






现在网上对LoRA的解读文章大多非常粗暴地粘贴了原文内容、实验结果以及翻译了实验结论,对于怎么得出结论的以及一些背景知识都没有很细的讲解,本篇博客针对LoRA: Low-Rank Adaptation of Large Language Models原文的第五节实验部分,第七节理解低秩更新以及Future Work部分进行了详细解读,并顺带总结了之后LoRA的各种变体以及LoRA在NLP(如命名实体识别等)和CV(如Stable Diffusion)领域的具体应用。
目录
1. 实验部分
对应原文的第五节:EMPIRICAL EXPERIMENTS
实验对比的Baseline有:
- 微调:在预训练后的模型上进行全参微调
- Bias-only or BitFit:Bias-only指仅优化神经网络中的偏置项(bias),而不改变主权重参数;BitFit是它的一种变体
- Prefix-embedding tuning (PreEmbed):通过引入额外的可学习的“前缀嵌入”来修改模型的行为
- Prefix-layer tuning (PreLayer):前缀层调优(PreLayer)是前缀嵌入调优的扩展除了前缀嵌入外,PreLayer方法会在多个层次上插入前缀信息,每一层都会接收到前缀信息,并且这些前缀信息会在模型的每一层中传播和调整,从而逐层影响最终的模型输出。
- Adapter tuning:只对这些新增的适配器层进行训练,保持预训练模型的其他部分不变
1.1 NLU任务
GLUE基准测试:包含了9个不同的自然语言理解任务,这些任务涵盖了词汇水平、句子水平和篇章级别的理解和推理。
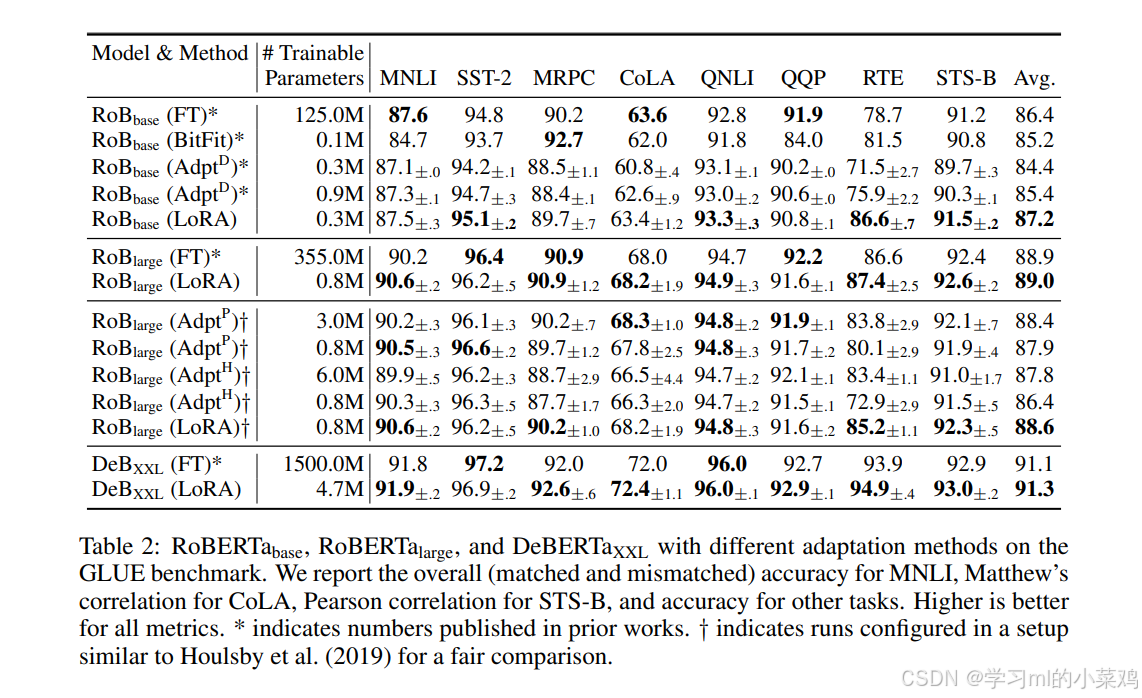
