






目录
一、算法概述
1.1 算法简介
逻辑回归也称对数几率回归,是一种广义的线性回归分析模型,属于机器学习中的监督学习。值得注意的是,虽然它的名字是“回归”,实际上却是一种分类学习算法。(PS:分类问题输出的结果是离散值,回归问题输出的结果是连续值)从本质来说逻辑回归属于二分类问题(二分类问题是指预测的值只有两个取值:0或1)。
逻辑回归=线性回归+Sigmoid函数
1.2 线性回归
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。给定数据集,其中
.
“线性回归”试图学得一个线性模型以尽可能准确地预测实值输出标记,即 ,使得
。
其中,确定ω和b的关键在于如何衡量f(x)与y之间的差别。因为均方误差是回归任务中最常用的性能度量,因此可以试图让均方误差最小化(最小二乘法)求解ω和b.
线性回归模型可简写为
1.3 Sigmoid函数
Sigmoid函数将输入变换为(0,1)上的输出。它将范围(-inf,inf)中的任意输入压缩到区间(0,1)中的某个值:

Sigmoid函数是⼀个⾃然的选择,因为它是⼀个平滑的、可微的阈值单元近似。sigmoid函数在神经网络中常被用于二元分类任务,因为它可以将输入转换成概率值。Sigmoid函数是一个在生物学中常见的S型函数,也称为逻辑函数,它可以将一个实数映射到(0,1)的区间内。在深度学习和机器学习的上下文中,它经常被用作神经元的激活函数,因为它可以将任意输入压缩到0和1之间,从而方便地进行概率解释。需要注意的是,当输入x非常大或非常小时,Sigmoid函数的梯度会变得非常小,可能导致在训练神经网络时出现梯度消失的问题。
1.4 对数几率回归
将Sigmoid函数代入线性回归函数模型,得到
进一步得到
将y视为样本x作为正例的概率,则1-y则为x作为反例的概率,两者比值为.因此
被称为对数几率。进一步
.
可以推导出
1.5 损失及优化
逻辑回归的损失,称为对数似然损失
其中,y为真实值,为预测值。损失函数值越小越好。因此
当y=1时,值越大越好;当y=0时,
值越小越好
所以完整损失函数为
优化以求得数据集的最佳参数:
a.使用梯度上升算法,其基本思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为,则函数f(x,y)的梯度表示为:
上式意味着沿x方向移动,沿y方向移动
。其中,函数f(x,y)必须要在待计算的点上有定义并且可微。梯度上升算法到达每个点后都会重新估计移动的方向。梯度算子总是指向函数值增长最快的方向,移动量的大小称为步长,记作α。如此迭代,直到满足停止条件。梯度上升的迭代公式是:
b.使用梯度下降优化算法来减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
二、算法实现
