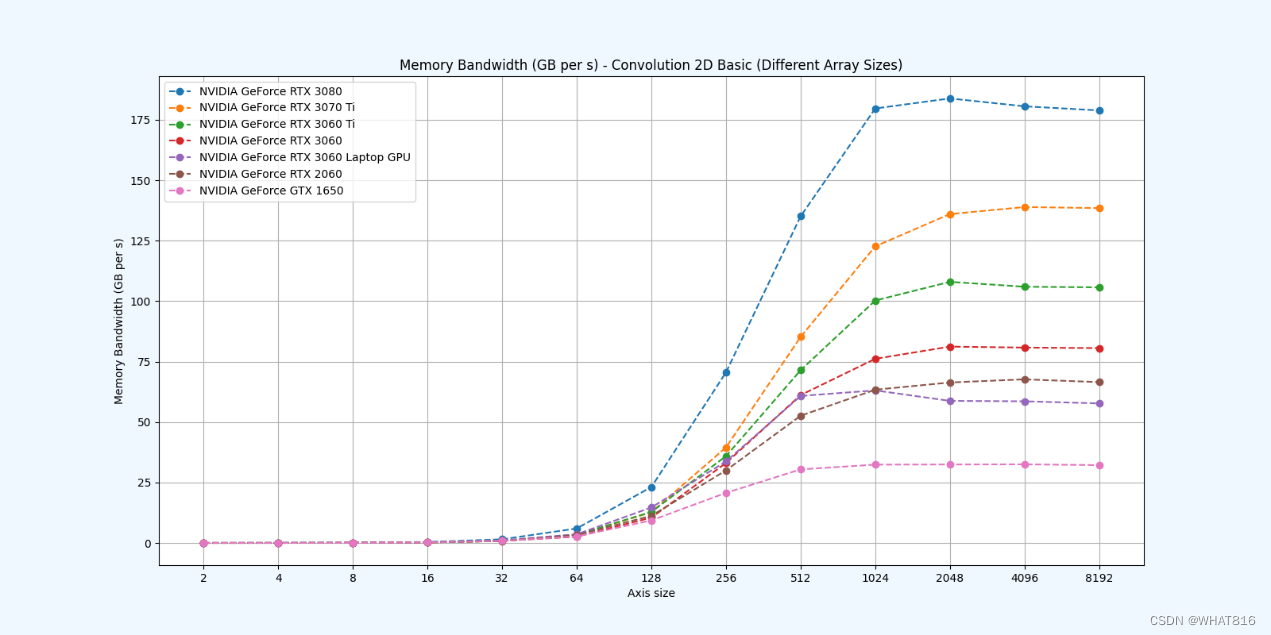
PMPP项目提供的分析
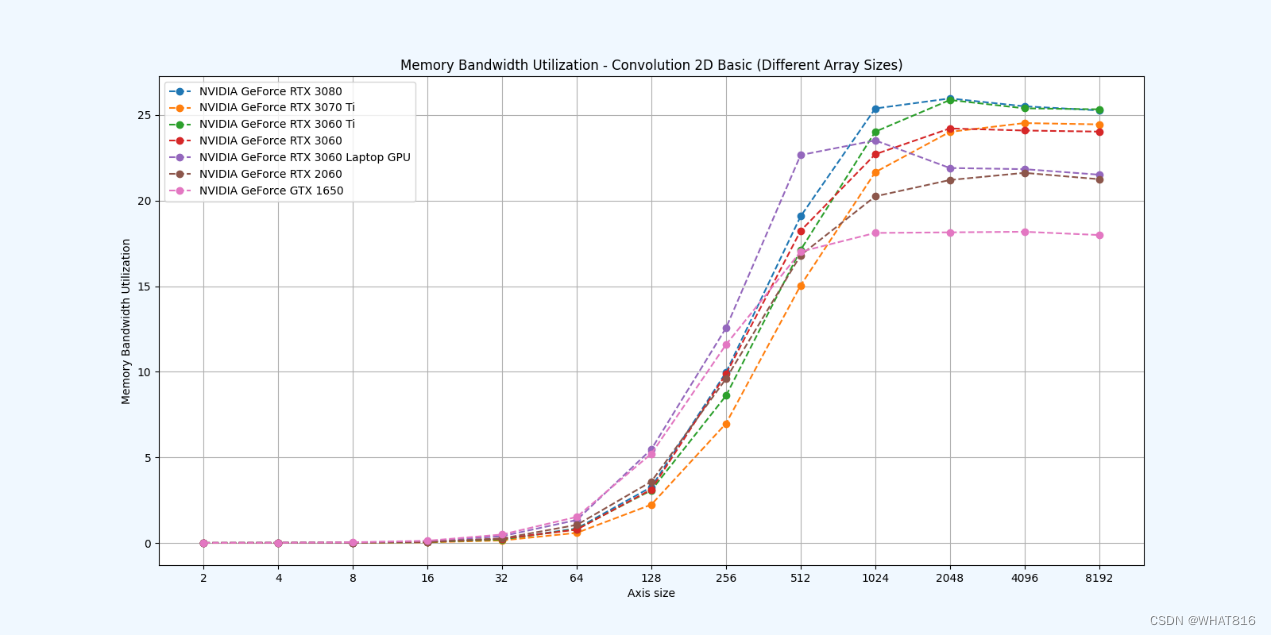
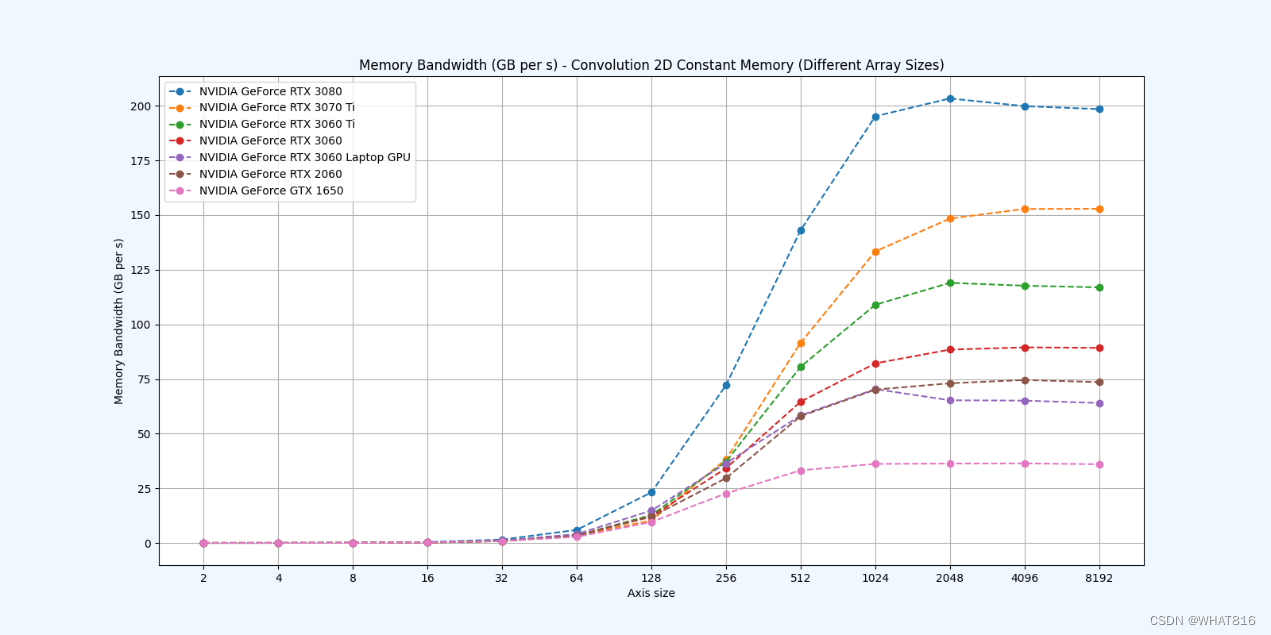