让RoBERTabase, RoBERTalarge和DeBERTaXXL在GLUE基准测试中使用不同的适应方法,评估LoRA在多个NLU(自然语言理解)任务上的表现(除了WNLI的另外8项GLUE测试任务),如下表所示:LoRA取得了在三个模型的各自八个任务的平均准确率最高,在细分的大多数任务的有最优表现,即使不是最优,也和最优的相差不多,是comparable的。
1.2 NLG任务
E2E NLG Challenge:端到端自然语言生成挑战,参赛系统需要根据给定的意义表示(Meaning Representation,简称MR)生成自然语言文本。挑战的核心在于评估系统生成的自然语言文本的质量。这通常通过自动评估指标和人类评估来完成。自动评估指标主要衡量生成文本与参考文本之间的相似度,而人类评估则关注生成文本的自然性、流畅性和与意义表示的匹配程度。
自动评估指标:BLEU(广泛使用的机器翻译和文本生成评估指标)NIST(另一种机器翻译评估指标)、METEOR(基于词汇对齐的评估指标)、ROUGE-L(用于评估自动文摘和机器翻译的指标)和CIDEr(专门用于图像描述生成的评估指标)等。
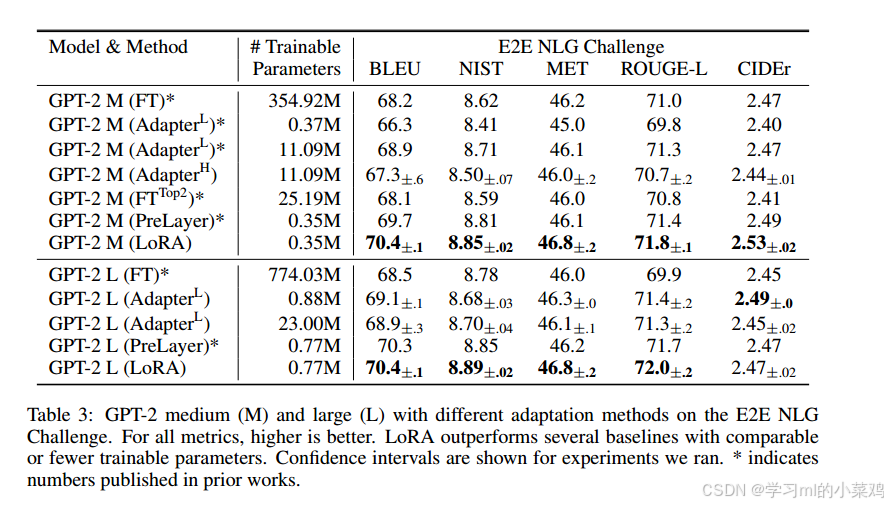
让GPT-2中(M)和大(L)模型在E2E NLG挑战中使用不同的适应方法,进一步评估LoRA在NLG(自然语言生成)任务上的表现,如下表所示,结论同上(大多数大于,即使不大于也是comparable的)
1.3 最终压力测试:增大参数规模的GPT3模型
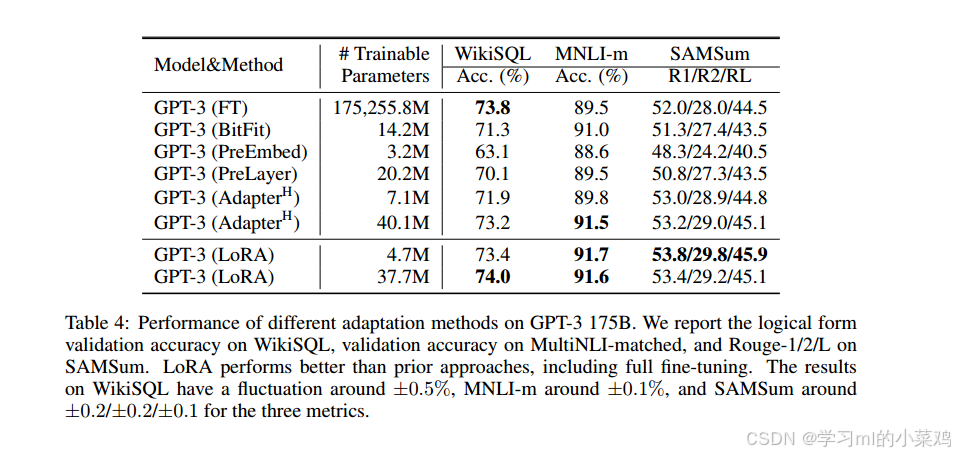
LoRA的优势可能在更大规模的模型中得到更好的体现,因此作为LoRA的最终压力测试,作者将GPT-3扩展到1750亿个参数,并进一步拓展了任务类型。如下表所示,LoRA仍表现优异,匹敌或超过了所有三个数据集的微调基线。
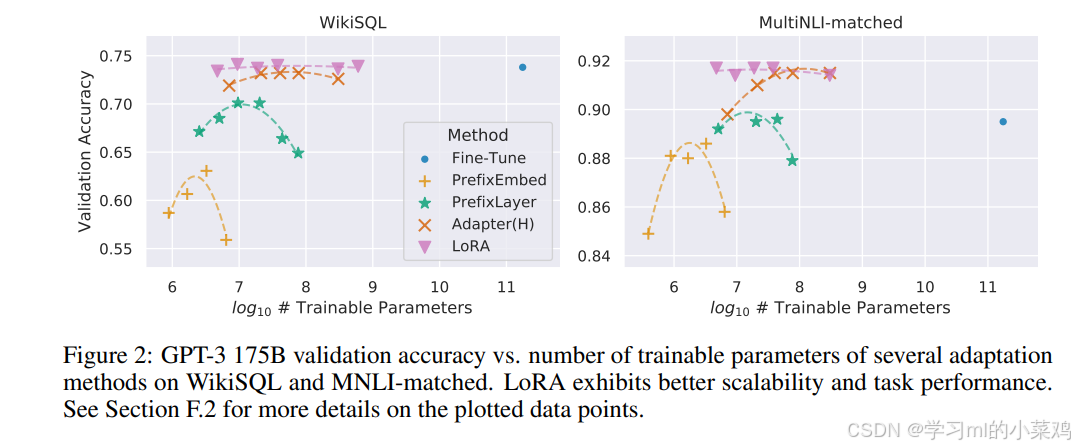
