






下载yolo系列集成的库:pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple(ultralytics可以指定版本号,像yolov8只与部分版本适配,yolov11因为是才出来不久直接下载即可)
YOLOv11指导官方文档:https://docs.ultralytics.com/zh/models/yolo11/
YOLOv11训练官方地址:https://docs.ultralytics.com/modes/train/
YOLOv11官方推理(测试)地址:https://docs.ultralytics.com/zh/modes/predict/
一、配置数据集文件格式(以打架数据集为例)
-
图片数据(images)与标签数据(labels)分别存在不同的文件下
-
train.cache和val.cache文件是在训练过程中产生的,主要用于存储缓存数据。这些缓存数据是为了加速训练过程中的数据加载和预处理环节而生成的。 -
-
images为存放图片数据的文件夹
-
train:训练集图片文件夹
-
val:验证集图片文件夹

-
-
labels为存放标签数据的文件夹(标签数据与图片数据一一对应)
-
train:训练集标签文件夹
-
val:验证集标签文件夹

-
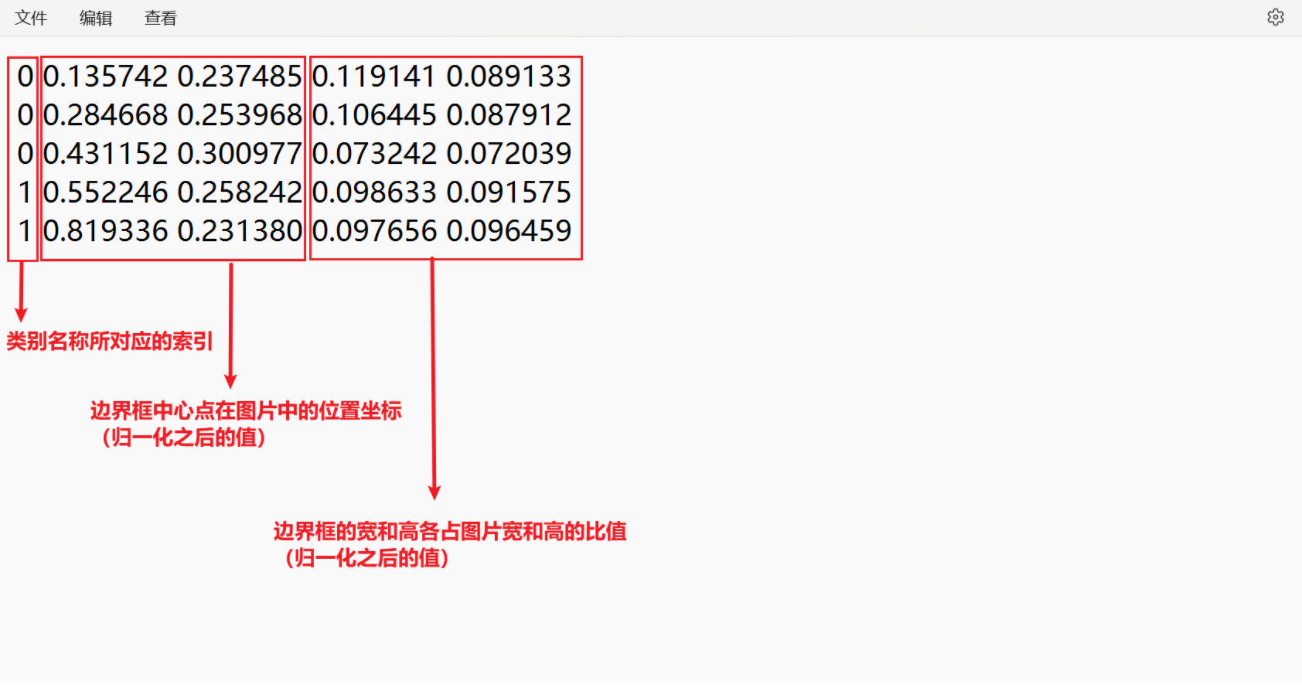
标签文件内容
-
-
-
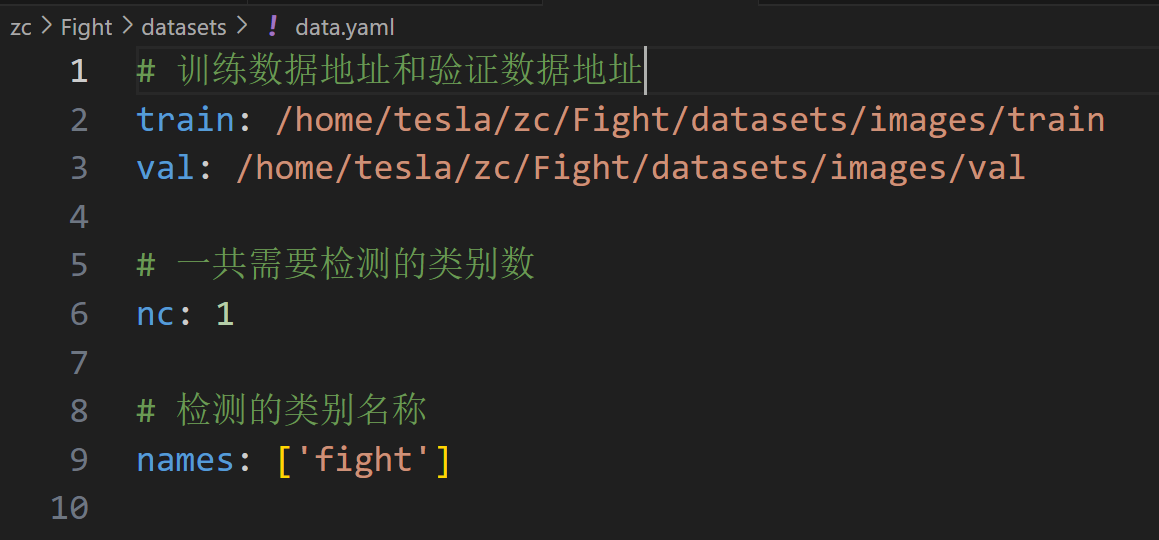
数据集配置文件(data.yaml)内容格式,这里只需要给定训练集和验证集的图片路径
二、YOLOv11训练及测试的参数解释
1、训练:model.train () 参数
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| model | str | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | str | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练和 验证数据类名和类数。 |
| epochs | int | 100 | 训练历元总数。每个历元代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
time | float | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
patience | int | 100 | 在验证指标没有改善的情况下,提前停止训练所需的历元数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
| batch | int | 16 | 批量大小有三种模式: 设置为整数(如 batch=16)、自动模式,内存利用率为 60%GPU (batch=-1),或指定利用率的自动模式 (batch=0.70). |
| imgsz | int 或 list | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | bool | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
save_period | int | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
cache | bool | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O,提高训练速度,但代价是增加内存使用量。 |
| device | int 或 str 或 list | None | 指定用于训练的计算设备:单个GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu) 或MPS for Apple silicon (device=mps). |
workers | int | 8 | 加载数据的工作线程数(每 RANK 如果多GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多GPU 设置。 |
project | str | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
name | str | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
exist_ok | bool | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
pretrained | bool | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
optimizer | str | 'auto' | 为培训选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
seed | int | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
deterministic | bool | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
