






1.OpenAI o1推理scaling引领AI新革命
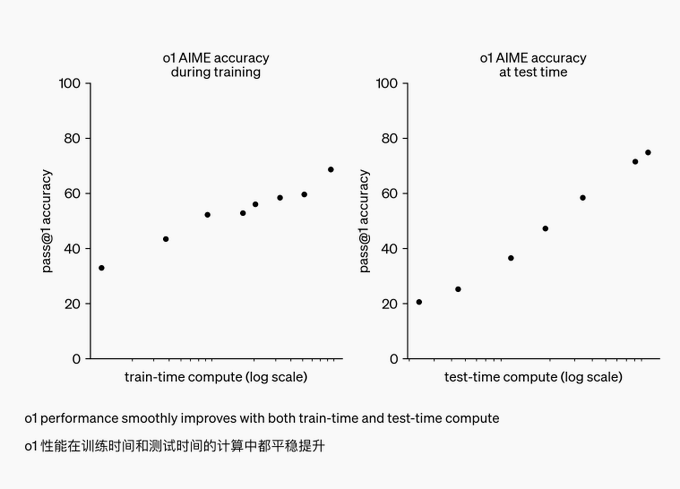
CoT技术让o1成为了推理领域的霸主!它引领了推理scaling的新革命——随着算力的飙升和响应时间的延长,o1的性能也在突飞猛进。
你可能会想,如果把o1的训练秘籍应用到所有大模型上,岂不是个个都能成为推理界的王者?
但Epoch AI的研究却告诉我们,事情没那么简单。他们发现,仅仅扩大推理计算的规模,根本无法缩小o1-preview和GPT-4o之间的巨大鸿沟。
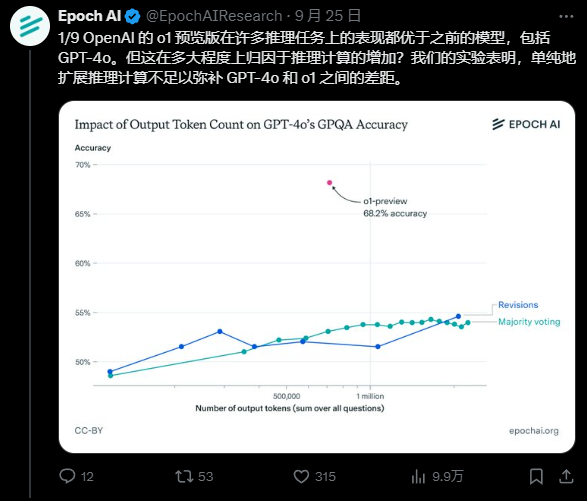
他们直言,尽管o1通过逐步推理方法进行了训练,但其性能的飞跃,可能还归功于其他未知的神秘因素。
2.OpenAI o1背后秘诀是什么?
就在上周,o1-preview和o1-mini亮相后,Epoch AI的专家们就迫不及待地把它们和GPT-4o来了个正面硬刚。
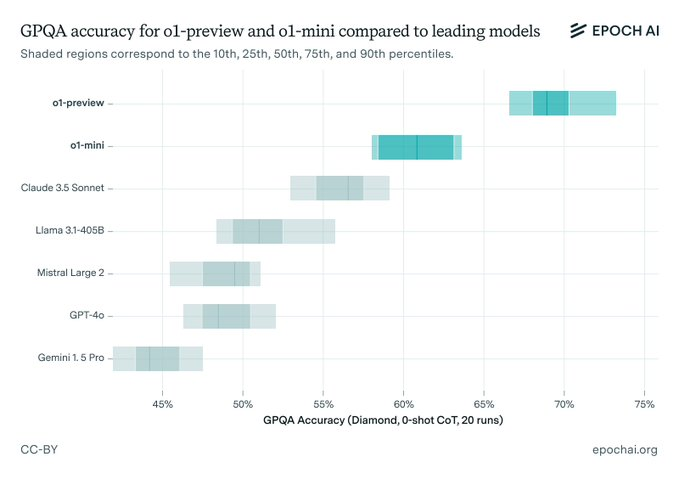
他们用GPQA这场研究生级别的测试来决一胜负,结果o1-preview以压倒性优势胜出,不仅秒杀了GPT-4o,还把其他竞争者远远甩在了后面。
但等等,这公平吗?o1可是用了更多的token和推理时间。为了一探究竟,研究人员给GPT-4o来了个"特训",用了多数投票和修正大招,想让它学学o1的思考方式。然而,即使这样,GPT-4o的准确率还是比o1低了整整10个百分点!
