






今日任务
任务:《人工智能入门实践》(北京邮电大学出版社)第三章课后习题(4)。
题目:
试分别用逻辑回归,贝叶斯分类器,SVM模型和决策树分类器等算法,针对手写数字训练集进行训练,并验证不同算法的性能。
我的工作
手写数字识别:逻辑回归,贝叶斯分类器,SVM分类器,决策树的比较.ipynb - Colaboratory (google.com)
import numpy as np#这个numpy的库主要用于数据预处理
import matplotlib.pyplot as plt#这个matplotlib主要用于数据可视化
from sklearn import datasets#datasets模块包含了一些经典的机器学习数据集,可以用于练习和测试机器学习算法。
from sklearn.model_selection import train_test_split#这个主要是将训练集分割为train_set和validation_set的
from sklearn.linear_model import LogisticRegression#从线性回归的模块中导入逻辑回归
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report#计算误差值的
import pandas as pd#一个适用于处理表格化信息的包
digits = datasets.load_digits()#加载MINST(但是是简化版本)
X = digits.data # 特征矩阵。它将每张图都平坦化了(CNN相比平坦化,更能提取到一些特征)
y = digits.target # 目标标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)#将训练集分为train_data和test_data
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# 初始化不同的分类器,用字典来表示
classifiers = {
"Logistic Regression": LogisticRegression(),
"Naive Bayes": GaussianNB(),
"SVM": SVC(),
"Decision Tree": DecisionTreeClassifier()
}
# 训练和评估每个分类器
results = {}
for name, clf in classifiers.items():#对每个分类器进行遍历
clf.fit(X_train, y_train)#clf代表选择的机器学习模型,例如逻辑回归、贝叶斯分类器、SVM模型或决策树等。fit是表示训练方法。
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
results[name] = accuracy#将得到的准确率写入表格
results_df = pd.DataFrame(list(results.items()), columns=['Classifier', 'Accuracy'])
results_df.sort_values(by='Accuracy', ascending=False, inplace=True)
print(results_df)在这里面,我将MINST数据集切割为80%的训练集和20%的测试集。在输入上,我对图片以特征矩阵来储存。然后我直接调用了各个分类器的函数,最后用表格存储识别准确率。
得出的结果
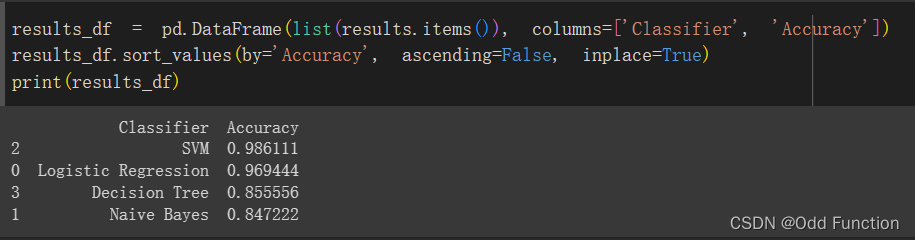
在这次实验中,我得出的结论是:SVM和逻辑回归分类器要好于决策树和贝叶斯分类器。
对结果的分析
SVM(支持向量机)和逻辑回归在手写数字识别上表现较好的原因包括以下几个因素:
1.非线性决策边界:手写数字识别问题通常具有复杂的非线性特征。SVM通过使用核技巧可以学习非线性决策边界,允许它更好地捕捉数字的复杂形状和结构。逻辑回归虽然是线性分类器,但通过适当的特征工程和多项式特征,也可以处理一定程度的非线性问题。
(核技巧的核心思想是将原始特征空间映射到一个高维特征空间,其中数据可能更容易分离。这个映射是通过所谓的“核函数”完成的。这些核函数将数据点从低维空间映射到高维空间,使得原本线性不可分的问题在高维空间中变得线性可分。)
