







前言
最近 AI 技术越来越火,很多公司和开发者都想在自己的应用里加入 AI 功能。DeepSeek 是一个性价比很高的 AI 平台,提供了多种部署方式,适合不同需求的用户。不管你是个人开发者、小团队,还是大公司,DeepSeek 都能帮你找到合适的解决方案。
这篇文章会详细讲解 DeepSeek 的四种主要部署方式:API 调用、模型推理服务器、本地部署和混合云部署。我们会分析每种方式的优缺点、费用和适用场景,帮你选出最适合的方案。无论你是刚接触 DeepSeek,还是想优化现有的部署,这篇文章都会给你实用的建议。

方案一:调用 API + DeepSeek 服务器
1. 方案简介
此方案通过调用 DeepSeek 提供的 API,直接利用其服务器进行推理任务。可以选择开发自有应用,或者使用 DeepSeek 官方推荐的客户端进行集成,例如:DeepSeek 官方推荐集成方式。
2. 费用说明
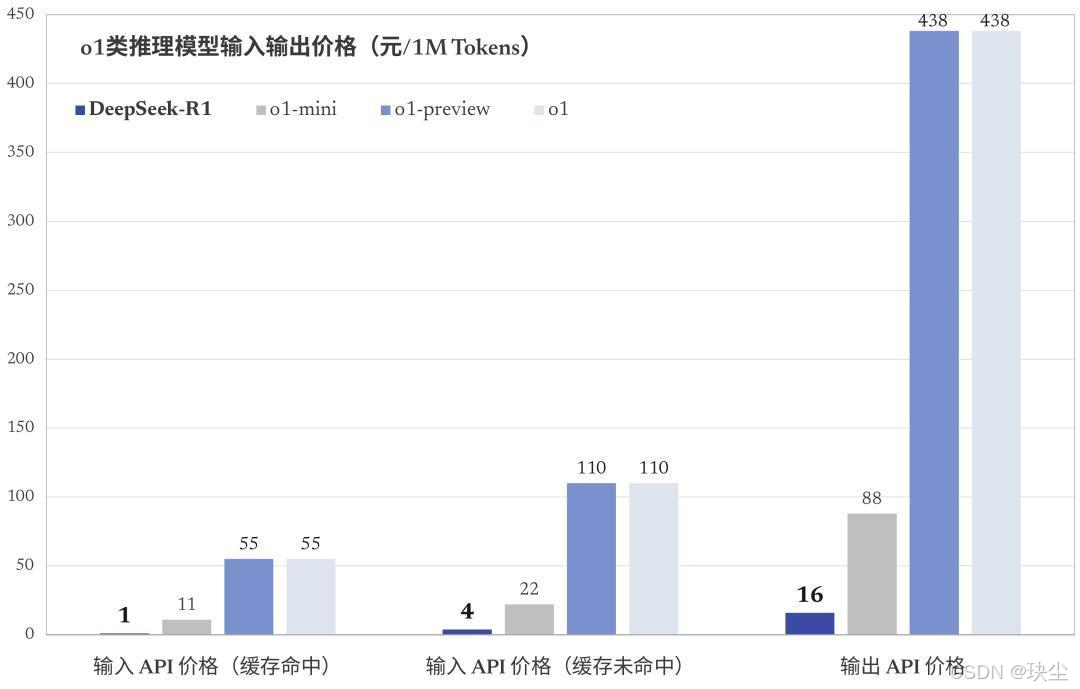
DeepSeek API 采用按 Token 计费的方式,价格如下:
- 普通模型(DeepSeek-V3)
- 输入:每百万 tokens 0.5 元(缓存命中)/ 2 元(缓存未命中)
- 输出:每百万 tokens 8 元
- 推理模型(DeepSeek-VL)
- 输入:每百万 tokens 1 元(缓存命中)/ 4 元(缓存未命中)
- 输出:每百万 tokens 16 元
3. 方案优缺点分析
优点
✅ 低部署成本:无需购买高性能服务器,直接调用 API 即可使用。
✅ 维护压力小:DeepSeek 服务器负责模型维护、升级,无需自行优化推理性能。
✅ 高效迭代:可以快速集成到现有应用,减少开发周期。
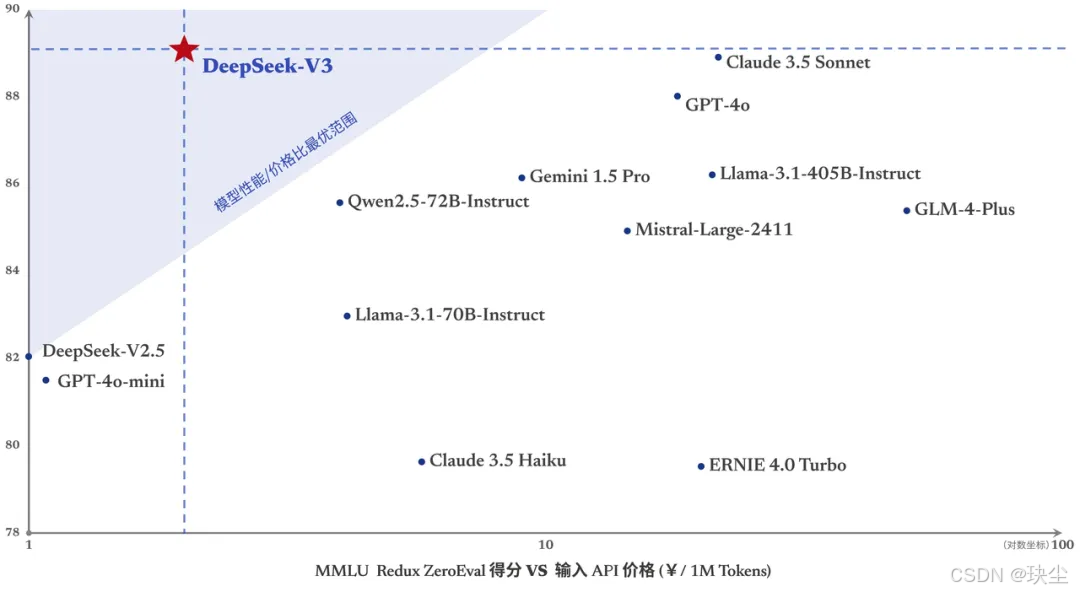