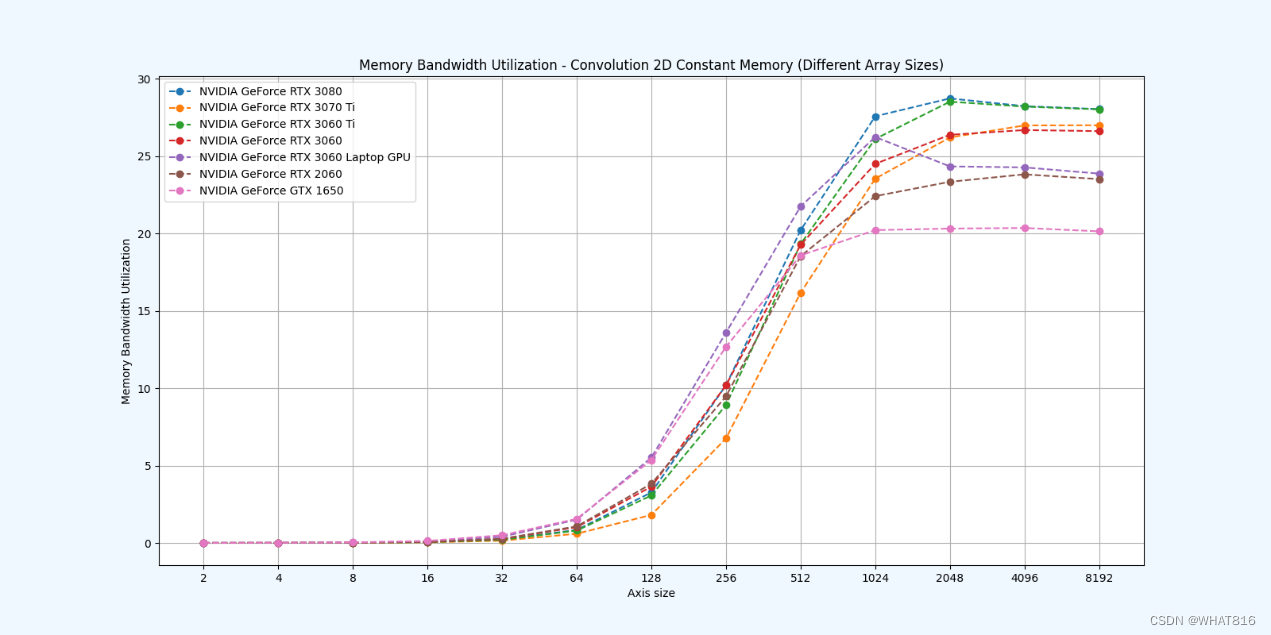
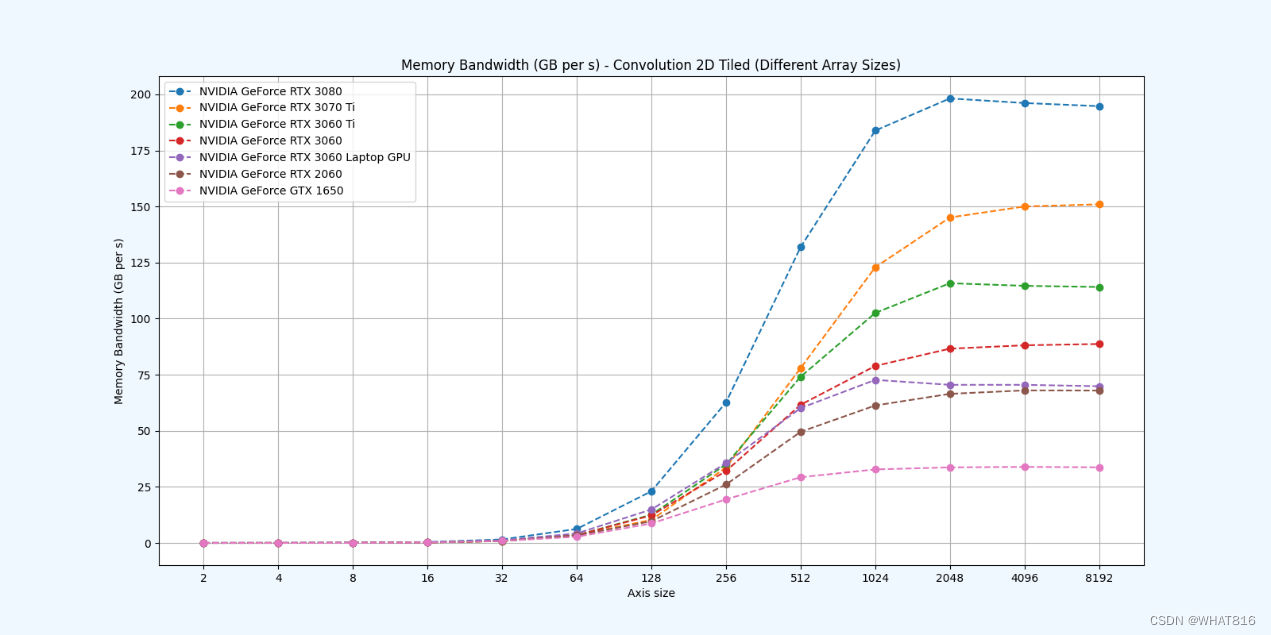