2.1 Logistic回归的一般过程
(1)收集数据
(2)准备数据:需要进行距离计算,因此要求数据类型为数值型。结构化数据格式最佳
(3)分析数据
(4)训练算法:训练的目的是为了找到最佳的分类回归系数
(5)测试算法:一旦训练步骤完成,分类将会很快
(6)使用算法:通过训练好的回归系数进行简单的回归计算
2.2训练算法:使用梯度上升找到最佳参数
loadDataSet()函数的主要功能是打开文件testSet.txt文件并逐行读取。每行前两个值分别为X1和X2,第三个值是数据对应的分类标签。
sigmoid()函数根据Sigmoid函数公式得到。
梯度上升算法的实际工作是在函数gradAscent()中完成的,其中,变量alpha是向目标移动的步长,maxCycles是迭代次数,变量h代表一个列向量,这里包含100个数据(样本)。运算dataMatrix*weights包含了(100*3)300次乘积。通过for循环可获得一组回归系数,它确定了不同类别数据之间的分割线。
梯度上升算法伪代码:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha*gradient更新回归系数的向量
返回回归系数
def loadDataSet():
dataMat=[]; labelMat=[]
fr=open("testSet.txt")
for line in fr.readlines():#逐行读取
lineArr=line.strip().split()#对testSet文件进行分割
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#默认X0=1.0,文件中每行的前两个值X1和X2
labelMat.append(int(lineArr[2])) #每行的第三个值(数据的类别标签)
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))#对应Sigmoid函数
def gradAscent(dataMatIn,classLabels):
dataMatrix=mat(dataMatIn)#dataMatIn作为二维数组,每列代表不同的特征,每行代表每个训练样本
labelMat=mat(classLabels).transpose()#类别标签,1*100的行向量进行转置变成列向量再赋值给labelMat
m,n=shape(dataMatrix)
alpha=0.001#目标移动的步长
maxCycles=500#迭代次数为500
weights=ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error#梯度上升算法迭代公式
return weights#返回训练好的回归系数