✅ 价格相对低廉:相比其他大模型 API(如 OpenAI GPT),DeepSeek 的 API 价格更具竞争力。
✅ 可选缓存优化:如果请求可以缓存命中,成本更低,适用于高重复请求场景。
缺点
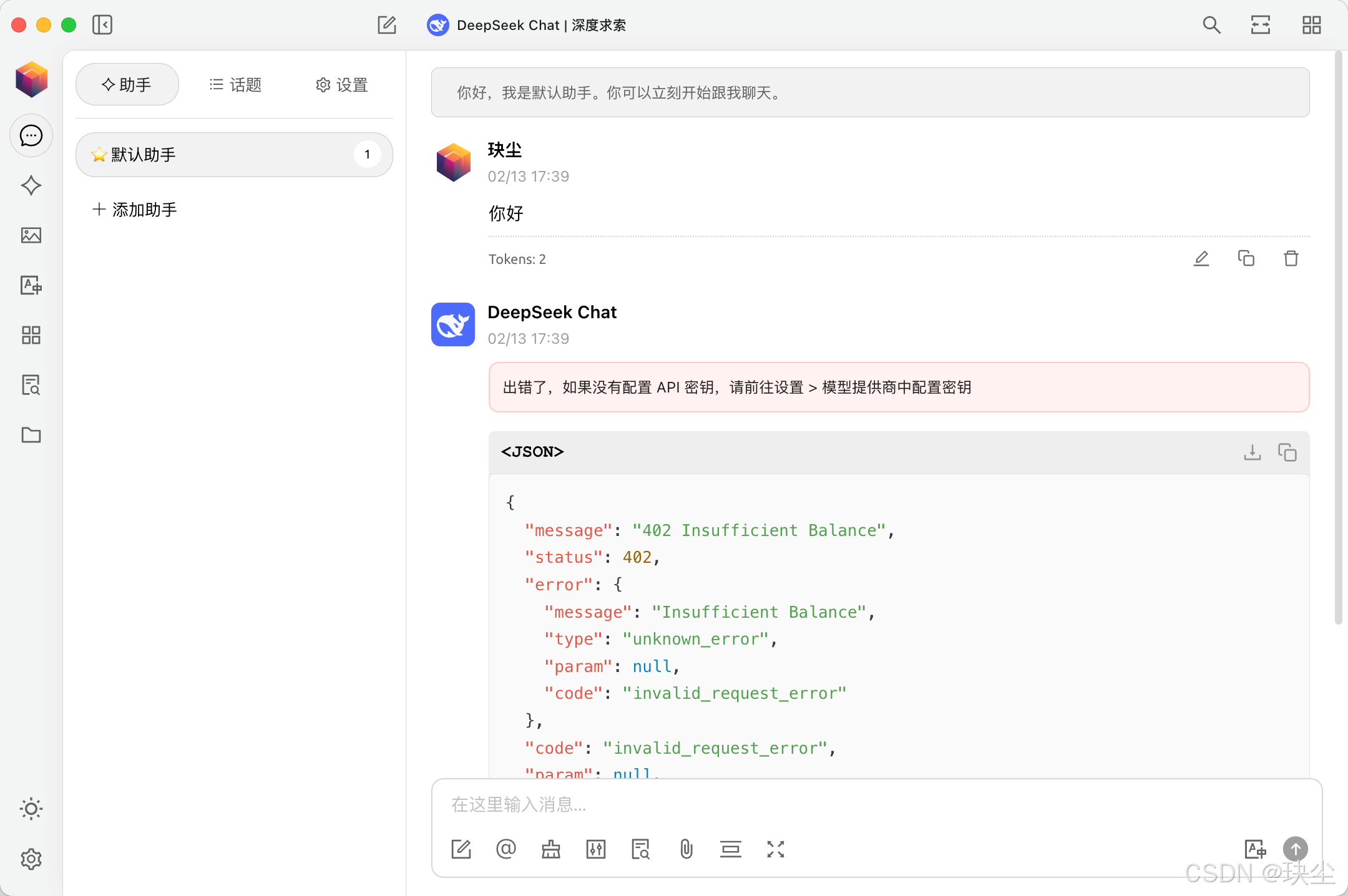
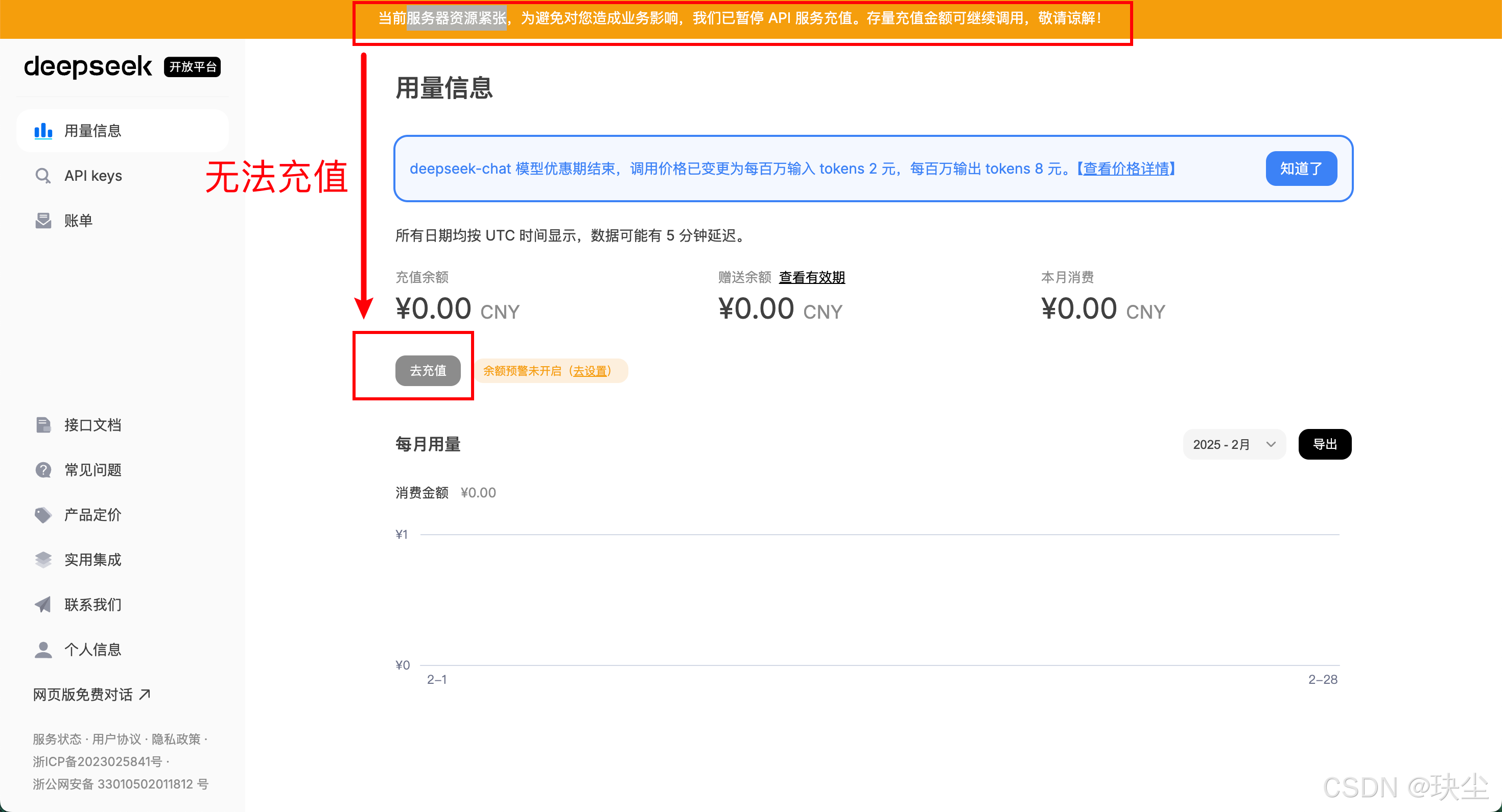
❌ 受 API 限制:目前DeepSeek服务器资源紧张,API调用受到限制。
❌ 延迟不可控:由于 API 调用需要网络传输,相比本地推理存在额外的网络延迟。
❌ 数据安全性:输入数据需要发送至 DeepSeek 服务器,可能涉及隐私或数据合规问题。
❌ 依赖服务稳定性:如果 DeepSeek 服务器出现故障或 API 调整,可能影响应用的可用性。
4. 实战演示
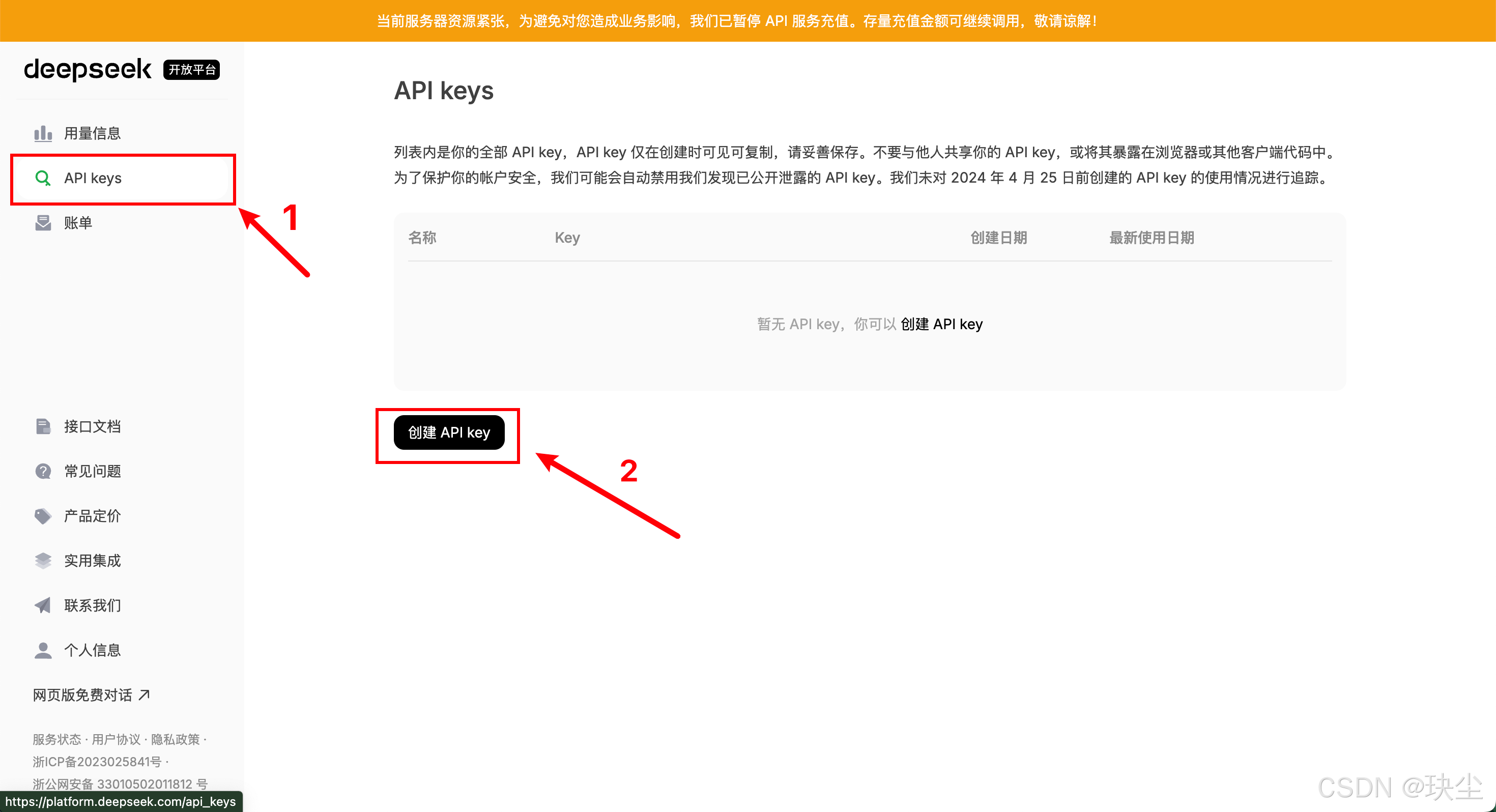
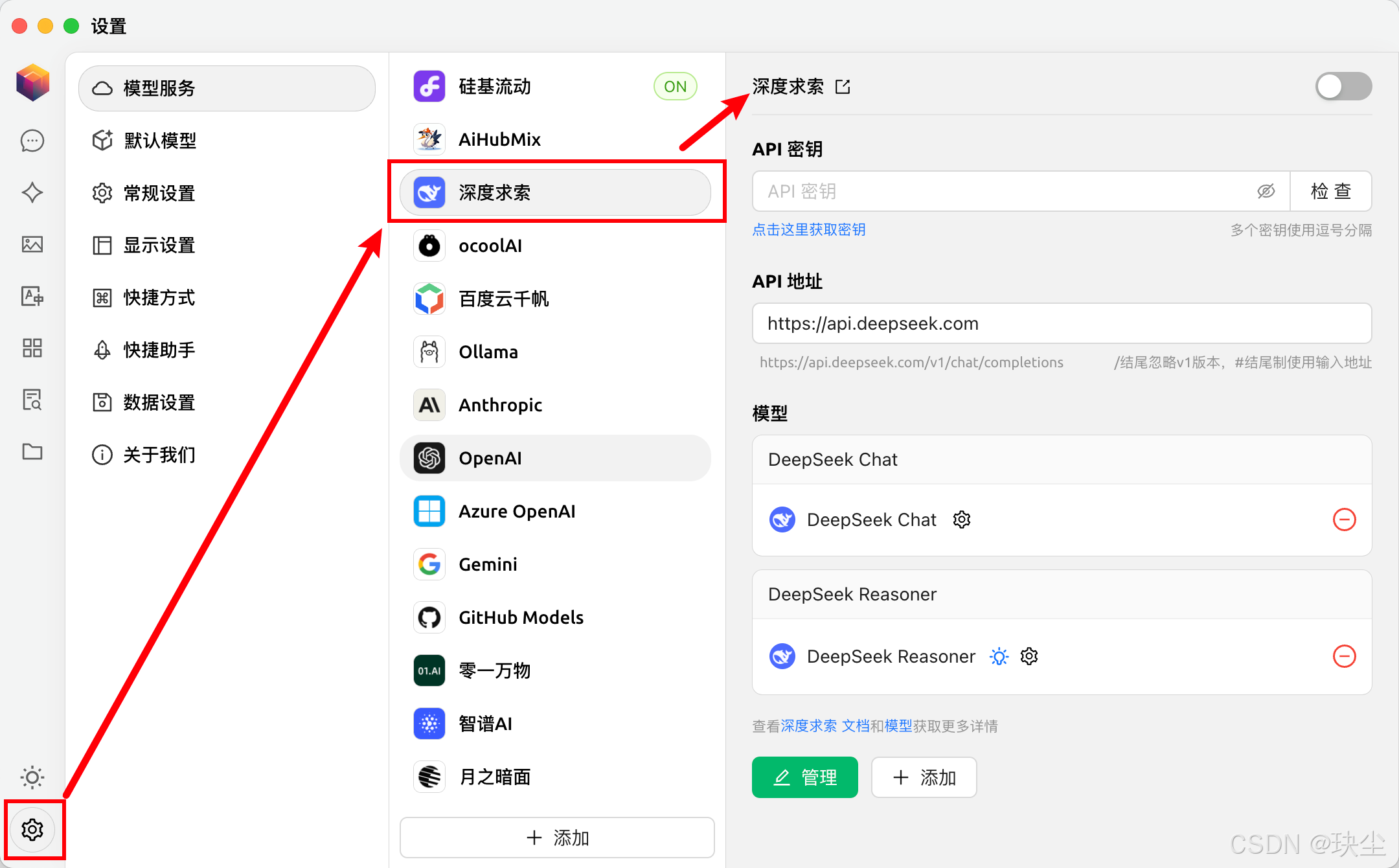
- 首先打开DeepSeek官网,然后找到API开放平台:

- 点击左侧
API Keys按钮,创建API key并复制:
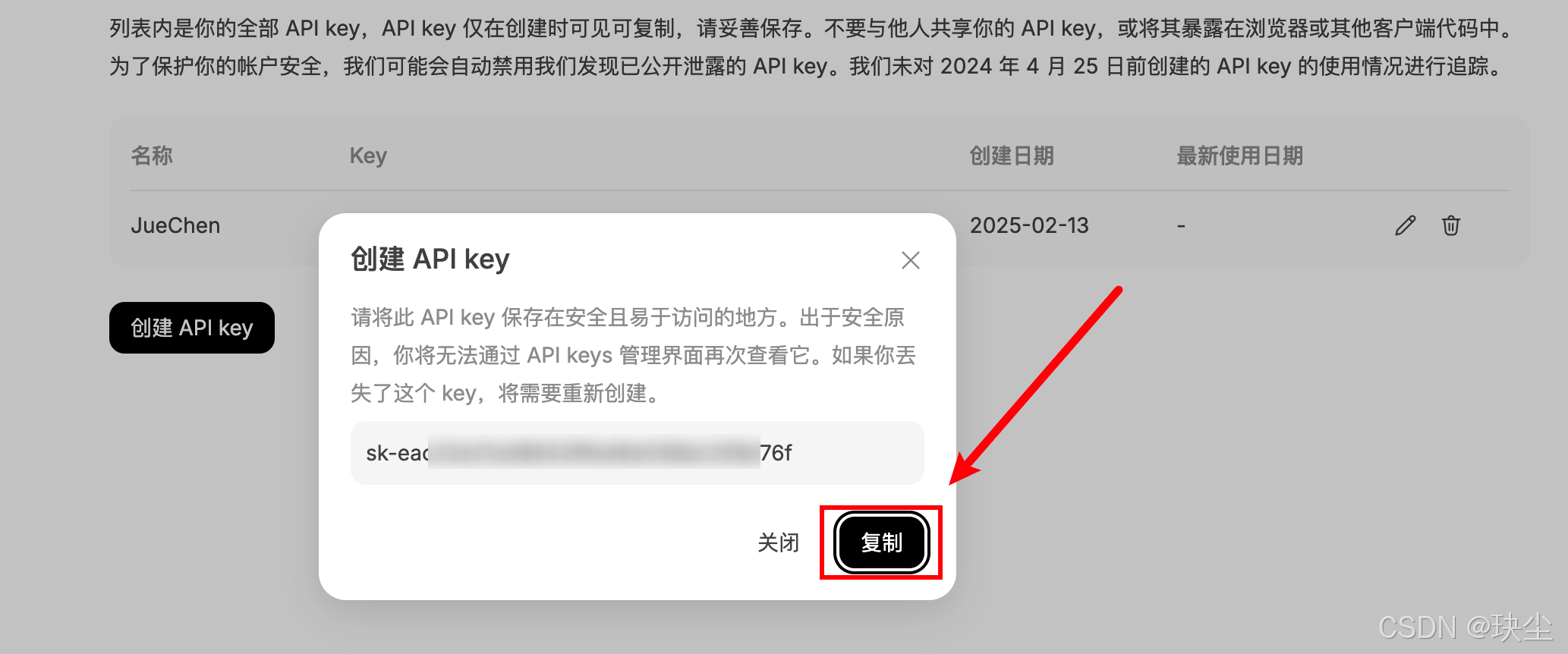
注意:API key 仅在创建时可见可复制,请妥善保存。不要与他人共享你的 API key,或将其暴露在浏览器或其他客户端代码中。
- 复制成功以后,随便找一个客户端打开(这里以Cherry Studio为例):
Cherry Studio安装简单,这里就不再过多赘述了。
-
按下图操作步骤依次操作即可:
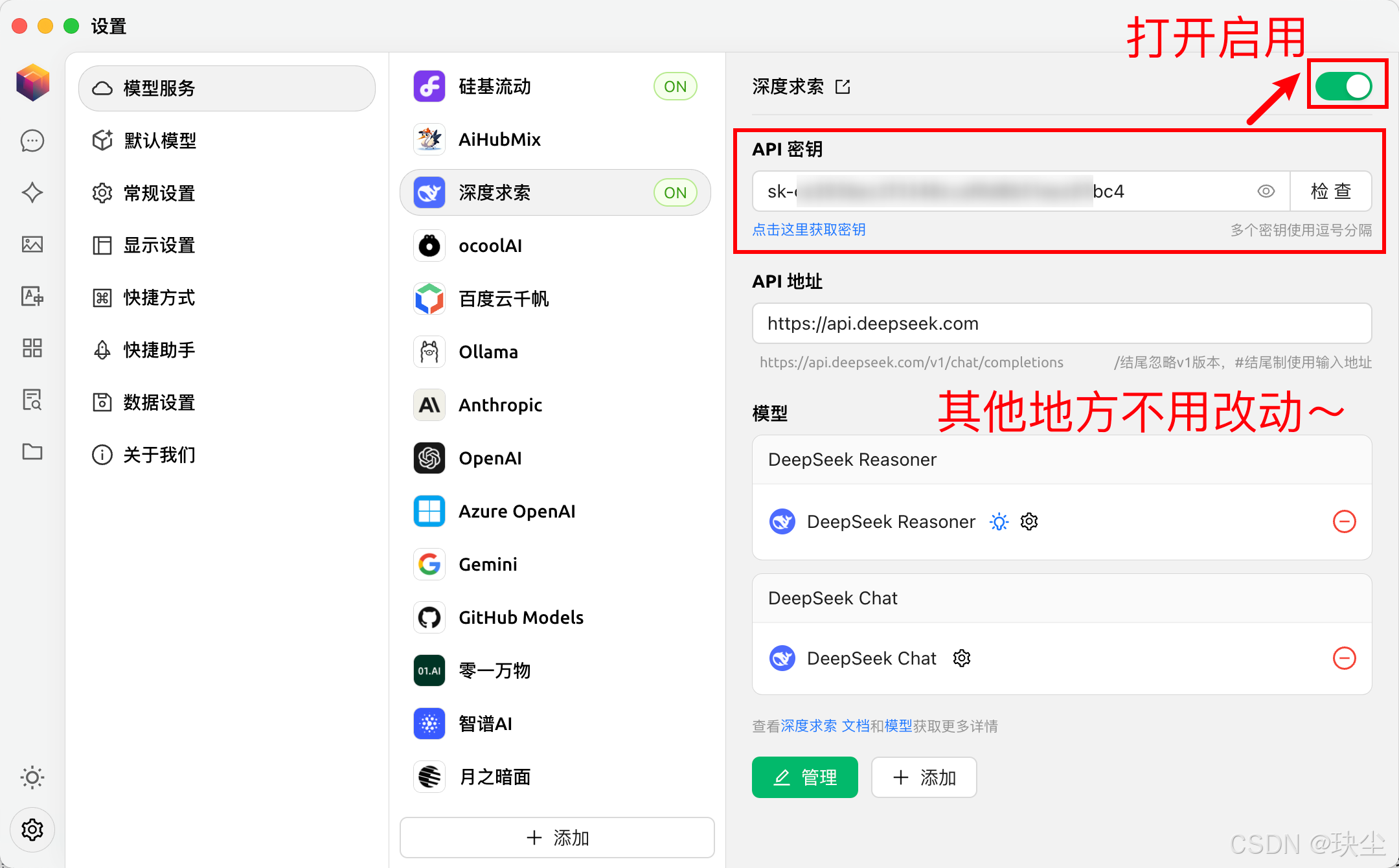
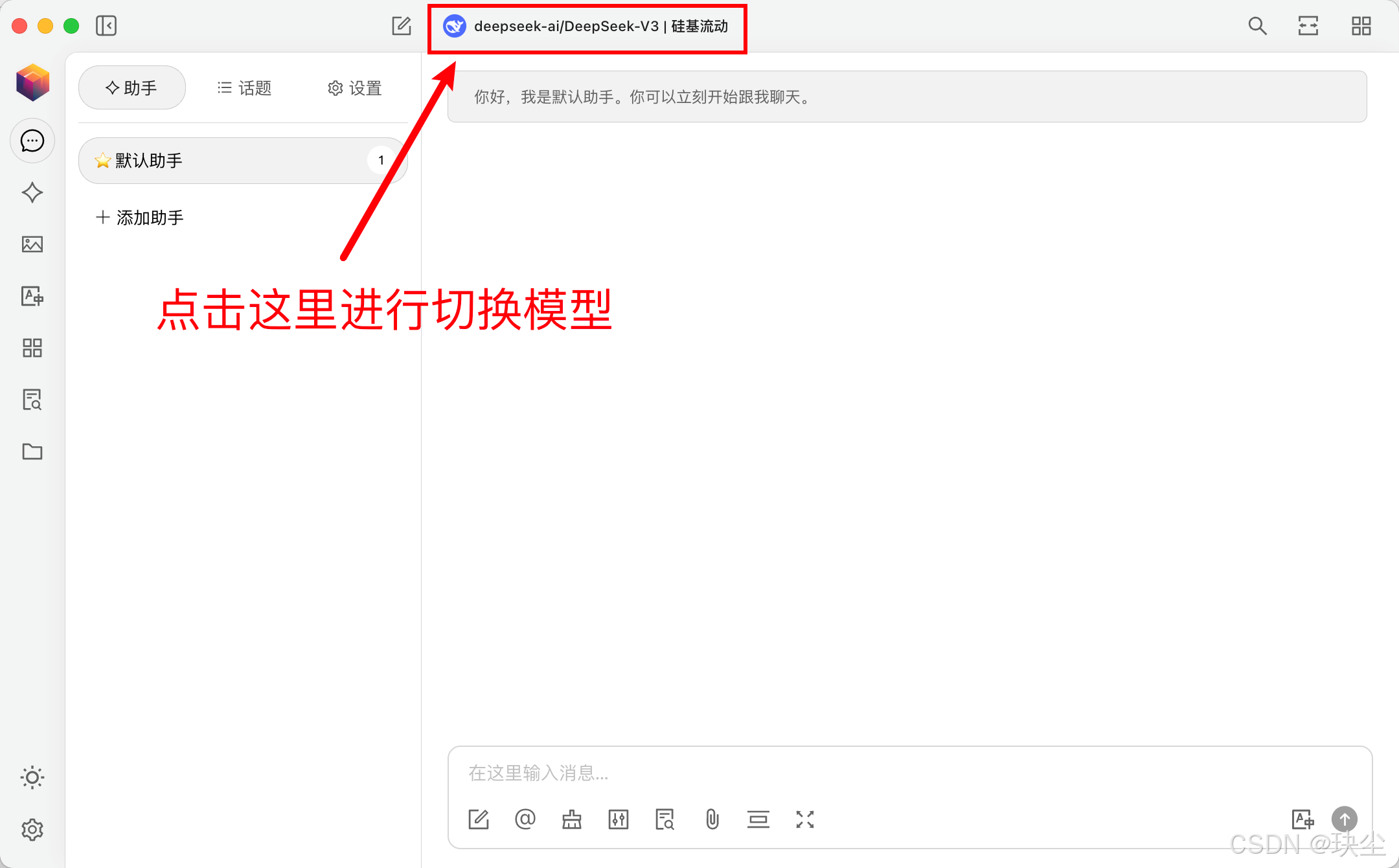