2.高维特征空间:手写数字的图像通常由像素组成,每个像素都可以看作是一个特征。这意味着输入数据的维度非常高。SVM和逻辑回归对于高维特征空间有良好的适应性,因为它们不容易受到维度灾难的影响。
(维度灾难:
数据稀疏性:随着维度的增加,数据点在高维空间中变得更加稀疏。这意味着数据点之间的距离变得更远,而且可能需要更多的数据来获得可靠的统计信息。
过拟合:在高维空间中,模型更容易过拟合训练数据,因为模型有更多的参数可以调整,而训练数据相对较少。这可能导致模型在训练数据上表现出色,但在未见过的数据上表现不佳。)
(为什么它们在高维空间中适应良好的原因:
间隔最大化(SVM):SVM的主要目标是找到一个最佳的超平面,以最大化不同类别之间的间隔。这种最大化间隔的性质使得SVM对于高维数据具有鲁棒性,因为在高维空间中,数据点之间的距离通常更大,使得超平面的选择更有代表性。这使SVM在高维空间中更容易找到适当的决策边界。
支持向量关注(SVM):SVM的决策边界仅依赖于离边界最近的一小部分训练数据点,这些数据点称为支持向量。在高维空间中,大多数数据点对于决策边界的位置不会有太大影响,因为它们相对较远。这意味着SVM的性能主要受到支持向量的影响,而不受到维度的过高影响。
正则化(逻辑回归):逻辑回归通常使用正则化项来防止过拟合,特别是在高维空间中。正则化可以帮助控制模型的复杂度,从而减少模型对高维数据的过度拟合,提高泛化能力。
特征选择(SVM和逻辑回归):SVM和逻辑回归可以与特征选择技术结合使用,以从高维数据中选择最相关的特征。这有助于降低维度,减少冗余特征,提高模型的效率和泛化性能。
核技巧(SVM):SVM的核技巧允许将数据从原始特征空间映射到高维特征空间,使得原本线性不可分的问题在高维空间中变得线性可分。这使得SVM能够更好地捕捉高维数据中的模式。)
3.对异常值的鲁棒性:SVM和逻辑回归在决策边界附近的支持向量上关注,对于手写数字识别问题,这些支持向量通常是数字的关键点。这种关注方式使它们具有较好的鲁棒性,能够抵御噪声和异常值的干扰。
今日收获
明白了有监督学习的三步
-
实例化。即针对采用的算法进行实例化,也就是定义评估模型对象。
from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression LR_regr = LinearRegression() # 实例化,定义一个线性回归器 LR_regr.fit(X_train, y_train) # 应用训练集进行模型训练 y_predict = LR_regr.predict(X_test) # 对测试集进行预测 # 对比预测结果和真实值(Grand_truth),对前30个测试结果可视化 plt.figure(figsize=(16,4)) plt.plot(range(30), y_test[:30], color='black', label="truth") plt.plot(range(30), y_predict[:30], color='red', label="predict") plt.legend()例如上面第三行代码就是将LinearRegression层进行实例化,成为LR_regr。
-
训练。即调用模型接口在训练数据上训练模型,也就是进行数据拟合,训练模型,确定对象的内置参数。各种算法都提供了统一的fit函数接口进行训练。
-
测试。训练完成后,模型对象的内置参数就确定了,然后就可以通过这个模型对象对新数据进行预测。通常算法都提供了统一的predict函数接口进行预测。 通过统一的训练和测试接口,使得我们在应用各种模型解决实际问题时都极为方便。
学会了用joblib包进行模型持久化
所谓模型持久化,就是将已经训练好的,参数确定的模型保存下来。通常这些模型的后缀为.ckpt或者.joblib
这样做的好处是:
1.适合模型在不同的环境下运行。
2.下次要进行预测的时候,就可以直接调用这个训练好的模型,就不用重新训练了。

(例如这个就是持久化模型的代码和导入模型的代码)
了解了scikit-learn的好处
他这个包能够将机器学习的各个算法进行封装,使得读者在利用该工具包解决问题时不需要涉及具体的算法原理。这样大大降低了应用的复杂度。但是我感觉,要面人工智能算法岗的同学还是要接触到他的具体原理。















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