 Noting:不是所有微调方法都是训练参数越多,表现越好。如下图所示,对于prefixEmbed和prefixLayer方法训练参数变多,验证精度先变大后变小;对于LoRA来说则基本不变。
Noting:不是所有微调方法都是训练参数越多,表现越好。如下图所示,对于prefixEmbed和prefixLayer方法训练参数变多,验证精度先变大后变小;对于LoRA来说则基本不变。
2. 理解低秩的更新
对应原文的第7节:UNDERSTANDING THE LOW-RANK UPDATES(原文的第6节是related work介绍,我把这一节与前面的现有方法不足和问题陈述放在一起,在LoRA论文精度上集中讲了)
提出了三个问题:
- 鉴于存在参数预算约束,在预训练的 Transformer 中,我们应当对哪些权重矩阵的子集进行适配,以实现下游性能的最大化?
- “最优”适配矩阵 ∆W 是否真的是低秩矩阵?
- ∆W 与 W 之间存在何种关联?∆W 与 W 的相关性是否较高?∆W 相较 W 的规模如何?
下面分别做讨论
2.1 选择哪些权重矩阵?
只考虑transformer的self-attention module里的四个权重矩阵,冻结MLP module中的两个权重矩阵,固定参数预算为18MB,则当选择一种矩阵改变时,r=8;选择两种矩阵改变时,r=4;选择四种矩阵改变时,r=2。
最终在两个数据集上取得的验证精度如上。单独使用Wq和Wk的表现较差,结合使用Wq和Wv的表现较好,综合使用四个矩阵的表现最好。这表明使用多种矩阵和较小的秩比使用一种矩阵和较大的秩表现更好。BTW,这里有一点疑问,为什么既然Wq单独的变现并不好,还一定要在两两组合的时候带上Wq,为什么不使用Wv和Wo这两种单独表现最好的矩阵进行组合(可能作者是做了实验的,但是因为某种原因没有展示,这就不得而知了)
2.2 低秩矩阵是否真的够用?
