







本文以线形回归为例,利用高斯分布概率密度函数和极大似然估计公式推导出线性回归误差函数通用表达式。
以一元线性回归算法为例,其模型如下所示:
(1)
假如给定 i=14 个样本数据 :
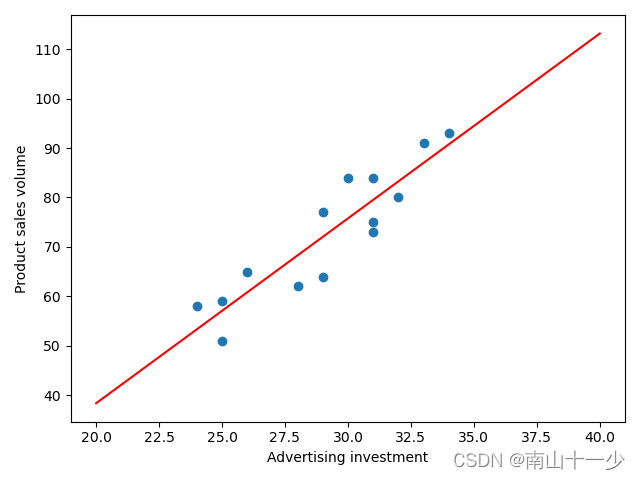
[ [29, 77], [28, 62], [34, 93], [31, 84], [25, 59], [29, 64], [32, 80], [31, 75], [24, 58], [33, 91], [25, 51], [31, 73], [26, 65], [30, 84]]
线性回归的原理即为通过确定模型参数,确定所有样本值代入模型后得到的结果值与真实值累计误差最小。以一元线性回归为例,直观的看如图所示,即为找到一条直线,穿过所有样本点,并使各个点到直线的累计距离 最小,从而求出直线方程的参数
和 参数
的值。
如果是多元线性回归,即样本的特征向量不止一个维度,同样遵循以上模型特点和原理,更通用的线形回归表达方式如下:
(2)
以上表达式可通过向量的方式进行表达,如下所示:
(3)
因为误差具有随机性,符合独立同分布特点,高斯概率分布函数如下:
(4)
因误差项满足高斯概率分布:
(5)
将误差代入高斯分布:
(6)
根据极大似然估计的原理,根据样本发生的概率估计整个事件的概率,其主要思想是所有样本发生的总概率最大的概率即为事件的概率,因为样本独立同分布,故所有样本概率积求最大值:
(7)
由于概率小于1,连乘会导致最后的值非常小,故两边取对数,让连乘变连加,且不会改变函数的单调性。
(8)
(9)
(10)
要是上述对数函数最大,即可让与连加部分最小即可,而这部分就是我们要推导的目标函数:
(11)
以上目标函数同时也可以用向量表达:
(12)
通过上诉步骤推导出的目标函数,与我们最朴素的想法通过求误差平方和不谋而合:
(13)
:是指给定的样本数据中的y值,即真实值
:是指通过线性回归模型(即直线方程)求得的 y 值,即:
上述目标函数求极小值可以通过最小二乘法求解,又名正规方程解:
即对目标函数求导等于0:
(14)
(15)
通过最小二乘法求极小值不仅计算量大,而且不是每个特征矩阵有逆,故通常使用梯度下降法求解,梯度下降本质是一种迭代搜索目标函数最优解的方法,顾名思义,其搜索方向是其梯度方向,因梯度的反方向是函数值减小最快的方向,因此故又称之为最速下降法。














 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