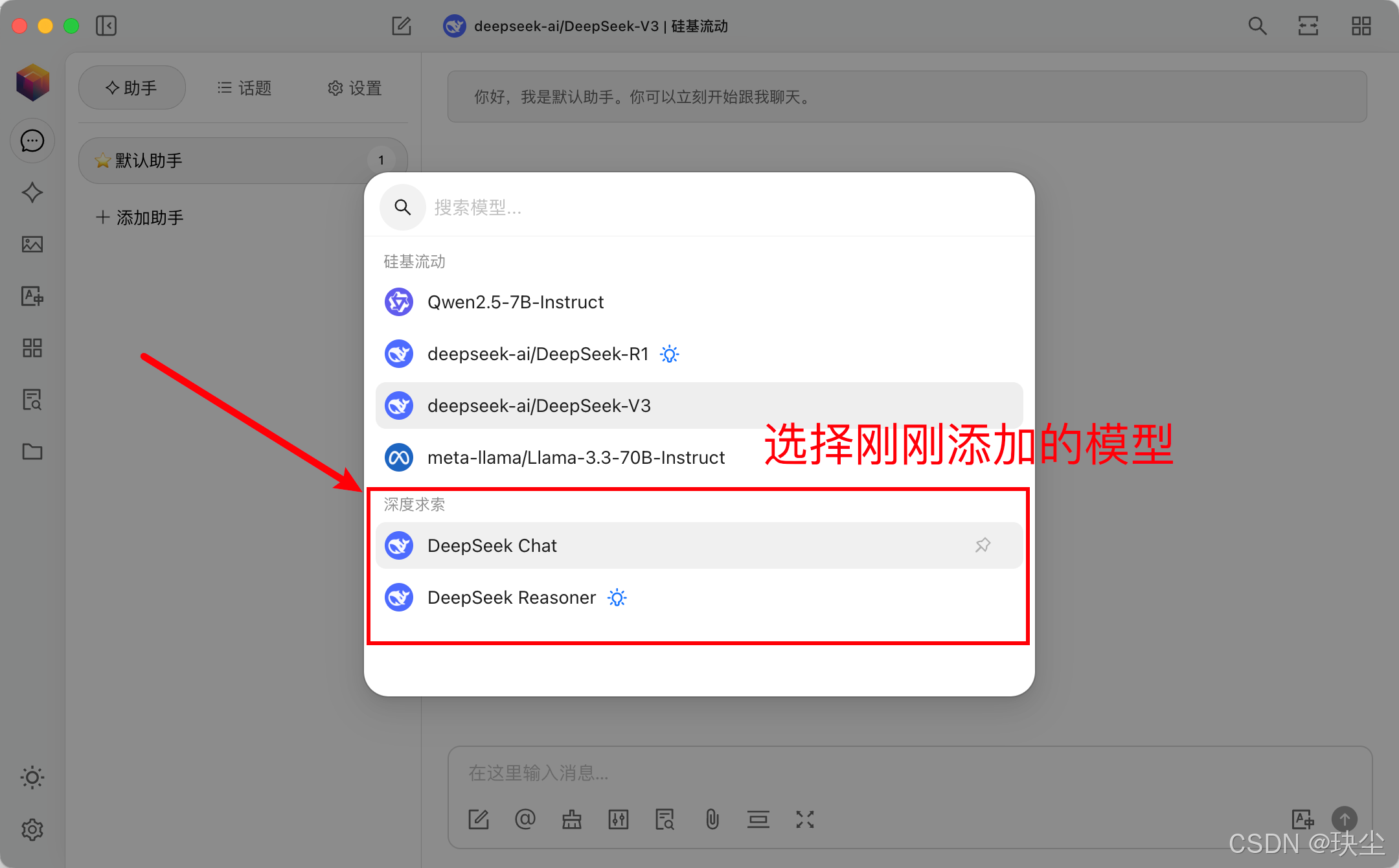
-
接下来就可以使用DeepSeek的模型啦,但是由于近期DeepSeek服务频频崩溃,为确保普通用户的正常访问,所以DeepSeek暂时停用了API服务。
方案二:第三方平台(秘塔搜索、硅基流动)
1. 秘塔搜索
优点:满血版R1,操作方便
缺点:无法关闭联网搜索
2. 硅基流动
网址:https://siliconflow.cn/zh-cn/models
使用流程:
-
注册账号。用手机号注册即可,新注册的账号有免费的2000token可以使用。
-
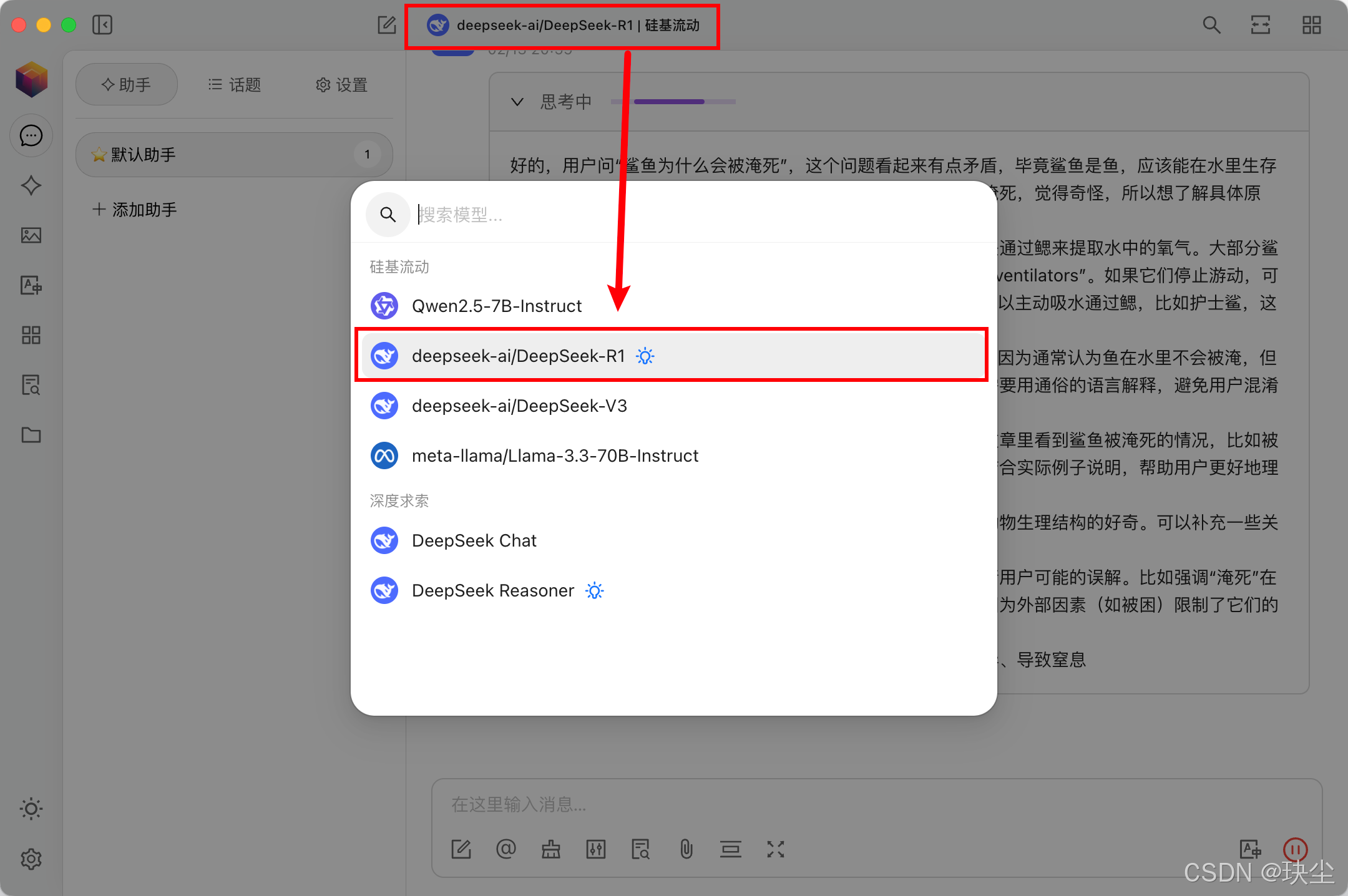
选择R1模型:

-
两种配置方式:
-
在线体验
-
调用API:
-
创建API密钥
-
复制API密钥
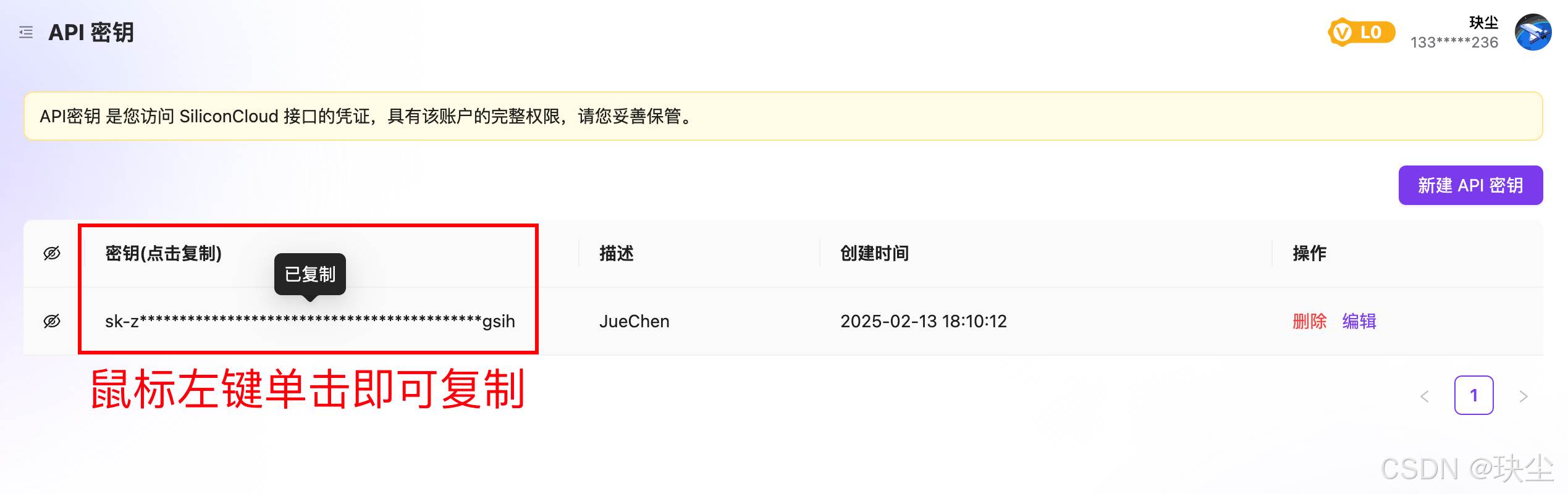
-
下载与安装客户端工具
DeepSeek 官方推荐了多款集成工具,帮助用户更方便地与 DeepSeek 模型进行交互。详细的集成工具列表可以查看官方 GitHub 页面:DeepSeek 集成工具。
其中,推荐使用的客户端工具是 Cherry Studio,这是一款功能强大的 AI 开发工具,能够简化 DeepSeek 模型的集成与调试工作。你可以通过以下链接访问并下载: Cherry Studio 官网。
需要注意的是,由于该工具是从 GitHub 下载的,部分地区可能会遇到无法直接访问的情况。对此,你可以选择使用梯子进行下载,或者直接使用我们提供的离线包进行安装,避免网络限制带来的不便。
安装过程非常简单,Cherry Studio 傻瓜式安装向导,用户只需按照提示一步步操作即可完成安装。 -
配置API密钥