if __name__=='__main__':
dataArr,labelMat=loadDataSet()
print(dataArr)
print(labelMat)
weights1=gradAscent(dataArr,labelMat)
print(weights1)运行结果:调用上述函数,可以看到在编辑器中出现数据data以数组[X0,X1,X2]形式展现,分类标签是一个1*100的行向量,同时输出梯度上升算法所需的参数,即一组回归系数。
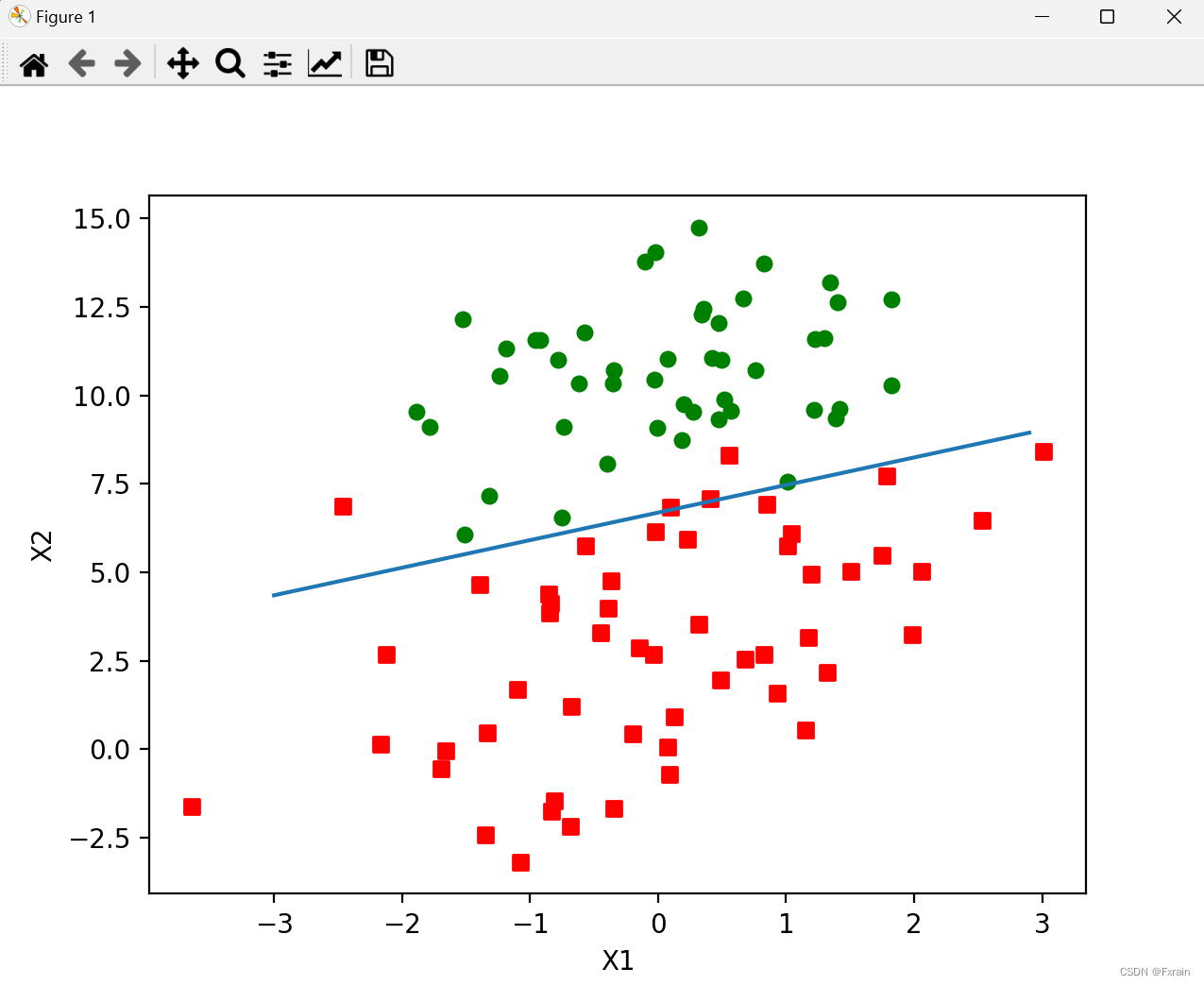
2.3分析数据:画出决策边界
plotBestFit()函数通过使用Matplotlib画出数据集和Loistic回归最佳拟合直线的函数,这里设置了Sigmoid函数为0(0是两个分类<类别1和类别0>的分界处),即 ,然后解出X2和X1的关系式(即分割线的方程,注:X0=1)
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()#获取数据集dataMat和标签集labelMat
dataArr=array(dataMat)#数据集转换为数组操作
n=shape(dataArr)[0]#n为数据集的行数
xcord1=[];ycord1=[]#xcord1和ycord1存储类别为1的数据点
xcord2=[];ycord2=[]#xcord2和ycord2存储类别为2的数据点
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig=plt.figure()#创建图形对象fig
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]#根据weights计算纵坐标y
ax.plot(x,y)
plt.xlabel('X1');plt.ylabel('X2')
plt.show()运行结果:调用函数可以看到绘制的数据集及最佳拟合直线展示在坐标图中。分类结果较好,仅错分几个数据。
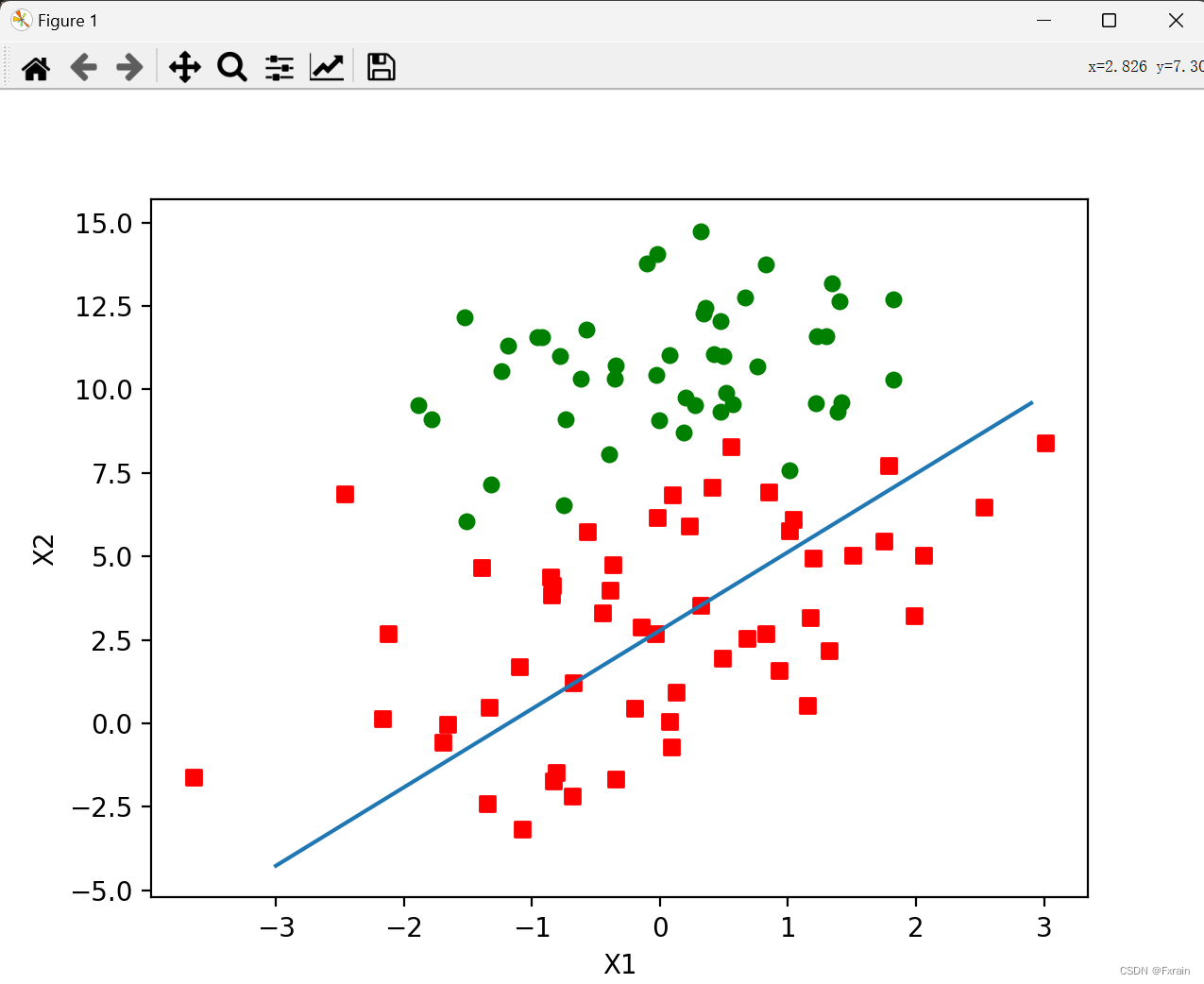
2.4训练算法:随机梯度上升
梯度上升算法在每次更新回归系数时都要遍历整个数据集,当样本数量较多,则会出现计算的复杂度过高问题。对这个问题,有一种改进方法为:一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。由于可以在新样本到来时对分类器进行增量式更新,因此随机梯度上升算法是一个在线学习算法。与“在线学习”相对应,一次处理所有数据被称作“批处理”。
stocGradAscent0()函数表示随机梯度上升算法,算法流程大致与梯度上升算法相似,但是不同之处在于:a.随机上升算法的h和error都是数值而不是向量;b.随机梯度上升算法不需要矩阵转换,所有变量的数据类型都是Numpy数组类型。
