






文章:Sepp Hochreiter, Jürgen Schmidhuber; Long Short-Term Memory. Neural Comput 1997; 9 (8): 1735–1780. doi: https://doi.org/10.1162/neco.1997.9.8.1735

这段话是对 递归神经网络(RNN)记忆机制的本质、应用场景和现有方法的不足 做出总结,并引出作者提出新方法的动机。
1."Recurrent networks can in principle use their feedback connections to store representations of recent input events in form of activations (“short-term memory”, as opposed to “long-term memory” embodied by slowly changing weights)."
翻译:递归网络原则上可以利用其反馈连接,将最近的输入事件以激活状态的形式进行存储(即“短期记忆”),与之相对的是“长期记忆”,后者由缓慢变化的权重承载。
关键词解析:
-
Recurrent networks:递归神经网络,RNN
-
feedback connections:网络中的反馈连接(当前状态依赖于前一时刻的输出)
-
activations:神经元的激活值,这里表示当前时间步的“记忆”
-
short-term memory:短期记忆,体现在隐藏状态中
-
long-term memory:长期记忆,指权重(weights)中“慢慢学到”的知识
📘 知识点补充:
-
RNN 的“记忆”分为两类:
-
短期:用激活状态
h_t表示,变化快 -
长期:用参数
W存储,通过训练缓慢调整
-
-
作者在这里强调 RNN 的短期记忆理论上很有潜力。
2."This is potentially significant for many applications, including speech processing, non-Markovian control, and music composition (e.g., Mozer 1992)."
翻译:这种能力在很多应用中都可能具有重要意义,例如语音处理、非马尔可夫控制和音乐创作(如 Mozer 1992 提出)。
关键词解析:
-
significant:重要的,有意义的
-
speech processing:语音处理,如语音识别、语音合成
-
non-Markovian control:非马尔可夫控制,即系统的状态不仅仅依赖当前输入,还与过去状态有关
-
music composition:音乐创作,通常涉及长序列结构
-
Mozer 1992:是指 Michael Mozer 在 1992 年关于音乐生成中使用 RNN 的研究
📘 知识点补充:
这些任务都具有明显的长序列依赖性,对记忆的要求较高,传统模型往往无法有效处理。
3."The most widely used algorithms for learning what to put in short-term memory, however, take too much time or do not work well at all, especially when minimal time lags between inputs and corresponding teacher signals are long."
翻译:然而,目前最常用的那些学习如何存储短期记忆的算法,要么太耗时,要么效果很差,尤其是当输入与其对应标签之间存在较长延迟时。
关键词解析:
-
widely used algorithms:如 BPTT、RTRL 等主流算法
-
what to put in short-term memory:算法要学的是哪些信息该记住,哪些可以忽略
-
minimal time lags:最小时间延迟,即输入与监督信号之间间隔很长
-
teacher signals:监督信号,也就是训练数据中的目标输出(ground truth)
📘 知识点补充:
举个例子:你输入一个句子“我今天很开心”,如果情感标签“positive”在句尾才出现,那模型需要记住整个句子内容,这种延迟会导致训练难度大,梯度容易消失。
4."Although theoretically fascinating, existing methods do not provide clear practical advantages over, say, backprop in feedforward nets with limited time windows."
翻译:尽管这些方法在理论上很吸引人,但在实际应用中,它们并没有比那些在有限时间窗上使用反向传播的前馈网络方法带来明显优势。
关键词解析:
-
theoretically fascinating:理论上很有吸引力(比如看起来能处理长依赖)
-
practical advantages:实际效果好不好,能不能收敛、泛化好、学得快
-
backprop in feedforward nets:前馈神经网络中的标准反向传播
-
limited time windows:只处理最近几步(如 sliding window),而不是整个序列
📘 知识点补充:这里的批评非常关键:即便我们有“递归网络”,但如果它不能有效传播梯度,它甚至不如普通的 MLP + 时间窗。
5."This paper will review an analysis of the problem and suggest a remedy."