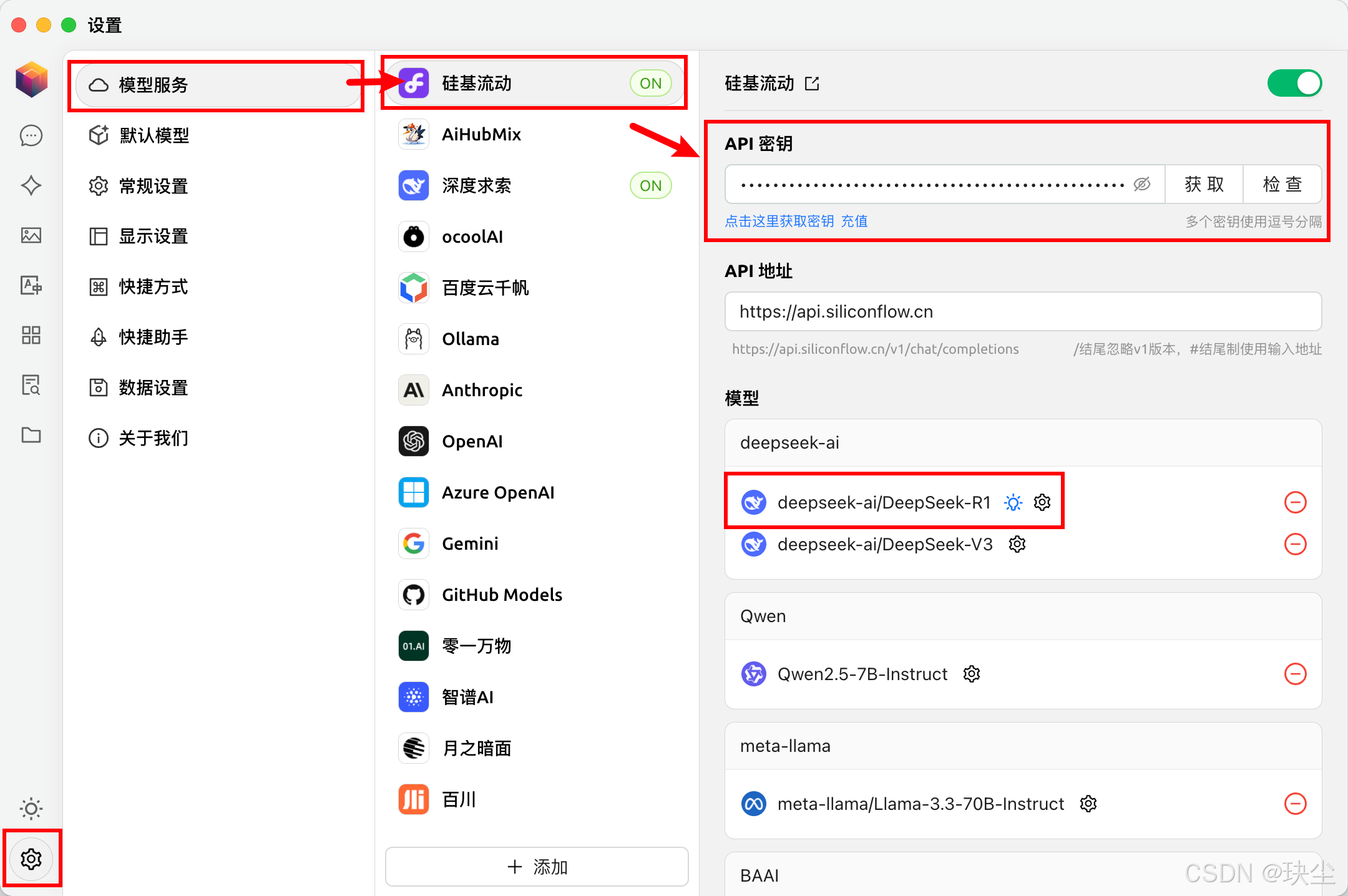
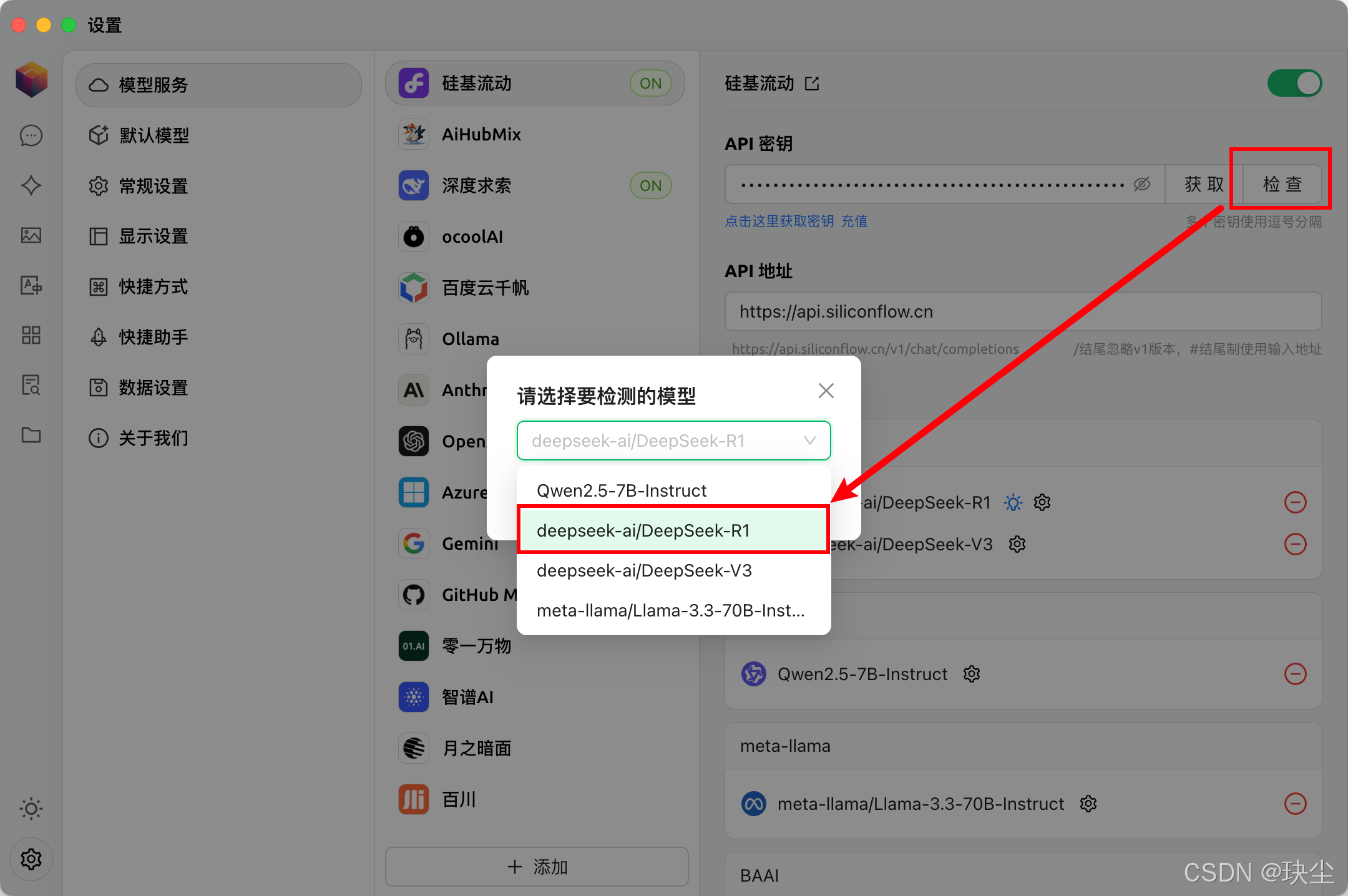
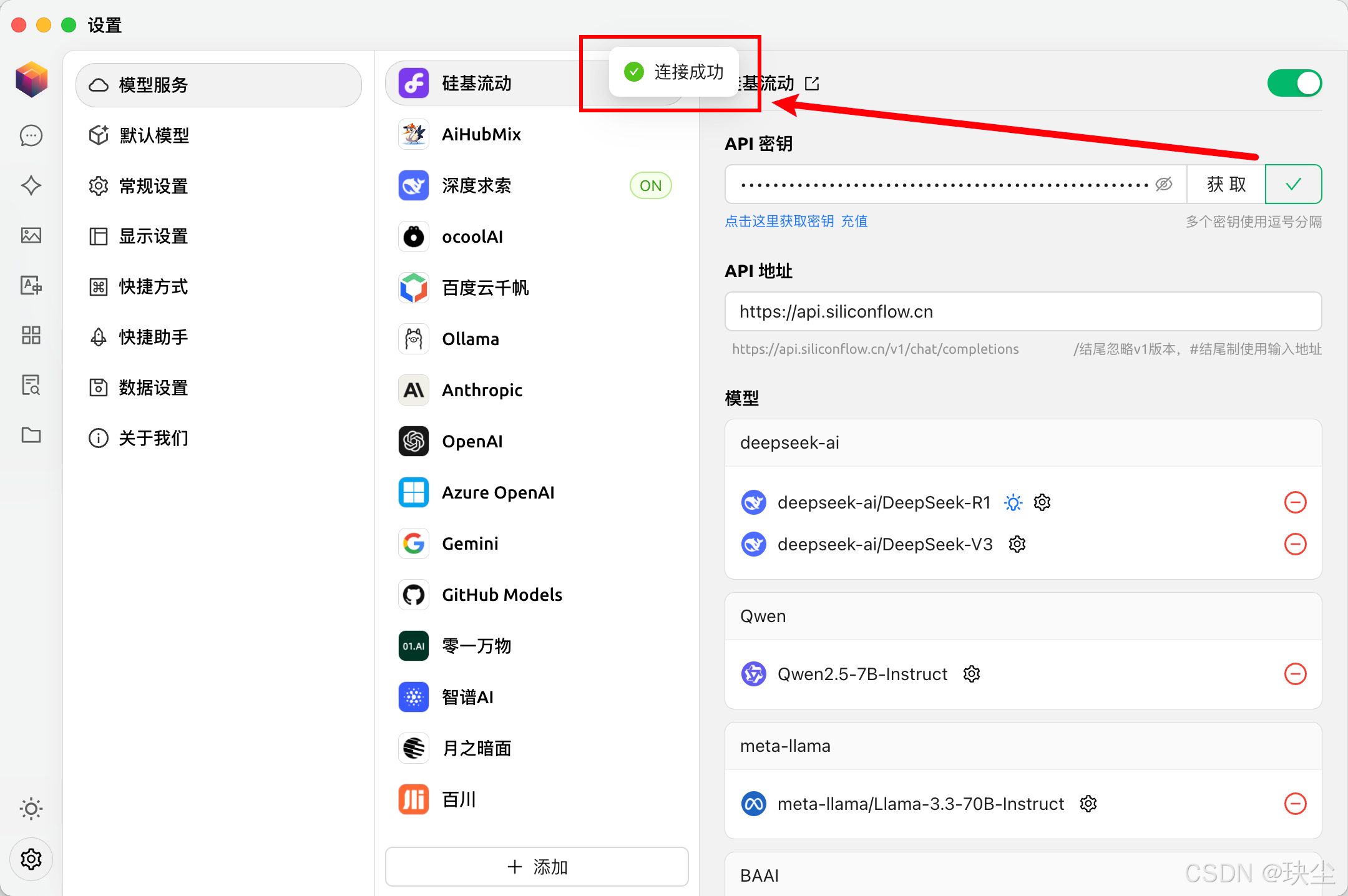
-
选择模型
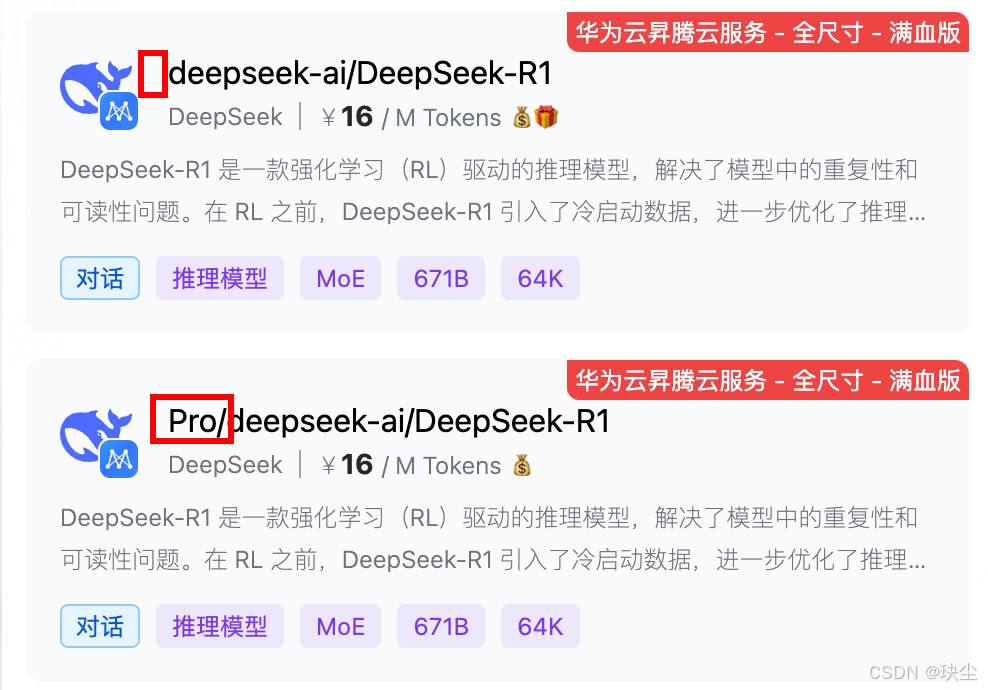
缺点:花完送的token,再想用就需要充值了。 -
充值操作:使用Pro的满血R1需要充钱,交互等待时长比普通的R1赠送的。想要充值的话,首先进行实名认证,后续正常支付即可。

-
3. 其他平台
-
百度千帆
- 链接: 百度千帆平台
- 描述: 提供AI模型的训练、推理和管理服务,适合企业开发AI应用。
-
阿里云PAI
- 链接: 阿里云PAI平台
- 描述: 阿里云的人工智能平台,支持机器学习、深度学习和大数据分析,可以快速创建AI模型。
-
腾讯云 TIONE
- 链接: 腾讯云 TIONE平台
- 描述: 提供AI模型的训练和部署平台,支持DeepSeek等AI解决方案。
-
Cursor
- 链接: Cursor
- 描述: 需要订阅Cursor会员才能使用的高效AI助手,适合开发者使用。
-
Grok
- 链接: Grok官网
- 描述: 提供基于Grok硬件的AI计算平台,主打高效的推理计算,支持蒸馏版的Llama 70B模型,但中文能力有限。
-
国家超算中心
- 链接: 国家超算中心
- 描述: 提供强大的计算资源和AI模型训练环境,适合科研和企业级应用。
方案三:本地算力部署(基于ollama)
1. 版本选择
简单来说,本地部署DeepSeek-R1模型就是让你在自己的电脑或服务器上运行这个模型,不需要联网。最大的问题是,这个模型非常大,尤其是DeepSeekR1671B(满血版),文件大小能达到720GB,普通电脑或公司服务器很难满足这种硬件需求。
