






文本分散化表示指将语言表示成低维、稠密、连续的向量,分为静态嵌入和动态嵌入两种方式。静态词嵌入有Word2Vec,Sen2Vec,Doc2Vec,以及GloVe模型;而动态词嵌入有ELMO,Transformer,GPT,Bert和XLNet等等。本文主要对静态词嵌入方法做一个整体介绍,动态词嵌入会在系列2中更新。
目录
静态词嵌入是一种不考虑上下文、固定的词表示方法。例如,Word2Vec、GloVe、FastText等模型生成的词向量都是静态的。这些模型会为每个词分配一个唯一的向量表示,相同的词在不同语境中始终有相同的向量表示。比如在下面这句话:he saw a saw(他看到了一把锯子)中,动词saw和名词saw的词向量是相同的。这种方法的优点是计算简单,能够在较小的计算资源下生成高质量的词表示,但缺点是不能有效区分多义词的不同含义。
1. Word2Vec
Word2Vec由Google在2013年提出,其通过对词在上下文中的共现关系进行建模,使得词向量能够捕捉词的语义信息。具体模型分为CBOW和Skip-gram。
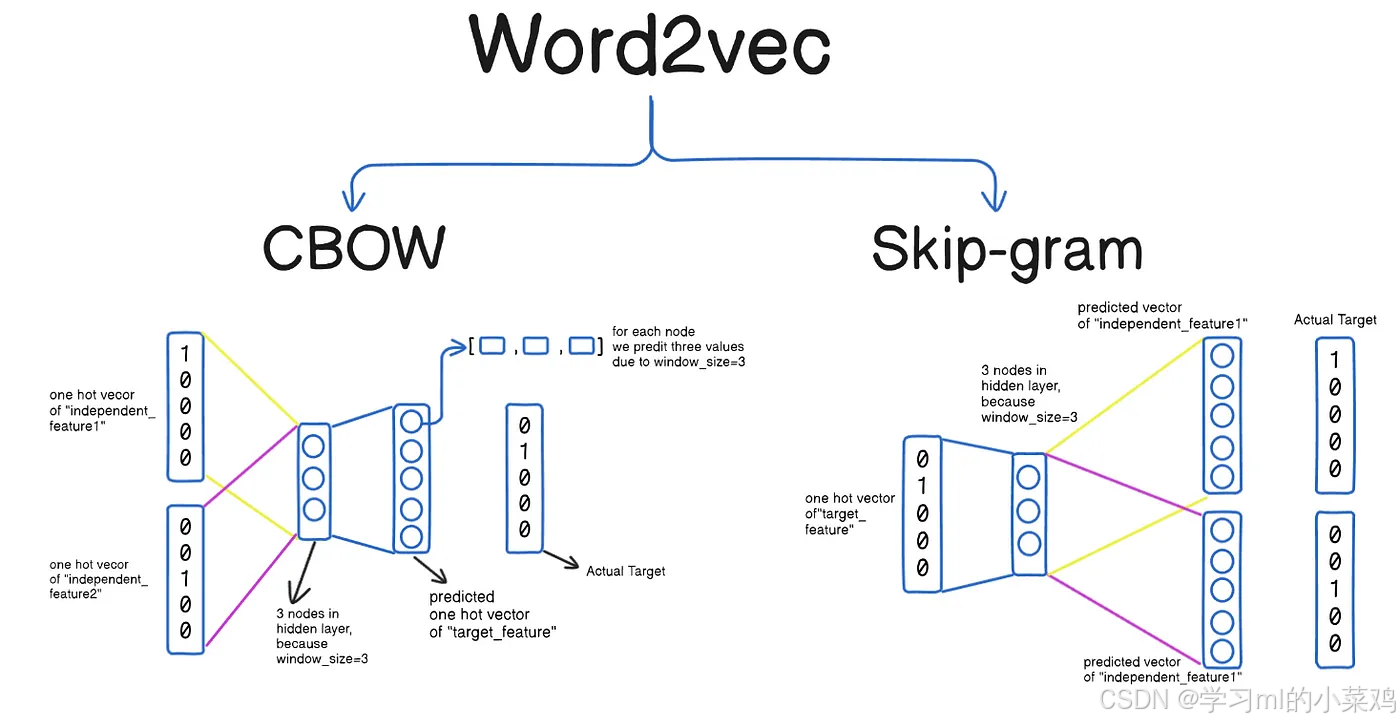
1.1 CBOW
CBOW(Continuous Bag of Words)的目标是通过上下文预测中心词(根据我的朋友判断我)。CBOW模型的特点是基于上下文词的平均向量来预测中心词,具体来说:这个过程大致是词典中的所有词由one-hot编码(假设有v个词),用上下文词编码的平均向量(维度为v)输入Wv*n矩阵变成N维向量得到CBOW的词嵌入表示,然后再经过Wn*v矩阵输出为v维向量,这是我们的预测值,将其与目标中心词的one-hot编码进行比对可以调整两个权重矩阵,从而优化预测结果(整个过程可以结合上图来看比较清楚)
CBOW适合小数据集且训练速度较快(因为它输入多个上下文词来预测一个词)。但是CBOW的平均化操作会减弱一些有用的上下文信息,特别是当上下文中包含稀有词时,模型难以学习到这些稀有词的细节信息。
1.2 Skip-gram
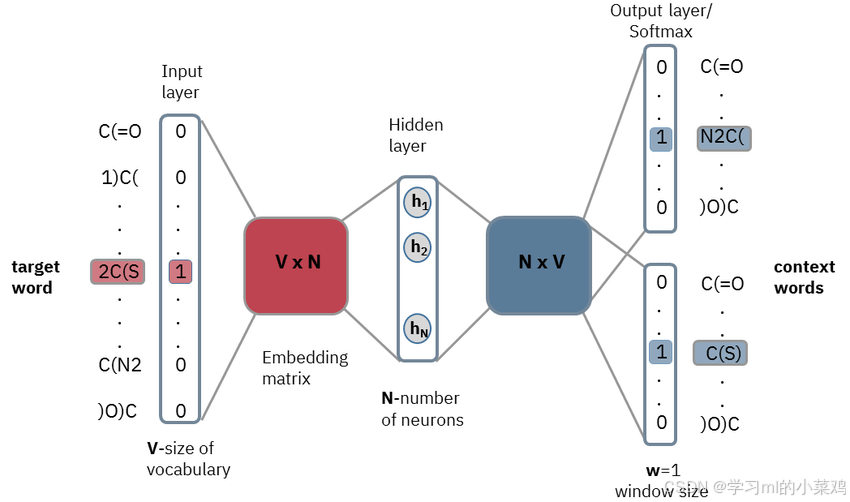
Skip-Gram模型的目标是通过中心词预测上下文词(根据我来判断我的朋友)。Skip-Gram更适合处理大规模语料,并且在稀有词的表示上效果更好。具体过程就是将CBOW的训练反过来了,可以通过上图和CBOW的介绍自己体会。
1.3 Sen2Vec+DocVec
Word2Vec、Sen2Vec 和 Doc2Vec 都是生成文本向量的模型,但它们适用于不同的文本粒度:
(1)Word2Vec:专门用于生成词级别的向量。它通过上下文信息训练每个词的分布式向量表示,因此每个词都有一个固定的向量。适合用于短文本分析或需要将每个词的语义表示融入其他模型的情况。例如分析三国演义中的人物远近关系。
(2)Sen2Vec:用于句子级别的向量表示,类似于 Word2Vec 但不仅仅关注单个单词,而是通过平均多个词向量来生成一个句子级别的嵌入。它考虑了句子中词的组合方式,从而生成更适合表示单一句子语义的向量。适合编码较短的文本段落或独立的句子。
(3)Doc2Vec:引入了段落向量扩展了 Word2Vec,用于生成文档级别的向量表示。它考虑了文档的整体结构和内容,因此可以为整篇文章(或段落)生成一个全局的向量表示,特别适合表示较长文本。比如我们在分析论文摘要、引言相似度的时候就可以对它们进行Doc2Vec操作。
2. GloVe
Glove(Global Vectors for Word Representation)是2014年由斯坦福大学团队提出的一种词嵌入模型。它的基本思想是基于全局词共现矩阵来捕捉词的语义关系。相比Word2Vec主要使用的滑动窗口模型捕捉的是词语在局部上下文中的语法和语义关系,GloVe的优势在于对全局统计信息的更有效利用。
Glove的具体步骤是:
(1)构建全局共现矩阵:根据语料库(如wiki百科、twitter数据等)构建矩阵,即使不在同一个句子里的词汇也能被记录共现情况,离得越远的两个词语在计算共线次数时所占权重越小。
(2)构建损失函数:Glove的loss function如下图所示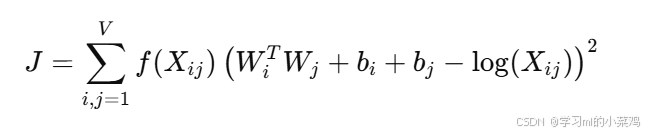
整个损失函数就是使得词向量表示尽可能模拟矩阵中的共现关系,其中Xij是词i和词j的共现频率,Wi和Wj分别是词i和词j的词向量,b代表偏置项,f(Xij)是一个加权函数,用来控制那些共现频率较低的词对词向量的影响。
(3)优化过程:采用梯度下降方法最小化损失函数,更新词向量Wi和Wj
结语:本文主要介绍了分散式文本表示中的两种静态词嵌入方法:Word2Vec和GloVe,如有不足欢迎批评指正。除此之外,文本表示还有one-hot这样的离散表示以及LDA这样的主题模型,后面的动态词嵌入方法也已更新,有需要的可以进一步看看文本向量化-词嵌入方法系列2:动态词嵌入(ELMo+BERT+XLNet)-CSDN博客。


















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