翻译:本文将回顾这个问题的分析,并提出一个解决方案。

对传统递归神经网络学习方法的缺陷的具体阐述,即我们经常听到的“梯度爆炸”和“梯度消失”问题的本质来源。
1."The problem. With conventional 'Back-Propagation Through Time' (BPTT, e.g., Williams and Zipser 1992, Werbos 1988) or 'Real-Time Recurrent Learning' (RTRL, e.g., Robinson and Fallside 1987),"
翻译:问题所在:在传统的时间反向传播(BPTT)(例如 Williams 和 Zipser, 1992;Werbos, 1988)或实时递归学习(RTRL)(例如 Robinson 和 Fallside, 1987)中
关键词解析:
-
Back-Propagation Through Time (BPTT):时间展开后,对展开的神经网络执行普通的反向传播。这是训练 RNN 的标准方法。
-
Real-Time Recurrent Learning (RTRL):另一种训练递归网络的在线学习算法,但计算成本极高。
-
Williams, Zipser, Werbos:RNN 训练方法的早期贡献者
📘 补充说明:BPTT 是目前训练 RNN 最常见的方法,但它依赖梯度在时间维度上的“传递”,这正是问题的根源。
2."error signals 'flowing backwards in time' tend to either (1) blow up or (2) vanish:"
翻译:
反向传播中,误差信号沿时间方向传播时,常常出现以下两种情况之一:
(1)爆炸(blow up)或(2)消失(vanish)
关键词解析:
-
error signals flowing backwards in time:梯度在时间维度上传播,比如当前的损失通过链式法则影响到很久以前的输入
-
blow up:梯度值越来越大,导致训练不稳定
-
vanish:梯度越来越小,导致网络无法学习远距离依赖关系
📘 核心知识点:梯度爆炸与消失(vanishing/exploding gradient)
-
RNN 会不断对时间步的梯度相乘,假如权重较大(>1),梯度可能无限增大(爆炸);
-
假如权重较小(<1),梯度可能迅速变为0(消失);
-
这两种情况都会造成训练失败。
3."the temporal evolution of the backpropagated error exponentially depends on the size of the weights (Hochreiter 1991)."
翻译:这种误差在时间上的传播过程以指数方式依赖于权重的大小(Hochreiter 1991 指出)。
关键词解析:
-
temporal evolution:随时间演化(这里指的是误差/梯度沿时间维度的传播)
-
exponentially depends on weights:乘上一个权重之后,再传给前一层,一直乘下去会指数变化
-
Hochreiter 1991:就是 LSTM 的发明者之一,他的博士论文系统分析了这个问题
4."Case (1) may lead to oscillating weights,"
翻译:情况(1)(梯度爆炸)可能导致权重不断震荡(变来变去,不稳定)
关键词解析:
-
oscillating weights:梯度太大 → 更新步长大 → 参数来回抖动 → 无法收敛
📘 后果:
-
loss 函数在训练过程中不下降,或者剧烈震荡
-
模型根本学不到稳定结构
5."while in case (2) learning to bridge long time lags takes a prohibitive amount of time, or does not work at all (see section 3)"
翻译:而在情况(2)(梯度消失)中,想要跨越较长时间间隔进行学习将花费极其长的时间,甚至根本无法实现(详见第3节)。
关键词解析:
-
learning to bridge long time lags:希望模型学习到前面输入和后面标签之间的联系,但因为梯度传不回去,学不到。
-
prohibitive:代价高得令人望而却步的
-
does not work at all:压根儿学不动
📘 总结一下梯度消失的后果:
-
网络只能记得“最近发生的事”
-
一旦依赖的信息来自于几十甚至上百步之前,模型就“记不住”了
-
这是很多 RNN 训练失败的根源所在

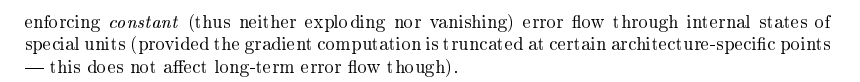
介绍LSTM 提出的核心动机和方法 ,聚焦在如何解决传统 RNN 的“梯度爆炸/消失”问题,也就是上段所描述的困境。
1."The remedy. This paper presents 'Long Short-Term Memory' (LSTM), a novel recurrent network architecture in conjunction with an appropriate gradient-based learning algorithm."