不过,这种方式特别适合那些对数据隐私要求极高的地方,比如保密单位或敏感行业,因为他们需要确保数据完全在本地处理,避免泄露风险。虽然硬件要求高,但好处是不用联网,完全自主控制。
使用蒸馏版::https://huggingface.co/deepseek-ai
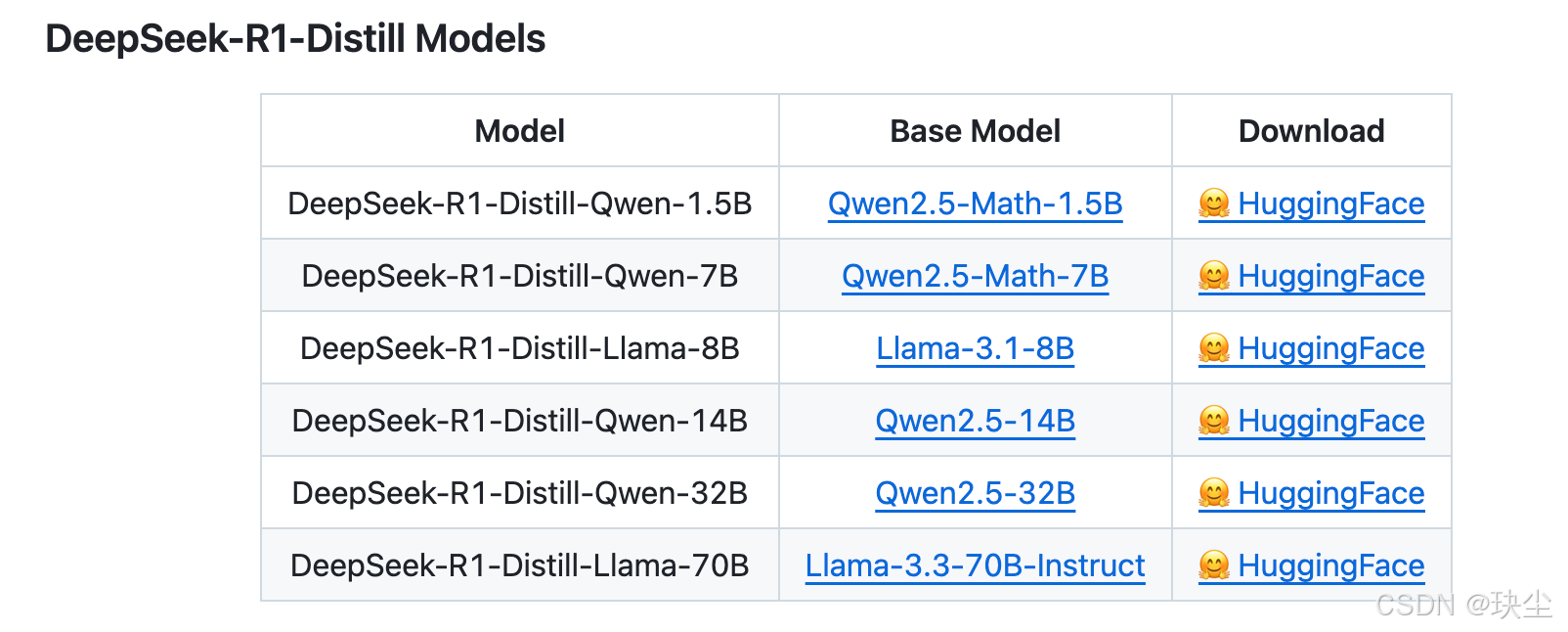
简单来说,DeepSeek 开源了2个主要模型和6个简化版模型。R1预览版和正式版的参数高达660B(非常大),普通公司根本用不起。为了让更多人能用,他们通过“蒸馏”技术压缩出了6个小模型,最小的只有1.5B参数,10G显存就能跑,适合普通用户。
如果你想在个人电脑上部署,通常会选择其他架构的简化模型,比如基于Llama或Qwen微调的版本,参数一般在32B以下。不过,这些简化版模型无法完全发挥DeepSeek R1的全部能力,算是性能和硬件需求之间的折中方案。
2. 部署过程
现在很多人喜欢用 Ollama(https://ollama.com/)来在本地运行大模型。Ollama 可以理解为一个本地版的“服务器”,用来托管和运行模型。你可以在它的模型库(https://ollama.com/library)里选择各种模型,然后在本地运行。
然后,你可以搭配一些前端工具来使用,比如 ChatBox、Cherry Studio(https://chatboxai.app/zh),或者其他工具,比如 Chrome 插件 PageAssist 或 AnythingLLM。
两者结合就能在本地轻松玩转大模型了!
步骤1:下载ollama
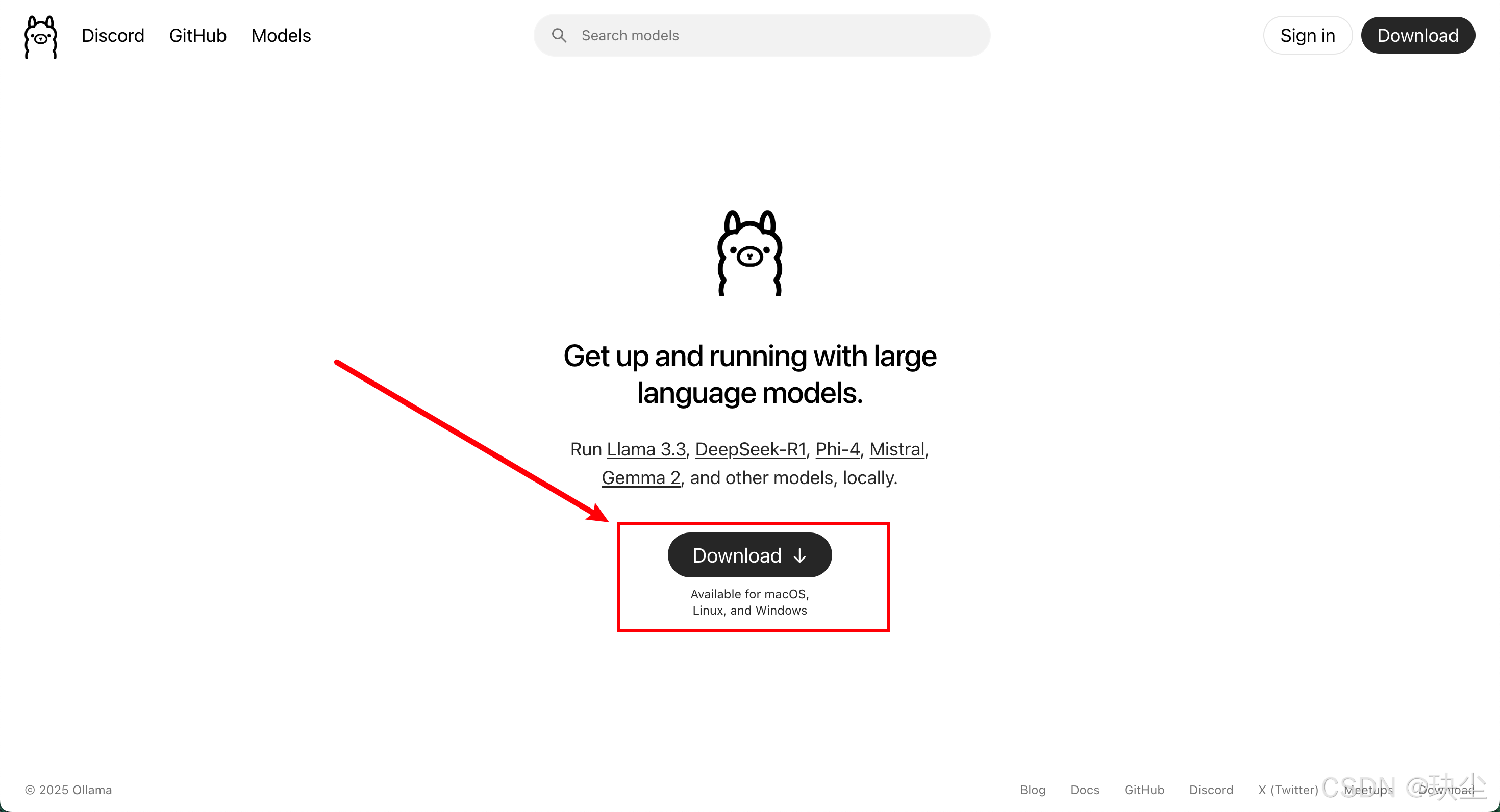
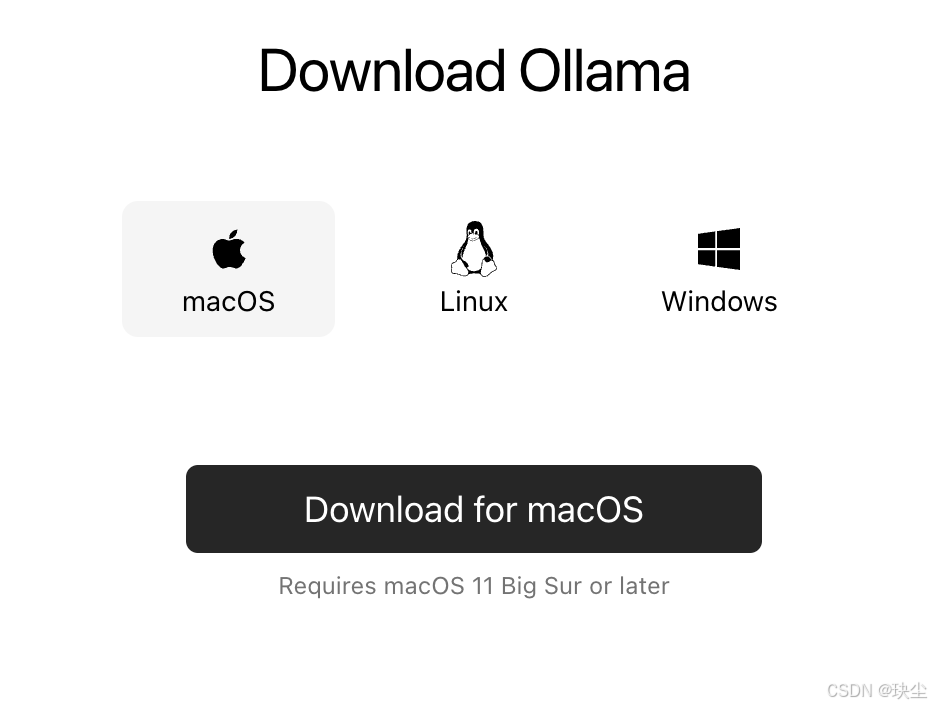