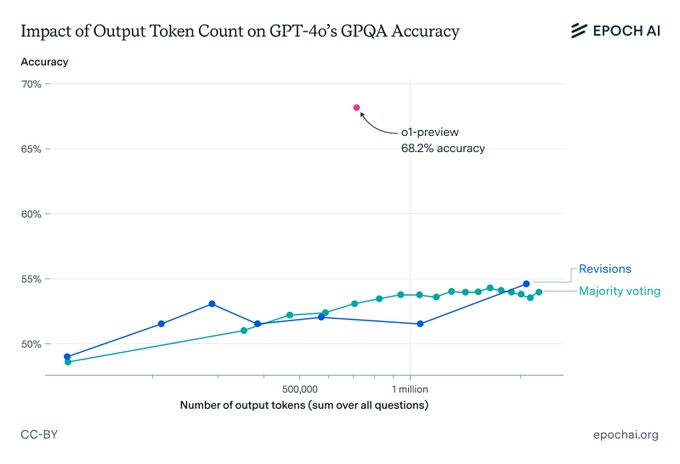
更狠的是,哪怕你给GPT-4o烧上1000美元的token费,它的准确率还是比o1低一大截。
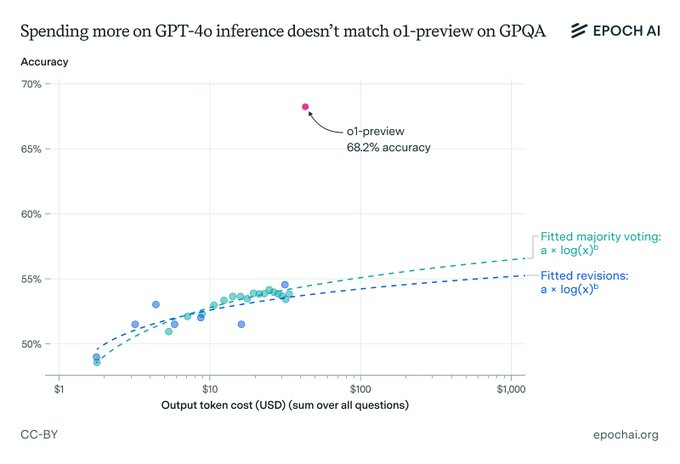
看来,o1之所以能傲视群雄,靠的不仅仅是token数量,更可能是它背后那些高深莫测的算法和强化学习技术。
3.OpenAI o1背后秘诀:自学推理
OpenAI发现,随着训练和推理时计算的增加,o1的性能稳步提升。
斯坦福大学2022年的「自学推理」(STaR)技术,让机器像学霸一样自我提升。先给模型例题和解法,再让它挑战新题目,做对了就更新题库,微调模型,让机器学会解题技巧。
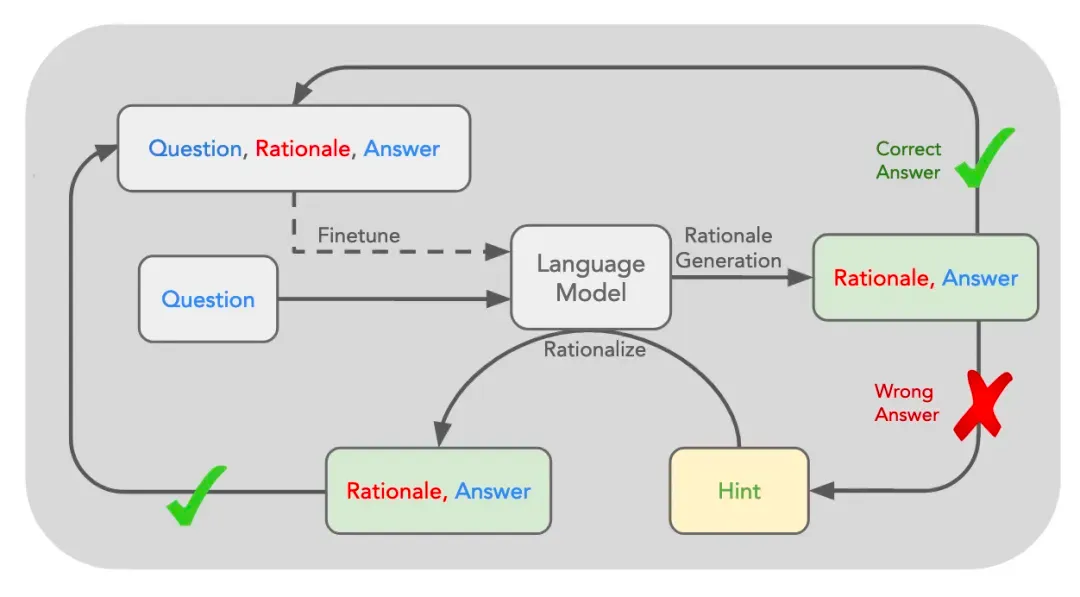
而更先进的“Quiet-STaR”技术,也就是神秘的Q*,更是让模型在每个输入后都进行“深思熟虑”,生成内部推理,系统再根据推理的准确性调整参数。这不仅让模型回答问题时更精准,还能在处理各种文本时都进行隐含推理。
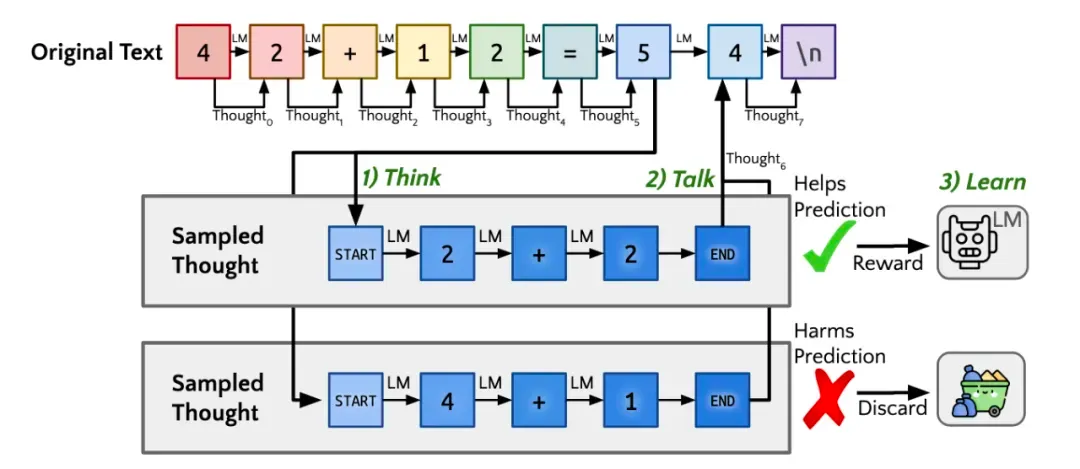
简单来说,这就像是给大模型一套自学成才的秘籍,让它在数学和编程领域内自我修炼,不断进步。这种自我学习机制,让模型在这些领域的表现尤为出色。
4.OpenAI o1规划能力仍有待提高
o1在STEM领域的推理能力让人印象深刻,但规划能力如何?
亚利桑那州大学的PlanBench基准测试揭示了真相。o1在Blocksworld任务上达到了97.8%的准确率,远超之前62.6%的最佳成绩。
