






一、数据操作
N维数组是机器学习及深度学习主要的数据结构。一个数字被称为标量;一个一维数组被称为向量;一个二维数组被称为特征矩阵;常用的3维数组,例如RGB图片;常用4维数组,例如一个RGB图片批量。
二、数据预处理
(1)手动创建模拟数据集
import os
os.makedirs(os.path.join("demo1",'data'),exist_ok=True)
data_file = os.path.join('demo1','data','house_tiny.csv') # 在demo文件夹下创建一个名为data的csv文件,模拟数据集
with open(data_file,'w') as f:
f.write('NumRooms,Alley\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')(2)从创建的csv文件中加载原始数据集
data = pd.read_csv(data_file) # 使用read_csv方法对csv数据集进行原始读取
print(data)输出结果:
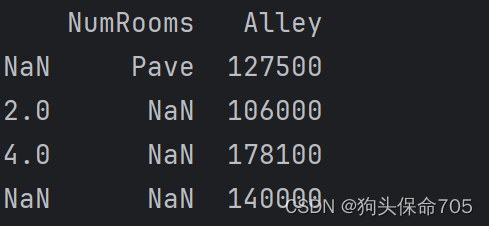
(3)处理缺失的数据
常用数据处理操作包括插值和删除。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # 将读取的数据分成inputs和outputs2块,inputs包括前2列内容,outputs包括第3列内容
inputs = inputs.fillna(inputs.mean(numeric_only=True)) # 判断inputs中值为NaN的数据,如果为NaN,则将不为NaN的数据的均值重新赋给为NaN的数据结果:

接下来处理Alley所在列的NaN。
inputs = pd.get_dummies(inputs,dummy_na=True) # 判断Alley列的数据,如果为Pave则Alley_Pave为1,如果为NaN则Alley_nan为1结果为:
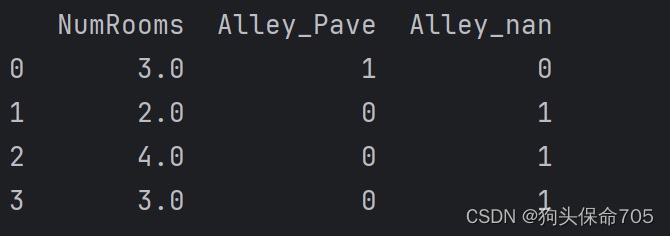
经过预处理后,已经将csv文件转换为一个纯数字构成的矩阵了,此时就可以将矩阵转换为张量了。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