翻译:解决方案:本文提出了一种新的递归神经网络结构,称为 “长短期记忆网络(LSTM)”,并结合了一种合适的基于梯度的学习算法。
关键词解析:
-
remedy:补救措施、解决方法
-
Long Short-Term Memory (LSTM):长短期记忆网络,是 RNN 的一种改进结构
-
novel recurrent network architecture:全新的递归网络结构
-
gradient-based learning algorithm:依旧是基于梯度下降的训练方式(比如反向传播)
📘 背景: LSTM 是为了解决 BPTT 中梯度消失/爆炸而设计的结构改进,而不是完全换掉训练算法。
2."LSTM is designed to overcome these error back-flow problems."
翻译:LSTM 的设计目的是克服这些误差反向传播中的问题。
关键词解析:
-
error back-flow problems:指的就是前面提到的梯度爆炸和梯度消失。
3."It can learn to bridge time intervals in excess of 1000 steps even in case of noisy, incompressible input sequences, without loss of short time lag capabilities."
翻译:即使在输入序列存在噪声且无法压缩的情况下,LSTM 也能学习超过1000个时间步长的依赖关系,同时又不丧失处理短时间依赖的能力。
关键词解析:
-
bridge time intervals:跨越时间间隔,指的是学习长时间延迟的输入和输出之间的关系
-
in excess of 1000 steps:时间步数超过1000,强调 LSTM 能处理长距离依赖
-
noisy:含有噪声的输入(不规律、变化大)
-
incompressible:无法通过压缩编码成简洁表示的输入(即无明显模式)
-
without loss of short time lag capabilities:仍然保留处理“短期依赖”的能力
📘 亮点: LSTM 是目前少有能同时兼顾“长时依赖”和“短时响应”的网络结构。
4."This is achieved by an efficient, gradient-based algorithm for an architecture enforcing constant (thus neither exploding nor vanishing) error flow through internal states of special units"
翻译:这一点的实现,依赖于一种高效的基于梯度的方法,以及一种特殊的网络结构,该结构强制在特殊单元的内部状态中维持“恒定误差流”,因而不会发生梯度爆炸或消失。
关键词解析:
-
efficient, gradient-based algorithm:依旧是用梯度下降,但方式上做了优化
-
architecture enforcing constant error flow:结构本身保证误差信号不增不减(恒定),这个“架构”就是 LSTM 的门控机制
-
internal states of special units:特殊单元的内部状态,即 LSTM 的 Cell State(单元状态)
📘 核心机制:LSTM 使用所谓的 Constant Error Carousel(CEC),即细胞状态(cell state)中误差可以直接传递而不被权重乘积所放大或缩小,因此避免梯度爆炸/消失。
5."(provided the gradient computation is truncated at certain architecture-specific points — this does not affect long-term error flow though)"
翻译:(只要在某些架构特定的位置对梯度计算进行截断即可 —— 这不会影响长期误差的传播)
关键词解析:
-
gradient computation is truncated:梯度截断,一种常见的技巧,用来控制反向传播的范围,避免不必要的计算
-
architecture-specific points:指的是网络结构中特定的位置,比如 LSTM 的门控处或循环边界
-
does not affect long-term error flow:说明截断只截短期部分,不会影响真正的“长时依赖”学习
📘 实际应用中:
-
在训练时,我们往往不会把梯度从当前时刻一直传回到起点,而是设定一个时间窗口,比如 100 步以内;
-
而 LSTM 的 cell state 可以在这段时间之外继续传递信息,从而实现“长期记忆”。

文章结构(Outline of the paper)的介绍。
"Outline of paper. Section 2 will briefly review previous work."
翻译:本文第2节将简要回顾以往的相关工作。
关键词:
-
briefly review:简要回顾
-
previous work:过往研究成果,比如 BPTT、RTRL、Elman 网络等
📘 说明:这为读者建立背景,尤其是关于早期 RNN 在学习长期依赖时所遇到的困难。
"Section 3 begins with an outline of the detailed analysis of vanishing errors due to Hochreiter (1991)."