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
for i in range(m):
h=sigmoid(sum(dataMatrix[i]*weights))#数值
error=classLabels[i]-h#数值
weights=weights+alpha*error*dataMatrix[i]
return weights运行结果:可以从下图结果看出,随机上升梯度算法的分类器 错分的样本明显多于 梯度上升算法的分类器,但后者在数据集上的迭代过程明显多于前者。
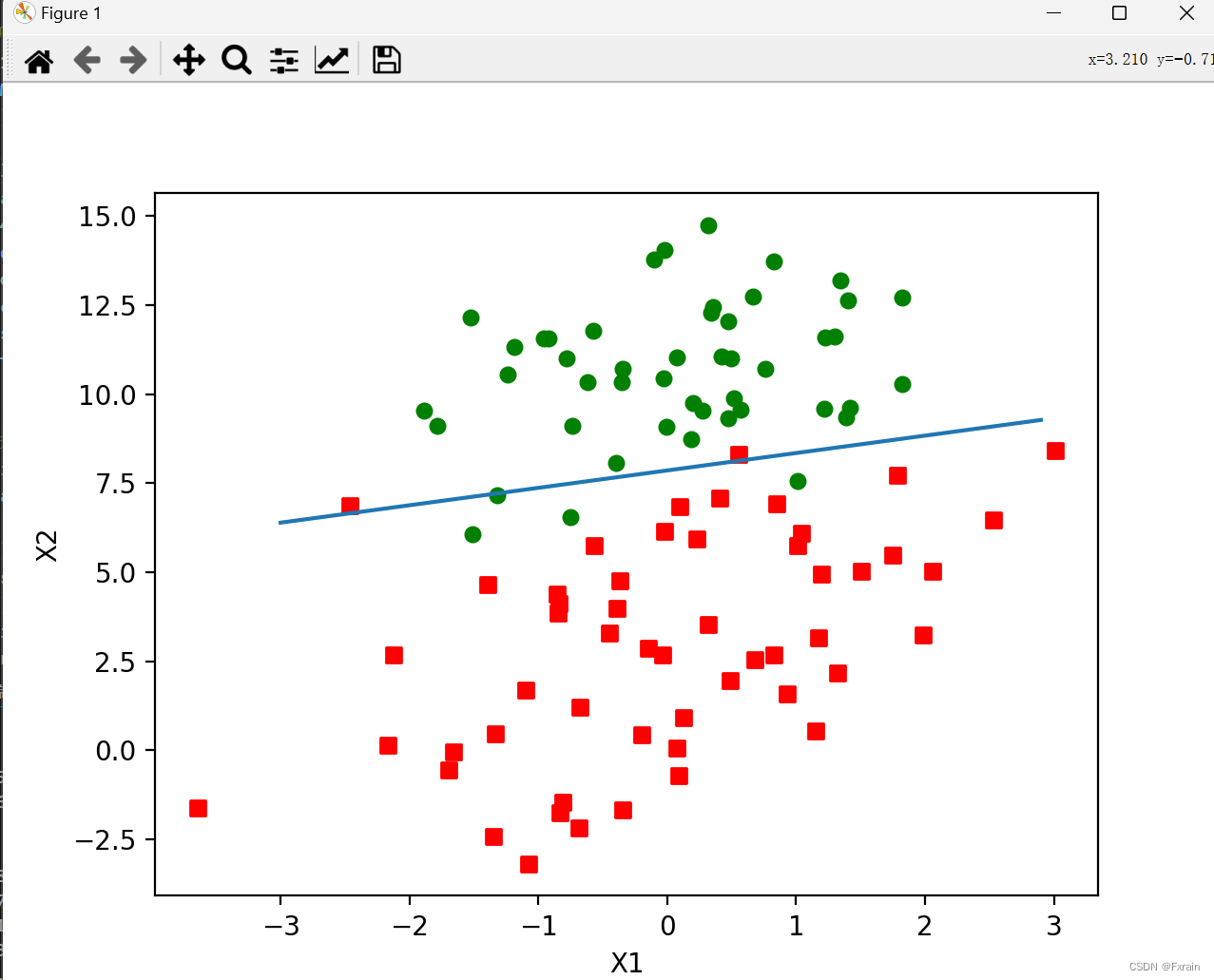
2.5改进梯度上升算法
与随机梯度上升算法相似,改进后的梯度上升算法stocGradAscent1()函数与其不同之处在于:
a.在每次迭代时alpha都会进行调整,这样可以缓解数据波动。同时,alpha随着迭代次数不断减小,但是因为alpha=4/(1.0+j+i)+0.01,有一个常数项,所以alpha不会减小到0。可以根据不同的问题需求更改常数项。其次,在降低alpha函数中,alpha每次减少1/(j+i),其中j是迭代次数,i是样本点的下标(即本次迭代中第i个选出来的样本),当j<<max(i)时,alpha就不是严格下降的。
b.通过随机选取样本来更新回归系数,这种方法可以减少周期性的波动。同时,若是迭代的次数没有给定的话,默认迭代150次。
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n=shape(dataMatrix)
weights=ones(n)
for j in range(numIter):
dataIndex=range(m)
for i in range(m):
alpha=4/(1.0+j+i)+0.01#alpha在每次迭代时都会调整
randIndex=int(random.uniform(0,len(dataIndex)))#随机选取样本
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights运行结果:可以从下图结果看出,改进后的随机梯度上升算法的分类器分类结果优于未改进的随机梯度上升算法,分隔线与gradAscent()函数的分类结果大致相同,但是迭代次数(150次)明显低于gradAscent()函数。
2.6 整体代码展示
#Logistic 回归
from numpy import *
import matplotlib.pyplot as plt
#加载数据集
def loadDataSet():
dataMat=[]; labelMat=[]
fr=open("testSet.txt")