single_cls | bool | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
classes | list[int] | None | 指定要训练的类 ID 列表。有助于在训练过程中筛选出特定的类并将其作为训练重点。 |
rect | bool | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
cos_lr | bool | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
close_mosaic | int | 10 | 在训练完成前禁用最后 N 个历元的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
resume | bool | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
amp | bool | True | 启用自动混合精度(AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
fraction | float | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
profile | bool | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
freeze | int 或 list | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
lr0 | float | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
lrf | float | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
momentum | float | 0.937 | 用于 SGD 的动量因子,或用于Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
weight_decay | float | 0.0005 | L2正则化项,对大权重进行惩罚,以防止过度拟合。 |
warmup_epochs | float | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
warmup_momentum | float | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
warmup_bias_lr | float | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
box | float | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
cls | float | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
dfl | float | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
pose | float | 12.0 | 姿态损失在姿态估计模型中的权重,影响着准确预测姿态关键点的重点。 |
kobj | float | 2.0 | 姿态估计模型中关键点对象性损失的权重,平衡检测可信度与姿态精度。 |
nbs | int | 64 | 用于损耗正常化的标称批量大小。 |
overlap_mask | bool | True | 决定是将对象遮罩合并为一个遮罩进行训练,还是将每个对象的遮罩分开。在重叠的情况下,较小的掩码会在合并时覆盖在较大的掩码之上。 |
mask_ratio | int | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
dropout | float | 0.0 | 分类任务中正则化的丢弃率,通过在训练过程中随机省略单元来防止过拟合。 |
val | bool | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
plots | bool | False | 生成并保存训练和验证指标图以及预测示例图,以便直观了解模型性能和学习进度。 |
from ultralytics import YOLO
# 模型配置文件
model_yaml_path = "/home/tesla/anaconda3/envs/zcenv/lib/python3.10/site-packages/ultralytics/cfg/models/11/yolo11.yaml"
# 数据集配置文件
data_yaml_path = "/home/tesla/zc/Fight/datasets/data.yaml"
# 预训练模型
pre_model_name = "/home/tesla/zc/Fight/yolo11n.pt"
# 加载预训练模型
if __name__ == '__main__':
# 加载预训练模型
model = YOLO(model_yaml_path).load(pre_model_name)