翻译:第3节将以 Hochreiter(1991)对梯度消失问题的深入分析为开端。
关键词:
-
vanishing errors:梯度消失的问题
-
Hochreiter (1991):这是 LSTM 的发明者之一,他早在1991年就对这个问题进行了理论研究
📘 补充:梯度消失是传统 RNN 难以捕捉长时依赖的根本原因之一。
"It will then introduce a naive approach to constant error backprop for didactic purposes, and highlight its problems concerning information storage and retrieval."
翻译:随后,出于教学目的,第3节还将介绍一种朴素实现恒定误差传播的方式,并指出其在信息存储与提取方面存在的问题。
关键词:
-
naive approach:朴素、简化的做法(不实用,仅用于教学)
-
constant error backprop:保持误差恒定地反向传播
-
didactic purposes:教学目的
-
information storage and retrieval:信息存储与检索
📘 说明:这段是为了帮助理解“恒定误差流”的概念,但它也说明,仅仅解决梯度问题还不够,还要能“存住”和“取出”信息。
"These problems will lead to the LSTM architecture as described in Section 4."
翻译:这些问题将引出第4节中的 LSTM 架构设计。
📘 说明:也就是说,LSTM 是为了解决两类问题同时设计的:
-
梯度消失/爆炸问题;
-
信息存储与提取的结构化机制问题。
"Section 5 will present numerous experiments and comparisons with competing methods."
翻译:第5节将展示大量实验,并与其它主流方法进行比较。
📘 说明:这一节是实证部分,验证 LSTM 的有效性,并证明其优越性。
"LSTM outperforms them, and also learns to solve complex, artificial tasks no other recurrent net algorithm has solved."
翻译:实验结果显示,LSTM 不仅表现优于其它方法,还学会了解决此前所有递归网络都无法完成的复杂人工任务。
📘 亮点:这是论文中的高光时刻,展示 LSTM 能力的部分。
"Section 6 will discuss LSTM's limitations and advantages."
翻译:第6节将讨论 LSTM 的局限性与优势。
"The appendix contains a detailed description of the algorithm (A.1), and explicit error flow formulae (A.2)."
翻译:附录部分包括:
-
A.1:对算法的详细描述;
-
A.2:关于误差传播的公式。
总结(提炼要点)
| 要点 | 内容 |
|---|---|
| 短期记忆 | RNN 可通过激活状态存储“短期记忆”信息 |
| 应用场景 | 语音、非马尔可夫控制、音乐等序列依赖任务 |
| 现有方法问题 | 学习慢、效果差,尤其在长时间延迟任务下性能糟糕 |
| 替代方案 | 普通前馈网络 + 时间窗甚至效果更好 |
| 作者意图 | 这篇论文分析问题并提出解决方案(LSTM) |
| 问题 | 解释 | 后果 |
|---|---|---|
| 梯度爆炸(blow up) | 梯度在时间上传播过程中不断放大,指数增长 | 权重震荡,训练不稳定甚至发散 |
| 梯度消失(vanish) | 梯度随着时间反向传播时不断减小,接近零 | 无法学习长时间依赖,模型“失忆” |
| 内容 | 说明 |
|---|---|
| 提出 LSTM | 作为传统 RNN 的“补救方案” |
| 目标 | 避免梯度爆炸/消失;学习长期依赖关系 |
| 特点 | - 能处理超过 1000 步的时间延迟 - 对噪声和复杂输入鲁棒 - 同时保留短期记忆能力 |
| 关键机制 | - 恒定误差流(constant error flow) - 特殊单元(LSTM 单元) - 梯度截断技巧 |
总体结构导图
| 部分 | 内容 |
|---|---|
| Section 2 | 回顾传统方法(BPTT、RTRL等) |
| Section 3 | 分析梯度消失问题,介绍朴素恒定误差传播方式及其问题 |
| Section 4 | 正式引出并详细描述 LSTM 架构 |
| Section 5 | 进行实验,展示与其他方法的对比结果 |
| Section 6 | 总结 LSTM 的优缺点 |
| Appendix | A.1:算法细节,A.2:误差流公式(数学推导) |

















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