for line in fr.readlines():#逐行读取
lineArr=line.strip().split()#对testSet文件进行分割
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#默认X0=1.0,文件中每行的前两个值X1和X2
labelMat.append(int(lineArr[2])) #每行的第三个值(数据的类别标签)
return dataMat,labelMat
#Sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))#对应Sigmoid函数
#梯度上升算法
def gradAscent(dataMatIn,classLabels):
dataMatrix=mat(dataMatIn)#dataMatIn作为二维数组,每列代表不同的特征,每行代表每个训练样本
labelMat=mat(classLabels).transpose()#类别标签,1*100的行向量进行转置变成列向量再赋值给labelMat
m,n=shape(dataMatrix)
alpha=0.001#目标移动的步长
maxCycles=500#迭代次数为500
weights=ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)#变量h是列向量而不是数值
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error#梯度上升算法迭代公式,这里的error是向量
return weights#返回训练好的回归系数
#绘制图像显示数据集的分布和最佳拟合直线
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()#获取数据集dataMat和标签集labelMat
dataArr=array(dataMat)#数据集转换为数组操作
n=shape(dataArr)[0]#n为数据集的行数
xcord1=[];ycord1=[]#xcord1和ycord1存储类别为1的数据点
xcord2=[];ycord2=[]#xcord2和ycord2存储类别为2的数据点
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig=plt.figure()#创建图形对象fig
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]#根据weights计算纵坐标y
ax.plot(x,y)
plt.xlabel('X1');plt.ylabel('X2')
plt.show()
#随机梯度上升算法