下表展示了作者仅使用Wq,使用{Wq,Wv},使用{Wq,Wv,Wk,Wo}三种矩阵改变方法,在两个数据集上改变r的大小得出的验证精度情况。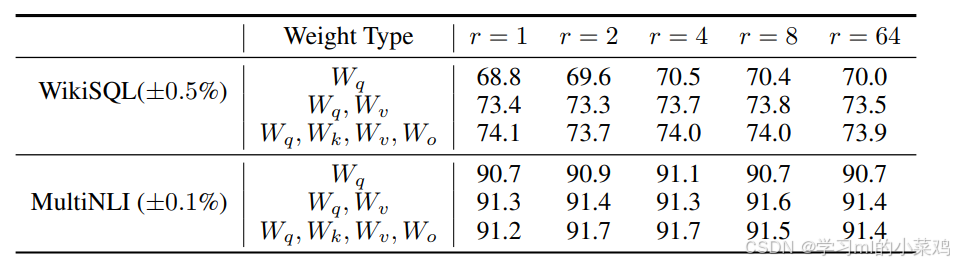
由表可知,即使当r=1时模型精度也取得了非常具有竞争力的结果,这进一步证实了开头的灵感来源:ΔW实际上是可以用一个固有的低秩矩阵表示的。
2.2.1 不同r之间的子空间相似度
为求证此假设,作者需要计算不同秩对应的子空间之间的重叠程度(如果用较低的r就能近似地表示较高的r形成的矩阵,那么使用r较低的矩阵就足够了)。因此作者又做了以下实验对比r=8和r=64的空间相似度。
首先前面已经提到h=W0*x+ΔW*x=W0*x+BA*x,如果我们把预训练的Wo权重矩阵的大小设为d*k,则B的大小为d*r,A的大小为r*k,Ar=8、Ar=64分别意味着A的大小为8*k和64*k。如果transformer层的预训练矩阵取的是512,那么这里的k=512。
由于A不是方阵不能进行特征值分解,故对A进行奇异值分解(SVD):
我们把这里的U称为左奇异矩阵,V’称为右奇异矩阵,U和V都是酉矩阵(正交单位矩阵),∑是对角矩阵,对角线上是A的奇异值(或者称为AA’的特征值),因此对于Ar=8(64)分解后,UAr=8的大小为8*8,UAr=64的大小为64*64。这里我们限制分析第48层(共96层),但结论也适用于其他层。
接着分解后我们用格拉斯曼距离表示子空间的相似度(计算公式如下所示,越接近1越相似,越接近0越不相似),
表示UAr=8前i个列向量组成的子矩阵。
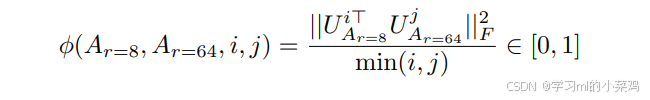
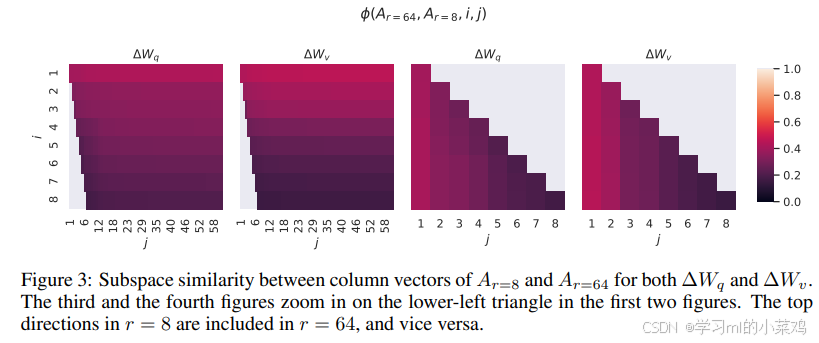
最后我们把不同子矩阵的相似度表示成热力图(颜色越浅,相似度越高,重叠度越高),右边两幅图是左边两幅图左下角的放大展示,由左边两图可以发现:i=1时相似度最高(无论是对ΔWq还是ΔWv矩阵),随着取得的向量维数增大,相似度逐渐减小。由右边两图可以取得相同结论:一个很小的j能取得很大的相似度,因此从图中可以得到结论:Ar=8和Ar=64的顶部奇异向量方向是最有用的(顶部奇异方向指最大奇异值相对应的向量,这里可能是将U中的列向量按奇异值排序了,因此就是指的i=1时的向量),而其他方向可能包含在训练过程中积累的大部分随机噪声。因此,适应矩阵确实可以有很低的秩。
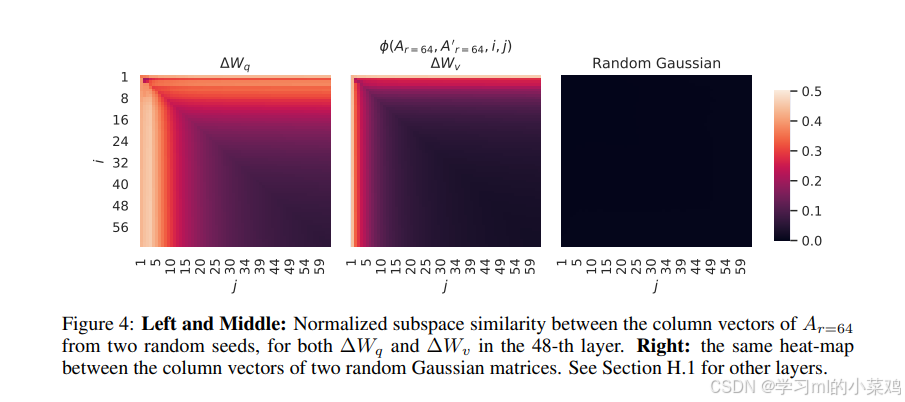
2.2.2 不同随机种子之间的子空间相似性
为了进一步验证不同随机种子之间的子空间相似性。我们通过绘制r = 64的两个随机种子运行的归一化子空间的相似性证实了这一点,如下图所示:Ar=64和A'r=64是使用两个不同随机种子得到的Ar=64,左图和中图都说明不同随机种子的子空间具有相似性,左图和中图作比较看出∆Wq似乎比∆Wv具有更高的“内在秩”(因为图中浅色的带要宽些,即两次运行对∆Wq学习了更多常见的奇异值方向)右图是两个随机高斯矩阵的列向量之间相同的热图,它们彼此之间没有重叠的奇异值方向。
2.3 ∆W与W的关系
∆W和W是否高度相关?为了回答这个问题,我们通过计算U'WV' 将W投影到∆W的r维子空间上,其中U/V分别为∆W的左/右奇异向量矩阵。然后比较了两个范数大小。得出下表(表中的U、V分别取ΔWq,Wq和random左/右矩阵的前r个奇异向量),从中得出结论:首先,与随机矩阵相比,∆W与W的相关性更强,说明∆W放大了W中已经存在的一些特征。其次,∆W并没有重复W的最上面的奇异方向,而是只放大了W中没有强调的方向。第三,放大系数非常大:当r = 4时,其放大系数为6.91/0.3221.5。