步骤二:安装Ollama
我这里用的是macOS版本,安装完成之后,在终端输入命令检验是否安装成功:
ollama -v
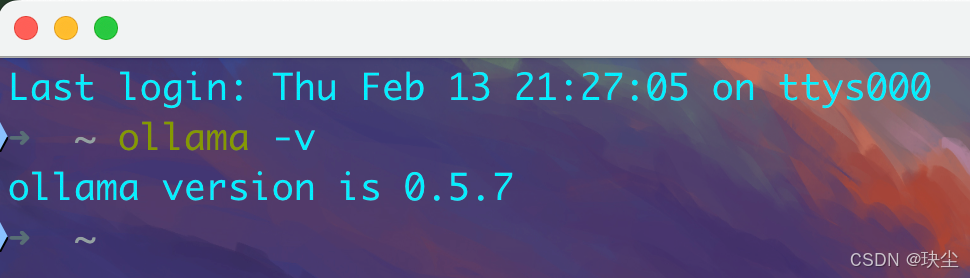
能显示ollama版本说明安装成功。
步骤三:选择R1模型
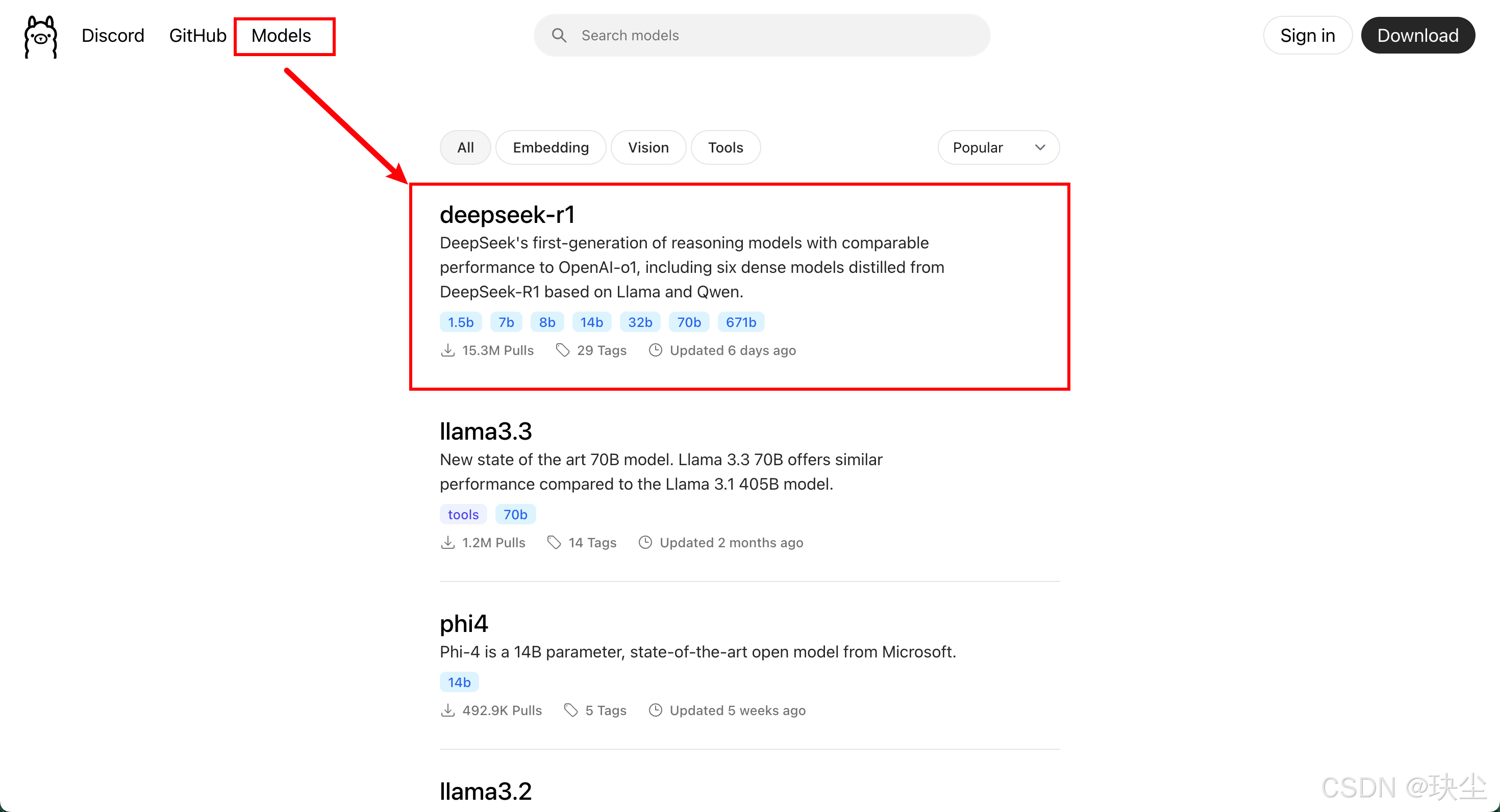
步骤四:选择版本
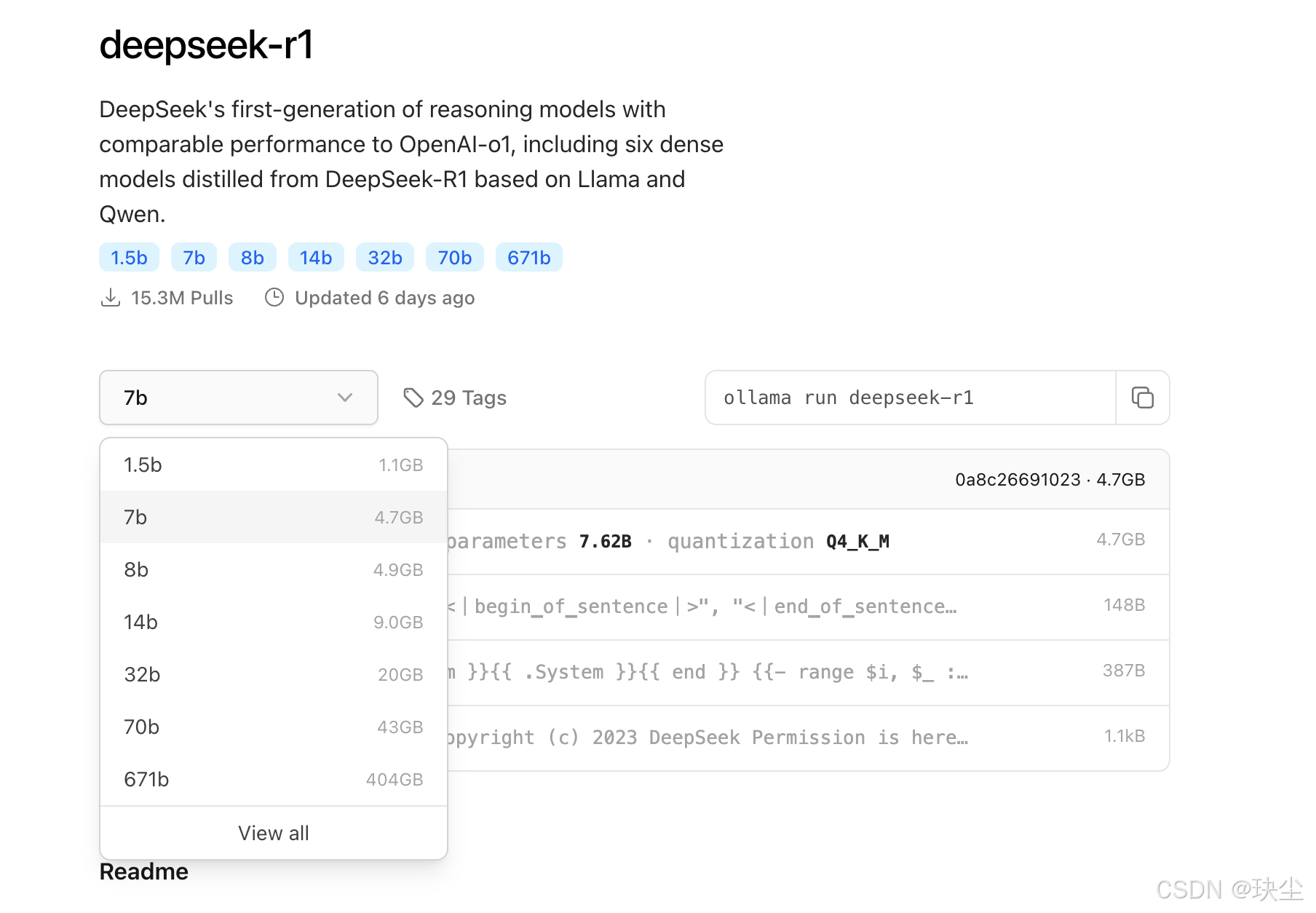
7B代表70亿参数,而671B经过HuggingFace的4-bit标准量化后,大小为404GB。由于它支持CPU和GPU混合推理,系统的“总内存空间”可以近似为内存和显存的总和。如果你想运行这个404GB的671B模型,建议你的内存和显存加起来能达到500GB以上。
除了模型本身所需的内存和显存外,运行时还需要额外的空间来缓存上下文。缓存空间越大,支持的上下文窗口也越大。因此,根据你电脑的配置,选择适合的模型版本非常重要。如果你想运行404GB的671B,建议你的系统有足够的内存和显存,而7B版本则适用于大多数电脑,通常可以顺利运行。这里就以7b为例:
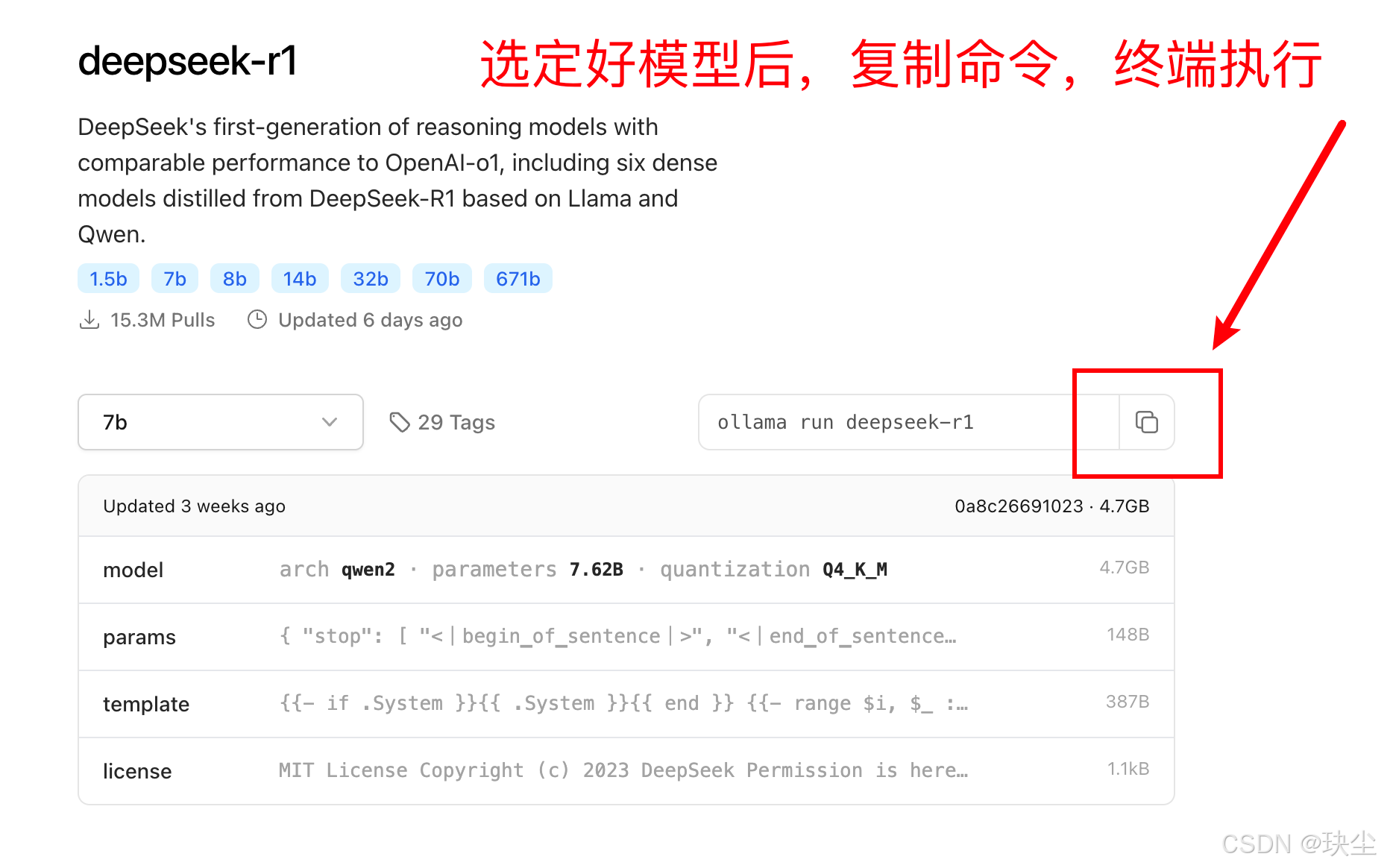
步骤五:本地运行DeepSeek模型
在命令行中输入以下命令:
ollama run deepseek-r1:7b
下载中…
下载支持断点续传,如果下载过程中速度变慢,可以点击命令行窗口,然后按 Ctrl+C (control + c)取消当前下载。取消后,按上箭头键即可找到之前的命令(如 “ollama run deepseek-r1:7b”),按回车键重新连接,会从中断处继续下载。
如果不想下载,也可以直接使用我们提供的已经下载好的模型文件,只需要按照后面章节的“修改models文件夹路径”步骤,配置好环境变量和对应的模型文件夹路径。