kernel的性能是使用NvBench项目在多个gpu中测量的。研究的性能测量方法有:
内存带宽:每秒传输的数据量。
内存带宽利用率:占用内存带宽的百分比。
基础方法:
常量存储器
共享存储器
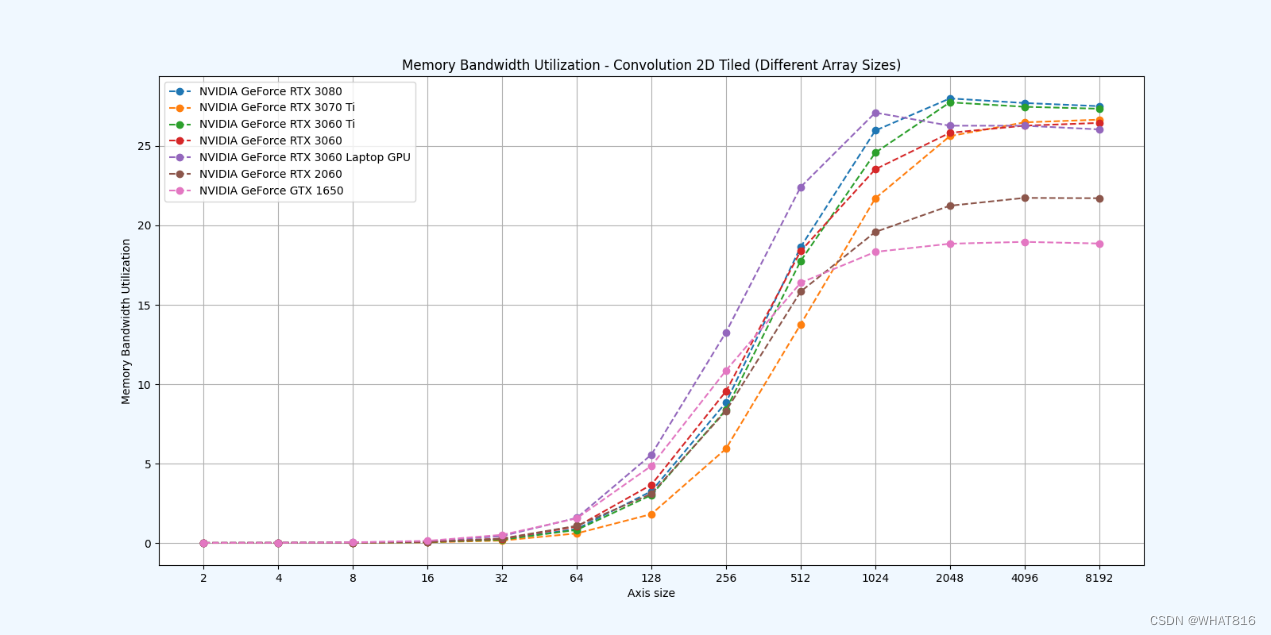
参考文献:
1、大规模并行处理器编程实战(第2版)
2、PPMP















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









