






1. 引言
近年来,随着深度学习模型规模的不断扩大,预训练大模型(Pre-trained Large Models)在自然语言处理(NLP)、计算机视觉(CV)等领域取得了显著的性能提升。然而,全参数微调(Full Fine-Tuning)在计算资源、存储需求和训练成本等方面存在较大的挑战。因此,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法逐渐受到研究者的关注。PEFT 通过调整少量模型参数,实现高效的迁移学习,在保证性能的同时减少计算成本,特别适用于资源受限环境。
2. PEFT 方法概述
PEFT 的核心思想是冻结预训练模型的大部分参数,仅对新增或特定子集参数进行优化,以实现对下游任务的适配。根据参数调整方式的不同,PEFT 主要包括以下几类方法:
2.1 适配器(Adapter)方法
适配器方法最早由 Houlsby 等人提出,其主要思路是在预训练模型的不同层级插入小规模的前馈网络(Feedforward Network),并仅优化适配器部分的参数。该方法具有以下优势:
-
仅对新增模块进行训练,降低计算开销;
-
适配器模块可独立于主模型存储,便于多任务迁移。
2.2 低秩适配(LoRA)
低秩适配(Low-Rank Adaptation, LoRA)方法在模型权重矩阵上引入低秩分解,通过学习低秩矩阵的参数,实现模型微调。LoRA 方法的优势在于:
-
通过低秩结构减少参数更新数量,有效降低存储开销;
-
适用于 Transformer 结构,能够在保证模型性能的前提下提高训练效率。
2.3 提示调优(Prompt Tuning)
提示调优(Prompt Tuning)是近年来提出的一种微调方法,通过学习特定任务的输入提示(Prompt)向量,使预训练模型更适应特定任务,而无需修改模型内部权重。该方法主要包括:
-
软提示(Soft Prompting):使用可学习的嵌入向量替代离散文本提示;
-
P-Tuning:基于连续优化的方法,引入可学习的提示向量,提高任务适应能力。
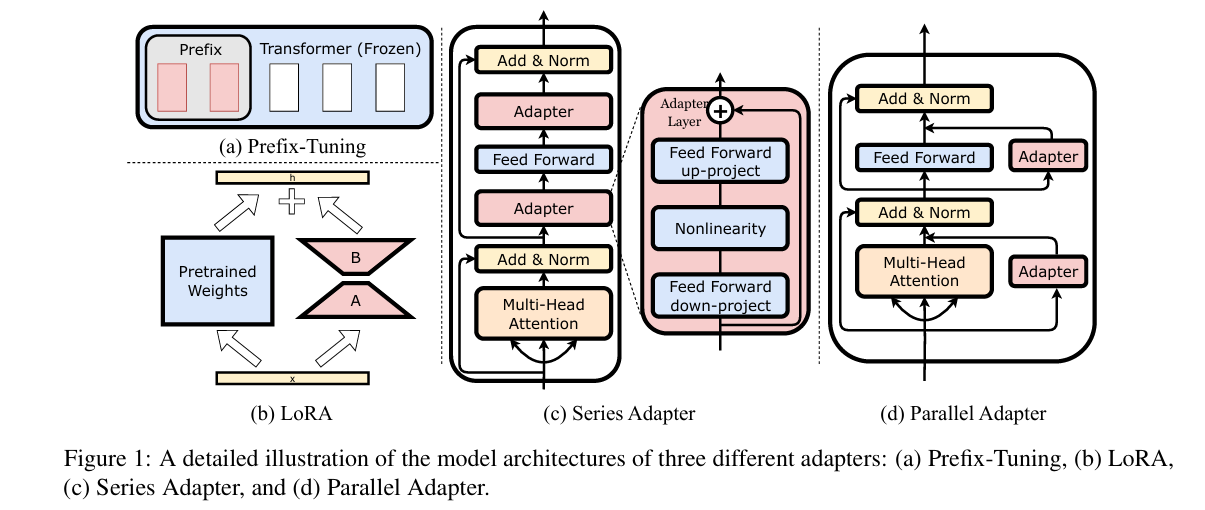
2.4 其他 PEFT 方法
除上述主流方法外,研究者还提出了其他 PEFT 方案,如偏置调优(BitFit)、逐层冻结微调(Layer-wise Freezing)、差分适配(Diff-Pruning)等。这些方法均在减少参数更新的同时,提升模型在特定任务上的表现。
3. PEFT 的优势分析
相较于全参数微调,PEFT 具有以下优势:
-
计算资源消耗低:仅优化少量参数,降低 GPU/TPU 计算需求;
-
存储占用小:适配器、LoRA 等方法仅需存储少量参数,支持高效任务切换;
-
知识保持能力强:冻结预训练模型参数,减少灾难性遗忘问题;
-
多任务适应性好:可通过模块化设计,实现高效的跨任务迁移。
4. 应用场景
PEFT 方法广泛应用于以下场景:
-
自然语言处理(NLP):机器翻译、情感分析、文本生成等任务;
-
计算机视觉(CV):图像分类、目标检测、图像生成等;
-
跨模态任务(Multi-Modal Tasks):结合文本与图像,进行多模态生成与理解。
5. 未来研究方向
尽管 PEFT 在多个领域取得了良好效果,但仍存在一些挑战和未来研究方向,包括:
-
更高效的参数压缩策略:进一步降低计算复杂度,提高推理效率;
-
更强的跨任务泛化能力:研究如何在多个任务之间共享 PEFT 模块;
-
结合自适应学习方法:引入元学习(Meta-Learning)、强化学习(Reinforcement Learning)等技术,提高微调效率;
-
探索 PEFT 在大模型中的应用:特别是在 GPT-4、Gemini 等超大规模模型上的优化方案。
6. 结论
参数高效微调(PEFT)作为一种高效的迁移学习方法,在降低计算资源消耗的同时,保证了模型的高性能表现。随着大规模预训练模型的不断发展,PEFT 方法将在更多领域得到应用,并推动 AI 技术的进一步发展。

















 2460
2460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