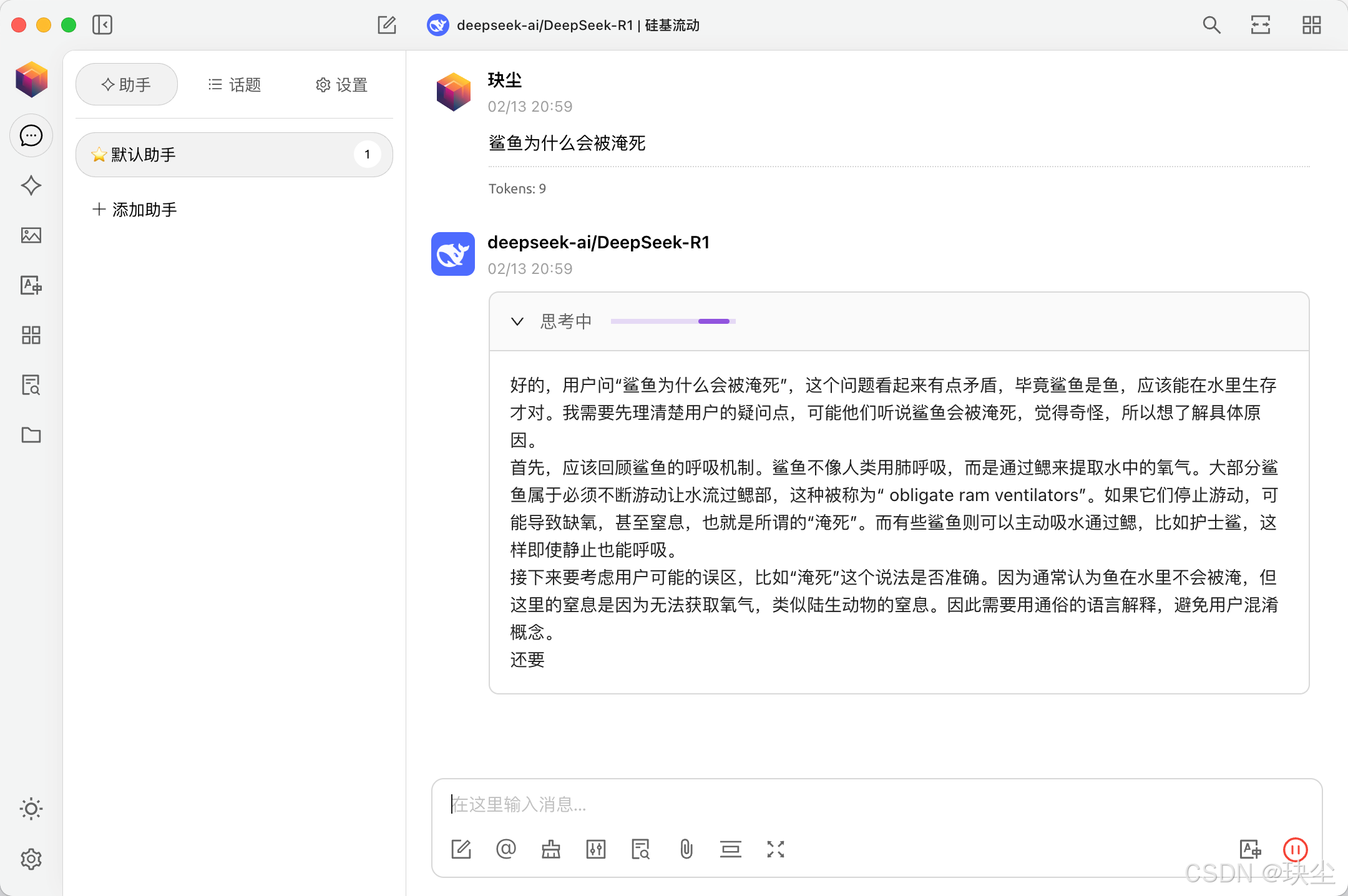
下载完成后,系统会自动进入模型界面,你可以在命令行中直接输入问题,就能得到回复。
例如:“你好啊!”
例如:“鲨鱼为什么会被淹死?”
获取帮助: /?
步骤六:查看已有模型
使用命令:ollama list

后续要想继续使用模型的话,仍然使用之前的命令即可:
3. 使用客户端工具
在本地部署好模型后,直接通过命令行操作可能不太方便,因此我们可以使用一些客户端工具来更方便地进行操作。
以Cherry Studio为例,可以用它来访问7B的蒸馏模型:
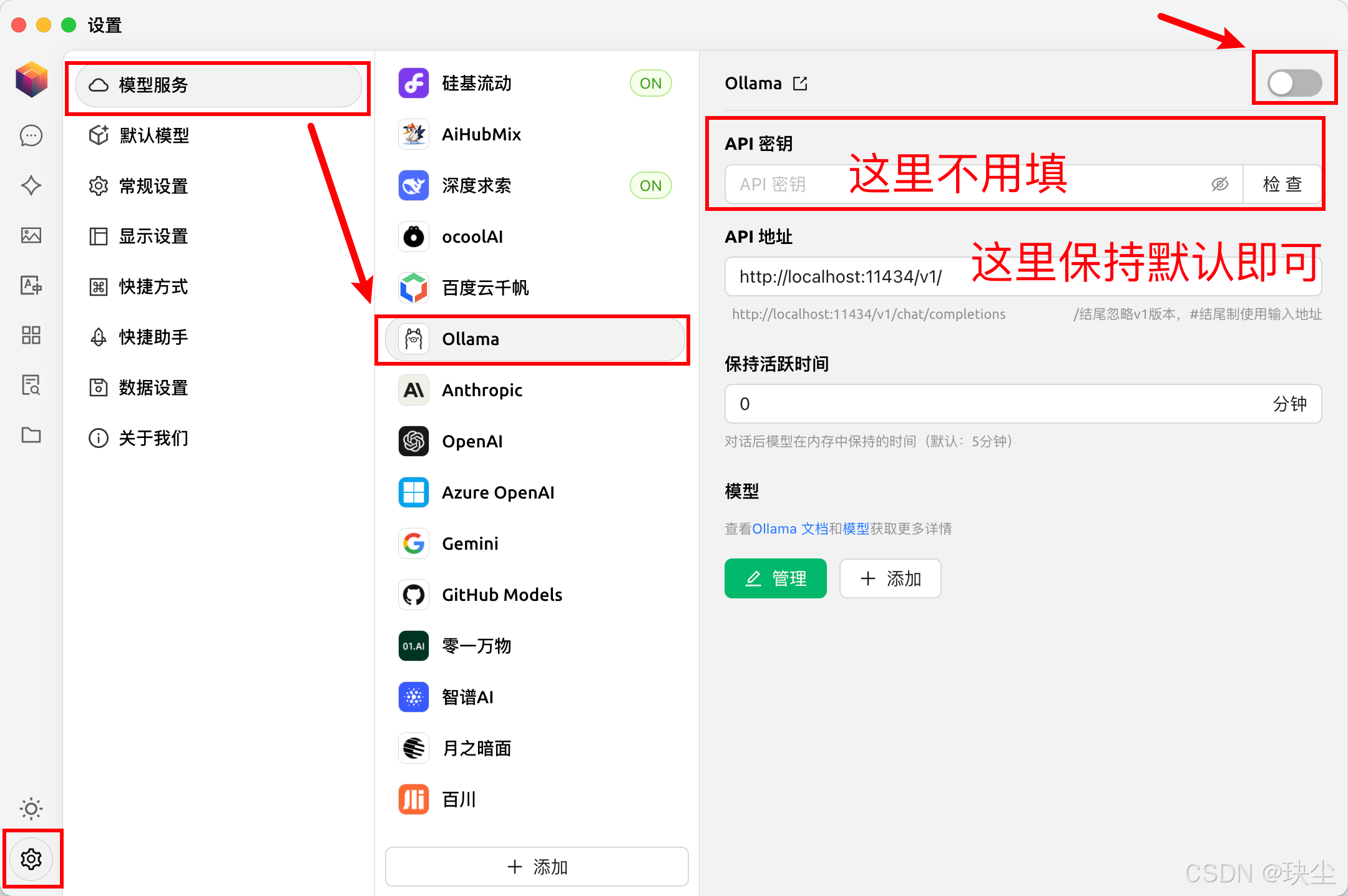
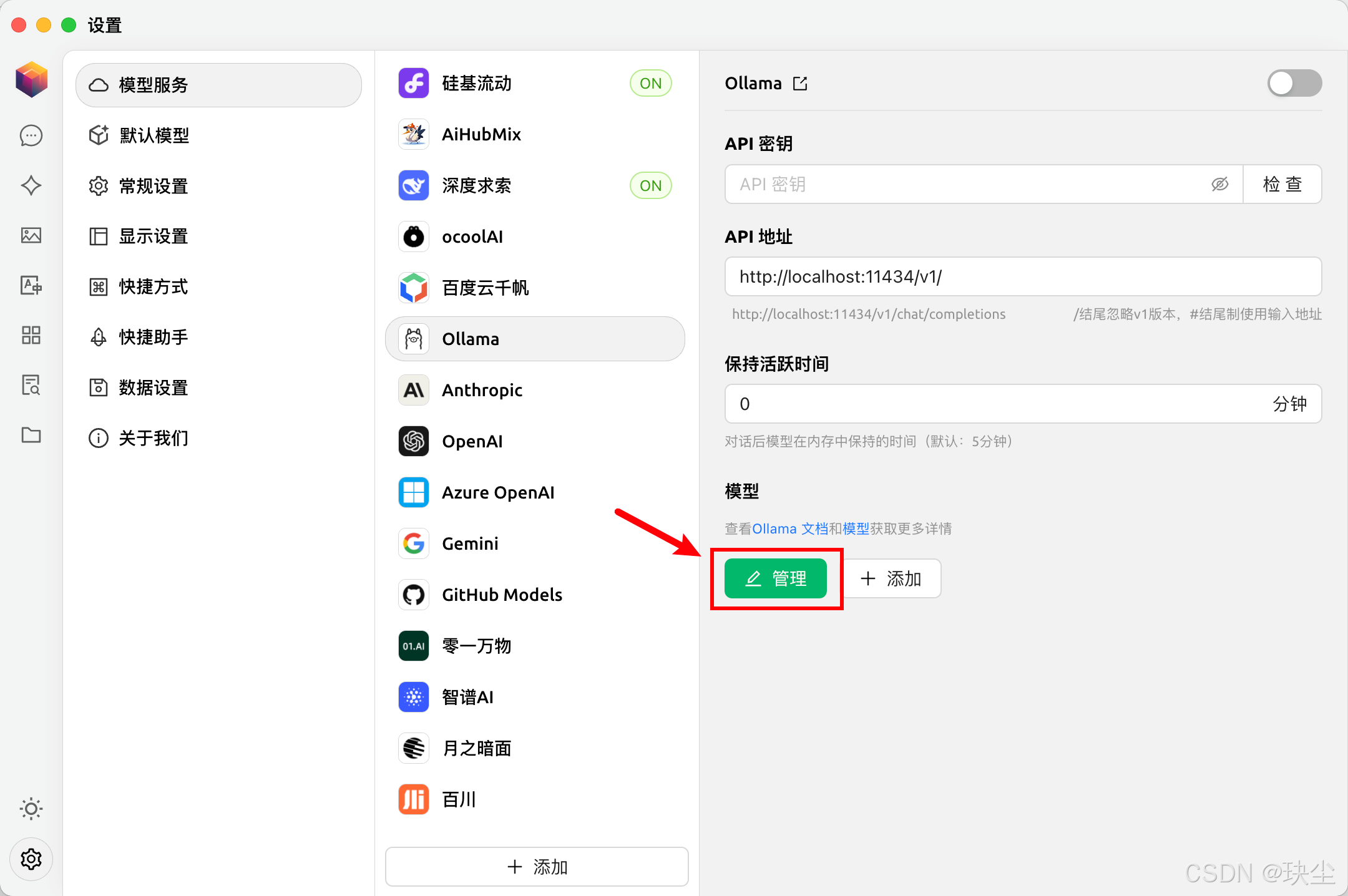
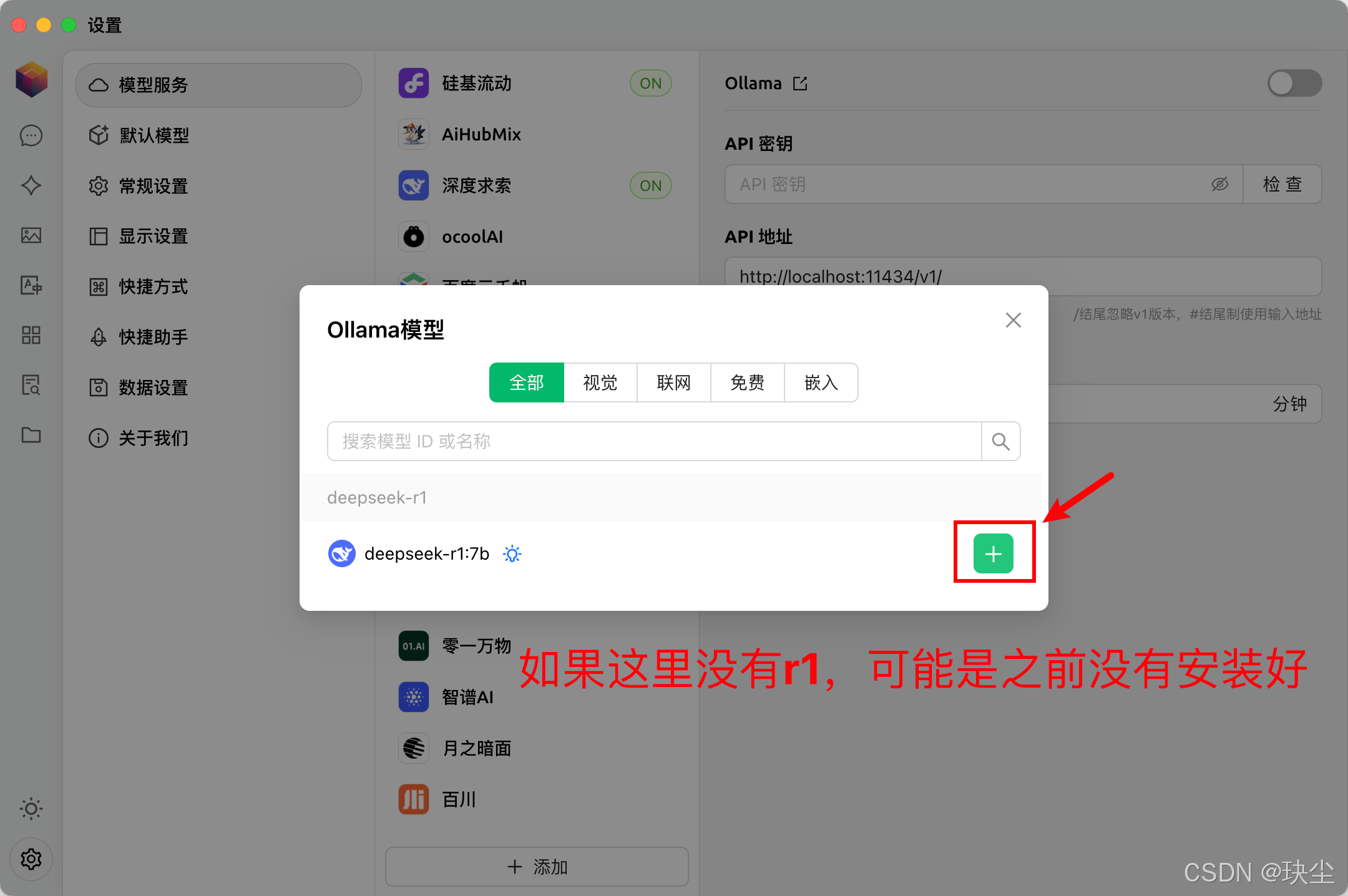
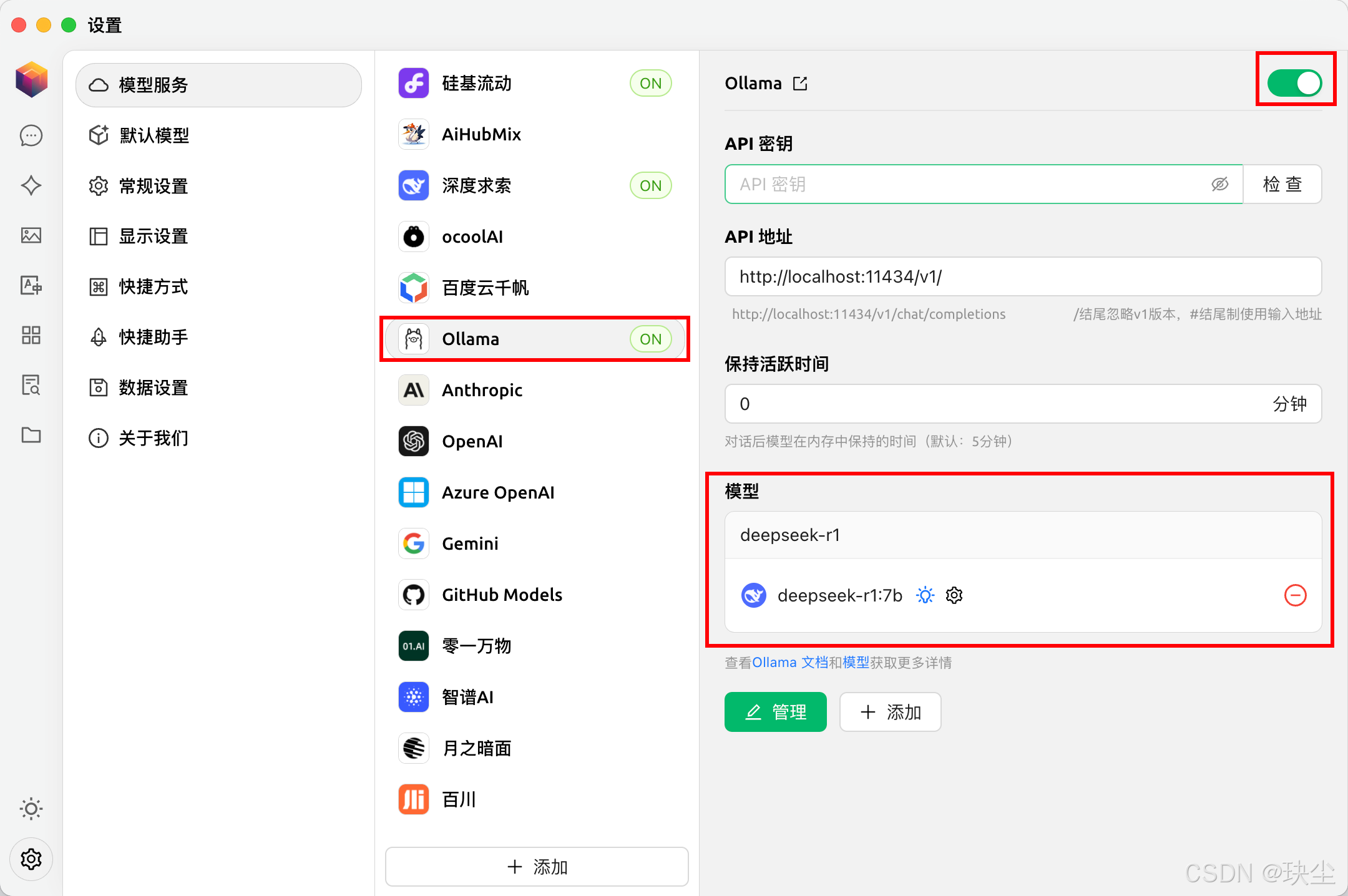
⚠️注意:使用时要确保ollama已启动!
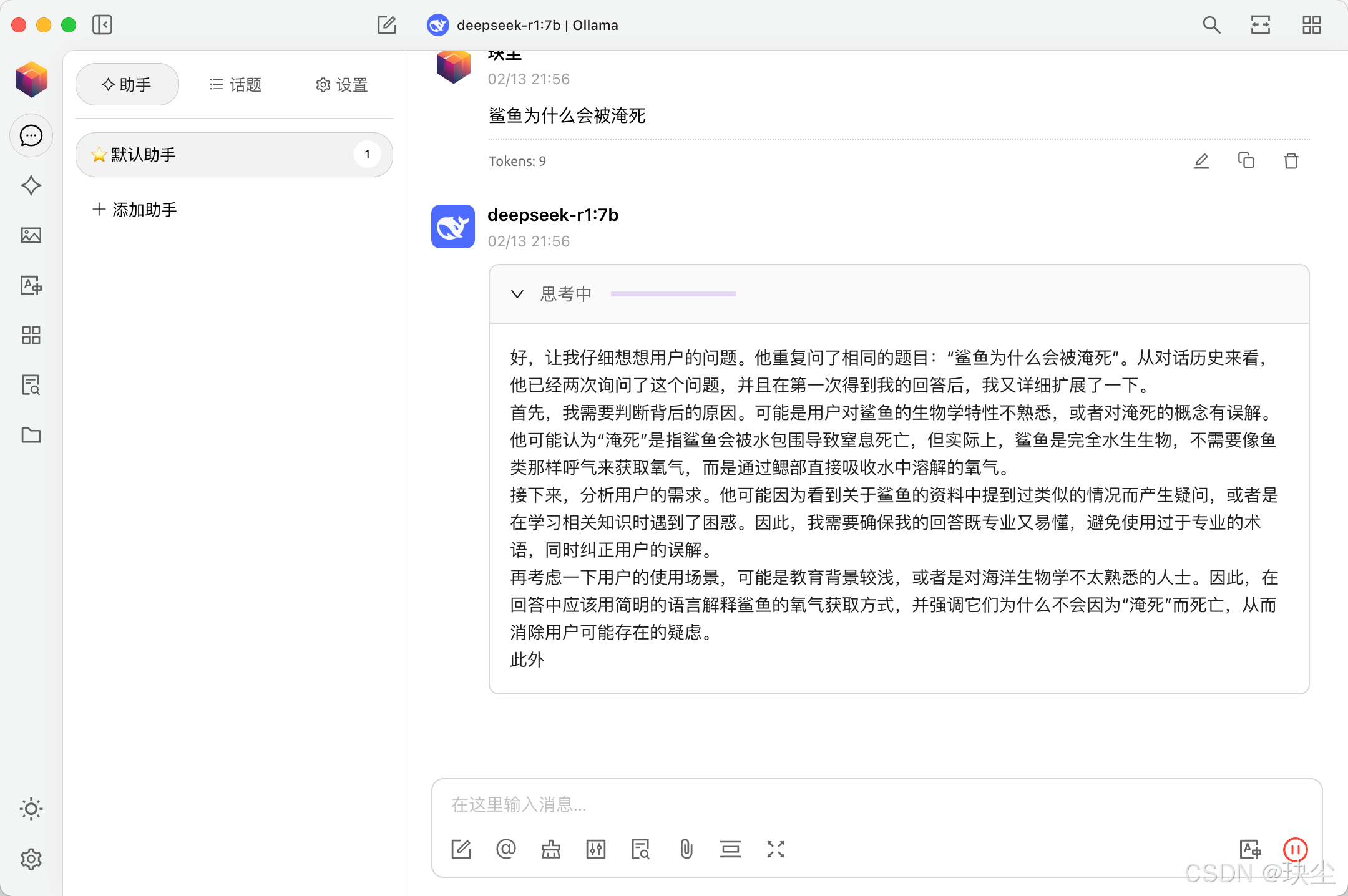
完美成功!!
方案四:服务器部署(了解)
如果企业想在自己的设备上部署完整的 DeepSeek-R1(671B 版本),需要非常强大的硬件支持。服务器可以是实体机,也可以是云服务器。使用 Ollama 提供的压缩版 671B 模型,大小是 404GB,建议内存和显存加起来超过 500GB。以下是几种性价比高的配置:
- Mac Studio:比如有人用了两台 192GB 内存的 Mac Studio 来运行压缩版的模型。
- 高内存带宽服务器:比如 HuggingFace 上的用户用了 24 条 16GB DDR5 内存的服务器。