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
for i in range(m):
h=sigmoid(sum(dataMatrix[i]*weights))#数值
error=classLabels[i]-h#数值
weights=weights+alpha*error*dataMatrix[i]
return weights
#改进后的随机梯度上升算法
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n=shape(dataMatrix)
weights=ones(n)
for j in range(numIter):
dataIndex=list(range(m))
for i in range(m):
alpha=4/(1.0+j+i)+0.01#alpha在每次迭代时都会调整
randIndex=int(random.uniform(0,len(dataIndex)))#随机选取样本
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
#main函数调用各个相关函数
if __name__=='__main__':
dataArr,labelMat=loadDataSet()
print(dataArr)
print(labelMat)
weights1=gradAscent(dataArr,labelMat)
print(weights1)
plotBestFit(weights1.getA())
weights2=stocGradAscent0(array(dataArr),labelMat)
plotBestFit(weights2)
weights3=stocGradAscent1(array(dataArr),labelMat)
plotBestFit(weights3)三、总结分析
3.1实验小结
本次实验我们学习了对逻辑回归算法的具体实现,逻辑回归应用于分类问题,常用于二分类问题。逻辑回归的目的就是找到Sigmoid函数的最佳拟合参数,求解最佳拟合参数的过程可以通过最优化算法实现,最优化算法有很多种,比如梯度上升、梯度下降等等。本次实验,我们使用梯度上升优化方法,但是梯度上升算法在处理样本较多的数据时,会有复杂度过高的情况。因此我们又提出了一种处理方法——随机梯度上升算法,仅迭代一次的随机梯度算法的分类器性能较差,所以我们对随机梯度上升算法进行改进,改进后的随机梯度上升算法的结果与梯度上升算法的结果类似,但是迭代的次数明显更少。
3.2参考书籍
《机器学习》 周志华
《机器学习实战》 Peter Harrington















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