这表明低秩适应矩阵潜在地放大了特定下游任务的重要特征,这些特征是在一般预训练模型中学习到的,但没有被强调。

这一部分工作在数学上的要求可能较高,如果实在看不懂细节的,大致了解下结论即可。如果实在对推理过程感兴趣但是不能完全理解上面文字部分的,推荐看下面的b站视频,up主关于实验部分讲的绝大多数我觉得都没有什么问题,大家可以辩证地辅助学习下【论文精读】LoRA(下):爆火的stable-diffusion模型微调方法_哔哩哔哩_bilibili
3. 未来工作
原文在结尾提到的四个future work方向分别是:
- LoRA与其他高效适应方法的结合:LoRA可以与其他高效的适应方法结合使用(如prefix tuing和adapter),可能会提供相互独立的改进。
- LoRA与微调机制的解释:微调或LoRA背后的机制目前还不清楚——预训练阶段学习到的特征是如何转化为在下游任务上表现良好的特征的?作者认为,相比于完整的微调,LoRA可能更容易回答这个问题。这是因为LoRA通过引入低秩矩阵来调整模型参数,这种方式可能更容易分析和理解特征的转换过程。
- LoRA权重矩阵选择的启发式方法:目前,我们主要依赖于启发式方法来选择应用LoRA的权重矩阵。这意味着在实际应用中,人们往往是基于经验而非严格的理论依据来决定哪些参数需要调整。作者提出了一个问题,即是否存在更有原则性的方法来选择这些权重矩阵,这可能涉及到更深入的理论分析和算法设计。
- ∆W的秩不足与W的秩不足:∆W的秩亏表明原始的权重矩阵W也可能存在秩亏的问题。这一点可以为未来的研究提供灵感,即研究者可以探索权重矩阵的秩亏对模型性能的影响,以及如何利用这一点来改进模型。(个人理解秩亏:当用低秩矩阵就能表示的时候用了高秩矩阵就是秩亏)
4. LoRA变体
针对文章中的future work展望以及其他ideas,LoRA自2021年提出以来,催生了很多变体。这些变体在优化模型的适应性、提高效率等方面做出了不同的贡献。以下是一些主要的LoRA变体及其特点的总结:
1. AdaLoRA[2303.10512] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
- 提出时间: 2023年
- 优势:引入自适应优化算法,根据每个任务的特点动态调整低秩矩阵的秩值和更新策略,使得微调过程更加灵活高效。在LoRA基础上通过更智能地选择和调整权重矩阵的秩,实现了对LoRA的改进。
2. Q-LoRA (Quantized LoRA)
[2305.14314] QLoRA: Efficient Finetuning of Quantized LLMs
- 提出时间: 2023年
- 优势: 在LoRA的基础上引入了量化技术,进一步压缩模型参数。通过量化权重,将模型的存储需求降低,适用于更大规模的模型和更小的硬件。方法:首先将LLM进行4位量化,从而显著减少模型的内存占用。接着使用低阶适配器(LoRA)方法对量化的LLM进行微调。
3. LoRA+
[2402.12354] LoRA+: Efficient Low Rank Adaptation of Large Models
- 提出时间: 2024年