- 云 GPU 服务器:比如用 2 张或更多 80GB 显存的 GPU(比如英伟达 H100,租用价格大约 2 美元/小时/卡)。
在这些硬件上运行模型,速度可以达到每秒生成 10 多个 token(文字)。
简单来说,部署流程和在个人电脑上部署 7B 模型的步骤差不多,具体如下:
- 下载 Ollama 客户端:根据服务器的操作系统,下载对应版本的 Ollama 客户端。
- 运行 Ollama:执行命令来运行 671B 版本的模型。第一次运行时会自动下载模型文件。
- 使用工具或开发页面:可以通过客户端工具(比如 ChatBox)、自己开发页面,或者写代码来调用 Ollama 的 R1 模型。
总结
本篇博客介绍了四种部署 DeepSeek 模型的方案,适合不同需求和场景:
- 调用 API + DeepSeek 服务器:最简单的方式,直接调用 DeepSeek 提供的 API,适合不想折腾硬件、追求快速上手的用户。
- 第三方平台(如秘塔搜索、硅基流动):通过第三方平台使用 DeepSeek 的能力,适合不想自己部署模型,但又需要灵活使用的场景。
- 本地算力部署(基于 Ollama):在个人电脑或本地服务器上运行模型,适合对数据隐私要求高、愿意折腾硬件的用户。
- 服务器部署:在企业级硬件或云服务器上部署完整版模型,适合对性能要求高、预算充足的企业用户。
每种方案都有各自的优缺点,选择哪种方式取决于你的需求、预算和技术能力。如果你是普通用户,API 或第三方平台可能是最方便的选择;如果你对数据隐私或性能有更高要求,本地或服务器部署会更适合。
总之,DeepSeek 的灵活性让它能适应各种场景,总有一种方案适合你!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