# 训练模型
results = model.train(data=data_yaml_path,
epochs=10,
batch=8,
name='train_v11_SGD', # 保存结果的文件夹名称
optimizer='SGD' # 优化器
)
2、测试:model.predict () 参数
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
source | str | 'ultralytics/assets' | 指定推理的数据源。可以是图像路径、视频文件、目录、URL 或用于实时馈送的设备 ID。支持多种格式和来源,可灵活应用于不同类型的输入。 |
| conf | float | 0.25 | 设置检测的最小置信度阈值。如果检测到的对象置信度低于此阈值,则将不予考虑。调整该值有助于减少误报。 |
| iou | float | 0.7 | 非最大抑制 (NMS) 的交叉重叠(IoU) 阈值。较低的数值可以消除重叠的方框,从而减少检测次数,这对减少重复检测非常有用。 |
| imgsz | int 或 tuple | 640 | 定义用于推理的图像大小。可以是一个整数 640 或一个(高度、宽度)元组。适当调整大小可以提高检测效率 精确度 和处理速度。 |
half | bool | False | 启用半精度(FP16)推理,可加快支持的 GPU 上的模型推理速度,同时将对精度的影响降至最低。 |
| device | str | None | 指定用于推理的设备(例如:…)、 cpu, cuda:0 或 0).允许用户选择CPU 、特定GPU 或其他计算设备执行模型。 |
| batch | int | 1 | 指定推理的批量大小(仅当来源为 目录、视频文件或 .txt 文件).更大的批次规模可以提供更高的吞吐量,缩短推理所需的总时间。 |
max_det | int | 300 | 每幅图像允许的最大检测次数。限制模型在单次推理中可以检测到的物体总数,防止在密集场景中产生过多的输出。 |
vid_stride | int | 1 | 视频输入的帧间距。允许跳过视频中的帧,以加快处理速度,但会牺牲时间分辨率。数值为 1 时会处理每一帧,数值越大越跳帧。 |
stream_buffer | bool | False | 决定是否对接收到的视频流帧进行排队。如果 False, old frames get dropped to accommodate new frames (optimized for real-time applications). If `True’, queues new frames in a buffer, ensuring no frames get skipped, but will cause latency if inference FPS is lower than stream FPS. |
visualize | bool | False | 在推理过程中激活模型特征的可视化,从而深入了解模型 "看到 "了什么。这对调试和模型解释非常有用。 |
augment | bool | False | 可对预测进行测试时间增强(TTA),从而在牺牲推理速度的情况下提高检测的鲁棒性。 |
agnostic_nms | bool | False | 启用与类别无关的非最大抑制 (NMS),可合并不同类别的重叠方框。这在多类检测场景中非常有用,因为在这种场景中,类的重叠很常见。 |
classes | list[int] | None | 根据一组类别 ID 过滤预测结果。只有属于指定类别的检测结果才会返回。这对于在多类检测任务中集中检测相关对象非常有用。 |
retina_masks | bool | False | 返回高分辨率分割掩码。返回的掩码 (masks.data) 如果启用,将与原始图像大小相匹配。如果禁用,它们将与推理过程中使用的图像大小一致。 |
embed | list[int] | None | 指定从中提取特征向量或嵌入的层。这对聚类或相似性搜索等下游任务非常有用。 |
project | str | None | 保存预测结果的项目目录名称,如果 save 已启用。 |
name | str | None | 预测运行的名称。用于在项目文件夹内创建一个子目录,在下列情况下存储预测输出结果 save 已启用。 |
""" 这里结合Opencv,以检测视频的方式来测试模型效果如何 """
from ultralytics import YOLO
import cv2
# 最优模型参数保存文件
path = 'best.pt'
# 模型加载
model = YOLO(path, task='detect')
# 需要预测的视频文件
cap = cv2.VideoCapture('test.mp4')
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 模型预测
results = model.predict(frame, iou=0.75, conf=0.6)
res = results[0].plot()
# 显示结果
cv2.imshow('results', res)
# 按下ESC键退出
if cv2.waitKey(10) == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