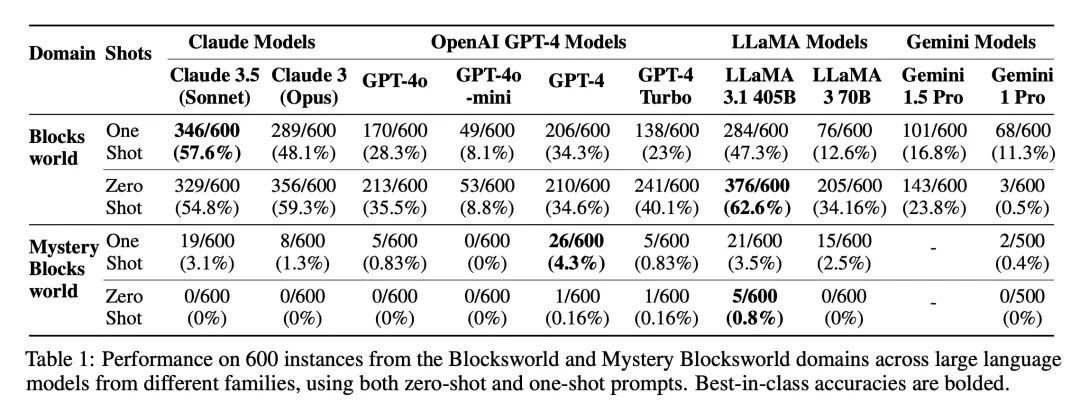
然而,在Mystery Blocksworld任务中,o1的准确率仅为52.8%,面对随机变体测试时更是下降至37.3%。
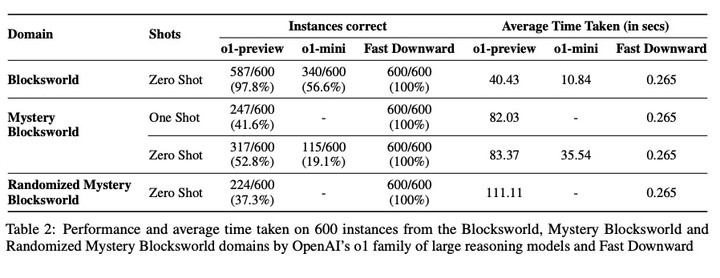
这表明o1在处理复杂规划任务时仍然存在局限,尽管它在某些方面表现出色,但与传统规划器相比,如Fast Downward,o1的正确性和可解释性仍有待提高。
5.Azure OpenAI已上架 o1-preview,o1-mini
Azure OpenAI 里面已上架,现在可在Playground 体验。
o1-preview 和 o1-mini 模型现已在 Azure AI Studio 和 GitHub Models 中可供部分 Azure 客户使用,以便他们共同探索和识别每个模型的独特优势。
o1 系列高级推理模型在以下复杂而微妙的问题领域表现出色:

复杂代码生成:能够执行算法生成和高级编码任务,以帮助开发人员。
高级问题解决方案:非常适合全面的头脑风暴会议和解决多方面的问题。
复杂文档比较:非常适合分析合同、案件档案或法律文件以辨别细微的差别。 指令遵循和工作流管理:特别擅长处理需要较短上下文的工作流。















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