- 优势: LoRA+通过引入不同的学习率来优化矩阵A和B的训练过程。在实践中,可以通过实验来找到最佳的学习率比率λ,以进一步提高模型的性能和微调速度。对于 LoRA 中使用的AB矩阵,原文中设置的学习率相同,但是LoRA+ 的作者证明,单一学习率并不是最优的。将矩阵 B 的学习率设置得比矩阵 A 的学习率高得多,训练就能变得更加高效。
4. LoRA with Knowledge Distillation (KD-LoRA)
- 提出时间: 2024年
- 优势: KD-LoRA 在显著减少资源需求的同时,实现了与 full fine-tuning (FFT) 和 LoRA 相当的性能,提高了小模型的精度,减少了训练时间和资源消耗。结合了LoRA和知识蒸馏(Knowledge Distillation)技术,通过蒸馏方法将大模型的知识迁移到小模型中。
5. PRoLoRA
PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA - ACL Anthology
- 提出时间:2024年
- 优势:引入了部分旋转增强的低秩自适应(PRoLoRA)层内共享机制,有效地规避了对等参数共享方法的缺点,具有卓越的模型容量、实现可行性和广泛的适用性。实验表明,在特定的参数预算和性能目标场景中,PRoLoRA的参数效率显著提高,并且可以扩展到更大的LLM。
这些LoRA变体通过引入不同的技术和方法,进一步优化了LoRA的效率和适用范围。从量化、知识蒸馏到超网络等技术的结合,使得LoRA能够在不同的应用场景下发挥更大的作用。总的来说,LoRA及其变体的优势在于能够在保证性能的前提下显著降低计算资源的消耗,非常适合资源受限的环境。
5. 应用范围
5.1 自然语言处理(NLP)
LoRA 在 NLP 中主要用于高效微调大型语言模型,通过微调特定参数快速适应新任务,例如
-
文本分类:情感分析、垃圾邮件检测
-
文本生成:文章续写、摘要生成、内容创作
-
命名实体识别:提取特定领域的实体(医疗、古籍等)
5.2 计算机视觉(CV)
尽管LoRA最初是为了解决NLP任务提出的,但是最近在CV领域也异常火爆,它能通过高效微调实现图像处理优化,主要应用于以下任务:
-
图像分类:对图像进行类别识别(如猫狗分类)
-
图像生成:Stable Diffusion 是一种基于扩散模型的强大图像生成器。它可以将随机噪声逐步还原为高质量的图像。而LoRA + Stable Diffusion 的结合是一种高效微调方案,通过LoRA能够实现(1)风格迁移:通过微调模型生成特定艺术风格的图像(如油画风格、日漫风格)(2)定制内容生成:针对特定对象微调模型,让 Stable Diffusion 可以生成独特内容(如特定人物特征)(3)小样本适配:从仅有几十张图片中学习生成特定风格或类别的图像。
可以在国内的社区libulibuLiblibAI-哩布哩布AI - 中国领先的AI创作平台上下载LoRA模型,如果可以科学上网的话也可以选择huggingface huggingface-LoRA
下图为在Google上找的一些关于SD+LoRA 的内容,能够让图像生成变得更加有趣好玩:
结语: 后面可能想在了解下实际操作中调用LoRA微调LLM的方法和社区中的一些好玩的LoRA内容,关于实战部分等有空也会更新下。由于一些细节原文可能也没有讲的特别清楚,所以解读文章的部分内容可能也只是我的个人理解,如有不足,欢迎评论交流和批评指正。


















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









