







一,原理
在这里借鉴YOLOv5中的SPP/SPPF结构详解_tt丫的博客-CSDN博客的文章,该文章的原理解释很清楚,具体原理如下:
1、SPP的应用的背景
在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固定尺寸的该怎么办呢?
通常来说,我们有以下几种方法:
(1)对输入进行resize操作,让他们统统变成你设计的层的输入规格那样。但是这样过于暴力直接,可能会丢失很多信息或者多出很多不该有的信息(图片变形等),影响最终的结果。
(2)替换网络中的全连接层,对最后的卷积层使用global average pooling,全局平均池化只和通道数有关,而与特征图大小没有关系
(3)最后一个当然是我们要讲的SPP结构啦~
Note:
但是在yolov5中SPP/SPPF作用是:实现局部特征和全局特征的featherMap级别的融合。
2、SPP结构分析
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
接下来我们来详述一下SPP是怎么处理滴~
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:21个神经元 -- 即我们待会希望提取到21个特征。
分析如下图所示:分别对1 * 1分块,2 * 2分块和4 * 4子图里分别取每一个框内的max值(即取蓝框框内的最大值),这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 2 * 2 + 4 * 4 = 21个。得出的特征再concat在一起。
而在YOLOv5中SPP的结构图如下图所示:
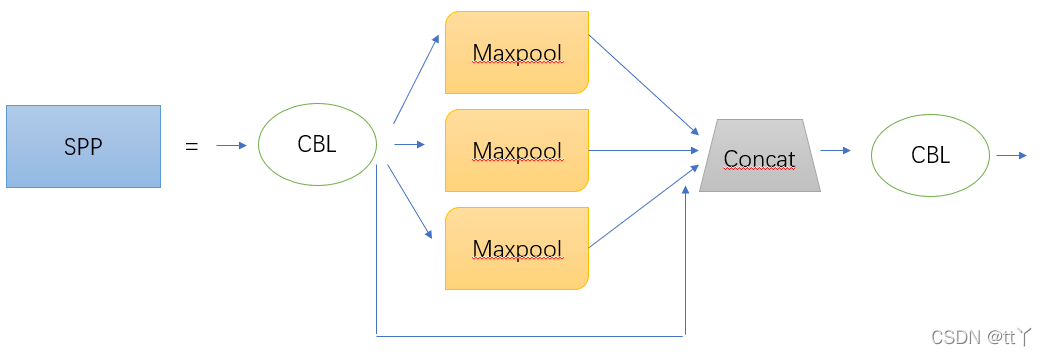
其中,前后各多加一个CBL,中间的kernel size分别为1 * 1,5 * 5,9 * 9和13 * 13。
所有以上内容都来自YOLOv5中的SPP/SPPF结构详解_tt丫的博客-CSDN博客的文章。
二,代码解析
代码用了图片,可以根据自己的图片路径修改图片路径,具体解析如下:
import torch
import torch.nn as nn
import cv2
#silu激活函数
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
#卷积结构
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super(Conv, self).__init__()
#卷积、标准化加激活函数
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)#卷积
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)#标准化
self.act = SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())#激活函数
def forward(self, x):
return self.act(self.bn(self.conv(x)))#卷积->BatchNorm2d->激活函数->output
def fuseforward(self, x):
return self.act(self.conv(x))#这个forward函数不存在BN操作
#spp结构
class SPP(nn.Module):
def __init__(self, c1=3, c2=3, k=(5, 9, 13)):#初始化卷积核大小5,9,13
super(SPP,self).__init__()
c_ = c1 // 2 # hidden channels
#卷积网络cv1,输出通道数是输入通道数的一半,卷积核大小是1,步长是1
self.cv1=Conv(c1,c_,1,1)
# 卷积网络cv2,输入通道数是cv1的输出通道数的4倍,输出通道数是c2(定值),卷积核大小是1,步长是1
self.cv2=Conv(c_*(len(k)+1),c2,1,1)
# 这里用了3次最大池化,参数分别为 5,1,2 // 9,1,4 // 13,1,6 这里根据卷积核填充后保证池化后的矩阵与原矩阵的大小相同
self.m=nn.ModuleList([nn.MaxPool2d(kernel_size=x,stride=1,padding=x//2) for x in k])
def forward(self,x):
# x先经过一次BN+SILU的卷积神经网络
x=self.cv1(x)
#返回值是将输入的x,三次最大池化的x1,x2,x3加起来。注意:cat函数不是直接相加,而是维度的合并,里面的”+“是求和,将几个矩阵直接求和
return self.cv2(torch.cat([x]+[m(x) for m in self.m],1))
if __name__ == "__main__":
#输入图片路径
image=cv2.imread(r"D:\AI\data\red_green_light\4.jpg")
images=image.reshape(1,3,1080, 1920)
input=torch.tensor(images,dtype=torch.float32)#浮点型
output1=SPP()
output=output1(input)
print(output)
print(output.shape)















 7728
7728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









